
You are currently browsing the tag archive for the ‘expander graphs’ tag.
Emmanuel Breuillard, Ben Green, Bob Guralnick, and I have just uploaded to the arXiv our joint paper “Expansion in finite simple groups of Lie type“. This long-delayed paper (announced way back in 2010!) is a followup to our previous paper in which we showed that, with one possible exception, generic pairs of elements of a simple algebraic group (over an uncountable field) generated a free group which was strongly dense in the sense that any nonabelian subgroup of this group was Zariski dense. The main result of this paper is to establish the analogous result for finite simple groups of Lie type (as defined in the previous blog post) and bounded rank, namely that almost all pairs 
There are also some related results established in the paper. Firstly, as we discovered after writing our first paper, there was one class of algebraic groups for which our demonstration of strongly dense subgroups broke down, namely the 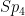

Secondly, we show that the distinction between one-sided expansion and two-sided expansion (see this set of lecture notes of mine for definitions) is erased in the context of Cayley graphs of bounded degree, in the sense that such graphs are one-sided expanders if and only if they are two-sided expanders (perhaps with slightly different expansion constants). The argument turns out to be an elementary combinatorial one, based on the “pivot” argument discussed in these lecture notes of mine.
Now to the main result of the paper, namely the expansion of random Cayley graphs. This result had previously been established for 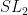
- Non-concentration (A random walk in this graph does not concentrate in a proper subgroup);
- Product theorem (A medium-sized subset of this group which is not trapped in a proper subgroup will expand under multiplication); and
- Quasirandomness (The group has no small non-trivial linear representations).
Quasirandomness of arbitrary finite simple groups of Lie type was established many years ago (predating, in fact, the introduction of the term “quasirandomness” by Gowers for this property) by Landazuri-Seitz and Seitz-Zalesskii, and the product theorem was already established by Pyber-Szabo and independently by Breuillard, Green, and myself. So the main problem is to establish non-concentration: that for a random Cayley graph on a finite simple group 
The first step was to classify the proper subgroups of 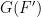
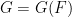
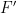

To preclude concentration in a structural subgroup, we use our previous result that generic elements of an algebraic group generate a strongly dense subgroup, and so do not concentrate in any algebraic subgroup. To translate this result from the algebraic group setting to the finite group setting, we need a Schwarz-Zippel lemma for finite simple groups of Lie type. This is straightforward for Chevalley groups, but turns out to be a bit trickier for the Steinberg and Suzuki-Ree groups, and we have to go back to the Chevalley-type parameterisation of such groups in terms of (twisted) one-parameter subgroups, that can be found for instance in the text of Carter; this “twisted Schwartz-Zippel lemma” may possibly have further application to analysis on twisted simple groups of Lie type. Unfortunately, the Schwartz-Zippel estimate becomes weaker in twisted settings, and particularly in the case of triality groups 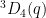
To rule out concentration in a conjugate of a subfield group, we repeat an argument we introduced in our Suzuki paper and pass to a matrix model and analyse the coefficients of the characteristic polynomial of words in this Cayley graph, to prevent them from concentrating in a subfield. (Note that these coefficients are conjugation-invariant.)
In this final set of course notes, we discuss how (a generalisation of) the expansion results obtained in the preceding notes can be used for some number-theoretic applications, and in particular to locate almost primes inside orbits of thin groups, following the work of Bourgain, Gamburd, and Sarnak. We will not attempt here to obtain the sharpest or most general results in this direction, but instead focus on the simplest instances of these results which are still illustrative of the ideas involved.
One of the basic general problems in analytic number theory is to locate tuples of primes of a certain form; for instance, the famous (and still unsolved) twin prime conjecture asserts that there are infinitely many pairs 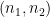
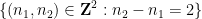

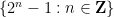
More generally, given some explicit subset 

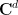


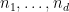
At this level of generality, this problem is impossibly difficult. Indeed, even the much simpler problem of deciding whether the set 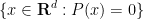

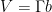


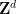


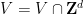

Even in this simpler setting, the question of determining whether an orbit 

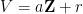

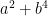

On the other hand, much more is known if one is willing to replace the primes by the larger set of almost primes – integers with a small number of prime factors (counting multiplicity). Specifically, for any 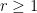


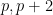

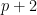

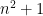
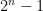
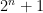
The main tool that allows one to count almost primes in orbits is sieve theory. The reason for this lies in the simple observation that in order to ensure that an integer 

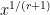
The most basic sieve of this form is the sieve of Eratosthenes, which when combined with the inclusion-exclusion principle gives the Legendre sieve (or exact sieve), which gives an exact formula for quantities such as the number 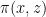


