
You are currently browsing the tag archive for the ‘determinants’ tag.
Fix a non-negative integer 
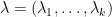
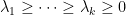




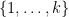

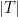
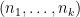
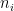

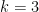


The weight here would be 
To each partition 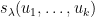
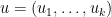

using the multinomial convention

Thus for instance the Young tableau 

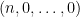

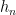


thus for instance
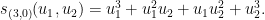
Schur polyomials are ubiquitous in the algebraic combinatorics of “type 
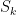

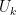
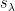

This definition of Schur polynomials allows for a way to describe the polynomials recursively. If 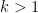


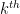

and the reduced partition 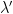


for all 



where 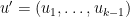


One can use this recursion (2) to prove some further standard identities for Schur polynomials, such as the determinant identity

for 
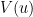


with the convention that 


We review the (standard) derivation of these identities via (2) below the fold. Among other things, these identities show that the Schur polynomials are symmetric, which is not immediately obvious from their definition.
One can also iterate (2) to write

where the sum is over all tuples 
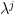



One can generalise (6) by introducing the skew Schur functions

for 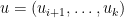



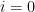

By construction, we have the decomposition
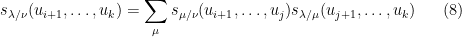
whenever 

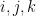
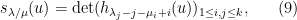
with the convention that 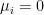
The Schur polynomials (and skew Schur polynomials) are “discretised” (or “quantised”) in the sense that their parameters 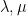
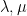
The continuous analogues can be defined as follows. Define a real partition of length 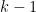
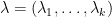
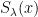
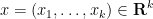
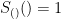

for 
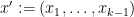

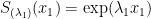
and

More generally, we can define the continuous skew Schur functions 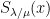


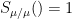
and

for 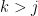
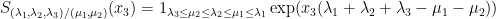
and
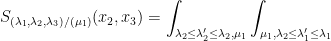

By expanding out the recursion, one obtains the analogue

of (6), and more generally one has

We will call the tuples 

where the integral is over all real partitions
By approximating various integrals by their Riemann sums, one can relate the continuous Schur functions to their discrete counterparts by the limiting formula
![\displaystyle N^{-k(k-1)/2} s_{\lfloor N \lambda \rfloor}( \exp[ x/N ] ) \rightarrow S_\lambda(x) \ \ \ \ \ (11)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++N%5E%7B-k%28k-1%29%2F2%7D+s_%7B%5Clfloor+N+%5Clambda+%5Crfloor%7D%28+%5Cexp%5B+x%2FN+%5D+%29+%5Crightarrow+S_%5Clambda%28x%29+%5C+%5C+%5C+%5C+%5C+%2811%29&bg=ffffff&fg=000000&s=0&c=20201002)
as 

and
![\displaystyle \exp[x/N] := (\exp(x_1/N), \dots, \exp(x_k/N)).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cexp%5Bx%2FN%5D+%3A%3D+%28%5Cexp%28x_1%2FN%29%2C+%5Cdots%2C+%5Cexp%28x_k%2FN%29%29.&bg=ffffff&fg=000000&s=0&c=20201002)
More generally, one has
![\displaystyle N^{j(j-1)/2-k(k-1)/2} s_{\lfloor N \lambda \rfloor / \lfloor N \mu \rfloor}( \exp[ x/N ] ) \rightarrow S_{\lambda/\mu}(x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++N%5E%7Bj%28j-1%29%2F2-k%28k-1%29%2F2%7D+s_%7B%5Clfloor+N+%5Clambda+%5Crfloor+%2F+%5Clfloor+N+%5Cmu+%5Crfloor%7D%28+%5Cexp%5B+x%2FN+%5D+%29+%5Crightarrow+S_%7B%5Clambda%2F%5Cmu%7D%28x%29&bg=ffffff&fg=000000&s=0&c=20201002)
as 
As a consequence of these limiting formulae, one expects all of the discrete identities above to have continuous counterparts. This is indeed the case; below the fold we shall prove the discrete and continuous identities in parallel. These are not new results by any means, but I was not able to locate a good place in the literature where they are explicitly written down, so I thought I would try to do so here (primarily for my own internal reference, but perhaps the calculations will be worthwhile to some others also).
The determinant 
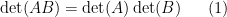
whenever 
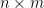

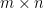





This identity, which converts an 
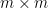

Another identity generated from (1) arises when trying to compute the determinant of a 
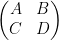
where 

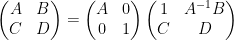

and on taking determinants using (1) we obtain the Schur determinant identity
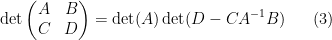
relating the determinant of a block-diagonal matrix with the determinant of the Schur complement 
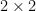

It is also possible to use determinant identities to deduce other matrix identities that do not involve the determinant, by the technique of matrix differentiation (or equivalently, matrix linearisation). The key observation is that near the identity, the determinant behaves like the trace, or more precisely one has
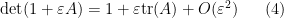
for any bounded square matrix 
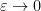

