On Thursday, Avi Wigderson continued his Distinguished Lecture Series here at UCLA on computational complexity with his second lecture “Expander Graphs – Constructions and Applications“. As in the previous lecture, he spent some additional time after the talk on an “encore”, which in this case was how lossless expanders could be used to obtain rapidly decodable error-correcting codes.
The talk was largely based on these slides. Avi also has a recent monograph with Hoory and Linial on these topics. (For a brief introduction to expanders, I can also recommend Peter Sarnak’s Notices article. I also mention expanders to some extent in my third Milliman lecture.)
— What is an expander? —
Expander graph are sparse graphs with an additional special property. This property can be described in several equivalent ways (combinatorial, probabilistic, or algebraic):
- Connectivity. Expander graphs are sparse but highly connected; any two disjoint sets of vertices cannot be disconnected from each other without removing a lot of edges (i.e. the sparsest cut between the sets is quite large). Equivalently, any proper subset A of vertices is going to have a large boundary
 , defined as the vertices which are not in A but are adjacent to a vertex in A.
, defined as the vertices which are not in A but are adjacent to a vertex in A.
- Mixing. A random walk on an expander graph converges very rapidly to the uniform distribution.
- Spectral gap. The second eigenvalue of the adjacency matrix is significantly smaller than the (typical) degree of the graph.
For sake of concreteness, Avi used the spectral gap formulation of expansion:
Definition. A ![{}[n,d]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%2Cd%5D&bg=ffffff&fg=545454&s=0&c=20201002) -graph is a graph G on n vertices which is d-regular, i.e. every vertex has d edges connected to it. A
-graph is a graph G on n vertices which is d-regular, i.e. every vertex has d edges connected to it. A ![{}[n,d,\alpha]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%2Cd%2C%5Calpha%5D&bg=ffffff&fg=545454&s=0&c=20201002) -graph is an -graph which has the additional property
-graph is an -graph which has the additional property
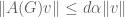
for all non-zero vectors  whose coordinates sum to zero, where A(G) is the adjacency matrix of G and
whose coordinates sum to zero, where A(G) is the adjacency matrix of G and  is the Euclidean norm of v.
is the Euclidean norm of v.
A family of graphs  of d-regular graphs (thus each
of d-regular graphs (thus each  is an
is an ![{}[n_i,d]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn_i%2Cd%5D&bg=ffffff&fg=545454&s=0&c=20201002) -graph for some
-graph for some  ) forms an expander family if each is a
) forms an expander family if each is a ![{}[n_i,d,\alpha]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn_i%2Cd%2C%5Calpha%5D&bg=ffffff&fg=545454&s=0&c=20201002) graph for some
graph for some  .
.
The above definition was a bit technical, but it can be clarified a bit by considering an example of a graph which is definitely not an expander. Consider an -graph G which is disconnected, with the n vertices divided into two disjoint sets A and B of n/2 vertices each, with no edge between A and B. Then if one lets v be the vector which is +1 on A and -1 on B (so that the total sum of coefficients is zero), one can check that  , so G is not an -graph for any
, so G is not an -graph for any  . More generally, it is an instructive exercise to show that an -graph is always a
. More generally, it is an instructive exercise to show that an -graph is always a ![{}[n,d,1]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%2Cd%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002) -graph, but is only an -graph for some if and only if it is connected. Thus the notion of an expander family can be viewed as a quantitative variant of connectivity.
-graph, but is only an -graph for some if and only if it is connected. Thus the notion of an expander family can be viewed as a quantitative variant of connectivity.
[A technical point: strictly speaking, the adjective “expander” applies in a meaningful manner to families of graphs, rather than to individual graphs, much as the adjective “bounded” is meaningful when applied to sequences of numbers, but not to individual numbers. Applying the expander notion to a single graph is a bit silly since a single graph forms an expander family if and only if it is connected. Nevertheless, it is common when discussing expanders to refer to an “expander graph” in the singular, especially when considering a graph whose number of vertices n is quite large and depends implicitly on some other parameter (e.g. a large prime p). Amusingly, one could avoid any abuse of notation by resorting to non-standard analysis, redefining an expander graph to be a graph with a non-standard number of vertices n, but which is an -graph for some standard d and , but this does not seem to significantly simplify or clarify the theory.]
