
You are currently browsing the tag archive for the ‘Emmanuel Candes’ tag.
[This post should have appeared several months ago, but I didn’t have a link to the newsletter at the time, and I subsequently forgot about it until now. -T.]
Last year, Emmanuel Candés and I were two of the recipients of the 2008 IEEE Information Theory Society Paper Award, for our paper “Near-optimal signal recovery from random projections: universal encoding strategies?” published in IEEE Inf. Thy.. (The other recipient is David Donoho, for the closely related paper “Compressed sensing” in the same journal.) These papers helped initiate the modern subject of compressed sensing, which I have talked about earlier on this blog, although of course they also built upon a number of important precursor results in signal recovery, high-dimensional geometry, Fourier analysis, linear programming, and probability. As part of our response to this award, Emmanuel and I wrote a short piece commenting on these developments, entitled “Reflections on compressed sensing“, which appears in the Dec 2008 issue of the IEEE Information Theory newsletter. In it we place our results in the context of these precursor results, and also mention some of the many active directions (theoretical, numerical, and applied) that compressed sensing is now developing in.
Emmanuel Candés and I have just uploaded to the arXiv our paper “The power of convex relaxation: near-optimal matrix completion“, submitted to IEEE Inf. Theory. In this paper we study the matrix completion problem, which one can view as a sort of “non-commutative” analogue of the sparse recovery problem studied in the field of compressed sensing, although there are also some other significant differences between the two problems. The sparse recovery problem seeks to recover a sparse vector 

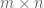
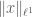
Now we turn to the matrix completion problem. Instead of an unknown vector ![M = (m_{ij})_{i \in [n_1], j \in [n_2]} \in {\Bbb R}^{n_1 \times n_2}](https://s0.wp.com/latex.php?latex=M+%3D+%28m_%7Bij%7D%29_%7Bi+%5Cin+%5Bn_1%5D%2C+j+%5Cin+%5Bn_2%5D%7D+%5Cin+%7B%5CBbb+R%7D%5E%7Bn_1+%5Ctimes+n_2%7D&bg=ffffff&fg=545454&s=0&c=20201002)
![[n] := \{1,\ldots,n\}](https://s0.wp.com/latex.php?latex=%5Bn%5D+%3A%3D+%5C%7B1%2C%5Cldots%2Cn%5C%7D&bg=ffffff&fg=545454&s=0&c=20201002)
![\Omega \subset [n_1] \times [n_2]](https://s0.wp.com/latex.php?latex=%5COmega+%5Csubset+%5Bn_1%5D+%5Ctimes+%5Bn_2%5D&bg=ffffff&fg=545454&s=0&c=20201002)
![[n_1] \times [n_2]](https://s0.wp.com/latex.php?latex=%5Bn_1%5D+%5Ctimes+%5Bn_2%5D&bg=ffffff&fg=545454&s=0&c=20201002)


Of course, with no further information on M, it is impossible to complete the matrix M from the partial information 



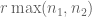
This type of problem comes up in several real-world applications, most famously in the Netflix prize. The Netflix prize problem is to be able to predict a very large ratings matrix M, whose rows are the customers, whose columns are the movies, and the entries are the rating that each customer would hypothetically assign to each movie. Of course, not every customer has rented every movie from Netflix, and so only a small fraction
Actually, one expects to need to oversample the matrix by a logarithm or two in order to have a good chance of exact recovery, if one is sampling randomly. This can be seen even in the rank one case r=1, in which 




On the other hand, one cannot hope to complete the matrix if some of the singular vectors of the matrix are extremely sparse. For instance, in the Netflix problem, a singularly idiosyncratic customer (or dually, a singularly unclassifiable movie) may give rise to a row or column of M that has no relation to the rest of the matrix, occupying its own separate component of the singular value decomposition of M; such a row or column is then impossible to complete exactly without sampling the entirety of that row or column. Thus, to get exact matrix completion from a small fraction of entries, one needs some sort of incoherence assumption on the singular vectors, which spreads them out across all coordinates in a roughly even manner, as opposed to being concentrated on just a few values.
In a recent paper, Candés and Recht proposed solving the matrix completion problem by minimising the nuclear norm (or trace norm)

amongst all matrices consistent with the observed data 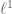
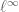
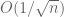

This differs from the presumably optimal threshold of 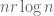

The main result of our paper is to mostly eliminate this gap, at the cost of a stronger hypothesis on the matrix being measured:
Main theorem. (Informal statement) Suppose the
matrix M has rank r and obeys a certain “strong incoherence property”. Then with high probability, nuclear norm minimisation will recover M from a random sample
, where
.
A result of a broadly similar nature, but with a rather different recovery algorithm and with a somewhat different range of applicability, was recently established by Keshavan, Oh, and Montanari. The strong incoherence property is somewhat technical, but is related to the Candés-Recht incoherence property and is satisfied by a number of reasonable random matrix models. The exponent O(1) here is reasonably civilised (ranging between 2 and 9, depending on the specific model and parameters being used).

Recent Comments