One of the most fundamental principles in Fourier analysis is the uncertainty principle. It does not have a single canonical formulation, but one typical informal description of the principle is that if a function  is restricted to a narrow region of physical space, then its Fourier transform
is restricted to a narrow region of physical space, then its Fourier transform 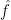 must be necessarily “smeared out” over a broad region of frequency space. Some versions of the uncertainty principle are discussed in this previous blog post.
must be necessarily “smeared out” over a broad region of frequency space. Some versions of the uncertainty principle are discussed in this previous blog post.
In this post I would like to highlight a useful instance of the uncertainty principle, due to Hugh Montgomery, which is useful in analytic number theory contexts. Specifically, suppose we are given a complex-valued function 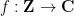 on the integers. To avoid irrelevant issues at spatial infinity, we will assume that the support
on the integers. To avoid irrelevant issues at spatial infinity, we will assume that the support  of this function is finite (in practice, we will only work with functions that are supported in an interval
of this function is finite (in practice, we will only work with functions that are supported in an interval ![{[M+1,M+N]}](https://s0.wp.com/latex.php?latex=%7B%5BM%2B1%2CM%2BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for some natural numbers
for some natural numbers 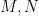 ). Then we can define the Fourier transform
). Then we can define the Fourier transform  by the formula
by the formula

where 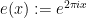 . (In some literature, the sign in the exponential phase is reversed, but this will make no substantial difference to the arguments below.)
. (In some literature, the sign in the exponential phase is reversed, but this will make no substantial difference to the arguments below.)
The classical uncertainty principle, in this context, asserts that if is localised in an interval of length  , then must be “smeared out” at a scale of at least
, then must be “smeared out” at a scale of at least  (and essentially constant at scales less than ). For instance, if is supported in , then we have the Plancherel identity
(and essentially constant at scales less than ). For instance, if is supported in , then we have the Plancherel identity