Expanders have various important combinatorial and probabilistic properties. For instance, if G is an -graph, and the n vertices of G are partitioned into two sets A and B, then the number of edges e(A,B) connecting A to B can be easily seen to be bounded below by the inequality
 .
.
Conversely, the discrete Cheeger inequality of Jerrum and Sinclair asserts that if a -graph is such that

for all partitions A, B, then the graph is an -graph. (Another closely related result is the expander mixing lemma.)
One can also show that a random walk on k steps in a -graph (starting at an arbitrary base point) converges exponentially fast in k to the uniform distribution (with constants depending on d and  but not n); informally, the random walk becomes very close to uniform after about
but not n); informally, the random walk becomes very close to uniform after about  steps; a more precise statement can be found here. [You may have heard of the famous result of Bayer and Diaconis that a deck of cards can be perfectly shuffled after just seven riffle shuffles; to oversimplify a bit, that claim is equivalent to asserting an expander property of the Cayley graph whose vertices are deck configurations, with two vertices connected if one is a riffle shuffle of another.]
steps; a more precise statement can be found here. [You may have heard of the famous result of Bayer and Diaconis that a deck of cards can be perfectly shuffled after just seven riffle shuffles; to oversimplify a bit, that claim is equivalent to asserting an expander property of the Cayley graph whose vertices are deck configurations, with two vertices connected if one is a riffle shuffle of another.]
Expanders have many applications, most obviously in graph theory, but also in computer science, number theory, group theory, and even to such apparently unrelated topics as the Baum-Connes conjecture in K-theory, which also has connections to topology, though Avi focused primarily on the computer science applications in this talk. Just to give one simple example of such an application, he discussed deterministic amplification of probabilistic algorithms. Suppose one had an algorithm  which took some input i and some n-bit stream (or “coin flips”)
which took some input i and some n-bit stream (or “coin flips”)  and returned an output A(i,r), which is a single bit (yes or no). Suppose that for a given input i, this algorithm was correct for (say) 2/3 of the possible bit streams r; thus if we select the n bits of r randomly the algorithm has at most a 1/3 probability of failure.
and returned an output A(i,r), which is a single bit (yes or no). Suppose that for a given input i, this algorithm was correct for (say) 2/3 of the possible bit streams r; thus if we select the n bits of r randomly the algorithm has at most a 1/3 probability of failure.
As discussed in the previous lecture, one can reduce the failure probability by iteration. If one selects k independent random bit streams  , and runs the algorithm A once for each such stream, and then takes the majority vote of the k different outcomes, then a simple application of the Chernoff bound shows that the resulting algorithm has a failure probability which is exponentially small (
, and runs the algorithm A once for each such stream, and then takes the majority vote of the k different outcomes, then a simple application of the Chernoff bound shows that the resulting algorithm has a failure probability which is exponentially small ( for some absolute constant c > 0). But this iterated algorithm requires one to generate kn independent random bits. In some applications, high-quality random bits are an expensive resource, and so it is natural to ask whether one can obtain an algorithm with similar performance but requiring many fewer random bits. It turns out that one can, simply by selecting
for some absolute constant c > 0). But this iterated algorithm requires one to generate kn independent random bits. In some applications, high-quality random bits are an expensive resource, and so it is natural to ask whether one can obtain an algorithm with similar performance but requiring many fewer random bits. It turns out that one can, simply by selecting  not independently, but by selecting
not independently, but by selecting  in turn by a random walk along a bounded-degree expander graph on
in turn by a random walk along a bounded-degree expander graph on  beginning at a random vertex, and then performing a majority vote. The mixing properties of random walk can be used to give the same type of exponentially small failure probability as before, but now only
beginning at a random vertex, and then performing a majority vote. The mixing properties of random walk can be used to give the same type of exponentially small failure probability as before, but now only  random bits are needed (each step of the random walk requires O(1) random bits, to decide which edge to go down.)
random bits are needed (each step of the random walk requires O(1) random bits, to decide which edge to go down.)
