
You are currently browsing the tag archive for the ‘ultraproducts’ tag.
(This is an extended blog post version of my talk “Ultraproducts as a Bridge Between Discrete and Continuous Analysis” that I gave at the Simons institute for the theory of computing at the workshop “Neo-Classical methods in discrete analysis“. Some of the material here is drawn from previous blog posts, notably “Ultraproducts as a bridge between hard analysis and soft analysis” and “Ultralimit analysis and quantitative algebraic geometry“‘. The text here has substantially more details than the talk; one may wish to skip all of the proofs given here to obtain a closer approximation to the original talk.)
Discrete analysis, of course, is primarily interested in the study of discrete (or “finitary”) mathematical objects: integers, rational numbers (which can be viewed as ratios of integers), finite sets, finite graphs, finite or discrete metric spaces, and so forth. However, many powerful tools in mathematics (e.g. ergodic theory, measure theory, topological group theory, algebraic geometry, spectral theory, etc.) work best when applied to continuous (or “infinitary”) mathematical objects: real or complex numbers, manifolds, algebraic varieties, continuous topological or metric spaces, etc. In order to apply results and ideas from continuous mathematics to discrete settings, there are basically two approaches. One is to directly discretise the arguments used in continuous mathematics, which often requires one to keep careful track of all the bounds on various quantities of interest, particularly with regard to various error terms arising from discretisation which would otherwise have been negligible in the continuous setting. The other is to construct continuous objects as limits of sequences of discrete objects of interest, so that results from continuous mathematics may be applied (often as a “black box”) to the continuous limit, which then can be used to deduce consequences for the original discrete objects which are quantitative (though often ineffectively so). The latter approach is the focus of this current talk.
The following table gives some examples of a discrete theory and its continuous counterpart, together with a limiting procedure that might be used to pass from the former to the latter:
| (Discrete) | (Continuous) | (Limit method) |
| Ramsey theory | Topological dynamics | Compactness |
| Density Ramsey theory | Ergodic theory | Furstenberg correspondence principle |
| Graph/hypergraph regularity | Measure theory | Graph limits |
| Polynomial regularity | Linear algebra | Ultralimits |
| Structural decompositions | Hilbert space geometry | Ultralimits |
| Fourier analysis | Spectral theory | Direct and inverse limits |
| Quantitative algebraic geometry | Algebraic geometry | Schemes |
| Discrete metric spaces | Continuous metric spaces | Gromov-Hausdorff limits |
| Approximate group theory | Topological group theory | Model theory |
As the above table illustrates, there are a variety of different ways to form a limiting continuous object. Roughly speaking, one can divide limits into three categories:
- Topological and metric limits. These notions of limits are commonly used by analysts. Here, one starts with a sequence (or perhaps a net) of objects
in a common space
, which one then endows with the structure of a topological space or a metric space, by defining a notion of distance between two points of the space, or a notion of open neighbourhoods or open sets in the space. Provided that the sequence or net is convergent, this produces a limit object
, which remains in the same space, and is “close” to many of the original objects
- Categorical limits. These notions of limits are commonly used by algebraists. Here, one starts with a sequence (or more generally, a diagram) of objects
or the inverse limit
of these objects, which is another object in the same category
- Logical limits. These notions of limits are commonly used by model theorists. Here, one starts with a sequence of objects
or of spaces
, each of which is (a component of) a model for given (first-order) mathematical language (e.g. if one is working in the language of groups,
or a new space
, which is still a model of the same language (e.g. if the spaces
.)
The purpose of this talk is to highlight the third type of limit, and specifically the ultraproduct construction, as being a “universal” limiting procedure that can be used to replace most of the limits previously mentioned. Unlike the topological or metric limits, one does not need the original objects
With so few requirements on the objects
Ultraproducts are not the only logical limit in the model theorist’s toolbox, but they are one of the simplest to set up and use, and already suffice for many of the applications of logical limits outside of model theory. In this post, I will set out the basic theory of these ultraproducts, and illustrate how they can be used to pass between discrete and continuous theories in each of the examples listed in the above table.
Apart from the initial “one-time cost” of setting up the ultraproduct machinery, the main loss one incurs when using ultraproduct methods is that it becomes very difficult to extract explicit quantitative bounds from results that are proven by transferring qualitative continuous results to the discrete setting via ultraproducts. However, in many cases (particularly those involving regularity-type lemmas) the bounds are already of tower-exponential type or worse, and there is arguably not much to be lost by abandoning the explicit quantitative bounds altogether.
The rectification principle in arithmetic combinatorics asserts, roughly speaking, that very small subsets (or, alternatively, small structured subsets) of an additive group or a field of large characteristic can be modeled (for the purposes of arithmetic combinatorics) by subsets of a group or field of zero characteristic, such as the integers 

