
You are currently browsing the tag archive for the ‘Szemeredi-Trotter theorem’ tag.
Abdul Basit, Artem Chernikov, Sergei Starchenko, Chiu-Minh Tran and I have uploaded to the arXiv our paper Zarankiewicz’s problem for semilinear hypergraphs. This paper is in the spirit of a number of results in extremal graph theory in which the bounds for various graph-theoretic problems or results can be greatly improved if one makes some additional hypotheses regarding the structure of the graph, for instance by requiring that the graph be “definable” with respect to some theory with good model-theoretic properties.
A basic motivating example is the question of counting the number of incidences between points and lines (or between points and other geometric objects). Suppose one has 
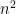



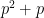




More generally, bounding on the size of bipartite graphs (or multipartite hypergraphs) not containing a copy of some complete bipartite subgraph 
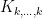


In our paper we improve the
Theorem 1 Suppose one has
- (i) The total number of incidences is
.
- (ii) If all the rectangles are dyadic, the bound can be improved to
.
- (iii) The bound in (ii) is best possible (up to the choice of implied constant).
We don’t know whether the bound in (i) is similarly tight for non-dyadic boxes; the usual tricks for reducing the non-dyadic case to the dyadic case strangely fail to apply here. One can generalise to higher dimensions, replacing rectangles by polytopes with faces in some fixed finite set of orientations, at the cost of adding several more logarithmic factors; also, one can replace the reals by other ordered division rings, and replace polytopes by other sets of bounded “semilinear descriptive complexity”, e.g., unions of boundedly many polytopes, or which are cut out by boundedly many functions that enjoy coordinatewise monotonicity properties. For certain specific graphs we can remove the logarithmic factors entirely. We refer to the preprint for precise details.
The proof techniques are combinatorial. The proof of (i) relies primarily on the order structure of 

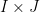


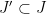

![{[R_-,R_+] := \{ R: R_- \leq R \leq R_+\}}](https://s0.wp.com/latex.php?latex=%7B%5BR_-%2CR_%2B%5D+%3A%3D+%5C%7B+R%3A+R_-+%5Cleq+R+%5Cleq+R_%2B%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Jozsef Solymosi and I have just uploaded to the arXiv our paper “An incidence theorem in higher dimensions“, submitted to Discrete and Computational Geometry. In this paper we use the polynomial Ham Sandwich method of Guth and Katz (as discussed previously on this blog) to establish higher-dimensional versions of the Szemerédi-Trotter theorem, albeit at the cost of an epsilon loss in exponents.
Recall that the Szemerédi-Trotter theorem asserts that given any finite set of points 



Apart from the constant factor, this bound is sharp. As discussed in this previous blog post, this theorem can be proven by the polynomial method, and the strategy can be rapidly summarised as follows. Select a parameter 
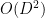
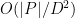
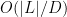
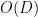


As a general rule, the contribution of the cell interiors becomes easier to handle as 
In higher dimensions, though, the complexity of the algebraic geometry required to control medium degree algebraic sets increases sharply; compare for instance the algebraic geometry of ruled surfaces appearing in the three-dimensional work of Guth and Katz as discussed here, compared with the algebraic geometry of curves in the two-dimensional Szemerédi-Trotter theorem discussed here.
However, Jozsef and I discovered that it is also possible to use the polynomial method with a non-optimised value of 


for the cell interiors, and so provided that one can also control incidences on the (low degree) cell boundary, we see that we have closed the induction (up to changes in the implied constants in the 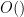
Unfortunately, as is well known, the fact that the implied constants in the

for any fixed 

Indeed, as a consequence of this strategy (and also a generic projection argument to cut down the ambient dimension, as used in this previous paper with Ellenberg and Oberlin, and an induction on dimension), we obtain in our paper a higher-dimensional incidence theorem:
Theorem 1 (Higher-dimensional Szemerédi-Trotter theorem) Let
, and let
, such that any two
for any
Something like the transversality hypothesis that any two 

Actually, for inductive reasons, we prove a more general result than Theorem 1, in which the 
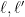