In order for the above algorithm to work properly, one needs to construct expanders explicitly – so explicitly that given any vertex in the expander, one can quickly compute all the neighbours. This was Avi’s next topic.
— Constructions of expanders —
A simple counting argument of Pinsker shows that expanders exist in abundance; indeed, a random sequence of [n,d]-graphs (with 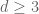 fixed and n going to infinity) is almost surely going to be an expander family. But for many applications, one needs more deterministic expanders.
fixed and n going to infinity) is almost surely going to be an expander family. But for many applications, one needs more deterministic expanders.
The first explicit expander families arose from group theory (as given by Margulis, Gabber-Galil, Alon-Milman, Lubotsky-Phillips-Sarnak, and others); a typical example of such a family are the Cayley graphs whose vertices are the special linear group 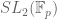 over a large field of prime order p, with the edges given by the set of generators
over a large field of prime order p, with the edges given by the set of generators

(thus two matrices in are connected by a graph if their quotient is either in S, or is an inverse of an element in S.) The expansion of these algebraic graph families is deeply connected to some non-trivial results in group theory and analytic number theory; in this case, the key property is Selberg’s famous 3/16 theorem on the least eigenvalue of the Laplacian on modular curves.
These algebraic constructions can be made extremely tight in the sense that the spectral gap parameter can be made optimally small. More precisely, there is the Alon-Boppana bound, which asserts that an -graph can only exist if  . Graphs which attain this bound are known as Ramanujan graphs, and were first constructed by Lubotsky-Phillips-Sarnak and Margulis by algebraic methods. (Random graphs come quite close to being Ramanujan, but are off by a slight amount.)
. Graphs which attain this bound are known as Ramanujan graphs, and were first constructed by Lubotsky-Phillips-Sarnak and Margulis by algebraic methods. (Random graphs come quite close to being Ramanujan, but are off by a slight amount.)
More recently, starting with the work of Reingold, Vadhan, and Wigderson, more explicitly combinatorial constructions of expanders have been given. A fundamental building block in such constructions is the zigzag product  of a
of a ![{}[n,m]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bn%2Cm%5D&bg=ffffff&fg=545454&s=0&c=20201002) -graph G and a
-graph G and a ![{}[m,d]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bm%2Cd%5D&bg=ffffff&fg=545454&s=0&c=20201002) -graph H (thus H is small compared with G – the number of vertices of H equals the degree of G). The zigzag product is to graphs as the semi-direct product is to groups (and in fact, this connection can be made very precise, as the semi-direct product can be viewed as the specialisation of the zigzag product to Cayley graphs). Roughly speaking, the zigzag product is defined by “blowing up” each vertex of G into a copy of H, and then decoupling the edges in G to become disjoint. A bit more formally, if we let V and W be the vertex sets of G and H respectively, then we let be the
-graph H (thus H is small compared with G – the number of vertices of H equals the degree of G). The zigzag product is to graphs as the semi-direct product is to groups (and in fact, this connection can be made very precise, as the semi-direct product can be viewed as the specialisation of the zigzag product to Cayley graphs). Roughly speaking, the zigzag product is defined by “blowing up” each vertex of G into a copy of H, and then decoupling the edges in G to become disjoint. A bit more formally, if we let V and W be the vertex sets of G and H respectively, then we let be the ![{}[nm, d+1]](https://s0.wp.com/latex.php?latex=%7B%7D%5Bnm%2C+d%2B1%5D&bg=ffffff&fg=545454&s=0&c=20201002) -graph with vertex sets V, and whose edge set consists of the “local” edges of form (a,x) and (a,y) where a lies in V and x,y form an edge in W, together with one “global” edge of the form (a,x), (b,y) for each edge (a,b) in G, where x and y depend on a and b and are chosen so that all the global edges are disjoint from each other (this can be done for instance by the greedy algorithm). [Note that there is a little bit of freedom in this construction, so that the zigzag product is not quite unique, but this is not a concern in applications, as all the zigzag products of two graphs have much the same expansion properties.]
