
You are currently browsing the tag archive for the ‘Gelfand-Naimark-Segal construction’ tag.
As laid out in the foundational work of Kolmogorov, a classical probability space (or probability space for short) is a triplet 

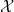

![{\mu: {\mathcal X} \rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7B%5Cmu%3A+%7B%5Cmathcal+X%7D+%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
- the (real) Hilbert space
of square-integrable functions
, modulo
-almost everywhere equivalence, and with the positive definite inner product
; and
- the unital commutative Banach algebra
of essentially bounded functions
defined as the essential supremum of
.
There is also a trace 

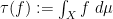
One can form the category 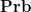

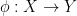

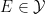
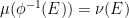
Let us now abstract the algebraic features of these spaces as follows; for want of a better name, I will refer to this abstraction as an algebraic probability space, and is very similar to the non-commutative probability spaces studied in this previous post, except that these spaces are now commutative (and real).
Definition 1 An algebraic probability space is a pair
where
is a unital commutative real algebra;
is a homomorphism such that
and
for all
;
- Every element
of
. (Technically, this isn’t an algebraic property, but I need it for technical reasons.)
A morphism
is a homomorphism
which is trace-preserving, in the sense that
for all
.
For want of a better name, I’ll denote the category of algebraic probability spaces as 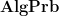
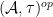
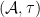

By the previous discussion, we have a covariant functor 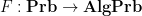
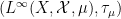
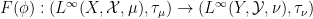
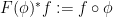
for 
In this post I would like to describe a functor 


Let us describe how to construct the functor
- Starting with an algebraic probability space
, and also form the spectral radius
.
- The inner product is clearly positive semi-definite. Quotienting out the null vectors and taking completions, we arrive at a real Hilbert space
, to which the trace
may be extended.
- Somewhat less obviously, the spectral radius is well-defined and gives a norm on
limits of sequences in
of
- The idempotents
of the Banach algebra
of an abstract
.
- The Boolean algebra homomorphisms
(or equivalently, the real algebra homomorphisms
) may be indexed by elements
of a space
- Let
for every
.
- Let
be the
, where
is a sequence with
.
- One verifies that
. Using this isomorphism, the trace
, and the abstract spaces
may now be identified with their concrete counterparts
- Every algebraic probability space morphism
generates a classical probability morphism
via the formula
using a pullback operation
on the abstract
that can be defined by density.
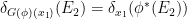
Remark 1 The classical probability space
The partial inversion relationship between the functors
- There is a natural transformation from
to the identity functor
.
More informally: if one starts with an algebraic probability space 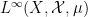
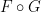

Remark 2 The opposite composition
is a little odd: it takes an arbitrary probability space
, with
being the space of homomorphisms
. while there is “morally” an embedding of
,
, then these algebras become naturally isomorphic after quotienting out by null sets.
Remark 3 An algebraic probability space captures a bit more structure than a classical probability space, because
(with the usual Haar measure and the usual trace
), any unital subalgebra
that is dense in
will generate the same classical probability space
of homomorphisms from
(with the measure induced from
, the Wiener algebra
or the full space
of continuous functions on a topological space. I hope to discuss one such example of extra structure (coming from the Gowers-Host-Kra theory of uniformity seminorms) in a later blog post (this generalises the example of the Wiener algebra given previously, which is encoding “Fourier structure”).
A small example of how one could use the functors 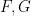

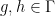
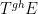

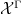
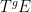
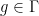
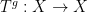



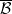
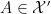
More indirectly, the functors

Recent Comments