
It is also good to keep in mind that no author is infallible, and that in some cases, the simplest explanation for incomprehension is that there is a typo in the text. For instance, suppose a paper states that “Since 

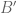

In a similar spirit, if the paper contains a cryptic comment which you didn’t quite understand, but chose to ignore in order to move on, and then two lines later you find a deduction of a conclusion which you don’t see to be a consequence of the previous statements, then one should go back to the cryptic comment and parse it very carefully, as it is likely to be a description of the missing hypothesis or technique needed to reach the stated conclusion.
Sometimes one has to look for the absence of key words, rather than their presence. Suppose for instance the statement
Another useful trick is to “project” the paper down to a simpler and shorter paper by restricting attention to a simpler special case, or by adopting some heuristic that allows one to trivialise some technical portions of the paper (or at least make some steps of the paper plausible enough to the reader that one is willing to skip over the details of proof for those steps). For instance, if the paper is dealing with a result in general dimension, one might first specialise the paper to one dimension (even if this means that the main results are no longer new, but consequences of previous literature). Or, if the paper has to analyse both the main term in an expression as well as error terms, one can adopt the heuristic that all error terms are negligible and only focus on the main term (or dually, one can accept that the main term is always going to compute out to the correct answer, and only focus on controlling error terms). If one is aware of a near-counterexample to the main result, specialising the paper to that near-counterexample (or to a hypothetical perturbation of that near-counterexample that is trying to be a genuine counterexample) is often quite instructive. Ideally, one should project away roughly half of the difficulties of the paper, leaving behind a paper which is twice as simple, and thus presumably much easier to understand; once this is done, one can undo the projection, and return to the original paper, which is now already half understood, and again much easier to understand than before one understood the projected paper. (The difficulty of reading a paper usually increases in a super-linear fashion with the complexity of the paper, so factoring the paper into two sub-papers, each with half the complexity, is often an efficient way to proceed.)
Finally, and perhaps most importantly, reading becomes much easier when one can somehow “get into the author’s head”, and get a sense of what the author is trying to do with each statement or lemma in the paper, rather than focusing purely on the literal statements in the text. A good author will interleave the mathematical text with commentary that is designed to do exactly this, but even without such explicit clues, one can often get a sense of the purpose of each component of the paper by comparing it with similar components in other papers, or by seeing how such a component is used in the rest of the paper. In extreme cases, one may have to go to a large blackboard and diagram all the logical dependencies of a paper (e.g. if Lemma 6 and Lemma 8 are used to prove Theorem 10, one can draw arrows between boxes bearing these names accordingly) to get some sense of what the key steps in the paper are.
For some further principles on how to justify a particularly fearsome looking step in a paper, see this MathOverflow answer of mine.
For an analogous technique in the dual problem of writing a paper, see this page.

1 comment
Comments feed for this article
5 April, 2024 at 12:34 am
lackhoa
Can you read math papers without essentially rewriting the whole paper in a your familiar notations? I find that it is impossible for me to comprehend papers if I just *look* at the text without doing anything.