-graph with vertex sets V, and whose edge set consists of the “local” edges of form (a,x) and (a,y) where a lies in V and x,y form an edge in W, together with one “global” edge of the form (a,x), (b,y) for each edge (a,b) in G, where x and y depend on a and b and are chosen so that all the global edges are disjoint from each other (this can be done for instance by the greedy algorithm). [Note that there is a little bit of freedom in this construction, so that the zigzag product is not quite unique, but this is not a concern in applications, as all the zigzag products of two graphs have much the same expansion properties.]
The key fact about zigzag products is that they preserve expansion: the zigzag product  of two expander families and
of two expander families and  is another expander family. (With a slight variant of the zigzag product, one can give a simple and explicit relation between the various spectral parameters here.) On the other hand, zigzag products also keep the degree d of the graph quite small, even if the first factor G has large degree. Because of this, it is possible to iterate the zigzag product (particularly in conjunction with the exponentiation operation
is another expander family. (With a slight variant of the zigzag product, one can give a simple and explicit relation between the various spectral parameters here.) On the other hand, zigzag products also keep the degree d of the graph quite small, even if the first factor G has large degree. Because of this, it is possible to iterate the zigzag product (particularly in conjunction with the exponentiation operation  , which replaces a graph G with a new graph (or multigraph) on the same vertex set whose adjacency matrix
, which replaces a graph G with a new graph (or multigraph) on the same vertex set whose adjacency matrix  is the
is the 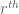 power of the original adjacency matrix A(G)) to create many new families of explicit expanders, with good expansion properties compared to their degree; I’ll omit the details here but they are covered in detail in Avi’s slides.
power of the original adjacency matrix A(G)) to create many new families of explicit expanders, with good expansion properties compared to their degree; I’ll omit the details here but they are covered in detail in Avi’s slides.
The zigzag construction is very flexible and robust, and can be tweaked in a large number of ways to create expander graphs with certain additional combinatorial properties – which are often not attainable with the earlier algebraic constructions, or even for the Ramanujan graphs (which are optimal with respect to the spectral parameter , but not necessarily with respect to more combinatorial parameters). For example, suppose one wants to find an [n,d] graph with the connectivity property that every pair of vertex sets of size at least n/a are connected by at least one edge, where a is a fixed large constant. This is easy to do for large d; the challenge is to get d as small as possible. For Ramanujan graphs, d needs to be as large as 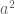 or so to obtain this property; in contrast, for random [n,d]-graphs, d can be as small as about
or so to obtain this property; in contrast, for random [n,d]-graphs, d can be as small as about  . It is not known how to achieve this deterministically, but using zigzag products (not on expanders per se, but on a related object known as an extractor) one can get within a few logarithmic factors of this bound.
. It is not known how to achieve this deterministically, but using zigzag products (not on expanders per se, but on a related object known as an extractor) one can get within a few logarithmic factors of this bound.
One can also combine the zigzag construction with algebraic constructions, for instance to create expander Cayley graphs in very general classes of finite groups, though Avi didn’t go into details on this point.
Another place where zigzag constructions have been useful is in lossless expanders. Observe that in an [n,d] graph, the neighbourhood of a k-vertex set can have size at most dk. A lossless expander is an [n,d]-graph (or more precisely, a expander family of such graphs) with the property that for any  there exists an a such that every k-vertex set with
there exists an a such that every k-vertex set with 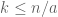 has a neighbourhood of size at least
has a neighbourhood of size at least  ; thus small sets expand nearly as much as possible. Ramanujan graphs don’t always have this property; no matter how large one makes a, one can find such graphs in which the neighbourhood of a k-element set is only about dk/2 or so. But by using the zigzag construction (this time to a type of graph known as a randomness conductor) one can create lossless expanders.
