
This week I am in San Diego for the annual joint mathematics meeting of the American Mathematical Society and the Mathematical Association of America. I am giving two talks here. One is a lecture (for the AMS “Current Events” Bulletin) on recent developments (by Martel-Merle, Merle-Raphael, and others) on stability of solitons; I will post on that lecture at some point in the near future, once the survey paper associated to that lecture is finalised.
The other, which I am presenting here, is an address on “structure and randomness in the prime numbers“. Of course, I’ve talked about this general topic many times before, (e.g. at my Simons lecture at MIT, my Milliman lecture at U. Washington, and my Science Research Colloquium at UCLA), and I have given similar talks to the one here – which focuses on my original 2004 paper with Ben Green on long arithmetic progressions in the primes – about a dozen or so times. As such, this particular talk has probably run its course, and so I am “retiring” it by posting it here.
p.s. At this meeting, Endre Szemerédi was awarded the 2008 Steele prize for a seminal contribution to research, for his landmark paper establishing what is now known as Szemerédi’s theorem, which underlies the result I discuss in this talk. This prize is richly deserved – congratulations Endre! [The AMS and MAA also awarded prizes to several dozen other mathematicians, including many mentioned previously on this blog; rather than list them all here, let me just point you to their prize booklet.]
My talk concerns the subject of additive prime number theory – which, roughly speaking, is the theory of additive patterns contained inside the prime numbers 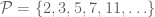

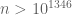

In this talk, I will present the following result of myself and Ben Green in this subject:
Green-Tao Theorem. The prime numbers
contain arbitrarily long arithmetic progressions.
More specifically, I want to talk about three basic ingredients in the proof, and how they come together to prove the theorem:
- Random models for the primes;
- Sieve theory and almost primes;
- Szemerédi’s theorem on arithmetic progressions.
— Random models for the primes —
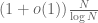 as N goes to infinity. This theorem is proven by using the Euler product formula
as N goes to infinity. This theorem is proven by using the Euler product formula
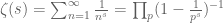
which relates the primes to the Riemann zeta function 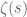
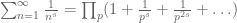
is a restatement (via generating functions) of the fundamental theorem of arithmetic; if instead one rewrites it as

one can view this as a restatement of (a variant of) the sieve of Eratosthenes.] By combining this formula with some non-trivial facts about the Riemann zeta function (and in particular, in the zeroes of that function), one can eventually obtain the prime number theorem.
One way to view the prime number theorem is as follows: if one picks an integer n from 1 to N at random, then that number n has a probability of 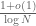
With this in mind, one can propose the following heuristic “proof” of the twin prime conjecture:
- Take a large number N, and let n be a randomly chosen integer from 1 to N. By the prime number theorem, the event that n is prime has probability
.
- By another application of the prime number theorem, the event that n+2 is prime also has probability
. (The shift by 2 causes some additional correction terms, but these can be easily absorbed into the o(1) term.)
- Assuming these two events are independent, we conclude
. In other words, the number of twin primes less than N is
.
- Since
Unfortunately, this argument doesn’t work. One way to see this is to observe that the same argument could be trivially modified to imply that there are infinitely many pairs of adjacent primes n, n+1, which is clearly absurd.