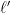
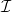


as a single diagram, rather than to consider just the sets
The reason for working in this greater level of generality is that it becomes much easier to use an induction hypothesis to deal with the cell boundary; one simply intersects each variety 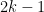
As one application of this more general incidence result, we almost extend a classic result of Spencer, Szemerédi, and Trotter asserting that 

The ham sandwich theorem asserts that, given 
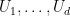
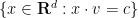


A useful generalisation of the ham sandwich theorem is the polynomial ham sandwich theorem, which asserts that given 
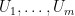
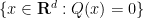
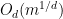
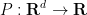
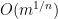
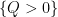
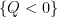
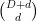
The polynomial ham sandwich theorem is a theorem about continuous bodies (bounded open sets), but a simple limiting argument leads one to the following discrete analogue: given 
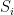
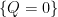
Proposition 1 (Cell decomposition) Let
of degree at most
into the hypersurface
of cells bounded by
, such that
, and such that each cell
contains at most
points.
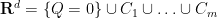
A proof is sketched in this previous blog post. The cells in the argument are not necessarily connected (being instead formed by intersecting together a number of semi-algebraic sets such as 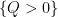
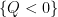


Remark 1 By setting
, we obtain as a limiting case of the cell decomposition the fact that any finite set
The cell decomposition can be viewed as a structural theorem for arbitrary large configurations of points in space, much as the Szemerédi regularity lemma can be viewed as a structural theorem for arbitrary large dense graphs. Indeed, just as many problems in the theory of large dense graphs can be profitably attacked by first applying the regularity lemma and then inspecting the outcome, it now seems that many problems in combinatorial incidence geometry can be attacked by applying the cell decomposition (or a similar such decomposition), with a parameter
In this post, I wanted to record a simpler (but still illustrative) version of this method (that I learned from Nets Katz), namely to provide yet another proof of the Szemerédi-Trotter theorem in incidence geometry:
Theorem 2 (Szemerédi-Trotter theorem) Given a finite set of points
has cardinality
This theorem has many short existing proofs, including one via crossing number inequalities (as discussed in this previous post) or via a slightly different type of cell decomposition (as discussed here). The proof given below is not that different, in particular, from the latter proof, but I believe it still serves as a good introduction to the polynomial method in combinatorial incidence geometry.
The celebrated Szemerédi-Trotter theorem gives a bound for the set of incidences

where we use the asymptotic notation 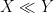

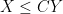

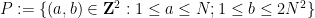


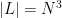
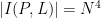
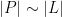

On the other hand, if one replaces the Euclidean plane 



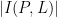
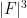

Nowadays, the slickest proof of the Szemerédi-Trotter theorem is via the crossing number inequality (as discussed in this previous post), which ultimately relies on Euler’s famous formula 
Roughly speaking, the idea is this. Using nothing more than the axiom that two points determine at most one line, one can obtain the bound
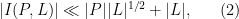
which is inferior to (1). (On the other hand, this estimate works in both Euclidean and finite field geometries, and is sharp in the latter case, as shown by the example given earlier.) Dually, the axiom that two lines determine at most one point gives the bound
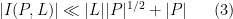
(or alternatively, one can use projective duality to interchange points and lines and deduce (3) from (2)).
An inspection of the proof of (2) shows that it is only expected to be sharp when the bushes 
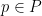
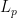

However, in Euclidean space, we have the phenomenon that the bush of a point 


More formally, the argument proceeds by applying the following lemma:
Lemma 1 (Cell decomposition) Let
. Then it is possible to find a set
of
lines in
convex regions (or cells), such that the interior of each such cell is incident to at most
lines.
The deduction of (1) from (2), (3) and Lemma 1 is very quick. Firstly we may assume we are in the range

otherwise the bound (1) follows already from either (2) or (3) and some high-school algebra.
Let 

We optimise this by selecting 



We can iterate away the 
It remains to prove (1). If one subdivides 
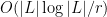
It is also worth noting that the original (somewhat complicated) argument of Szemerédi-Trotter has been adapted to establish the analogue of (1) in the complex plane

Recent Comments