while from the Cauchy-Schwarz inequality we have

for each frequency  , and in particular that
, and in particular that
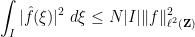
for any arc  in the unit circle (with
in the unit circle (with 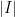 denoting the length of ). In particular, an interval of length significantly less than can only capture a fraction of the
denoting the length of ). In particular, an interval of length significantly less than can only capture a fraction of the  energy of the Fourier transform of , which is consistent with the above informal statement of the uncertainty principle.
energy of the Fourier transform of , which is consistent with the above informal statement of the uncertainty principle.
Another manifestation of the classical uncertainty principle is the large sieve inequality. A particularly nice formulation of this inequality is due independently to Montgomery and Vaughan and Selberg: if is supported in , and  are frequencies in
are frequencies in 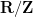 that are
that are  -separated for some
-separated for some  , thus
, thus  for all
for all 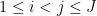 (where
(where  denotes the distance of to the origin in ), then
denotes the distance of to the origin in ), then
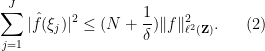
The reader is encouraged to see how this inequality is consistent with the Plancherel identity (1) and the intuition that is essentially constant at scales less than . The factor  can in fact be amplified a little bit to
can in fact be amplified a little bit to  , which is essentially optimal, by using a neat dilation trick of Paul Cohen, in which one dilates to
, which is essentially optimal, by using a neat dilation trick of Paul Cohen, in which one dilates to ![{[MK+K, MK+NK]}](https://s0.wp.com/latex.php?latex=%7B%5BMK%2BK%2C+MK%2BNK%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) (and replaces each frequency
(and replaces each frequency 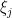 by their
by their 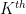 roots), and then sending
roots), and then sending 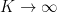 (cf. the tensor product trick); see this survey of Montgomery for details. But we will not need this refinement here.
(cf. the tensor product trick); see this survey of Montgomery for details. But we will not need this refinement here.
In the above instances of the uncertainty principle, the concept of narrow support in physical space was formalised in the Archimedean sense, using the standard Archimedean metric  on the integers
on the integers  (in particular, the parameter is essentially the Archimedean diameter of the support of ). However, in number theory, the Archimedean metric is not the only metric of importance on the integers; the
(in particular, the parameter is essentially the Archimedean diameter of the support of ). However, in number theory, the Archimedean metric is not the only metric of importance on the integers; the  -adic metrics play an equally important role; indeed, it is common to unify the Archimedean and -adic perspectives together into a unified adelic perspective. In the -adic world, the metric balls are no longer intervals, but are instead residue classes modulo some power of . Intersecting these balls from different -adic metrics together, we obtain residue classes with respect to various moduli
-adic metrics play an equally important role; indeed, it is common to unify the Archimedean and -adic perspectives together into a unified adelic perspective. In the -adic world, the metric balls are no longer intervals, but are instead residue classes modulo some power of . Intersecting these balls from different -adic metrics together, we obtain residue classes with respect to various moduli  (which may be either prime or composite). As such, another natural manifestation of the concept of “narrow support in physical space” is “vanishes on many residue classes modulo “. This notion of narrowness is particularly common in sieve theory, when one deals with functions supported on thin sets such as the primes, which naturally tend to avoid many residue classes (particularly if one throws away the first few primes).
(which may be either prime or composite). As such, another natural manifestation of the concept of “narrow support in physical space” is “vanishes on many residue classes modulo “. This notion of narrowness is particularly common in sieve theory, when one deals with functions supported on thin sets such as the primes, which naturally tend to avoid many residue classes (particularly if one throws away the first few primes).
In this context, the uncertainty principle is this: the more residue classes modulo that avoids, the more the Fourier transform must spread out along multiples of  . To illustrate a very simple example of this principle, let us take
. To illustrate a very simple example of this principle, let us take 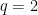 , and suppose that is supported only on odd numbers (thus it completely avoids the residue class
, and suppose that is supported only on odd numbers (thus it completely avoids the residue class 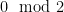 ). We write out the formulae for
). We write out the formulae for 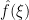 and
and 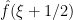 :
:
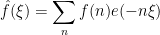
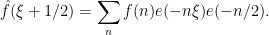
If is supported on the odd numbers, then  is always equal to
is always equal to  on the support of , and so we have
on the support of , and so we have  . Thus, whenever has a significant presence at a frequency , it also must have an equally significant presence at the frequency
. Thus, whenever has a significant presence at a frequency , it also must have an equally significant presence at the frequency 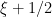 ; there is a spreading out across multiples of
; there is a spreading out across multiples of  . Note that one has a similar effect if was supported instead on the even integers instead of the odd integers.
. Note that one has a similar effect if was supported instead on the even integers instead of the odd integers.
A little more generally, suppose now that avoids a single residue class modulo a prime ; for sake of argument let us say that it avoids the zero residue class  , although the situation for the other residue classes is similar. For any frequency and any
, although the situation for the other residue classes is similar. For any frequency and any  , one has
, one has

From basic Fourier analysis, we know that the phases  sum to zero as
sum to zero as  ranges from
ranges from  to
to 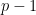 whenever
whenever  is not a multiple of . We thus have
is not a multiple of . We thus have

In particular, if is large, then one of the other  has to be somewhat large as well; using the Cauchy-Schwarz inequality, we can quantify this assertion in an
has to be somewhat large as well; using the Cauchy-Schwarz inequality, we can quantify this assertion in an  sense via the inequality
sense via the inequality

Let us continue this analysis a bit further. Now suppose that avoids 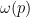 residue classes modulo a prime , for some
residue classes modulo a prime , for some 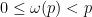 . (We exclude the case
. (We exclude the case  as it is clearly degenerates by forcing to be identically zero.) Let
as it is clearly degenerates by forcing to be identically zero.) Let 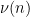 be the function that equals
be the function that equals  on these residue classes and zero away from these residue classes, then
on these residue classes and zero away from these residue classes, then

Using the periodic Fourier transform, we can write

for some coefficients 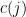 , thus
, thus
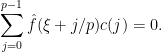
Some Fourier-analytic computations reveal that

and

and so after some routine algebra and the Cauchy-Schwarz inequality, we obtain a generalisation of (3):

