
One of the major activities in probability theory is studying the various statistics that can be produced from a complex system with many components. One of the simplest possible systems one can consider is a finite sequence 
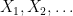

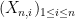

The first fundamental result about these sums is the law of large numbers (or LLN for short), which comes in two formulations, weak (WLLN) and strong (SLLN). To state these laws, we first must define the notion of convergence in probability.
Definition 1 Let
be a sequence of random variables taking values in a separable metric space
(e.g. the
or
), and let
be another random variable taking values in
. We say that
, one has
as
. Thus, if
are scalar, we have
as
The measure-theoretic analogue of convergence in probability is convergence in measure.
It is instructive to compare the notion of convergence in probability with almost sure convergence. it is easy to see that 


We have the following easy relationships between convergence in probability and almost sure convergence:
Exercise 2 Let
- (i) If
almost surely, show that
- (ii) Suppose that
for all
- (iii) If
of the
almost surely.
- (iv) If
are absolutely integrable and
as
- (v) (Urysohn subsequence principle) Suppose that every subsequence
that converges to
- (vi) Does the Urysohn subsequence principle still hold if “in probability” is replaced with “almost surely” throughout?
- (vii) If
or
is continuous, show that
converges in probability to
. More generally, if for each
,
is a sequence of scalar random variables that converge in probability to
, and
or
is continuous, show that
converges in probability to
. (Thus, for instance, if
converge in probability to
respectively, then
and
converge in probability to
and
respectively.
- (viii) (Fatou’s lemma for convergence in probability) If
.
- (ix) (Dominated convergence in probability) If
for all
and some absolutely integrable
converges to
.
Exercise 3 Let
- (i) Suppose that there is a random variable
. Show that
- (ii) Suppose that the
such that
almost surely).
We can now state the weak and strong law of large numbers, in the model case of iid random variables.
Theorem 4 (Law of large numbers, model case) Let
be an iid sequence of copies of an absolutely integrable random variable
, and for each natural number
denote the random variable
.
- (i) (Weak law of large numbers) The random variables
converge in probability to
.
- (ii) (Strong law of large numbers) The random variables
Informally: if 
It is instructive to compare the law of large numbers with what one can obtain from the Kolmogorov zero-one law, discussed in Notes 2. Observe that if the 





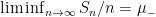

The law of large numbers asserts, roughly speaking, that the theoretical expectation 
There are several ways to prove the law of large numbers (in both forms). One basic strategy is to use the moment method – controlling statistics such as 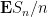

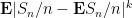


For the strong law of large numbers, one can also use methods relating to the theory of martingales, such as stopping time arguments and maximal inequalities; we present some classical arguments of Kolmogorov in this regard.
— 1. The moment method —
We begin by using the moment method to establish both the strong and weak law of large numbers for sums of iid random variables, under additional moment hypotheses.
We first make a very simple observation: in order to prove the weak or strong law of large numbers for complex variables, it suffices to do so for real variables, as the complex case follows from the real case after taking real and imaginary parts. Thus we shall restrict attention henceforth to real random variables, in order to avoid some unnecessarily complications involving complex conjugation.
Let 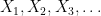



In particular, the expectation of

for any 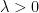

Now we turn to second moment bounds on 

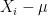

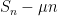


Suppose that 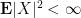




(All expressions here are absolutely integrable thanks to the Cauchy-Schwarz inequality.) If 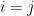


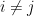


Putting all this together, we obtain

or equivalently

This bound was established in the mean zero case, but it is clear that it also holds in general, since subtracting a constant from a random variable does not affect its variance. Thus we see that while 


If we insert this variance bound into Chebyshev’s inequality, we obtain the bound

for any natural number 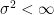

Note that (2) implies that

converges to zero in probability whenever 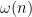

in probability. Informally, this means that 
One can hope to use (2) and the Borel-Cantelli lemma (Exercise 2(ii)) to also obtain the strong law of large numbers in the second moment case, but unfortunately the quantities 
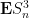

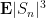

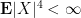




Note that all expectations here are absolutely integrable by Hölder’s inequality and the hypothesis of finite fourth moment. The correlation 



since 



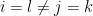
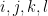