Very roughly speaking, the end result of sieve theory is that excepting some degenerate and “exponentially thin” settings (such as those associated with the Mersenne primes), all the orbits which are expected to have a large number of primes, can be proven to at least have a large number of 
Theorem 1 (Bourgain-Gamburd-Sarnak) Let
which is not virtually solvable. Let
be a polynomial with integer coefficients obeying the following primitivity condition: for any positive integer
, there exists
such that
is coprime to
with
This is not the strongest version of the Bourgain-Gamburd-Sarnak theorem, but it captures the general flavour of their results. Note that the theorem immediately implies an analogous result for orbits 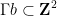

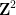
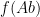
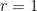
By specialising to the polynomial 
It turns out that to prove Theorem 1, the Cayley expansion results in 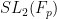

We have now seen two ways to construct expander Cayley graphs 
We now pursue the second approach more thoroughly. The main difficulty here is to figure out how to ensure flattening of the random walk, as it is then an easy matter to use quasirandomness to show that the random walk becomes mixing soon after it becomes flat. In the case of Selberg’s theorem, we achieved this through an explicit formula for the heat kernel on the hyperbolic plane (which is a proxy for the random walk). However, in most situations such an explicit formula is not available, and one must develop some other tool for forcing flattening, and specifically an estimate of the form
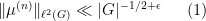
for some 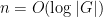


In 2006, Bourgain and Gamburd introduced a general method for achieving this goal. The intuition here is that the main obstruction that prevents a random walk from spreading out to become flat over the entire group 

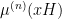
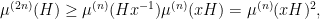
since 
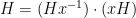

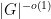
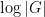
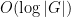
A potentially more general obstruction of this type would be if the random walk gets trapped in (a coset of) an approximate group 

It turns out that this latter observation has a converse: if a measure does not concentrate in cosets of approximate groups, then some flattening occurs. More precisely, one has the following combinatorial lemma:
Lemma 1 (Weighted Balog-Szemerédi-Gowers lemma) Let
be a finitely supported probability measure on
for all
), and let
. Then one of the following statements hold:
- (i) (Flattening) One has
.
- (ii) (Concentration in an approximate group) There exists an
-approximate group
and an element
such that
.
This lemma is a variant of the more well-known Balog-Szemerédi-Gowers lemma in additive combinatorics due to Gowers (which roughly speaking corresponds to the case when 
The lemma is particularly useful when the group
Theorem 2 (Bourgain-Gamburd expansion machine) Suppose that
is a symmetric set of
generators, and that there are constants
with the following properties.
- (Quasirandomness). The smallest dimension of a nontrivial representation
of
;
- (Product theorem). For all
there is some
such that the following is true. If
is a
-approximate subgroup with
then
- (Non-concentration estimate). There is some even number
such that
where the supremum is over all proper subgroups
.
Then
-expander for some
depending only on
, and the function
(and this constant

This criterion for expansion is implicitly contained in this paper of Bourgain and Gamburd, who used it to establish the expansion of various Cayley graphs in
Emmanuel Breuillard, Ben Green, and I have just uploaded to the arXiv the paper “Suzuki groups as expanders“, to be submitted. The purpose of this paper is to finish off the last case of the following theorem:
Theorem 1 (All finite simple groups have expanders) For every finite simple non-abelian group
on
with
for all
) has expansion constant bounded away from zero uniformly in
for all
with
and some
independent of
To put in an essentially equivalent way, one can quickly generate a random element of a finite simple group with a near-uniform distribution by multiplying together a few (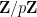
The first step in proving this theorem is, naturally enough, the classification of finite simple groups. The sporadic groups have bounded cardinality and are a trivial case of this theorem, so one only has to deal with the seventeen infinite families of finite non-abelian simple groups. With one exception, the groups 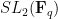
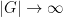
The exceptional family is the family of Suzuki groups 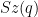
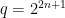
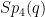


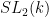
Our main result is that the Suzuki groups also support expanders, thus completing the last case of the above theorem. In fact we can pick just two random elements 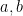

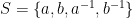
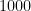
Our methods are different, instead following closely the arguments of Bourgain and Gamburd, which established the analogue of our result (i.e. that two random elements generate an expander graph) for the family of groups 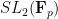
- (Early period) When
for some small
, one wants
for some fixed
- (Middle period) Once
for some suitable
is reasonably spread out in the sense that its
for some small
- (Late period) Once
in the
norm).
The late period claim is easy to establish from Gowers’ theory of quasirandom groups, the key point being that (like all other finite simple nonabelian groups), the Suzuki groups do not admit any non-trivial low-dimensional irreducible representations (we can for instance use a precise lower bound of 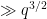
The main difficulty is then to deal with the early period, obtaining some initial non-concentration in the random walk associated to 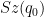

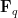
In the algebraic case, one can prevent concentration using a lower bound on the girth of random Cayley graphs due to Gamburd, Hoory, Shahshahani, Shalev, and Virág (and we also provide an independent proof of this fact for completeness, which fortunately is able to avoid any really deep technology, such as Lang-Weil estimates); this follows an analogous argument of Bourgain-Gamburd in the

Recent Comments