; thus small sets expand nearly as much as possible. Ramanujan graphs don’t always have this property; no matter how large one makes a, one can find such graphs in which the neighbourhood of a k-element set is only about dk/2 or so. But by using the zigzag construction (this time to a type of graph known as a randomness conductor) one can create lossless expanders.
One particularly striking recent application of the zig-zag product construction (by Reingold) is to create a deterministic algorithm to solve the maze exploration problem mentioned in the previous lecture (getting from A to B in some large connected graph) in polynomial time and logarithmic space. Roughly speaking, the idea is to first observe that any connected graph G (let’s take it to be an [n,d]-graph for simplicity) has a very weak expansion property; it is an -graph for some a little bit less than 1 (e.g.  will do). This is not enough expansion by itself to do much of anything, but by taking graph powers and zigzag products of G with itself (and with a small expander), one can soon create a polynomially larger graph G’ which has a very good expansion constant, so much so that one can get from any point in G’ to any other by traversing a path of logarithmic length (and one can simply exhaust over all such paths in polynomial time and logarithmic memory). Finally, because the zigzag product is so combinatorially simple and explicit, it is possible to use the solution to the G’ exploration problem to obtain a solution to the G exploration problem with comparable time and memory costs.
will do). This is not enough expansion by itself to do much of anything, but by taking graph powers and zigzag products of G with itself (and with a small expander), one can soon create a polynomially larger graph G’ which has a very good expansion constant, so much so that one can get from any point in G’ to any other by traversing a path of logarithmic length (and one can simply exhaust over all such paths in polynomial time and logarithmic memory). Finally, because the zigzag product is so combinatorially simple and explicit, it is possible to use the solution to the G’ exploration problem to obtain a solution to the G exploration problem with comparable time and memory costs.
— Lossless expanders and error-correcting codes —
Avi then talked about how lossless expanders can be used to produce quickly decodable error-correcting codes (and it is crucial here that the expander is lossless; graphs that only expand from k to dk/2 will not work for this application). Mathematically, a code for the purposes of this talk is a function  that makes k-bit strings into larger n-bit strings in an injective manner. Actually, for the purposes of this analysis, the actual function is not important; what is important is the list of codewords
that makes k-bit strings into larger n-bit strings in an injective manner. Actually, for the purposes of this analysis, the actual function is not important; what is important is the list of codewords  (which is often identified with C in this subject, by abuse of notation). There are many important statistics of codes, but two particularly key ones are the rate k/n, and the distance, defined as the minimal separation (in the Hamming metric) between two codewords. Note that an error correcting code can (in principle) absorb a number of errors equal to half the distance, although in practice it may be computationally expensive to perform this correction.
(which is often identified with C in this subject, by abuse of notation). There are many important statistics of codes, but two particularly key ones are the rate k/n, and the distance, defined as the minimal separation (in the Hamming metric) between two codewords. Note that an error correcting code can (in principle) absorb a number of errors equal to half the distance, although in practice it may be computationally expensive to perform this correction.
Let us informally say that a code is good if the rate is comparable to 1, and if the distance is comparable to n. It was shown by Shannon that good codes exist, indeed a randomly selected code is likely to be rather good. On the other hand, it is not possible to perform error correction on a random code quickly.