Similarly for the cases 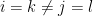

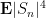


and hence by Markov’s inequality

for any 

The right-hand side decays like 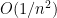
One can of course continue to compute higher and higher moments of
We begin with two quick applications of the weak law of large numbers to topics outside of probability. We first give an explicit version of the Weierstrass approximation theorem, which asserts that continuous functions on (say) the unit interval ![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Proposition 5 (Approximation by Bernstein polynomials) Let
be a continuous function. Then the Bernstein polynomials
converges uniformly to
as

Proof: We first establish the pointwise bound 
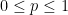



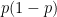

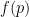





To establish the uniform convergence, we use the proof of the weak law of large numbers, rather than the statement of that law, to get the desired uniformity in the parameter

for any 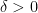


![{x,y \in [0,1]}](https://s0.wp.com/latex.php?latex=%7Bx%2Cy+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



On the other hand, being continuous on 


and thus by the triangle inequality and the identity

Since
The other application of the weak law of large numbers is to the geometry of high-dimensional cubes, giving the rather unintuitive conclusion that most of the volume of the high-dimensional cube is contained in a thin annulus.

Proposition 6 Let
of the cube
(by
.
This proposition already indicates that high-dimensional geometry can behave in a manner quite differently from what one might naively expect from low-dimensional geometric intuition; one needs to develop a rather distinct high-dimensional geometric intuition before one can accurately make predictions in large dimensions.
Proof: Let ![{[-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



Hence, by the weak law of large numbers, the quantity 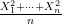
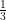

goes to zero as
The first and second moment method are very general, and apply to sums 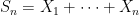

(assuming of course that

(assuming now that

Remark 7 Viewing the variance as the square of the standard deviation, the identity (4) can be interpreted as a rigorous instantiation of the following informal principle of square root cancellation: if one has a sum
(in the sense that a statistic such as the standard deviation of
. Thus for instance a sum of
would be expected to have magnitude about
These identities, together with Chebyshev’s inequality, already gives some useful control on many statistics, including some which are not obviously of the form of a sum of independent random variables. A classic example of this is the coupon collector problem, which we formulate as follows. Let 

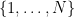
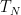

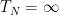
At first glance, 

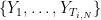

If we then write 
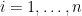

Remarkably, the random variables 
Proposition 8 The random variables
, in the sense that
for
and
.

The joint independence of the
Proof: It suffices to show that


for any choice of natural numbers 

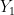
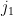



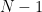





Exercise 9 Show that if
(thus
for all
) then
and variance
.
From the above proposition and exercise as well as (3), (4) we see that

and

From the integral test (and crudely bounding 

and

where we use the usual asymptotic notation of denoting by 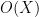