Thus we see that the more residue classes mod we exclude, the more Fourier energy has to disperse along multiples of 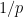 . It is also instructive to consider the extreme case
. It is also instructive to consider the extreme case 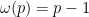 , in which is supported on just a single residue class
, in which is supported on just a single residue class 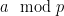 ; in this case, one clearly has
; in this case, one clearly has  , and so spreads its energy completely evenly along multiples of .
, and so spreads its energy completely evenly along multiples of .
In 1968, Montgomery observed the following useful generalisation of the above calculation to arbitrary modulus:
Proposition 1 (Montgomery’s uncertainty principle) Let  be a finitely supported function which, for each prime , avoids residue classes modulo for some . Then for each natural number , one has
be a finitely supported function which, for each prime , avoids residue classes modulo for some . Then for each natural number , one has

where  is the quantity
is the quantity

where  is the Möbius function.
is the Möbius function.
We give a proof of this proposition below the fold.
Following the “adelic” philosophy, it is natural to combine this uncertainty principle with the large sieve inequality to take simultaneous advantage of localisation both in the Archimedean sense and in the -adic senses. This leads to the following corollary:
Corollary 2 (Arithmetic large sieve inequality) Let be a function supported on an interval which, for each prime , avoids residue classes modulo for some . Let  , and let
, and let 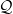 be a finite set of natural numbers. Suppose that the frequencies
be a finite set of natural numbers. Suppose that the frequencies  with
with 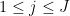 ,
, 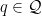 , and
, and 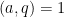 are -separated. Then one has
are -separated. Then one has
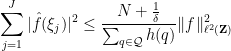
where was defined in (4).
Indeed, from the large sieve inequality one has
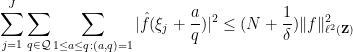
while from Proposition 1 one has

whence the claim.
There is a great deal of flexibility in the above inequality, due to the ability to select the set , the frequencies , the omitted classes , and the separation parameter . Here is a typical application concerning the original motivation for the large sieve inequality, namely in bounding the size of sets which avoid many residue classes:
Corollary 3 (Large sieve) Let  be a set of integers contained in which avoids residue classes modulo for each prime , and let
be a set of integers contained in which avoids residue classes modulo for each prime , and let  . Then
. Then

where

Proof: We apply Corollary 2 with  ,
,  ,
, 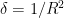 ,
, 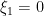 , and
, and 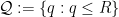 . The key point is that the Farey sequence of fractions
. The key point is that the Farey sequence of fractions 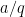 with
with  and is
and is  -separated, since
-separated, since
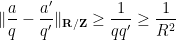
whenever  are distinct fractions in this sequence.
are distinct fractions in this sequence. 
If, for instance, is the set of all primes in larger than  , then one can set
, then one can set  for all
for all 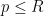 , which makes
, which makes 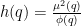 , where
, where  is the Euler totient function. It is a classical estimate that
is the Euler totient function. It is a classical estimate that

Using this fact and optimising in , we obtain (a special case of) the Brun-Titchmarsh inequality

where 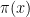 is the prime counting function; a variant of the same argument gives the more general Brun-Titchmarsh inequality
is the prime counting function; a variant of the same argument gives the more general Brun-Titchmarsh inequality

for any primitive residue class  , where
, where  is the number of primes less than or equal to
is the number of primes less than or equal to  that are congruent to . By performing a more careful optimisation using a slightly sharper version of the large sieve inequality (2) that exploits the irregular spacing of the Farey sequence, Montgomery and Vaughan were able to delete the error term in the Brun-Titchmarsh inequality, thus establishing the very nice inequality
that are congruent to . By performing a more careful optimisation using a slightly sharper version of the large sieve inequality (2) that exploits the irregular spacing of the Farey sequence, Montgomery and Vaughan were able to delete the error term in the Brun-Titchmarsh inequality, thus establishing the very nice inequality