One particularly popular type of code is a linear code, in which C is a linear function (identifying  with the field of two elements). The image of such a code is thus a linear subspace in
with the field of two elements). The image of such a code is thus a linear subspace in  , and thus can be defined as the simultaneous null space of n-k linear functionals on this space, which can be viewed as checksums or parity bits that need to vanish in order for a given word to lie in the code. Over
, and thus can be defined as the simultaneous null space of n-k linear functionals on this space, which can be viewed as checksums or parity bits that need to vanish in order for a given word to lie in the code. Over 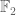 , a linear functional on the Hamming cube is nothing more than the sum of some collection of the coordinate functions on that cube. Thus one can describe the code C (or more precisely, its image
, a linear functional on the Hamming cube is nothing more than the sum of some collection of the coordinate functions on that cube. Thus one can describe the code C (or more precisely, its image  ) by a bipartite graph connecting the n coordinates with the n-k parity bits, with each parity bit being formed as the sum of the coordinates it is connected to.
) by a bipartite graph connecting the n coordinates with the n-k parity bits, with each parity bit being formed as the sum of the coordinates it is connected to.
With linear codes, encoding is a relatively quick process; the challenge is in decoding in the presence of errors. Remarkably, if one selects the graph defining the code to be a bipartite lossless expander (so that each of the n coordinates is connected to d parity bits for some bounded d, and any m coordinates (with m less than a small multiple of n) is connected to close to dm parity bits), then not only is the code good (high rate and high distance), one can decode very quickly (linear time in n) by the following belief propagation algorithm:
- Start with the corrupted word, and compute all the parity bits. If they all vanish, then we have a codeword and we stop.
- Otherwise, we go through each coordinate and see how many of the d parity bits connected to that coordinate are non-vanishing (i.e. they take the value 1). If a majority of these bits return 1, then we flip the bit of the coordinate; otherwise, we keep the bit unchanged. (Intuitively, we are reducing the number of non-vanishing parity bits as much as possible.)
- Repeat 2 until all parity bits vanish.
Intuitively, the reason why this algorithm should work (if the number m of corrupted bits is small enough) is that in a lossless expander, the parity bits associated to each of the corrupted coordinates are mostly disjoint. Thus, every corrupted coordinates should see that most of the parity bits connected to it are taking the value of 1, giving a strong signal that those bits should change. Conversely, the uncorrupted bits should mostly see only a small minority of parity bits connected to it reporting the value 1. Indeed, one can show that each iteration of Step 2 cuts down the number m of corrupted bits by a constant factor (if m was small enough that the lossless property can be used, with some suitably small  ). Also it is not hard to analyse the run-time of this algorithm and show that it is linear in the length n of the code.
). Also it is not hard to analyse the run-time of this algorithm and show that it is linear in the length n of the code.
[Update, Jan 14: memory requirement for Reingold’s graph exploration algorithm corrected. Connections to Baum-Connes conjecture reworded.]


8 comments
Comments feed for this article
11 January, 2008 at 2:48 pm
Anonymous
There appears to be a typo in your definition of the set S of generators of SL_2.
12 January, 2008 at 5:01 am
Emmanuel Kowalski
I once spent quite some time to locate (for reference purpose) a complete proof of the link from Selberg’s 3/16 theorem to the expanding properties of Cayley graphs as you described; the books I know on the subject (e.g., Sarnak’s “Some applications of modular forms”, Lubotzky’s “Discrete groups, expanding graphs and invariant measures”) do not give full details — they treat the case of compact surfaces and not finite-volume ones, which is of course fine for understanding what’s going on, but is not a complete argument.
So maybe it will be useful to give the references I found: the result (for finite-volume, non-compact surfaces) seems to be due to R. Brooks, in “On the angles between certain arithmetically defined subspaces of “, in Annales de l’institut Fourier, tome 37, no 1 (1987), p. 175-185 (available on numdam.org), see Corollary, p. 182. Here the argument of Brooks is _very_ condensed, but there is a complete write-up in lecture notes of his entitled “The spectral geometry of Riemann surfaces”, Section 2 (those notes are available as Chapter 12 of “Topology in Molecular Biology”, published by Springer, or here).