Proposition 1 (Additive rectification) Let
be a subset of the additive group
for some prime
, and let
be an integer. Suppose that
. Then there exists a map
into a subset
of the integers which is a Freiman isomorphism of order
in the sense that for any
, one has
if and only if
Furthermore
is a right-inverse of the obvious projection homomorphism from
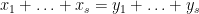
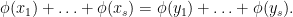
The original version of the rectification principle allowed the sets involved to be substantially larger in size (cardinality up to a small constant multiple of
The proof of Proposition 1 is quite short (see Theorem 3.1 of Bilu-Lev-Ruzsa); the main idea is to use Minkowski’s theorem to find a non-trivial dilate 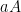
Very recently, Codrut Grosu obtained an arithmetic analogue of the above theorem, in which the rectification map
Theorem 2 (Arithmetic rectification) Let
for some prime
, and let
. Then there exists a map
and any polynomial
of degree at most
if and only if


Note that it is necessary to use an algebraically closed field such as 
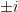

Using Theorem 2, one can transfer results in arithmetic combinatorics (e.g. sum-product or Szemerédi-Trotter type theorems) regarding finite subsets of
Grosu’s argument uses some quantitative elimination theory, and in particular a quantitative variant of a lemma of Chang that was discussed previously on this blog. In that previous blog post, it was observed that (an ineffective version of) Chang’s theorem could be obtained using only qualitative algebraic geometry (as opposed to quantitative algebraic geometry tools such as elimination theory results with explicit bounds) by means of nonstandard analysis (or, in what amounts to essentially the same thing in this context, the use of ultraproducts). One can then ask whether one can similarly establish an ineffective version of Grosu’s result by nonstandard means. The purpose of this post is to record that this can indeed be done without much difficulty, though the result obtained, being ineffective, is somewhat weaker than that in Theorem 2. More precisely, we obtain
Theorem 3 (Ineffective arithmetic rectification) Let
. Then if
is a field of characteristic at least
for some
, and
, then there exists a map
Our arguments will not provide any effective bound on the quantity
Following the principle that ultraproducts can be used as a bridge to connect quantitative and qualitative results (as discussed in these previous blog posts), we will deduce Theorem 3 from the following (well-known) qualitative version:
Proposition 4 (Baby Lefschetz principle) Let
be a field of characteristic zero that is finitely generated over the rationals. Then there is an isomorphism
from
of
This principle (first laid out in an appendix of Lefschetz’s book), among other things, often allows one to use the methods of complex analysis (e.g. Riemann surface theory) to study many other fields of characteristic zero. There are many variants and extensions of this principle; see for instance this MathOverflow post for some discussion of these. I used this baby version of the Lefschetz principle recently in a paper on expanding polynomial maps.
Proof: We give two proofs of this fact, one using transcendence bases and the other using Hilbert’s nullstellensatz.
We begin with the former proof. As 
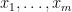


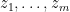
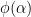

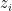
Now we give the latter proof. Let 
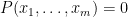
if and only if

Let 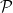


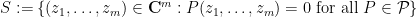
is the intersection of countably many algebraic sets and is thus also an algebraic set (by the Hilbert basis theorem or the Noetherian property of algebraic sets). If the desired claim failed, then 
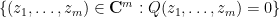


for some 
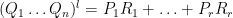
for some natural numbers 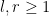
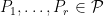

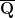
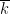