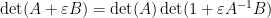
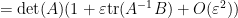
for infinitesimal 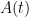

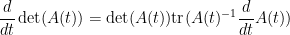
whenever
Let us see some examples of this differentiation method. If we take the Weinstein-Aronszajn identity (2) and multiply one of the rectangular matrices
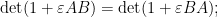
applying (4) and extracting the linear term in 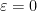
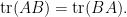
To manipulate derivatives and inverses, we begin with the Neumann series approximation
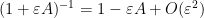
for bounded square
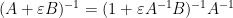
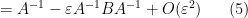
for square matrices 

whenever
We can then differentiate (or linearise) the Schur identity (3) in a number of ways. For instance, if we replace the lower block 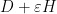


while the right-hand side becomes

extracting the linear term in
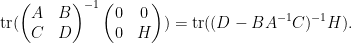
As 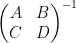
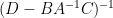

One can also compute the other components of this inverse in terms of the Schur complement 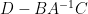
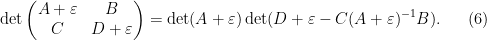
By (4), the left-hand side is
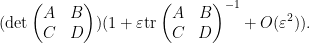
From (5), we have

and so from (4) the right-hand side of (6) is
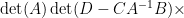
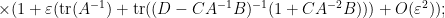
extracting the linear component in
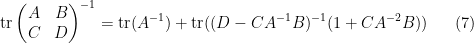
which relates the trace of the inverse of a block matrix, with the trace of the inverse of one of its blocks. This particular identity turns out to be useful in random matrix theory; I hope to elaborate on this in a later post.
As a final example of this method, we can analyse low rank perturbations 
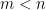
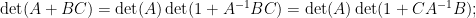
if one then perturbs 

Extracting the linear component in

assuming that
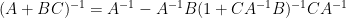
for the inverse of a low rank perturbation
Exercise 1 Use the “determinant first” approach to derive the Woodbury matrix identity (also known as the binomial inverse theorem)
where
are all invertible.

Exercise 2 Let
and differentiate this in
(assuming that all inverses exist) and thence
Rotating
which is useful for inverting a matrix
that has been split into a self-adjoint component
.


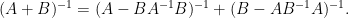
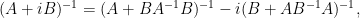
Van Vu and I have just uploaded to the arXiv our paper “Random matrices: Universality of local spectral statistics of non-Hermitian matrices“. The main result of this paper is a “Four Moment Theorem” that establishes universality for local spectral statistics of non-Hermitian matrices with independent entries, under the additional hypotheses that the entries of the matrix decay exponentially, and match moments with either the real or complex gaussian ensemble to fourth order. This is the non-Hermitian analogue of a long string of recent results establishing universality of local statistics in the Hermitian case (as discussed for instance in this recent survey of Van and myself, and also in several other places).
The complex case is somewhat easier to describe. Given a (non-Hermitian) random matrix ensemble 
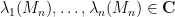
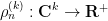


In the case when 
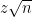

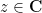

for 

for 


(There is also an asymptotic for the boundary case 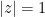


Our first main result is that the asymptotic (1) for 

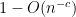

There are several steps involved in the proof. The first step is to apply the Girko Hermitisation trick to replace the problem of understanding the spectrum of a non-Hermitian matrix, with that of understanding the spectrum of various Hermitian matrices. The two identities that realise this trick are, firstly, Jensen’s formula

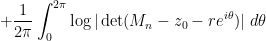
that relates the local distribution of eigenvalues to the log-determinants 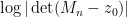

that relates the log-determinants of 

The main difficulty is then to obtain concentration and universality results for the Hermitian log-determinants 
The matrices 
While this result is the first local universality result in the category of random matrices with independent entries, there are still two limitations to the result which one would like to remove. The first is the moment matching hypotheses on the matrix. Very recently, one of the ingredients of our paper, namely the local circular law, was proved without moment matching hypotheses by Bourgade, Yau, and Yin (provided one stays away from the edge of the spectrum); however, as of this time of writing the other main ingredient – the universality of the log-determinant – still requires moment matching. (The standard tool for obtaining universality without moment matching hypotheses is the heat flow method (and more specifically, the local relaxation flow method), but the analogue of Dyson Brownian motion in the non-Hermitian setting appears to be somewhat intractible, being a coupled flow on both the eigenvalues and eigenvectors rather than just on the eigenvalues alone.)
My colleague Ricardo Pérez-Marco showed me a very cute proof of Pythagoras’ theorem, which I thought I would share here; it’s not particularly earth-shattering, but it is perhaps the most intuitive proof of the theorem that I have seen yet.

In the above diagram, a, b, c are the lengths BC, CA, and AB of the right-angled triangle ACB, while x and y are the areas of the right-angled triangles CDB and ADC respectively. Thus the whole triangle ACB has area x+y.
Now observe that the right-angled triangles CDB, ADC, and ACB are all similar (because of all the common angles), and thus their areas are proportional to the square of their respective hypotenuses. In other words, (x,y,x+y) is proportional to 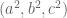

Recent Comments