for any 


Another application of the weak and strong law of large numbers (even with the moment hypotheses currently imposed on these laws) is a converse to the Borel-Cantelli lemma in the jointly independent case:
Exercise 10 (Second Borel-Cantelli lemma) Let
be a sequence of jointly independent events. If
, show that almost surely an infinite number of the
hold simultaneously. (Hint: compute the mean and variance of
. One can also compute the fourth moment if desired, but it is not necessary to do so for this result.)
One application of the second Borel-Cantelli lemma has the colourful name of the “infinite monkey theorem“:
Exercise 11 (Infinite monkey theorem) Let
. Show that almost surely, every finite word
of letters
in the alphabet appears infinitely often in the string
.
In the usual formulation of the weak or strong law of large numbers, we draw the sums
Exercise 12 (Triangular arrays) Let
be a triangular array of scalar random variables
, such that for each
is a collection of independent random variables. For each
.
- (i) (Weak law) If all the
, show that
- (ii) (Strong law) If all the
, show that
Note that the weak and strong law of large numbers established previously corresponds to the case 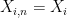
We now illustrate the use of moment method and law of large number methods to two important examples of random structures, namely random graphs and random matrices.
Exercise 13 For a natural number
on a (deterministic) vertex set
of
possible graphs one can place on
for unordered pairs
in
For eachbe an Erdös-Renyi graph on
(we do not require the graphs to be independent of each other).
- (i) If
is the number of edges in
converges almost surely to
- (ii) If
is the number of triangles in
in
such that
), show that
converges in probability to
. (Note: there is not quite enough joint independence here to directly apply the law of large numbers, however the second moment method still works nicely.)
- (iii) Show in fact that
Exercise 14 For each
be a random
matrix (i.e. a random variable taking values in the space
or
of
of
are jointly independent in
and take values in
with a probability of
.
- (i) Show that the random variables
are deterministically equal to
denotes the adjoint (which, in this case, is also the transpose) of
denotes the trace (sum of the diagonal entries) of a matrix.
- (ii) Show that for any natural number
, the quantities
are bounded uniformly in
that can depend on
or
to gain intuition.)
- (iii) If
denotes the operator norm of
converges almost surely to zero, and that
diverges almost surely to infinity. (Hint: use the spectral theorem to relate
.)
One can obtain much sharper information on quantities such as the operator norm of a random matrix; see this previous blog post for further discussion.
Exercise 15 The Cramér random model for the primes is a random subset
of the natural numbers with
,
, and the events
for
being jointly independent with
(the restriction to
is to ensure that
is less than
, which can be used to provide heuristic confirmations for many conjectures in analytic number theory. (It can be refined to give what are believed to be more accurate predictions; see this previous blog post for further discussion.)
- (i) (Probabilistic prime number theorem) Prove that almost surely, the quantity
converges to one as
.
- (ii) (Probabilistic Riemann hypothesis) Show that if
converges almost surely to zero as
- (iii) (Probabilistic twin prime conjecture) Show that almost surely, there are an infinite number of elements
also lies in
- (iv) (Probabilistic Goldbach conjecture) Show that almost surely, all but finitely many natural numbers

Probabilistic methods are not only useful for getting heuristic predictions about the primes; they can also give rigorous results about the primes. We give one basic example, namely a probabilistic proof (due to Turán) of a theorem of Hardy and Ramanujan, which roughly speaking asserts that a typical large number 
Exercise 16 (Hardy-Ramanujan theorem) Let
be a natural number (so in particular
), and let
. Assume Mertens’ theorem
for all
- (i) Show that the random variable
(where
is
otherwise, and the sum is over primes up to
) has mean
and variance
. (Hint: compute (up to reasonable error) the means, variances and covariances of the random variables
- (ii) If
converges to
.) More precisely, show that
converges in probability to zero, whenever
is any function such that
goes to infinity as


Exercise 17 (Shannon entropy) Let
, and let
to be the quantity
with the convention that
. (In some texts, the logarithm to base
is used instead of the natural logarithm
.)
- (i) Show that
. (Hint: use Jensen’s inequality.) Determine when the equality
holds.
- (ii) Let
is a random variable taking values in
, and the distribution
is a probability measure on
denote the set
Show that if
and
(Hint: use the weak law of large numbers to understand the number of times each element
.)
Thus, roughly speaking, while
, and is roughly uniformly distributed on that set. This is the beginning of the microstate interpretation of Shannon entropy, but we will not develop the theory of Shannon entropy further in this course.






— 2. Truncation —
The weak and strong laws of large numbers have been proven under additional moment assumptions (of finite second moment and finite fourth moment respectively). To remove these assumptions, we use the simple but effective truncation method, decomposing a general scalar random variable 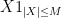


Let’s first see how this works with the weak law of large numbers. As before, we assume we have an iid sequence 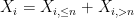
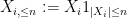
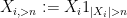


and


as

We begin by studying 
The random variables 



Thus, 
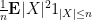


and hence by the Chebyshev inequality

Observe that 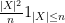
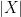

as
To handle 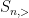




By dominated convergence again, 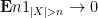

Putting all this together, we conclude (5) as required. This concludes the proof of the weak law of large numbers (in the iid case) for arbitrary absolutely integrable

whenever
Due to the reliance on the dominated convergence theorem, the above argument does not provide any uniform rate of decay in (5). Indeed there is no such uniform rate. Consider for instance the sum 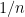
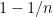