From Proposition 4 one can now deduce Theorem 3 by a routine ultraproduct argument (the same one used in these previous blog posts). Suppose for contradiction that Theorem 3 fails. Then there exists natural numbers 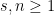
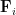

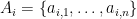
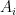
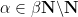
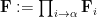
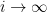
Now let 
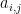

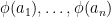

if and only if
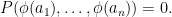
By Los’s theorem, we then conclude that for all
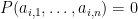
if and only if
But this gives a Freiman field isomorphism of order 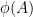
I’ve just uploaded to the arXiv my joint paper with Vitaly Bergelson, “Multiple recurrence in quasirandom groups“, which is submitted to Geom. Func. Anal.. This paper builds upon a paper of Gowers in which he introduced the concept of a quasirandom group, and established some mixing (or recurrence) properties of such groups. A 
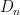
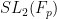


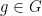

where 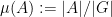




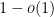

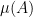
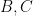

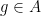
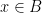
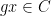



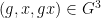

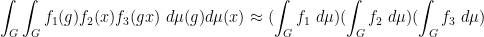
for any bounded functions 
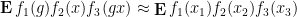
where 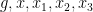
As observed in Gowers’ paper, one can iterate this observation to find “parallelopipeds” of any given dimension in dense subsets of 



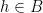
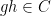
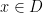
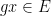
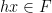
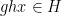

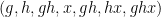

However, there are other tuples for which the above iteration argument does not seem to apply. One of the simplest tuples in this vein is the tuple 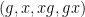

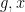
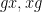


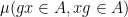

Theorem 1 Let
, we have
where
,
are drawn uniformly and independently at random from
is drawn uniformly at random from the conjugates of
for each fixed choice of
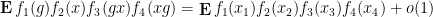
This is the probabilistic formulation of the above theorem; one can also phrase the theorem in other formulations (such as an integral formulation), and this is detailed in the paper. This theorem leads to a number of recurrence results; for instance, as a corollary of this result, we have

for almost all 
To me, the more interesting thing here is not the result itself, but how it is proven. Vitaly and I were not able to find a purely finitary way to establish this mixing theorem. Instead, we had to first use the machinery of ultraproducts (as discussed in this previous post) to convert the finitary statement about a quasirandom group to an infinitary statement about a type of infinite group which we call an ultra quasirandom group (basically, an ultraproduct of increasingly quasirandom finite groups). This is analogous to how the Furstenberg correspondence principle is used to convert a finitary combinatorial problem into an infinitary ergodic theory problem.
Ultra quasirandom groups come equipped with a finite, countably additive measure known as Loeb measure 


for “almost all” 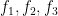

To establish this mixing theorem, we use the machinery of idempotent ultrafilters, which is a particularly useful tool for understanding the ergodic theory of actions of countable groups 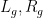
Idempotent ultrafilters are an extremely infinitary type of mathematical object (one has to use Zorn’s lemma no fewer than three times just to construct one of these objects!). So it is quite remarkable that they can be used to establish a finitary theorem such as Theorem 1, though as is often the case with such infinitary arguments, one gets absolutely no quantitative control whatsoever on the error terms 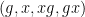
We also have some miscellaneous other results in the paper. It turns out that by using the triangle removal lemma from graph theory, one can obtain a recurrence result that asserts that whenever 



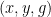
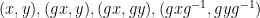
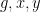
We also give some properties of a model example of an ultra quasirandom group, namely the ultraproduct 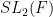
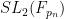

Much as group theory is the study of groups, or graph theory is the study of graphs, model theory is the study of models (also known as structures) of some language 
We will observe the common abuse of notation of using the set 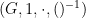
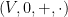




Once one has a structure 


for some formula 


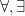

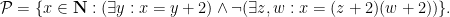
In the theory of the field of reals 
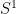
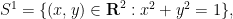
but so is the the complement of the circle,
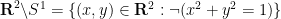
and the interval ![{[-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle [-1,1] = \{ x \in {\bf R}: \exists y: x^2+y^2 = 1\}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B-1%2C1%5D+%3D+%5C%7B+x+%5Cin+%7B%5Cbf+R%7D%3A+%5Cexists+y%3A+x%5E2%2By%5E2+%3D+1%5C%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
Due to the unlimited use of constants, any finite subset of a power 
We can isolate some special subclasses of definable sets:
- An atomic definable set is a set of the form (1) in which
is an atomic formula (i.e. it does not contain any logical connectives or quantifiers).
- A quantifier-free definable set is a set of the form (1) in which
Example 1 In the theory of a field such as
.
A quantifier-free definable set in 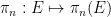
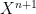
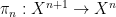