“, in Annales de l’institut Fourier, tome 37, no 1 (1987), p. 175-185 (available on numdam.org), see Corollary, p. 182. Here the argument of Brooks is _very_ condensed, but there is a complete write-up in lecture notes of his entitled “The spectral geometry of Riemann surfaces”, Section 2 (those notes are available as Chapter 12 of “Topology in Molecular Biology”, published by Springer, or here).
14 January, 2008 at 7:20 am
Anonymous
Correction: Reingold’s algorithm for connectivity runs in logarithmic space and not polylogarithmic as you wrote (a log^2 space algorithm is easy to get).
14 January, 2008 at 10:38 am
Terence Tao
Thanks for the correction!
14 January, 2008 at 7:23 pm
David Fisher
I want to clarify the relation between expanders,
Baum-Connes and topology. Saying this connection yields an “application of expanders to topology” is a bit of a stretch.
The Baum-Connes conjecture is a conjecture
concerning K-theory of group C^* algebras. It conjectures that a certain map is an isomorphism between two different K groups.
The injectivity of this Baum-Connes map implies the Novikov conjecture which is a conjecture about topological invariance of certain higher signatures. This implication is robust in that knowing Baum-Connes for a particular group implies Novikov for manifolds with that group as fundamental group.
There is, however, no reverse implication. So if
Baum-Connes is false for a group, we still have
no idea about Novikov.
By a theorem of Guoliang Yu, if a group admits a uniform embedding in a Hilbert space, the Baum-Connes map is injective and so the Novikov conjecture is true. There are other variants on
Yu’s result, but this is the result relevant here.
Gromov pointed out that if one could embed a
family of expander graphs into the Cayley graph
of the group, then the group would not admit a
uniform embedding in a Hilbert space. And proposed a method for constructing such a group.
(Actually the expander graphs are only embedded
quasi-isometrically, but this is enough.) To the best of my knowledge a complete and formal account justifying the existence of these groups is not yet in available. But I think a complete account is likely to be available soon, quite possibly multiple complete accounts.
Currently, no one knows if these groups actually provide a counter-example to Baum-Connes or not.
They do provide, indirectly, counterexamples to
some generalizations of the original Baum-Connes
conjecture. This is work of Higson, Lafforgue and Skandalis that has been in print since 2002. Though I am not an expert in this particular domain, I think
it is fair to say that serious effort has been devoted to seeing if Gromov’s groups are actually counterexamples to Baum-Connes. They might be,
but new ideas are almost certainly needed.
So currently expanders really only allow us to build some groups that obstruct one method of proving a big conjecture about group C^* algebras. Therefore obstructing one method of proving a big
conjecture about topology.
These conjectures are all hard and important so it
is worthwhile knowing how not to try to prove them. But, at the moment, there is no result about
topology, positive or negative, that comes out of this story.
14 January, 2008 at 9:14 pm
Terence Tao
Dear David,
Thanks for the detailed clarification! It sounds like a topic which I will have to learn more about at some point. For now, I’ve reworded the text slightly (which, incidentally, was not a direct quote from Avi).
15 January, 2008 at 2:00 pm
David Fisher
Dear Terry,
A couple of additional remarks that I always forget, but that get to the heart of the matter.
First, in the positive direction, the work on
Baum-Connes does have topological implications.
E.g. Guoliang Yu’s work can be used to prove the Novikov conjecture for hyperbolic groups. I think
my earlier post may give the wrong impression on this point.
But on the negative side the connections just
aren’t so good. In particular, the Novikov
conjecture passes to direct limits of groups.
The construction of groups containing expander graphs constructs them as direct limits of hyperbolic groups. So these groups which might not satisfy
Baum-Connes are already known to satisfy Novikov.
Best,
David
14 March, 2008 at 3:07 am
Big Boned · A talk at Zachos' class
[…] Expander introduction and show how to use it. A great introduction (but need a lot of knowledge which I didn’t have yet) of Expander graph is mentioned in Tao’s blog. […]