for any natural numbers 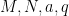 with
with  . This is a particularly useful inequality in non-asymptotic analytic number theory (when one wishes to study number theory at explicit orders of magnitude, rather than the number theory of sufficiently large numbers), due to the absence of asymptotic notation.
. This is a particularly useful inequality in non-asymptotic analytic number theory (when one wishes to study number theory at explicit orders of magnitude, rather than the number theory of sufficiently large numbers), due to the absence of asymptotic notation.
I recently realised that Corollary 2 also establishes a stronger version of the “restriction theorem for the Selberg sieve” that Ben Green and I proved some years ago (indeed, one can view Corollary 2 as a “restriction theorem for the large sieve”). I’m placing the details below the fold.
— 1. Proof of uncertainty principle —
We now prove Proposition 1. As with the case when is prime, the idea is to work by duality, testing against a suitably chosen test function  and using the Cauchy-Schwarz inequality.
and using the Cauchy-Schwarz inequality.
By replacing  with the modulated function
with the modulated function  , we may assume without loss of generality that
, we may assume without loss of generality that 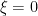 . We may of course assume that is square-free, and that
. We may of course assume that is square-free, and that 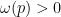 for all
for all  , since otherwise
, since otherwise  and the claim is vacuously true. Let us abbreviate the summation
and the claim is vacuously true. Let us abbreviate the summation  as
as  , thus our task is to show that
, thus our task is to show that
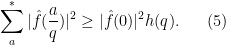
For each prime dividing , let  be the union of the residue classes modulo which avoid . It turns out that the optimal choice for is the function
be the union of the residue classes modulo which avoid . It turns out that the optimal choice for is the function

On the one hand, we see that is equal to 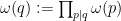 on the support of , and thus
on the support of , and thus

On the other hand, each  is mean zero and periodic of period , and thus a linear combination of phases
is mean zero and periodic of period , and thus a linear combination of phases  with
with  coprime to . Multiplying together, we conclude that
coprime to . Multiplying together, we conclude that
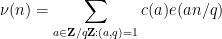
for some coefficients 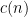 . Taking the inner product against , we conclude that
. Taking the inner product against , we conclude that

By Cauchy-Schwarz, we conclude that
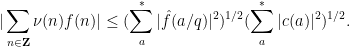
But by the Plancherel identity we have

Note that  has mean
has mean  , and so
, and so
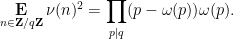
Putting everything together, we obtain (5) as required.
Remark 1 The factor of in the uncertainty principle is sharp, as can be seen by computing what happens when  .
.
— 2. Restriction theory of the large sieve —
The hypotheses of Corollary 2 are somewhat inconvenient to work with. We can specialise Corollary 2 to a more tractable version:
Theorem 4 (Special case of large sieve inequality) Let be a function supported on an interval which, for each prime , avoids residue classes modulo for some . Let , and  . Then one has
. Then one has
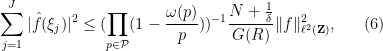
where 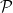 is a set of at most
is a set of at most 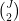 primes.
primes.
Proof: Observe that for each 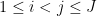 , there is at most one fraction
, there is at most one fraction  with
with 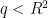 such that
such that 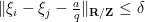 . Indeed, if there were two such fractions
. Indeed, if there were two such fractions  , then we would have
, then we would have

by the triangle inequality. On the other hand, the left-hand side is at least 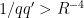 , contradicting the definition of .
, contradicting the definition of .
By selecting at most one prime for each of the pairs 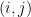 with , we may thus find a natural number
with , we may thus find a natural number  that is the product of at most primes, and with the property that
that is the product of at most primes, and with the property that

whenever , , and  . From this (and (2)) we see that
. From this (and (2)) we see that

whenever 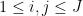 and
and 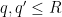 with
with  , with either
, with either 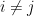 or
or  . Applying Corollary 2, we conclude that
. Applying Corollary 2, we conclude that

On the other hand, from the multiplicative (and non-negative) nature of  we have
we have

Writing as the primes dividing , we see that

The claim follows.
Suppose that  for all primes and some fixed . Then from Mertens’ theorem, we have
for all primes and some fixed . Then from Mertens’ theorem, we have

Also, one has the standard sieve theory bound
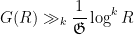
where 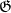 is the singular series
is the singular series

This bound can be established by a variety of techniques (e.g. by estimating the Dirichlet series  for small values of
for small values of  ), and can for instance be found in Lemma 4.1 of this text of Halberstam and Richert. Putting this together, we conclude that
), and can for instance be found in Lemma 4.1 of this text of Halberstam and Richert. Putting this together, we conclude that
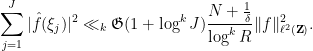
Setting 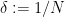 , we can simplify this a bit to
, we can simplify this a bit to