Some structures have the property of enjoying quantifier elimination, which means that every definable set is in fact a quantifier-free definable set, or equivalently that the projection of a quantifier-free definable set is again quantifier-free. For instance, an algebraically closed field 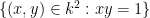
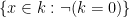
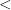
On the other hand, many important structures do not have quantifier elimination; typically, the projection of a quantifier-free definable set is not, in general, quantifier-free definable. This failure of the projection property also shows up in many contexts outside of model theory; for instance, Lebesgue famously made the error of thinking that the projection of a Borel measurable set remained Borel measurable (it is merely an analytic set instead). Turing’s halting theorem can be viewed as an assertion that the projection of a decidable set (also known as a computable or recursive set) is not necessarily decidable (it is merely semi-decidable (or recursively enumerable) instead). The notorious P=NP problem can also be essentially viewed in this spirit; roughly speaking (and glossing over the placement of some quantifiers), it asks whether the projection of a polynomial-time decidable set is again polynomial-time decidable. And so forth. (See this blog post of Dick Lipton for further discussion of the subtleties of projections.)
Now we consider the status of quantifier elimination for the theory of a finite field 
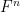
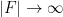


Another way to proceed is to work not with a single finite field 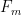
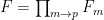

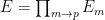
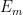


The ultraproduct
As mentioned before, quantifier elimination trivially holds for finite fields. But for infinite pseudo-finite fields, such as the ultraproduct 
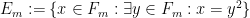

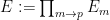

Nevertheless, there is a very nice almost quantifier elimination result for these fields, in characteristic zero at least, which we phrase here as follows:
Theorem 1 (Almost quantifier elimination) Let
be a definable set over
where
is an atomic definable subset of
is a polynomial.

Results of this type were first obtained essentially due to Catarina Kiefe, although the formulation here is closer to that of Chatzidakis-van den Dries-Macintyre.
Informally, this theorem says that while we cannot quite eliminate all quantifiers from a definable set over a nonstandard finite field, we can eliminate all but one existential quantifier. Note that negation has also been eliminated in this theorem; for instance, the definable set 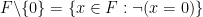


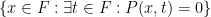
There is an equivalent formulation of this theorem for standard finite fields, namely that if 
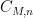
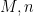
The theorem gives quite a satisfactory description of definable sets in either standard or nonstandard finite fields (at least if one does not care about effective bounds in some of the constants, and if one is willing to exclude the small characteristic case); for instance, in conjunction with the Lang-Weil bound discussed in this recent blog post, it shows that any non-empty definable subset of a nonstandard finite field has a nonstandard cardinality of 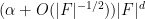

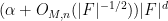

Below the fold I give a proof of Theorem 1, which relies primarily on the Lang-Weil bound mentioned above.
In the previous set of notes, we saw that one could derive expansion of Cayley graphs from three ingredients: non-concentration, product theorems, and quasirandomness. Quasirandomness was discussed in Notes 3. In the current set of notes, we discuss product theorems. Roughly speaking, these theorems assert that in certain circumstances, a finite subset 
Theorem 1 (Product theorem in
) Let
, let
. Let
be sufficiently small depending on
- (Expansion) One has
.
- (Close to
.
- (Trapping)
We will prove this theorem (which was proven first in the 
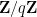

Exercise 1 (Diameter bound) Assuming Theorem 1, show that whenever
, then any element of
elements from
for some
.) This is a special case of a conjecture of Babai and Seress, who conjectured that the bound should hold uniformly for all finite simple groups (in particular, the implied constants here should not actually depend on
case can handle other finite groups of Lie type of bounded rank, but at present we do not have bounds that are independent of the rank. On the other hand, a recent paper of Helfgott and Seress has almost resolved the conjecture for the permutation groups
.
A key tool to establish product theorems is an argument which is sometimes referred to as the pivot argument. To illustrate this argument, let us first discuss a much simpler (and older) theorem, essentially due to Freiman, which has a much weaker conclusion but is valid in any group
Theorem 2 (Baby product theorem) Let
- (Expansion) One has
.
- (Close to a subgroup)
with
.
To prove this theorem, we suppose that the first conclusion does not hold, thus 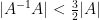
To do this, we take a group element 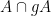
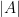
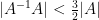

