
You are currently browsing the tag archive for the ‘szemeredi regularity lemma’ tag.
Perhaps the most important structural result about general large dense graphs is the Szemerédi regularity lemma. Here is a standard formulation of that lemma:
Lemma 1 (Szemerédi regularity lemma) Let
be a graph on
vertices, and let
. Then there exists a partition
for some
with the property that for all but at most
of the pairs
, the pair
is
-regular in the sense that
whenever
are such that
and
, and
is the edge density between
and
. Furthermore, the partition is equitable in the sense that
for all

There are many proofs of this lemma, which is actually not that difficult to establish; see for instance these previous blog posts for some examples. In this post I would like to record one further proof, based on the spectral decomposition of the adjacency matrix of 
For reasons of exposition, it is convenient to first establish a slightly weaker form of the lemma, in which one drops the hypothesis of equitability (but then has to weight the cells 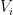
Lemma 2 (Szemerédi regularity lemma, weakened variant) . Let
outside of an exceptional set
, one has
whenever
, where
is the number of edges between
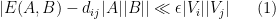

Let us now prove Lemma 2. We enumerate 




for some orthonormal basis 
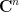
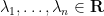

We can compute the trace of 

 , so
, so 
Among other things, this implies that

for all 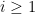
Let 
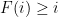

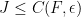
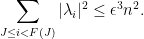
(Indeed, the bound on 



where 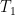
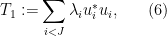
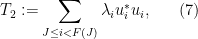
and 
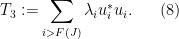
We now design a vertex partition to make 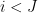




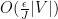

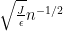
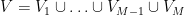

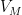
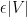



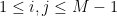
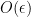
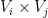

for any 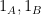
Next, we observe from (3) and (7) that 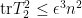
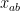
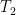
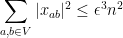
and hence by Markov’s inequality we have

for all pairs 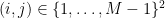
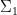
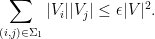

for any
Finally, to control 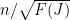
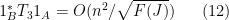
for any 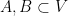
Let 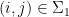
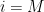

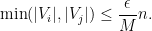
One easily verifies that (2) holds. If

for all 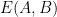
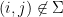
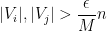
and so (since
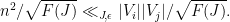
If we let
To prove Lemma 1, one argues similarly (after modifying 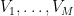
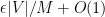
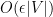
Remark 1 It is easy to verify that
in the partition. It was shown by Gowers that a tower-exponential bound is actually necessary here. By varying
essentially gives the weak regularity lemma of Frieze and Kannan.
Remark 2 If we specialise to a Cayley graph, in which
is a finite abelian group and
for some (symmetric) subset
of
Remark 3 The use of spectral theory here is parallel to the use of Fourier analysis to establish results such as Roth’s theorem on arithmetic progressions of length three. In analogy with this, one could view hypergraph regularity as being a sort of “higher order spectral theory”, although this spectral perspective is not as convenient as it is in the graph case.
A few days ago, Endre Szemerédi was awarded the 2012 Abel prize “for his fundamental contributions to discrete mathematics and theoretical computer science, and in recognition of the profound and lasting impact of these contributions on additive number theory and ergodic theory.” The full citation for the prize may be found here, and the written notes for a talk given by Tim Gowers on Endre’s work at the announcement may be found here (and video of the talk can be found here).
As I was on the Abel prize committee this year, I won’t comment further on the prize, but will instead focus on what is arguably Endre’s most well known result, namely Szemerédi’s theorem on arithmetic progressions:
Theorem 1 (Szemerédi’s theorem) Let
, where
. Then
for any
.
Szemerédi’s original proof of this theorem is a remarkably intricate piece of combinatorial reasoning. Most proofs of theorems in mathematics – even long and difficult ones – generally come with a reasonably compact “high-level” overview, in which the proof is (conceptually, at least) broken down into simpler pieces. There may well be technical difficulties in formulating and then proving each of the component pieces, and then in fitting the pieces together, but usually the “big picture” is reasonably clear. To give just one example, the overall strategy of Perelman’s proof of the Poincaré conjecture can be briefly summarised as follows: to show that a simply connected three-dimensional manifold is homeomorphic to a sphere, place a Riemannian metric on it and perform Ricci flow, excising any singularities that arise by surgery, until the entire manifold becomes extinct. By reversing the flow and analysing the surgeries performed, obtain enough control on the topology of the original manifold to establish that it is a topological sphere.
In contrast, the pieces of Szemerédi’s proof are highly interlocking, particularly with regard to all the epsilon-type parameters involved; it takes quite a bit of notational setup and foundational lemmas before the key steps of the proof can even be stated, let alone proved. Szemerédi’s original paper contains a logical diagram of the proof (reproduced in Gowers’ recent talk) which already gives a fair indication of this interlocking structure. (Many years ago I tried to present the proof, but I was unable to find much of a simplification, and my exposition is probably not that much clearer than the original text.) Even the use of nonstandard analysis, which is often helpful in cleaning up armies of epsilons, turns out to be a bit tricky to apply here. (In typical applications of nonstandard analysis, one can get by with a single nonstandard universe, constructed as an ultrapower of the standard universe; but to correctly model all the epsilons occuring in Szemerédi’s argument, one needs to repeatedly perform the ultrapower construction to obtain a (finite) sequence of increasingly nonstandard (and increasingly saturated) universes, each one containing unbounded quantities that are far larger than any quantity that appears in the preceding universe, as discussed at the end of this previous blog post. This sequence of universes does end up concealing all the epsilons, but it is not so clear that this is a net gain in clarity for the proof; I may return to the nonstandard presentation of Szemeredi’s argument at some future juncture.)
Instead of trying to describe the entire argument here, I thought I would instead show some key components of it, with only the slightest hint as to how to assemble the components together to form the whole proof. In particular, I would like to show how two particular ingredients in the proof – namely van der Waerden’s theorem and the Szemerédi regularity lemma – become useful. For reasons that will hopefully become clearer later, it is convenient not only to work with ordinary progressions 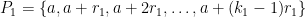
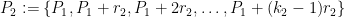
To illustrate some of the basic ideas, let us first consider a situation in which we have located a progression 

