Hariharan Narayanan, Scott Sheffield, and I have just uploaded to the arXiv our paper “Sums of GUE matrices and concentration of hives from correlation decay of eigengaps“. This is a personally satisfying paper for me, as it connects the work I did as a graduate student (with Allen Knutson and Chris Woodward) on sums of Hermitian matrices, with more recent work I did (with Van Vu) on random matrix theory, as well as several other results by other authors scattered across various mathematical subfields.
Suppose  are two
are two  Hermitian matrices with eigenvalues
Hermitian matrices with eigenvalues 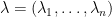 and
and 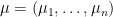 respectively (arranged in non-increasing order. What can one say about the eigenvalues
respectively (arranged in non-increasing order. What can one say about the eigenvalues 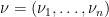 of the sum
of the sum 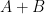 ? There are now many ways to answer this question precisely; one of them, introduced by Allen and myself many years ago, is that there exists a certain triangular array of numbers called a “hive” that has
? There are now many ways to answer this question precisely; one of them, introduced by Allen and myself many years ago, is that there exists a certain triangular array of numbers called a “hive” that has 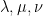 as its boundary values. On the other hand, by the pioneering work of Voiculescu in free probability, we know in the large
as its boundary values. On the other hand, by the pioneering work of Voiculescu in free probability, we know in the large  limit that if
limit that if 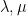 are asymptotically drawn from some limiting distribution, and
are asymptotically drawn from some limiting distribution, and  and
and  are drawn independently at random (using the unitarily invariant Haar measure) amongst all Hermitian matrices with the indicated eigenvalues, then (under mild hypotheses on the distribution, and under suitable normalization),
are drawn independently at random (using the unitarily invariant Haar measure) amongst all Hermitian matrices with the indicated eigenvalues, then (under mild hypotheses on the distribution, and under suitable normalization),  will almost surely have a limiting distribution that is the free convolution of the two original distributions.
will almost surely have a limiting distribution that is the free convolution of the two original distributions.
One of my favourite open problems is to come up with a theory of “free hives” that allows one to explain the latter fact from the former. This is still unresolved, but we are now beginning to make a bit of progress towards this goal. We know (for instance from the calculations of Coquereaux and Zuber) that if are drawn independently at random with eigenvalues , then the eigenvalues of are distributed according to the boundary values of an “augmented hive” with two boundaries 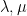 , drawn uniformly at random from the polytope of all such augmented hives. (This augmented hive is basically a regular hive with another type of pattern, namely a Gelfand-Tsetlin pattern, glued to one side of it.) So, if one could show some sort of concentration of measure for the entries of this augmented hive, and calculate what these entries concentrated to, one should presumably be able to recover Voiculescu’s result after some calculation.
, drawn uniformly at random from the polytope of all such augmented hives. (This augmented hive is basically a regular hive with another type of pattern, namely a Gelfand-Tsetlin pattern, glued to one side of it.) So, if one could show some sort of concentration of measure for the entries of this augmented hive, and calculate what these entries concentrated to, one should presumably be able to recover Voiculescu’s result after some calculation.
In this paper, we are able to accomplish the first half of this goal, assuming that the spectra are not deterministic, but rather drawn from the spectra of rescaled GUE matrices (thus  are independent rescaled copies of the GUE ensemble). We have chosen to normalize matters so that the eigenvalues have size
are independent rescaled copies of the GUE ensemble). We have chosen to normalize matters so that the eigenvalues have size  , so that the entries of the augmented hive have entries
, so that the entries of the augmented hive have entries 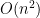 . Our result is then that the entries of the augmented hive in fact have a standard deviation of
. Our result is then that the entries of the augmented hive in fact have a standard deviation of 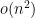 , thus exhibiting a little bit of concentration. (Actually, from the Brunn-Minkowski inequality, the distribution of these entries is log concave, so once once controls the standard deviation one also gets a bit of exponential decay beyond the standard deviation; Narayanan and Sheffield had also recently established the existence of a rate function for this sort of model.) Presumably one should get much better concentration, and one should be able to handle other models than the GUE ensemble, but this is the first advance that we were able to achieve.
, thus exhibiting a little bit of concentration. (Actually, from the Brunn-Minkowski inequality, the distribution of these entries is log concave, so once once controls the standard deviation one also gets a bit of exponential decay beyond the standard deviation; Narayanan and Sheffield had also recently established the existence of a rate function for this sort of model.) Presumably one should get much better concentration, and one should be able to handle other models than the GUE ensemble, but this is the first advance that we were able to achieve.
Augmented hives seem tricky to work with directly, but by adapting the octahedron recurrence introduced for this problem by Knutson, Woodward, and myself some time ago (which is related to the associativity 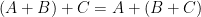 of addition for Hermitian matrices), one can construct a piecewise linear volume-preserving map between the cone of augmented hives, and the product of two Gelfand-Tsetlin cones. The problem then reduces to establishing concentration of measure for certain piecewise linear maps on products of Gelfand-Tsetlin cones (endowed with a certain GUE-type measure). This is a promising formulation because Gelfand-Tsetlin cones are by now quite well understood.
of addition for Hermitian matrices), one can construct a piecewise linear volume-preserving map between the cone of augmented hives, and the product of two Gelfand-Tsetlin cones. The problem then reduces to establishing concentration of measure for certain piecewise linear maps on products of Gelfand-Tsetlin cones (endowed with a certain GUE-type measure). This is a promising formulation because Gelfand-Tsetlin cones are by now quite well understood.
On the other hand, the piecewise linear map, initially defined by iterating the octahedron relation  , looks somewhat daunting. Fortunately, there is an explicit formulation of this map due to Speyer, as the supremum of certain linear maps associated to perfect matchings of a certain “excavation graph”. For us it was convenient to work with the dual of this excavation graph, and associate these linear maps to certain “lozenge tilings” of a hexagon.
, looks somewhat daunting. Fortunately, there is an explicit formulation of this map due to Speyer, as the supremum of certain linear maps associated to perfect matchings of a certain “excavation graph”. For us it was convenient to work with the dual of this excavation graph, and associate these linear maps to certain “lozenge tilings” of a hexagon.
It would be more convenient to study the concentration of each linear map separately, rather than their supremum. By the Cheeger inequality, it turns out that one can relate the latter to the former provided that one has good control on the Cheeger constant of the underlying measure on the Gelfand-Tsetlin cones. Fortunately, the measure is log-concave, so one can use the very recent work of Klartag on the KLS conjecture to eliminate the supremum (up to a logarithmic loss which is only moderately annoying to deal with).
It remains to obtain concentration on the linear map associated to a given lozenge tiling. After stripping away some contributions coming from lozenges near the edge (using some eigenvalue rigidity results of Van Vu and myself), one is left with some bulk contributions which ultimately involve eigenvalue interlacing gaps such as
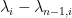
where

is the

eigenvalue of the top left
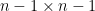
minor of
, and

is in the bulk region

for some fixed

. To get the desired result, one needs some non-trivial correlation decay in
for these statistics. If one was working with eigenvalue gaps
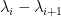
rather than interlacing results, then such correlation decay was conveniently obtained for us by
recent work of Cippoloni, Erdös, and Schröder. So the last remaining challenge is to understand the relation between eigenvalue gaps and interlacing gaps.
For this we turned to the work of Metcalfe, who uncovered a determinantal process structure to this problem, with a kernel associated to Lagrange interpolation polynomials. It is possible to satisfactorily estimate various integrals of these kernels using the residue theorem and eigenvalue rigidity estimates, thus completing the required analysis.


Recent Comments