Ben Green and I have just uploaded to the arXiv our paper “New bounds for Szemeredi’s theorem, Ia: Progressions of length 4 in finite field geometries revisited“, submitted to Proc. Lond. Math. Soc.. This is both an erratum to, and a replacement for, our previous paper “New bounds for Szemeredi’s theorem. I. Progressions of length 4 in finite field geometries“. The main objective in both papers is to bound the quantity  for a vector space
for a vector space 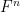 over a finite field
over a finite field  of characteristic greater than
of characteristic greater than  , where is defined as the cardinality of the largest subset of that does not contain an arithmetic progression of length . In our earlier paper, we gave two arguments that bounded in the regime when the field was fixed and
, where is defined as the cardinality of the largest subset of that does not contain an arithmetic progression of length . In our earlier paper, we gave two arguments that bounded in the regime when the field was fixed and  was large. The first “cheap” argument gave the bound
was large. The first “cheap” argument gave the bound

and the more complicated “expensive” argument gave the improvement

for some constant  depending only on .
depending only on .
Unfortunately, while the cheap argument is correct, we discovered a subtle but serious gap in our expensive argument in the original paper. Roughly speaking, the strategy in that argument is to employ the density increment method: one begins with a large subset  of that has no arithmetic progressions of length , and seeks to locate a subspace on which has a significantly increased density. Then, by using a “Koopman-von Neumann theorem”, ultimately based on an iteration of the inverse
of that has no arithmetic progressions of length , and seeks to locate a subspace on which has a significantly increased density. Then, by using a “Koopman-von Neumann theorem”, ultimately based on an iteration of the inverse 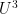 theorem of Ben and myself (and also independently by Samorodnitsky), one approximates by a “quadratically structured” function
theorem of Ben and myself (and also independently by Samorodnitsky), one approximates by a “quadratically structured” function  , which is (locally) a combination of a bounded number of quadratic phase functions, which one can prepare to be in a certain “locally equidistributed” or “locally high rank” form. (It is this reduction to the high rank case that distinguishes the “expensive” argument from the “cheap” one.) Because has no progressions of length , the count of progressions of length weighted by will also be small; by combining this with the theory of equidistribution of quadratic phase functions, one can then conclude that there will be a subspace on which has increased density.
, which is (locally) a combination of a bounded number of quadratic phase functions, which one can prepare to be in a certain “locally equidistributed” or “locally high rank” form. (It is this reduction to the high rank case that distinguishes the “expensive” argument from the “cheap” one.) Because has no progressions of length , the count of progressions of length weighted by will also be small; by combining this with the theory of equidistribution of quadratic phase functions, one can then conclude that there will be a subspace on which has increased density.
The error in the paper was to conclude from this that the original function 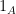 also had increased density on the same subspace; it turns out that the manner in which approximates is not strong enough to deduce this latter conclusion from the former. (One can strengthen the nature of approximation until one restores such a conclusion, but only at the price of deteriorating the quantitative bounds on one gets at the end of the day to be worse than the cheap argument.)
also had increased density on the same subspace; it turns out that the manner in which approximates is not strong enough to deduce this latter conclusion from the former. (One can strengthen the nature of approximation until one restores such a conclusion, but only at the price of deteriorating the quantitative bounds on one gets at the end of the day to be worse than the cheap argument.)
After trying unsuccessfully to repair this error, we eventually found an alternate argument, based on earlier papers of ourselves and of Bergelson-Host-Kra, that avoided the density increment method entirely and ended up giving a simpler proof of a stronger result than (1), and also gives the explicit value of 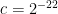 for the exponent
for the exponent  in (1). In fact, it gives the following stronger result:
in (1). In fact, it gives the following stronger result:
Theorem 1 Let be a subset of of density at least  , and let
, and let  . Then there is a subspace
. Then there is a subspace  of of codimension
of of codimension  such that the number of (possibly degenerate) progressions
such that the number of (possibly degenerate) progressions 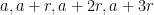 in
in 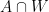 is at least
is at least 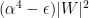 .
.
The bound (1) is an easy consequence of this theorem after choosing  and removing the degenerate progressions from the conclusion of the theorem.
and removing the degenerate progressions from the conclusion of the theorem.
The main new idea is to work with a local Koopman-von Neumann theorem rather than a global one, trading a relatively weak global approximation to with a significantly stronger local approximation to on a subspace . This is somewhat analogous to how sometimes in graph theory it is more efficient (from the point of view of quantative estimates) to work with a local version of the Szemerédi regularity lemma which gives just a single regular pair of cells, rather than attempting to regularise almost all of the cells. This local approach is well adapted to the inverse theorem we use (which also has this local aspect), and also makes the reduction to the high rank case much cleaner. At the end of the day, one ends up with a fairly large subspace on which is quite dense (of density  ) and which can be well approximated by a “pure quadratic” object, namely a function of a small number of quadratic phases obeying a high rank condition. One can then exploit a special positivity property of the count of length four progressions weighted by pure quadratic objects, essentially due to Bergelson-Host-Kra, which then gives the required lower bound.
) and which can be well approximated by a “pure quadratic” object, namely a function of a small number of quadratic phases obeying a high rank condition. One can then exploit a special positivity property of the count of length four progressions weighted by pure quadratic objects, essentially due to Bergelson-Host-Kra, which then gives the required lower bound.