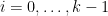

where 
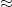




If we write 


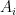
By hypothesis, we know already that each set 

Let us now make a “weakly mixing” assumption on the

for “most” subsets 


We will inductively consider the following (nonrigorously defined) sequence of claims 

-
, there are
arithmetic progressions
, such that
for all
.
(Actually, to avoid boundary issues one should restrict 




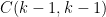

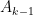


We can heuristically justify the claims 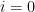
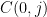
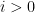

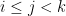



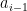
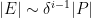
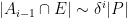
which then gives the desired claim
The observant reader will note that we only needed the claim 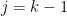

We now return to the question of how to justify the weak mixing hypothesis (2). For a single block
Proposition 2 (Single upper bound) Let
be a progression of progressions
, the set
in
such that

Proof: The key is the double counting identity

Because
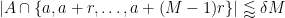
for each 

The claim then follows from the pigeonhole principle.

Now suppose we want to obtain weak mixing not just for a single set 

for all 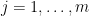
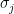

Proposition 3 (Multiple upper bound) Let
, let
. Then (if
simultaneously for all

Proof: Suppose that the claim failed (for some suitably large 
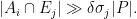
This can be viewed as a colouring of the interval 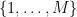

One nice thing about this proposition is that the upper bounds can be automatically upgraded to an asymptotic:
Proposition 4 (Multiple mixing) Let
simultaneously for all
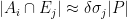
Proof: By applying the previous proposition to the collection of sets 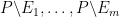
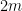
and

which gives the claim.
However, this improvement of Proposition 2 turns out to not be strong enough for applications. The reason is that the number 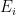
Proposition 5 (Really multiple mixing) Let
in some (large) finite set
be a subset of
. Then (if
simultaneously for almost all
.

Proof: We build a bipartite graph 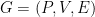
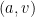

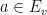
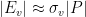

We now apply the regularity lemma to this graph 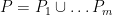


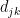



and the number

The point here is that the 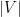
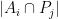
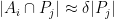
simultaneously for all
This proposition now suggests a way forward to establish the type of mixing properties (2) needed for the preceding attempt at proving Szemerédi’s theorem to actually work. Whereas in that attempt, we were working with a single progression of progressions 
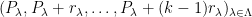

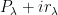
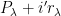
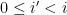
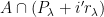

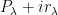
Of course, we still have to figure out how to get such large families of well-arranged progressions of progressions. Szemerédi’s solution was to begin by working with generalised progressions of a much larger rank 

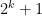

Many structures in mathematics are incomplete in one or more ways. For instance, the field of rationals 



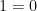
Similarly, the rationals 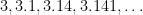

A third type of incompleteness is that of logical incompleteness, which applies now to formal theories rather than to fields or metric spaces. For instance, Zermelo-Frankel-Choice (ZFC) set theory is logically incomplete, because there exist statements (such as the consistency of ZFC) which could potentially be provable by the theory (because it does not lead to a contradiction, or at least so we believe, just from the axioms and deductive rules of the theory), but is not actually provable in this theory.
A fourth type of incompleteness, which is slightly less well known than the above three, is what I will call elementary incompleteness (and which model theorists call the failure of the countable saturation property). It applies to any structure that is describable by a first-order language, such as a field, a metric space, or a universe of sets. For instance, in the language of ordered real fields, the real line 


In each of these cases, though, it is possible to start with an incomplete structure and complete it to a much larger structure to eliminate the incompleteness. For instance, starting with an arbitrary field 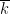
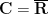
Similarly, starting with an arbitrary metric space 

In a similar vein, we have the Gödel completeness theorem, which implies (among other things) that for any consistent first-order theory 



