This is the tenth thread for the Polymath8b project to obtain new bounds for the quantity
 ;
;
the previous thread may be found here.
Numerical progress on these bounds have slowed in recent months, although we have very recently lowered the unconditional bound on 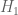 from 252 to 246 (see the wiki page for more detailed results). While there may still be scope for further improvement (particularly with respect to bounds for
from 252 to 246 (see the wiki page for more detailed results). While there may still be scope for further improvement (particularly with respect to bounds for 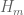 with
with 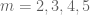 , which we have not focused on for a while, it looks like we have reached the point of diminishing returns, and it is time to turn to the task of writing up the results.
, which we have not focused on for a while, it looks like we have reached the point of diminishing returns, and it is time to turn to the task of writing up the results.
A draft version of the paper so far may be found here (with the directory of source files here). Currently, the introduction and the sieve-theoretic portions of the paper are written up, although the sieve-theoretic arguments are surprisingly lengthy, and some simplification (or other reorganisation) may well be possible. Other portions of the paper that have not yet been written up include the asymptotic analysis of  for large k (leading in particular to results for m=2,3,4,5), and a description of the quadratic programming that is used to estimate for small and medium k. Also we will eventually need an appendix to summarise the material from Polymath8a that we would use to generate various narrow admissible tuples.
for large k (leading in particular to results for m=2,3,4,5), and a description of the quadratic programming that is used to estimate for small and medium k. Also we will eventually need an appendix to summarise the material from Polymath8a that we would use to generate various narrow admissible tuples.
One issue here is that our current unconditional bounds on for m=2,3,4,5 rely on a distributional estimate on the primes which we believed to be true in Polymath8a, but never actually worked out (among other things, there was some delicate algebraic geometry issues concerning the vanishing of certain cohomology groups that was never resolved). This issue does not affect the m=1 calculations, which only use the Bombieri-Vinogradov theorem or else assume the generalised Elliott-Halberstam conjecture. As such, we will have to rework the computations for these , given that the task of trying to attain the conjectured distributional estimate on the primes would be a significant amount of work that is rather disjoint from the rest of the Polymath8b writeup. One could simply dust off the old maple code for this (e.g. one could tweak the code here, with the constraint 1080*varpi/13+ 330*delta/13<1 being replaced by 600*varpi/7+180*delta/7<1), but there is also a chance that our asymptotic bounds for (currently given in messy detail here) could be sharpened. I plan to look at this issue fairly soon.
Also, there are a number of smaller observations (e.g. the parity problem barrier that prevents us from ever getting a better bound on than 6) that should also go into the paper at some point; the current outline of the paper as given in the draft is not necessarily comprehensive.


122 comments
Comments feed for this article
17 May, 2014 at 10:27 am
Polymath 8b, XI: Finishing up the paper | What's new
[…] the previous thread may be found here. […]
26 February, 2017 at 3:55 am
samir.brahim@gmail.com
Dear All,
I have proved the twin number but no journal would like to review, ti is too scary !!
I will be happy if any one can read my Sketch of the proof’s section Page 5 and 6 only
https://arxiv.org/abs/1512.00970
Best regards
Samir