OK, so the above argument is broken; can we fix it? Well, we can try to accomodate the above objection. Why is it absurd to have infinitely many pairs of adjacent primes? Ultimately, it is because of the obvious fact that the prime numbers are all odd (with one exception). In contrast, the above argument was implicitly using a random model for the primes (first proposed by Cramer) in which every integer from 1 to N – odd or even – had an equal chance of 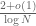



and similarly
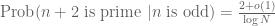
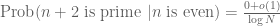
Now, instead of assuming that the events “n is prime” and “n+2 is prime” are absolutely independent, let us assume that they are conditionally independent, relative to the parity of n. Then we conclude that


and a little computation (using the law of total probability) then shows that the number of twin primes less than N is now 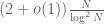
Well, the above random model is still flawed. It now correctly asserts that there are extremely few pairs n,n+1 of adjacent primes, but it also erroneously predicts that there are infinitely many triplets of primes of the form n, n+2, n+4, when in fact there is only one – 3,5,7 – since exactly one of n, n+2, n+4 must be divisible by 3. But we can refine the random model further by taking mod 3 structures into account as well as mod 2 structures. Indeed, if we partition the integers from 1 to N using both the mod 2 partition and the mod 3 partition, we obtain the six residue classes 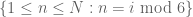
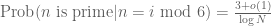
and
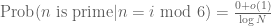
and by repeating the previous analysis, the predicted count of twin primes less than N now drops from 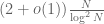
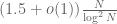
Now, it turns out that this model is still not correct – it fails to account for the mod 5 structure of the primes. But it is not hard to incorporate that structure into this model also, which revises the twin prime count downward a bit to 
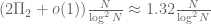
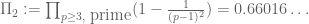
is known as the twin prime constant. More generally, Hardy and Littlewood proposed a general conjecture, now known as the Hardy-Littlewood prime k-tuples conjecture, that predicted asymptotic counts for a general class of additive patterns in the primes; this conjecture (and further refinements) would imply the twin prime conjecture, Vinogradov’s theorem, my theorem with Ben Green, and many other results and conjectures in the subject also.
Roughly speaking, these conjectures assert that apart from the “obvious” structure in the primes, arising from the prime number theorem and from the local behaviour of the primes mod 2, mod 3, etc., there are no other structural patterns in the primes, and so the primes behave “pseudorandomly” once all the obvious structures are taken into account. The conjectures are plausible, and backed up by a significant amount of numerical evidence; unfortunately, nobody knows how to enforce enough pseudorandomness in the primes to make the conjectures rigorously proven. (One cannot simply take limits of the above random models as one inputs more and more mod p information, because the o(1) error terms grow rapidly and soon overwhelm the main term that one is trying to understand.) The problem is that the primes may well contain “exotic structures” or “conspiracies”, beyond the obvious structures listed above, which could further distort things like the twin prime count, perhaps so much so that only finitely many twin primes remain. This seems extremely unlikely, but we can’t rule it out completely yet; how can one disprove a conspiracy?
Some numerics may help illustrate what I mean by the primes becoming random after the mod 2, mod 3, etc. structures are “taken into account” (though I should caution against reading too much into such small-scale computations, as there are many opportunities in small data sets for random coincidences or transient phenomena to create misleading artefacts). Here are the first few natural numbers, with the primes in red, the odd numbers in the starred columns, and the even numbers in dotted columns:
-
* . * . * . * . * . * . * .
-
1 2 3 4 5 6 7 8 9 10 11 12 13 14
-
15 16 17 18 19 20 21 22 23 24 25 26 27 28
-
29 30 31 32 33 34 35 36 37 38 39 40 41 42
-
43 44 45 46 47 48 49 50 51 52 53 54 55 56
-
* . * . * . * . * . * . * . * .
-
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31
-
33 35 37 39 41 43 45 47 49 51 53 55 57 59 61 63
-
65 67 69 71 73 75 77 79 81 83 85 87 89 91 93 95
Then it seems that there is no further parity structure; the starred columns (which have numbers which are 1 mod 4) and the dotted columns (which have numbers which are 3 mod 4), seem equally likely to contain primes. (Indeed, this is a proven fact, being a special case of the prime number theorem in arithmetic progressions.) But look what happens if we highlight the mod 3 structure instead:
-
* . * . * . * .
-
1 3 5 7 9 11 13 15 17 19 21 23
-
25 27 29 31 33 35 37 39 41 43 45 47
-
49 51 53 55 57 59 61 63 65 67 69 71
-
73 75 77 79 81 83 85 87 89 91 93 95
-
* . * .
-
1 7 13 19 25 31 37 43 49 55
-
61 67 73 79 85 91 97 103 109 115
-
121 127 133 139 145 151 157 163 169 175
-
.