Note the very slow growth in  . It is not difficult to use this bound to obtain the
. It is not difficult to use this bound to obtain the 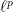 variant
variant
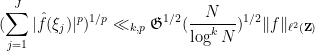
for any  and any -separated . Averaging, we obtain a restriction theorem
and any -separated . Averaging, we obtain a restriction theorem

which is essentially Proposition 4.2 of my paper with Ben Green (but with the Selberg sieve replaced by the large sieve). As such, it can be used to deduce many of the other results in that paper. For instance, one has the following strengthening of Theorem 1.1 in that paper: if is a subset of that avoids residue classes mod for each and some  , then
, then

for all . If  for some , and is sufficiently large depending on
for some , and is sufficiently large depending on  , one can then show that contains arithmetic progressions of length three by repeating the arguments in Section 6 of that paper; among other things, this reproves our result that there are infinitely many progressions of length three among the Chen primes (which arises from the two-dimensional case
, one can then show that contains arithmetic progressions of length three by repeating the arguments in Section 6 of that paper; among other things, this reproves our result that there are infinitely many progressions of length three among the Chen primes (which arises from the two-dimensional case  of the above assertion).
of the above assertion).


15 comments
Comments feed for this article
1 January, 2012 at 11:35 am
Emmanuel Kowalski
Very interesting! I’d never thought of the large sieve in these terms… I wonder how far this point of view extends to more general forms of the large sieve, especially involving non-abelian finite groups as quotients. (My current favorite proof of Prop. 1 and Cor. 3 is the amplification-based one in this paper of mine.)
Concerning the relation of the large sieve with the Selberg sieve, I think a number of people have found links in various contexts (one reference I’ve put in the paper I refer to above is to p. 125 of Halberstam and Richert). But I’ve never properly understood these relations.
P.S. A typo: there’s a missing argument (p) towards the end of section 1, in “note that …. has mean ….”
Also in the beginning of Section 1, after the definition of nu(n), I’m puzzled by what \pi_i means?
1 January, 2012 at 12:04 pm
Terence Tao
Thanks for the corrections! (The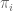 should be
should be  , but for some reason the LaTeX renderer is giving an incorrect image right now, although the ALT-text is fine.)
, but for some reason the LaTeX renderer is giving an incorrect image right now, although the ALT-text is fine.)
I think the methods in your paper are in some sense complementary to the ones in this post. In your paper you have an amplifier which is large on the sifted set, but small on average outside of it, whereas here I use weights which are small (in fact, constant) on the sifted set but large outside of it. But the numerology and formulae for the weights in the divisor sum seem to be rather similar nonetheless. (Incidentally, I arrived at these weights by performing a Selberg optimisation process similar to the one in your paper, though I didn’t present these rather tedious computations in the actual post.)
which are small (in fact, constant) on the sifted set but large outside of it. But the numerology and formulae for the weights in the divisor sum seem to be rather similar nonetheless. (Incidentally, I arrived at these weights by performing a Selberg optimisation process similar to the one in your paper, though I didn’t present these rather tedious computations in the actual post.)
3 January, 2012 at 5:39 am
valuevar
Emmanuel,
My experience of statements as to how the Selberg sieve and the large sieve are supposedly ‘dual’ is in general the same as yours. However, there seems to be some material directly relevant to this in Friedlander-Iwaniec’s new book (Opera de Cribro). Tell me if you want to take a look together.
3 January, 2012 at 8:18 am
Emmanuel Kowalski
Thanks! Indeed, there is a section 9.5 “Where Linnik meets Selberg: a duet”…. I hadn’t noticed that before so I will have a look…
3 January, 2012 at 1:54 pm
Anonymous
Hi Professor Tao, from his writings, I realized that the indeterministic has a vision, now I mean, I have carefully read the article on the uncertainty principle, and I realized that she is an indeterminate, but how? I purely mathematical proof of the ‘rise of determinism, indeterminism is the result of our ignorance because as Albert Einstein said God does not play dice, but I do not want this expression affects the interpretation of quantum mechanics as I could to prove mathematically that there is no hidden variable, possibly Einstein meant by this expression not only lack of understanding of quantum mechanics, but also the math!