Proposition 3 (Dichotomy) If
- (Non-involved case)
is empty.
- (Involved case)
.
Proof: Suppose we are not in the pivot case, so that 


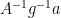
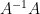

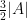
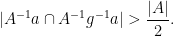
But the left-hand side is equal to 
The above proposition provides a clear separation between two types of elements 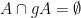

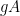
Proposition 4 The set
.
Proof: It is clear that the identity element 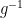
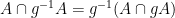
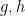


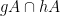
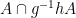

If 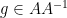
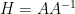
Now we can quickly wrap up the proof of Theorem 2. By construction, 
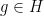
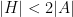

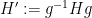

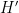
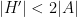
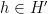


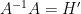
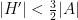
Exercise 2 Show that the constant
in Theorem 2 cannot be replaced by any larger constant.
Exercise 3 Let
be a finite non-empty set such that
. Show that
. (Hint: If
, show that
for some
.)
Exercise 4 Let
. Show that there is a finite group
and
Below the fold, we give further examples of the pivot argument in other group-like situations, including Theorem 2 and also the “sum-product theorem” of Bourgain-Katz-Tao and Bourgain-Glibichuk-Konyagin.
Roughly speaking, mathematical analysis can be divided into two major styles, namely hard analysis and soft analysis. The precise distinction between the two types of analysis is imprecise (and in some cases one may use a blend the two styles), but some key differences can be listed as follows.
- Hard analysis tends to be concerned with quantitative or effective properties such as estimates, upper and lower bounds, convergence rates, and growth rates or decay rates. In contrast, soft analysis tends to be concerned with qualitative or ineffective properties such as existence and uniqueness, finiteness, measurability, continuity, differentiability, connectedness, or compactness.
- Hard analysis tends to be focused on finitary, finite-dimensional or discrete objects, such as finite sets, finitely generated groups, finite Boolean combination of boxes or balls, or “finite-complexity” functions, such as polynomials or functions on a finite set. In contrast, soft analysis tends to be focused on infinitary, infinite-dimensional, or continuous objects, such as arbitrary measurable sets or measurable functions, or abstract locally compact groups.
- Hard analysis tends to involve explicit use of many parameters such as
,
,
, etc. In contrast, soft analysis tends to rely instead on properties such as continuity, differentiability, compactness, etc., which implicitly are defined using a similar set of parameters, but whose parameters often do not make an explicit appearance in arguments.
- In hard analysis, it is often the case that a key lemma in the literature is not quite optimised for the application at hand, and one has to reprove a slight variant of that lemma (using a variant of the proof of the original lemma) in order for it to be suitable for applications. In contrast, in soft analysis, key results can often be used as “black boxes”, without need of further modification or inspection of the proof.
- The properties in soft analysis tend to enjoy precise closure properties; for instance, the composition or linear combination of continuous functions is again continuous, and similarly for measurability, differentiability, etc. In contrast, the closure properties in hard analysis tend to be fuzzier, in that the parameters in the conclusion are often different from the parameters in the hypotheses. For instance, the composition of two Lipschitz functions with Lipschitz constant
is still Lipschitz, but now with Lipschitz constant
instead of
In the lectures so far, focusing on the theory surrounding Hilbert’s fifth problem, the results and techniques have fallen well inside the category of soft analysis. However, we will now turn to the theory of approximate groups, which is a topic which is traditionally studied using the methods of hard analysis. (Later we will also study groups of polynomial growth, which lies on an intermediate position in the spectrum between hard and soft analysis, and which can be profitably analysed using both styles of analysis.)
Despite the superficial differences between hard and soft analysis, though, there are a number of important correspondences between results in hard analysis and results in soft analysis. For instance, if one has some sort of uniform quantitative bound on some expression relating to finitary objects, one can often use limiting arguments to then conclude a qualitative bound on analogous expressions on infinitary objects, by viewing the latter objects as some sort of “limit” of the former objects. Conversely, if one has a qualitative bound on infinitary objects, one can often use compactness and contradiction arguments to recover uniform quantitative bounds on finitary objects as a corollary.
Remark 1 Another type of correspondence between hard analysis and soft analysis, which is “syntactical” rather than “semantical” in nature, arises by taking the proofs of a soft analysis result, and translating such a qualitative proof somehow (e.g. by carefully manipulating quantifiers) into a quantitative proof of an analogous hard analysis result. This type of technique is sometimes referred to as proof mining in the proof theory literature, and is discussed in this previous blog post (and its comments). We will however not employ systematic proof mining techniques here, although in later posts we will informally borrow arguments from infinitary settings (such as the methods used to construct Gleason metrics) and adapt them to finitary ones.
Let us illustrate the correspondence between hard and soft analysis results with a simple example.
Proposition 1 Let
be a continuous function (giving the extended half-line
the usual order topology). Then the following statements are equivalent:
- (i) (Qualitative bound on infinitary objects) For all
, one has
.
- (ii) (Quantitative bound on finitary objects) There exists
such that
for all
.
In applications,
Proof: To see that (ii) implies (i), observe from density that every point 