-
1 31 61 91 121 151 181
-
211 241 271 301 331 361 391
-
421 451 481 511 541 571 601
-
631 661 691 721 751 781 811
Apart from the dotted column, which has all entries divisible by 7 and thus not prime, the primes seem fairly randomly distributed. In the above examples I always zoomed into the residue class 1 mod p for p=2,3,5,…, but if one picks other residue classes (other than 0 mod p, of course), one also sees the primes become increasingly randomly distributed, with no obvious pattern within each class (and no obvious relation between pairs of classes, triplets of classes, etc.). One can view the prime k-tuples conjecture as a precise formalisation of this assertion of increasing random distribution. (In my paper with Ben, we rely quite crucially on this zooming in trick to improve the pseudorandomness of the almost primes, referring to it as the “W-trick”.)
We have talked about random models for the primes, which seem to be very accurate, but difficult to rigorously justify. However, there is a closely related concept to a prime, namely an almost prime, for which we can show the corresponding random models to be accurate, by the elementary yet surprisingly useful technique of sieve theory.
The most elementary sieve of all is the sieve of Eratosthenes. This sieve uncovers (or “sifts out”) all the prime numbers in a given range, say between N/2 and N for some large number N, by starting with all the integers in this range, and then discarding all the multiples of 2, then the multiples of 3, the multiples of 5 and so forth. After all multiples of prime numbers less than 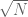
It is tempting to use this sieve to count patterns in primes, such as twin primes. After all, it is easy to count how many twins there are in the integers from N/2 to N; if one then throws out all the multiples of 2, it is still straightforward to count the number of twins remaining. Similarly if one then throws out multiples of 3, of 5, and so forth; not surprisingly, the computations here bear some resemblance to those used to predict twin prime counts from the random models just mentioned. However, as with the random models, the error terms begin to accumulate rapidly, and one loses control of these counts long before one reaches the end of the sieve. More advanced sieves (in which one does not totally exclude the multiples of small numbers, but instead adjusts the “weight” or “score” of a number upward or downward depending on its factors) can improve matters significantly, but even the best sieves still only work if one stops sieving well before the 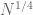
I like to think of the sieving process as being analogous to carving out a sculpture (analogous to the primes) from a block of granite (analogous to the integers) . To begin with, one uses crude tools (such as a mallet) to remove large, simple pieces from the block; but after a while, one has to make finer and finer adjustments, replacing the mallet by a chisel, and then by a pick, removing lots and lots of very small pieces, until the final sculpture is complete. Initially, the structure is simple enough that one can easily pick out patterns (such as twins, or arithmetic progressions); but there is the (highly unlikely) possibility that the many small sets removed at the end are just distributed perversely enough to knock out all the patterns one discerns in the initial stage of the process.
Because we cannot exclude this possibility, sieve theory alone does not seem to able to count patterns in primes. However, we can stop the sieve at an earlier level. If we do so, we obtain good counts of patterns, not in primes, but in the larger set of almost primes – which, for the purposes of this talk, one can think of as being defined as those numbers with no small factors (e.g. no factors less than 

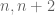
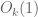
Unfortunately, there is still a gap between finding patterns in the almost primes and finding patterns in the primes themselves, because the primes are only a subset of the almost primes. For instance, while the number of primes less than N is roughly 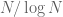
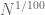
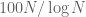
— Szemerédi’s theorem on arithmetic progressions —
Thus far, we have discussed the general problem of how to find patterns in sets such as the primes or almost primes. This problem in general seems to be very difficult, because we do not know how structured or pseudorandom the primes are. There is however one type of pattern which is special – it necessarily shows up in just about any kind of set – structured or random. This type of set is an arithmetic progression. In fact, we have the following important theorem:
Szemerédi’s theorem: Let
be a set of integers of positive upper density (which means that
). Then A contains arbitrarily long arithmetic progressions.
This is a remarkable theorem: it says that if one picks any set of integers at all, so long as it is large enough to occupy a positive fraction of all integers, that is enough to guarantee the existence of arithmetic progressions of any length inside that set. This is in contrast with just about any other pattern, such as twins: for instance, the multiples of three have positive density, but contain no twins.
