
You are currently browsing the tag archive for the ‘Hooley Delta function’ tag.
Kevin Ford, Dimitris Koukoulopoulos and I have just uploaded to the arXiv our paper “A lower bound on the mean value of the Erdős-Hooley delta function“. This paper complements the recent paper of Dimitris and myself obtaining the upper bound


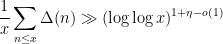
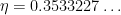 is an exponent that arose in previous work of result of Ford, Green, and Koukoulopoulos, who showed that
is an exponent that arose in previous work of result of Ford, Green, and Koukoulopoulos, who showed that 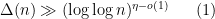
 outside of a set of density zero. The previous best known lower bound for the mean value was
outside of a set of density zero. The previous best known lower bound for the mean value was 
The point is the main contributions to the mean value of 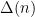

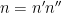
 is the product of primes between some intermediate threshold
is the product of primes between some intermediate threshold 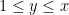 and and behaves “typically” (so in particular, it has about
and and behaves “typically” (so in particular, it has about  prime factors, as per the Hardy-Ramanujan law and the Erdős-Kac law, but
prime factors, as per the Hardy-Ramanujan law and the Erdős-Kac law, but 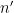 is the product of primes up to
is the product of primes up to  and has double the number of typical prime factors –
and has double the number of typical prime factors –  , rather than
, rather than  – thus is the type of number that would make a significant contribution to the mean value of the divisor function
– thus is the type of number that would make a significant contribution to the mean value of the divisor function  . Here is such that
. Here is such that  is an integer in the range
is an integer in the range 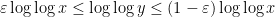
 there are basically
there are basically 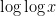 different values of give essentially disjoint contributions. From the easy inequalities
different values of give essentially disjoint contributions. From the easy inequalities 
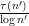 has mean about one, one would expect to get the above result provided that one could get a lower bound of the form
has mean about one, one would expect to get the above result provided that one could get a lower bound of the form 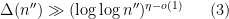 with prime factors between and . Unfortunately, due to the lack of small prime factors in , the arguments of Ford, Green, Koukoulopoulos that give (1) for typical do not quite work for the rougher numbers . However, it turns out that one can get around this problem by replacing (2) by the more efficient inequality
with prime factors between and . Unfortunately, due to the lack of small prime factors in , the arguments of Ford, Green, Koukoulopoulos that give (1) for typical do not quite work for the rougher numbers . However, it turns out that one can get around this problem by replacing (2) by the more efficient inequality 

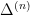 when
when 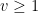 . This inequality is easily proven by applying the pigeonhole principle to the factors of of the form
. This inequality is easily proven by applying the pigeonhole principle to the factors of of the form 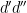 , where
, where 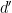 is one of the
is one of the  factors of , and
factors of , and  is one of the
is one of the 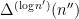 factors of in the optimal interval
factors of in the optimal interval ![{[e^u, e^{u+\log n'}]}](https://s0.wp.com/latex.php?latex=%7B%5Be%5Eu%2C+e%5E%7Bu%2B%5Clog+n%27%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . The extra room provided by the enlargement of the range
. The extra room provided by the enlargement of the range ![{[e^u, e^{u+1}]}](https://s0.wp.com/latex.php?latex=%7B%5Be%5Eu%2C+e%5E%7Bu%2B1%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) to turns out to be sufficient to adapt the Ford-Green-Koukoulopoulos argument to the rough setting. In fact we are able to use the main technical estimate from that paper as a “black box”, namely that if one considers a random subset
to turns out to be sufficient to adapt the Ford-Green-Koukoulopoulos argument to the rough setting. In fact we are able to use the main technical estimate from that paper as a “black box”, namely that if one considers a random subset  of
of ![{[D^c, D]}](https://s0.wp.com/latex.php?latex=%7B%5BD%5Ec%2C+D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) for some small
for some small  and sufficiently large
and sufficiently large  with each
with each ![{n \in [D^c, D]}](https://s0.wp.com/latex.php?latex=%7Bn+%5Cin+%5BD%5Ec%2C+D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) lying in with an independent probability
lying in with an independent probability 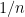 , then with high probability there should be
, then with high probability there should be  subset sums of that attain the same value. (Initially, what “high probability” means is just “close to
subset sums of that attain the same value. (Initially, what “high probability” means is just “close to  “, but one can reduce the failure probability significantly as
“, but one can reduce the failure probability significantly as  by a “tensor power trick” taking advantage of Bennett’s inequality.)
by a “tensor power trick” taking advantage of Bennett’s inequality.)
Dimitris Koukoulopoulos and I have just uploaded to the arXiv our paper “An upper bound on the mean value of the Erdős-Hooley delta function“. This paper concerns a (still somewhat poorly understood) basic arithmetic function in multiplicative number theory, namely the Erdos-Hooley delta function
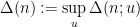