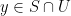
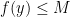

Conversely, to show that (i) implies (ii), we use the “compactness and contradiction” argument. Suppose for sake of contradiction that (ii) failed. Then for any natural number 
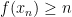
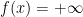
Remark 2 Note that the above deduction of (ii) from (i) is ineffective in that it gives no explicit bound on the uniform bound
The above simple example illustrates that in order to get from an “infinitary” statement such as (i) to a “finitary” statement such as (ii), a key step is to be able to take a sequence 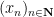
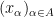
- (Topological limit) If the
- (Categorical limit) If the
to
or inverse limit
of these objects to form a limiting object
- (Logical limit) If the
or limiting space
that is a logical limit of the
The three types of limits are analogous in many ways, with a number of connections between them. For instance, in the study of groups of polynomial growth, both topological limits (using the metric notion of Gromov-Hausdorff convergence) and logical limits (using the ultralimit construction) are commonly used, and to some extent the two constructions are at least partially interchangeable in this setting. (See also these previous posts for the use of ultralimits as a substitute for topological limits.) In the theory of approximate groups, though, it was observed by Hrushovski that logical limits (and in particular, ultraproducts) are the most useful type of limit to connect finitary approximate groups to their infinitary counterparts. One reason for this is that one is often interested in obtaining results on approximate groups 
Logical limits are closely tied with non-standard analysis. Indeed, by applying an ultraproduct construction to standard number systems such as the natural numbers 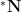
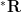
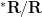
In these notes, we lay out the basic theory of ultraproducts and ultralimits (in particular, proving Los’s theorem, which roughly speaking asserts that ultralimits are limits in a logical sense, as well as the countable saturation property alluded to earlier). We also lay out some of the basic foundations of nonstandard analysis, although we will not rely too heavily on nonstandard tools in this course. Finally, we apply this general theory to approximate groups, to connect finite approximate groups to an infinitary type of approximate group which we will call an ultra approximate group. We will then study these ultra approximate groups (and models of such groups) in more detail in the next set of notes.
Remark 3 Throughout these notes (and in the rest of the course), we will assume the axiom of choice, in order to easily use ultrafilter-based tools. If one really wanted to expend the effort, though, one could eliminate the axiom of choice from the proofs of the final “finitary” results that one is ultimately interested in proving, at the cost of making the proofs significantly lengthier. Indeed, there is a general result of Gödel that any result which can be stated in the language of Peano arithmetic (which, roughly speaking, means that the result is “finitary” in nature), and can be proven in set theory using the axiom of choice (or more precisely, in the ZFC axiom system), can also be proven in set theory without the axiom of choice (i.e. in the ZF system). As this course is not focused on foundations, we shall simply assume the axiom of choice henceforth to avoid further distraction by such issues.

Recent Comments