6 January, 2012 at 6:06 pm
hans
What space does R/Z denote? An ordinary quotient space with the set of reals and the set of integers?
8 January, 2012 at 4:11 am
Sergey
Very interesting, thanks!
Sergey Novikov
8 January, 2012 at 7:31 am
Ghaith Hiary
The large sieve makes even more sense now, thanks!
1 February, 2012 at 8:17 am
Every odd integer larger than 1 is the sum of at most five primes « What’s new
[…] out that on this particular minor arc one can use tools from the theory of the large sieve (such as Montgomery’s uncertainty principle) to eliminate this logarithmic loss almost completely; it turns out that the most efficient way to […]
6 February, 2012 at 11:22 am
Fourteenth Linkfest
[…] Tao: Montgomery’s uncertainty principle, Random matrices: Sharp concentration of eigenvalues, Random matrices: The Universality phenomenon […]
28 April, 2012 at 1:37 pm
Mark Lewko
In the last section, do you need the more strict condition $w(p) = k$, instead of just $0 \leq w(p) \leq k$? It seems a lower bound of $k\leq w(p)$ is needed for estimate of $G(R)$ (while the upper bound of $w(p) \leq k$ is still needed to derive the $log^k(J)$ bound). Otherwise, it seems the hypothesis of the results get weaker as $k$ increases, while the estimates get stronger.
Slightly rephrasing the final result, you have obtained a sharp estimate for the $\Lambda(p)$ constant of the primes (less than $N$). This seems remarkable, considering how poor our knowledge of $\Lambda(p)$ constants for more sparse arithmetic sets are. For instance, there seems to be no Fourier analytic proof that there exists a $\Lambda(5)$ subset of $[N]$ of size $N^{1/2+\epsilon}$. However, when reading the last section it seems natural to hope that one might approach such problems by applying a similar analysis, but sieving out many more residue classes. Is it clear what goes wrong when one tries to do this? (I am aware that the $\Lambda(p)$ result for the primes was originally proved by Bourgain in connection with his work on $\Lambda(p)$ sets, so I imagine he would have done this if it did work.)
28 April, 2012 at 2:05 pm
Terence Tao
I think the lower bound on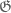 continues to work for
continues to work for  so long as one restricts the product over primes to be less than R. (Note that the factor
so long as one restricts the product over primes to be less than R. (Note that the factor 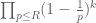 essentially cancels out the
essentially cancels out the  term by Mertens’ theorem, so the dependence on
term by Mertens’ theorem, so the dependence on  is actually somewhat illusory.)
is actually somewhat illusory.)
I’m not sure to what extent the method can be pushed to much sparser sets as you suggest, which would require k to be as large as some power of R. At this point, dependence of constants on k becomes much more important. I haven’t done any computations, but my guess is that one could only go down to sets of size or so for some small
or so for some small  (there is some work by Hamel and Laba along such lines, for instance; that work uses a sieve majorant analogous to the Selberg sieve rather than the large sieve, but I would imagine the numerology to be roughly comparable. It may be worth checking though whether large sieve ideas could improve any of the Hamel-Laba results.).
(there is some work by Hamel and Laba along such lines, for instance; that work uses a sieve majorant analogous to the Selberg sieve rather than the large sieve, but I would imagine the numerology to be roughly comparable. It may be worth checking though whether large sieve ideas could improve any of the Hamel-Laba results.).
20 May, 2012 at 2:58 pm
Heuristic limitations of the circle method « What’s new
[…] order of , which exceeds the major arc contribution of by a logarithmic factor. (One can also use Montgomery’s uncertainty principle to show that the major arc contributions are a fraction of the minor arc ones, for any reasonable […]
3 June, 2013 at 8:57 am
The prime tuples conjecture, sieve theory, and the work of Goldston-Pintz-Yildirim, Motohashi-Pintz, and Zhang | What's new
[…] than (and the large sieve inequality shows that this is sharp up to a factor of two, see e.g. this previous post for more […]
4 June, 2013 at 12:44 pm
Online reading seminar for Zhang’s “bounded gaps between primes” | What's new
[…] classical estimate of Montgomery and Vaughan tells us that we cannot make much narrower than , see this previous post for some related […]