Finally, if one starts with an arbitrary structure 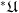
As mentioned earlier, completion tends to make a space much larger and more complicated. If one algebraically completes a finite field, for instance, one necessarily obtains an infinite field as a consequence. If one metrically completes a countable metric space with no isolated points, such as 
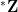
However, there are substantial benefits to working in the completed structure which can make it well worth the massive increase in size. For instance, by working in the algebraic completion of a field, one gains access to the full power of algebraic geometry. By working in the metric completion of a metric space, one gains access to powerful tools of real analysis, such as the Baire category theorem, the Heine-Borel theorem, and (in the case of Euclidean completions) the Bolzano-Weierstrass theorem. By working in a logically and elementarily completed theory (aka a saturated model) of a first-order theory, one gains access to the branch of model theory known as definability theory, which allows one to analyse the structure of definable sets in much the same way that algebraic geometry allows one to analyse the structure of algebraic sets. Finally, when working in an elementary completion of a structure, one gains a sequential compactness property, analogous to the Bolzano-Weierstrass theorem, which can be interpreted as the foundation for much of nonstandard analysis, as well as providing a unifying framework to describe various correspondence principles between finitary and infinitary mathematics.
In this post, I wish to expand upon these above points with regard to elementary completion, and to present nonstandard analysis as a completion of standard analysis in much the same way as, say, complex algebra is a completion of real algebra, or real metric geometry is a completion of rational metric geometry.
In a previous post, we discussed the Szemerédi regularity lemma, and how a given graph could be regularised by partitioning the vertex set into random neighbourhoods. More precisely, we gave a proof of
Lemma 1 (Regularity lemma via random neighbourhoods) Let
. Then there exists integers
with the following property: whenever
at random from
uniformly from
vertex cells
(some of which can be empty) generated by the vertex neighbourhoods
for
, will obey the regularity property
with probability at least
, where the sum is over all pairs
for which
-regular between
. [Recall that a pair
is
for any
and
with
, where
is the density of edges between


The proof was a combinatorial one, based on the standard energy increment argument.
In this post I would like to discuss an alternate approach to the regularity lemma, which is an infinitary approach passing through a graph-theoretic version of the Furstenberg correspondence principle (mentioned briefly in this earlier post of mine). While this approach superficially looks quite different from the combinatorial approach, it in fact uses many of the same ingredients, most notably a reliance on random neighbourhoods to regularise the graph. This approach was introduced by myself back in 2006, and used by Austin and by Austin and myself to establish some property testing results for hypergraphs; more recently, a closely related infinitary hypergraph removal lemma developed in the 2006 paper was also used by Austin to give new proofs of the multidimensional Szemeredi theorem and of the density Hales-Jewett theorem (the latter being a spinoff of the polymath1 project).
For various technical reasons we will not be able to use the correspondence principle to recover Lemma 1 in its full strength; instead, we will establish the following slightly weaker variant.
Lemma 2 (Regularity lemma via random neighbourhoods, weak version) Let
with the following property: whenever
such that if one selects
uniformly from
vertex cells
generated by the vertex neighbourhoods
, will obey the regularity property (1) with probability at least
.
Roughly speaking, Lemma 1 asserts that one can regularise a large graph 
In the theory of dense graphs on
Lemma 1 (Regularity lemma, standard version) Let
. Then there exists a partition of the vertices
, with
bounded below by
and above by a quantity
depending only on
, obeying the following properties:
- (Equitable partition) For any
, the cardinalities
of
.
- (Regularity) For all but at most
pairs
, the portion of the graph
for any
, where

This lemma becomes useful in the regime when 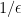
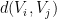
For various technical reasons it is easier to work with a slightly weaker version of the lemma, which allows for the cells 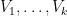
Lemma 2 (Regularity lemma, weighted version) Let
bounded above by a quantity
depending only on
- (Regularity) One has
where the sum is over all pairs
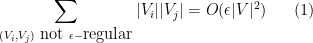
While Lemma 2 is, strictly speaking, weaker than Lemma 1 in that it does not enforce the equitable size property between the atoms, in practice it seems that the two lemmas are roughly of equal utility; most of the combinatorial consequences of Lemma 1 can also be proven using Lemma 2. The point is that one always has to remember to weight each cell 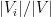
One disadvantage of the greedy algorithm is that it is not efficient in the limit 

Lemma 3 (Regularity lemma via random neighbourhoods) Let
.
Thus, roughly speaking, one can regularise a graph simply by taking a large number of random vertex neighbourhoods, and using the partition (or Venn diagram) generated by these neighbourhoods as the partition. The intuition is that if there is any non-uniformity in the graph (e.g. if the graph exhibits bipartite behaviour), this will bias the random neighbourhoods to seek out the partitions that would regularise that non-uniformity (e.g. vertex neighbourhoods would begin to fill out the two vertex cells associated to the bipartite property); if one takes sufficiently many such random neighbourhoods, the probability that all detectable non-uniformity is captured by the partition should converge to
This fact seems to be reasonably well-known folklore, discovered independently by many authors; it is for instance quite close to the graph property testing results of Alon and Shapira, and also appears implicitly in a paper of Ishigami, as well as a paper of Austin (and perhaps even more implicitly in a paper of myself). However, in none of these papers is the above lemma stated explicitly. I was asked about this lemma recently, so I decided to provide a proof here.

Recent Comments