7 comments
Comments feed for this article
9 May, 2012 at 7:22 am
magnus carlsen
Dear Terry,
you should add in your references that the paper “New bounds on cap sets” (reference number 1)
is published in the journal of the AMS
[Will do, thanks – T.]
11 May, 2012 at 9:21 am
Anonymous
You could help young mathematicians by posting the referee report for the original paper along with the story behind the discovery of the gap in the proof of the main result.
28 May, 2012 at 10:11 am
reader
Sanders’ paper [13] has been published: MR 2012f:11019. So has Tao & Ziegler [16]: doi:10.1007/s00026-011-0124-3.
[Thanks, this will be added to the next revision of the ms. -T.]
23 May, 2024 at 8:47 pm
Anonymous
Despite being almost trivial linear algebra, I’m struggling a bit to understand your proof of Lemma 4.7, and was hoping you could give a few words of clarification. In particular, should there be a hypothesis that of quadratic functions that define the quadratic factor in the hypothesis have sufficiently large rank? You run what you call the “rank reduction process” until the rank of various linear combinations of the quadratic factors exceed r + d. At each stage you reduce the number of quadratic functions. You conclude that this must stop before you run out of quadratic functions. But I don’t see why this ensures you find a subset with high rank. Couldn’t you just continue until you get down to one quadratic function which has rank less than r+d? More succinctly, I don’t see how the argument works if you start with a factor defined by a single quadratic function, and seek a local quadratic factor with a higher rank.
This isn’t particularly relevant to the question, but I’m also not sure why you call the process of locating a factor with higher rank the “rank reduction process”.
24 May, 2024 at 2:45 pm
Terence Tao
It is quite permissible to end up with 0 quadratic polynomials at the final stage of the algorithm, in which case it will be of rank at least for any
for any  .
.
I realize that when referring to this argument as a “rank reduction” argument we were using a different application of the concept of rank which in this context is quite confusing. In linear algebra, when one has a collection of vectors , the rank of the collection is sometimes defined to be the dimension of the linear space spanned by those vectors (or the rank of the matrix which contains the coordinates of these vectors as the rows). It is the span of the quadratic component of the factor that is being reduced by this algorithm; but of course we are using rank for another purpose in this argument. “quadratic complexity reduction process” may be a more appropriate term here.
, the rank of the collection is sometimes defined to be the dimension of the linear space spanned by those vectors (or the rank of the matrix which contains the coordinates of these vectors as the rows). It is the span of the quadratic component of the factor that is being reduced by this algorithm; but of course we are using rank for another purpose in this argument. “quadratic complexity reduction process” may be a more appropriate term here.
24 May, 2024 at 4:47 pm
Anonymous
I’m surely missing something here. Say that phi is defined by a full rank 100 by 100 matrix. Now rank( lambda phi) = 100 for all lambda neq 0. If I understand the algorithm (which it seems I do not), then the next stage is to restrict to the kernel of phi, which is just the trivial zero dimensional space. In what sense is this, say, rank > 1000?
25 May, 2024 at 7:11 am
Terence Tao
From Definition 4.4, A collection of quadratic forms will automatically have rank at least
of quadratic forms will automatically have rank at least  for any
for any  if one has
if one has 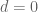 ; this is an example of a vacuously true statement, since in this case there are no non-trivial linear combinations of the
; this is an example of a vacuously true statement, since in this case there are no non-trivial linear combinations of the  to be tested.
to be tested.