 measures the extent to which the divisors of a natural number can be concentrated in a dyadic (or more precisely,
measures the extent to which the divisors of a natural number can be concentrated in a dyadic (or more precisely,  -dyadic) interval
-dyadic) interval ![{(e^u, e^{u+1}]}](https://s0.wp.com/latex.php?latex=%7B%28e%5Eu%2C+e%5E%7Bu%2B1%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . From the pigeonhole principle, we have the bounds
. From the pigeonhole principle, we have the bounds 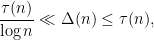
 is the usual divisor function. The statistical behavior of the divisor function is well understood; for instance, if is drawn at random from to , then the mean value of
is the usual divisor function. The statistical behavior of the divisor function is well understood; for instance, if is drawn at random from to , then the mean value of 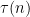 is roughly
is roughly 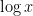 , the median is roughly
, the median is roughly 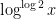 , and (by the Erdős-Kac theorem) asymptotically has a log-normal distribution. In particular, there are a small proportion of highly divisible numbers that skew the mean to be significantly higher than the median.
, and (by the Erdős-Kac theorem) asymptotically has a log-normal distribution. In particular, there are a small proportion of highly divisible numbers that skew the mean to be significantly higher than the median.
On the other hand, the statistical behavior of the Erdős-Hooley delta function is significantly less well understood, even conjecturally. Again drawing 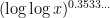
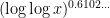


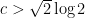 , with the lower bound due to Hall and Tenenbaum, and the upper bound a recent result of La Bretèche and Tenenbaum.
, with the lower bound due to Hall and Tenenbaum, and the upper bound a recent result of La Bretèche and Tenenbaum.
The main result of this paper is an improvement of the upper bound to
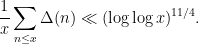
The reason we looked into this problem was that it was connected to forthcoming work of David Conlon, Jacob Fox, and Huy Pham on the following problem of Erdos: what is the size of the largest subset 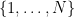


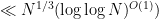
Let me now discuss some of the ingredients of the proof. The first few steps are standard. Firstly we may restrict attention to square-free numbers without much difficulty (the point being that if a number 


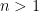



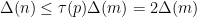


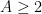 , we have a bound
, we have a bound 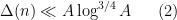
 which is small in the sense that
which is small in the sense that 
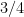 to
to 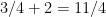 ).
).
To get some intuition on the size of 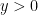

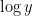
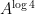

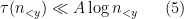
At this point we perform another standard technique, namely the moment method of controlling the supremum 
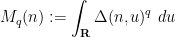
 ; it is not difficult to establish the bound
; it is not difficult to establish the bound 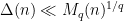
 . We will be able to show a moment bound
. We will be able to show a moment bound 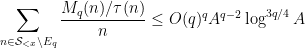
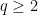 for some exceptional set
for some exceptional set  obeying the smallness condition (3) (actually, for technical reasons we need to improve the right-hand side slightly to close an induction on ); this will imply the distributional bound (2) from a standard Markov inequality argument (setting ).
obeying the smallness condition (3) (actually, for technical reasons we need to improve the right-hand side slightly to close an induction on ); this will imply the distributional bound (2) from a standard Markov inequality argument (setting ).
The strategy is then to obtain a good recursive inequality for (averages of) 
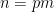
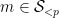
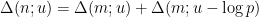
 ; taking moments, one obtains the identity
; taking moments, one obtains the identity  here and apply Hölder’s inequality. But it convenient to first use the symmetry of the summand in
here and apply Hölder’s inequality. But it convenient to first use the symmetry of the summand in  to reduce to the case of relatively small values of
to reduce to the case of relatively small values of  :
: 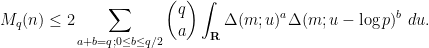
 term as
term as 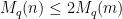
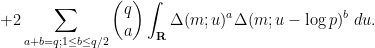
 by dividing out by the divisor function:
by dividing out by the divisor function: 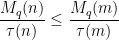
 and . After some standard manipulations (using the Brun–Titchmarsh and Hölder inequalities), one is able to estimate sums such as
and . After some standard manipulations (using the Brun–Titchmarsh and Hölder inequalities), one is able to estimate sums such as 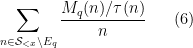
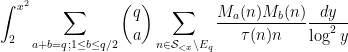 that turns out to hold in our application). By an induction hypothesis and a Markov inequality argument, one can get a reasonable pointwise upper bound on
that turns out to hold in our application). By an induction hypothesis and a Markov inequality argument, one can get a reasonable pointwise upper bound on  (after removing another exceptional set), and the net result is that one can basically control the sum (6) in terms of expressions such as
(after removing another exceptional set), and the net result is that one can basically control the sum (6) in terms of expressions such as 
 . This allows one to estimate these expressions efficiently by induction.
. This allows one to estimate these expressions efficiently by induction.

Recent Comments