There are several proofs of this difficult theorem known. It would be too technical to discuss any of them here in detail, but very roughly speaking, all the proofs proceed by dividing the set A into “structured” components (such as sets which are periodic) and “pseudorandom” components (which, roughly, are those components for which the random model gives accurate predictions). One can show that the structured components always generate a lot of arithmetic progressions, and that the pseudorandom components do not significantly disrupt this number of progressions.
Unfortunately, Szemerédi’s theorem does not apply to the primes, because they have zero density. (There are some quantitative versions of that theorem that apply to some sets of zero density, but they are not yet strong enough to directly deal with sets as sparse as the primes.)
— Putting it all together —
To summarise: random models predict arbitrarily long progressions in the primes, but we cannot verify these models. Sieve theory does let us establish long progressions in the almost primes, but the primes are only a fraction of the almost primes. Szemerédi’s theorem gives progressions, but only for sets of positive density within the integers.
To proceed, we exploit the fact that the primes have positive relative density inside the almost primes, by the following argument (inspired, incidentally, by Furstenberg’s ergodic-theoretic proof of Szemerédi’s theorem). We conjecture that the primes obey a certain random model, in which the only structure present being mod p structure for small p. If this is the case, then we are done. If not, it means that there is some specific obstruction to pseudorandomness in the primes, much as the mod 2 or mod 3 obstructions we discussed earlier prevented the most naive random models of the primes from being accurate. We don’t know exactly what that obstruction is, but it turns out that it is possible nevertheless to use that obstruction to modify the random model for the primes to be more accurate, much as we used the mod 2 and mod 3 information previously. We then repeat this process, locating obstructions to pseudorandomness and incorporating them into our random model, until no major obstructions remain. (This can be done after only a bounded number of steps, because one can show (with some effort) that each addition to the random model increases its “energy” by a certain amount, and one can show that the total amount of energy in the model must stay bounded.) As a consequence we know that we can model the primes accurately (at least for the purposes of counting arithmetic progressions) by some random model. [I have not precisely defined what I mean here by “random model”, but very roughly speaking, any such model consists of a partition (or 
The above procedure does not give a very tractable formula for what this model is. However, because the primes are a dense subset of the almost primes, which behave like a random subset of the integers, one can show (by a “comparison principle”, and oversimplifying somewhat) that the primes must then behave like a random subset of a dense subset B of the integers. But then Szemerédi’s theorem applies, and shows that this set B contains plenty of progressions; a random subset of B will then also contain many progressions, and thus the primes will also.
[A simplified version of the above argument, using game theory instead of the above ergodic theory-motivated approach, was recently obtained by Reingold, Trevisan, Tulsiani, and Vadhan.]

18 comments
Comments feed for this article
7 January, 2008 at 11:36 pm
km
Hi Terry,
This is off the topic.
What is your view on solving the Riemann hypothesis? You wrote on solving the Navier-Stokes Millennium Prize problem some time ago.
Could you also write on the possible approaches in your mind that could tackle the Riemann hypothesis?
Thanks.
km
8 January, 2008 at 2:20 am
Aaron
It would be great if you could post video recordings of lectures when possible.
9 January, 2008 at 10:46 am
Terence Tao
Dear km: I actually haven’t thought seriously about RH since some very naive attempts at it in graduate school. It’s possible that one could approach this problem by finding out more structure in the zeta function, but my (somewhat uninformed) opinion is that zeta is inherently a rather pseudorandom object (except of course for its obvious structural properties such as meromorphicity, asymptotics, and the functional equation), and it may be better to return to the prime number side of things, for instance by locating a new proof of the prime number theorem, or finding a way to exclude Siegel zeroes and obtain a more effective prime number theorem in arithmetic progressions. But it’s hard to see how current methods can hope to get the type of power gain in the error terms for prime statistics which would be needed for the full RH; some radically new idea would be needed for that, probably.
Dear Aaron: I don’t believe these lectures were recorded on video.