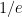

that holds uniformly whenever 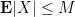


One can ask what happens to the
Exercise 18 Let
as
.
The above exercise shows that 

for 

This suggests, paradoxically, that any finite price for this lottery, no matter how high, would be a bargain!
To clarify this paradox, we need to get a better understanding of the random variable 
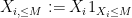



and

The random variable 

and we can upper bound the variance by



and hence 
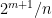

for any
Now we turn to 


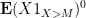

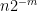

This bound is valid for any natural number 
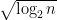

which (for large

In particular, we see that 
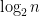

In contrast to the absolutely integrable case, in which the weak law can be upgraded to the strong law, there is no strong law for the Saint Petersburg paradox:
Exercise 19 With the notation as in the above analysis of the Saint Petersburg paradox, show that
is almost surely unbounded. (Hint: it suffices to show that
is almost surely unbounded. For this, use the second Borel-Cantelli lemma.)
The following exercise can be viewed as a continuous analogue of the Saint Petersburg paradox.
Exercise 20 A real random variable
.
- (i) Verify that standard Cauchy distributions exist (this boils down to checking that the integral of the probability density function is
- (ii) Show that a real random variable with the standard Cauchy distribution is not absolutely integrable.
- (iii) If
converges in probability to
but is almost surely unbounded.
Exercise 21 (Weak law of large numbers for triangular arrays) Let
be a triangular array of random variables, with the variables
be a sequence going to infinity, and write
and
. Assume that
and
as
in probability.



Now we turn to establishing the strong law of large numbers in full generality. A first attempt would be to apply the Borel-Cantelli lemma to the bound (6). However, the decay rates for quantities such as 
We turn to the details. In previous arguments it was convenient to normalise the underlying random variable 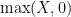

Henceforth we assume 
Lemma 22 Let
be an increasing sequence, and let
converges to
, where
. Then
Proof: Let 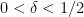


and (for sufficiently large

and thus

Taking limit inferior and superior, we conclude that

and then sending 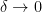
An inspection of the above argument shows that we only need to verify the hypothesis for a countable sequence of 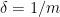
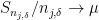
Fix 

whenever 

and

are finite. Using the monotone convergence theorem to interchange the sum and expectation, it thus suffices to show the pointwise estimates

and

for some 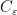
We remark that by carefully inspecting the above proof of the strong law of large numbers, we see that the hypothesis of joint independence of the
The next exercise shows how one can use the strong law of large numbers to approximate the cumulative distribution function of a random variable
Exercise 23 Let
- (i) Show that for every real number
, one has almost surely that
and
as
- (ii) Establish the Glivenko-Cantelli theorem: almost surely, one has
uniformly in
denote the largest integer multiple of
less than
is within
of
for all


Exercise 24 (Lack of strong law for triangular arrays) Let
, where
(this is an example of a zeta distribution).
- (i) Show that
- (ii) Let
are almost surely unbounded. (Hint: for any constant
occurs with probability at least
for some
— 3. The Kolmogorov maximal inequality —
Let

From Chebyshev’s inequality, we thus have

for any 
Theorem 25 (Kolmogorov maximal inequality) With the notation and hypotheses as above, we have

Proof: For each 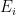




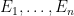

On the event 

We will shortly prove the inequality

for all 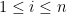

and the claim follows from (7).
It remains to prove (8). Since


we have

But note that the random variable 
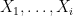



and the claim (8) follows.
An inspection of the above proof reveals that the key ingredient is the lack of correlation between past and future – a variable such as 
The Kolmogorov maximal inequality gives the following variant of the strong law of large numbers.
Theorem 26 (Convergence of random series) Let
Then the series
is almost surely convergent (i.e., the partial sums converge almost surely).

Proof: From the Kolmogorov maximal inequality and continuity from below we have

This is already enough to show that the partial sums 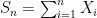


Sending

for all 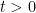
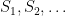
We can use this result together with some elementary manipulation of sums to give the following alternative proof of the strong law of large numbers.
Theorem 27 (Strong law of large numbers) Let
. Then
Proof: We may normalise




and hence by the Borel-Cantelli lemma we almost surely have 


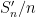
The random variables 
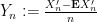





so by Theorem 26 we see that the sum 
Write 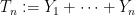
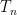

we conclude that the sequence 

almost surely. On the other hand, we have


and hence by dominated convergence

as 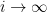

as 
Exercise 28 (Kronecker lemma) Let
be a convergent series of real numbers
be a sequence tending to infinity. Show that
converges to zero as
was implicitly used in the above argument.)
Exercise 29 (Kolmogorov three-series theorem, one direction) Let
. Suppose that the two series
and
are absolutely convergent, and the third series
is convergent. Show that the series
is almost surely convergent. (The converse claim is also true, and will be discussed in later notes; the two claims are known collectively as the Kolmogorov three-series theorem.)
One advantage that the maximal inequality approach to the strong law of large numbers has over the moment method approach is that it tends to offer superior bounds on the (almost sure) rate of convergence. We content ourselves with just one example of this:
Exercise 30 (Cheap law of iterated logarithm) Let
). Write
converges almost surely to zero as
The exercises below will be moved to a more appropriate location later, but are currently placed here in order to not disrupt existing numbering.
Exercise 31 Let
converge in
to
as

Exercise 32 A scalar random variable
Thus Markov’s inequality tells us that every absolutely integrable random variable is in weak
such that
converges in probability to

Exercise 33 Let
has the same distribution as
for
(Hint: for each

Exercise 34 (Lévy’s inequality) Let
with the property that
for
(Hint: for each
with probability at least


97 comments
Comments feed for this article
15 April, 2024 at 4:54 pm
Anonymous
Dear professor Tao: For part (i) Exercise 15, as are summable, by your previous comment and the Borel-Cantelli lemma it follows that
are summable, by your previous comment and the Borel-Cantelli lemma it follows that 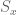 converges to
converges to  almost surely. Is this correct?
almost surely. Is this correct?
16 April, 2024 at 7:42 am
Anonymous
Wait, the root test gives 1 and one can’t conclude summability in this case. May I ask how is it that Chebyshev’s inequality is sufficient here?
23 April, 2024 at 6:39 pm
Anonymous
Dear prof Tao:
For part (i) of Exercise 15, if we let let , do you recommend calculating the fourth moment
, do you recommend calculating the fourth moment  for the Borel-Cantelli lemma? Do we need to use the triangular arrays form as in Exercise 12?
for the Borel-Cantelli lemma? Do we need to use the triangular arrays form as in Exercise 12?
25 April, 2024 at 3:56 pm
Anonymous
Dear prof Tao:
May I ask if the solution to part (2) of Exercise 15 requires the use of part (1)?
[It is a stronger statement, and is more difficult to prove. Strictly speaking one could attack (2) directly without first establishing (1), but for beginners I would recommend trying (1) first. -T.]
29 April, 2024 at 10:59 pm
Anonymous
Dear professor Tao:
In part (2) of Exercise 15, let be independent Bernoulli random variables of parameter
be independent Bernoulli random variables of parameter  . if one considers the partial sums
. if one considers the partial sums 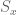 of
of  from
from  up to
up to  , where
, where  equals
equals  over
over  , then the moment method for the fourth moment stills seems not strong enough for one to show that
, then the moment method for the fourth moment stills seems not strong enough for one to show that 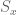 converges almost surely to zero. May I ask if this is the correct approach to pursuit, or if one needs to go to even higher moment?
converges almost surely to zero. May I ask if this is the correct approach to pursuit, or if one needs to go to even higher moment?
10 May, 2024 at 8:19 pm
Terence Tao
For this problem, one needs to work with a high moment that depends on (or else utilize a more powerful concentration inequality, such as Hoeffding’s inequality).
(or else utilize a more powerful concentration inequality, such as Hoeffding’s inequality).
7 May, 2024 at 11:35 am
Anonymous
Dear professor Tao:
Since part (3) of Exercise 15 only asks for a qualitative prediction on the number of twin Cramer random model primes, is it possible to work out a solution without obtaining a bound as explicit as the one obtained in Prediction 8 of your note for 254A, Supplement 4?
10 May, 2024 at 8:46 pm
Terence Tao
Yes, there are multiple ways to approach this question, that give various levels of strength in their conclusion. For instance, one relatively easy way to proceed here is to locate a number of independent events that would produce twins, and apply the converse of the Borel-Cantelli lemma for independent events.