4 January, 2012 at 9:23 pm
Shubhendu Trivedi
Dear Prof. Tao,
It might not be the same event, but the material on this post (RH, Szemeredi’s Theorem, Green-Tao Theorem) seems to be the same as on this video (including the title):
12 January, 2008 at 6:38 am
Giovanni
Dear Terence
I’m not a very mathematician, but I’m very interesting about Your Blog.
Then, I’m not undestand about arithmetic function o(1) or in general o(n).
Please can You explain me the definition?.
Best Regards
Giovanni
12 January, 2008 at 1:22 pm
Chris
Dear Terence,
thanks for the illuminating article.. i do a lot of ring sieve theory, basically wrapping integers around a spiral of base B.
there’s some neat things you can find about the ring sieves, such as the really pretty geometry that results when you are demodulating things such as RSA encrypted information, structures that are two primes multiplied with each other.
anyways, i noticed that there’s a really interesting base, 24. It is the last base that the powers of the primes all occur as remainder 1 modulo 24. Could this be helpful in your investigations on the ‘pick’ level of the structure you mention?
chris.
13 January, 2008 at 4:42 pm
Terence Tao
Dear Giovanni,
The o() notation is part of Landau notation, more popularly known as “big-O” and “little-O” notation:
http://en.wikipedia.org/wiki/Big_O_notation
14 January, 2008 at 8:41 am
circadian rhythm
Dear km,
Recent experience with big results suggests that first someone should
come up with a programme. I would first read what De Branges has to
say on the matter. Though this might require a lot of night reading.
29 July, 2008 at 8:57 am
Kadhirvel
Please follow the link below for fact about primes
http://kadiprimality.blogspot.com/
18 November, 2008 at 12:45 pm
Marker lectures II, “Linear equations in primes” « What’s new
[…] My first lecture, “Long arithmetic progressions in primes”, is similar to my AMS lecture on the same topic and so I am not reposting it here. The second lecture, the notes for which begin after the fold, […]
21 November, 2008 at 11:11 am
Paddy Ganti
[Terence] I have just ‘discovered’ you yesterday and really love what I you did so far.
I was naieve enough to try a similar approach (the mod p one) at my grad school. You can view my output of survery work here: ise.gmu.edu/~paddy/CSIS.ppt where I have an alternative version of mod 3 approach as “Every prime other than 3 has to be of the firm sqrt(1+24n)” and then trying to prove that there will be atleast one such thing between n and 2n..
[Aaron] This video link will be appropriate for you: http://video.google.com/googleplayer.swf?docid=7691494040933085582&hl=en as it contains the same gist laid out in the article.
1 September, 2009 at 1:55 am
More Mahler lectures « What’s new
[…] Recent progress in additive prime number theory. This is an updated and reformatted version of my AMS lecture on this topic. […]
20 May, 2012 at 2:58 pm
Heuristic limitations of the circle method « What’s new
[…] the prediction (7) by a multiplicative constant known as the twin prime constant; see for instance this previous blog post for more discussion. Our analysis here is focused on orders of growth in rather than on […]
18 September, 2012 at 2:56 pm
The probabilistic heuristic justification of the ABC conjecture « What’s new
[…] However, there is a standard way to correct for these local correlations; see for instance in this previous blog post. As it turns out, these local correlations ultimately alter the prediction for the asymptotic […]
3 December, 2013 at 10:06 am
mathtuition88
Reblogged this on Singapore Maths Tuition.
7 June, 2014 at 4:29 am
Saman Ranjbar
terry can i ask something .what happen if we have a way for finding all prime numbers?
5 February, 2015 at 9:09 am
Anonymous
Dear Prof, Tao
I am asking if there is a mathematical poof that the event: (p is a prime and p+2 is also a prime) occurs inependentely from the previous couples of twin primes.
14 June, 2015 at 11:43 am
Ollev
Dear Sir, as far as i know the rhyhtm of primes has been easily solved about 5 years ago by Johan Oldekamp, a Dutch man. Here is the link
Click to access PrimeRhythm.pdf