
This is a continuation of several threads from Tim Gowers’ massively collaborative mathematics project, “A combinatorial approach to density Hales-Jewett“, which I discussed in my previous post.
For any positive integer n, let ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=545454&s=0&c=20201002)
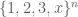

![A \subset [3]^n](https://s0.wp.com/latex.php?latex=A+%5Csubset+%5B3%5D%5En&bg=ffffff&fg=545454&s=0&c=20201002)

Density Hales-Jewett theorem (k=3):
, i.e.
.
This theorem implies several other important results, most notably Roth’s theorem on length three progressions (in an arbitrary abelian group!) and also the corners theorem of Ajtai and Szemeredi (again in an arbitrary abelian group).
Here are some of the questions we are initially exploring in this thread (and which I will comment further on below the fold):
- What are the best upper and lower bounds for
, with some partial results for higher n. We also have some relationships between different
- What do extremal or near-extremal sets (i.e. line-free sets with cardinality close to
- What are some good constructions of line-free sets that lead to asymptotic lower bounds on
.
- Can these methods extend to other related problems, such as the Moser cube problem or the capset problem?
- How feasible is it to extend the existing combinatorial proofs of Roth’s theorem (or the corners theorem), in particular the arguments of Szemeredi, to the Density Hales-Jewett theorem?
But I imagine that further threads might develop in the course of the discussion.
As with the rest of the project, this is supposed to be an open collaboration: please feel free to pose a question or a comment, even if (or especially if) it is just barely non-trivial. (For more on the “rules of the game”, see this post.)
— I.
Because the Cartesian product of two line-free sets is line-free, we have a lower bound

for all 
There is a trivial bound

which comes from the observation that any line-free subset of ![{}[3]^{n+1}](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E%7Bn%2B1%7D&bg=ffffff&fg=545454&s=0&c=20201002)

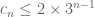
for 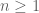
If we identify ![{}[3] = \{1,2,3\}](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D+%3D+%5C%7B1%2C2%2C3%5C%7D&bg=ffffff&fg=545454&s=0&c=20201002)

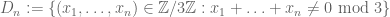
thus 
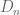
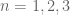
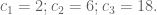
For n=4, the only combinatorial lines remaining in 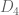
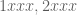
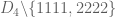

This bound was complemented with the lower bound 
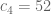
For 


No attempt at getting reasonable bounds for 
Question I.A: Can we improve the upper and lower bounds on 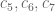
Question I.B: Is there some reasonably efficient way to automate this process?
Question I.C: What do the extremal line-free sets (sets of size close to
At some point we should submit this sequence to the OEIS.
— II. Lower bounds on
For any integers a,b,c adding up to n, let ![\Gamma_{a,b,c} \subset [3]^n](https://s0.wp.com/latex.php?latex=%5CGamma_%7Ba%2Cb%2Cc%7D+%5Csubset+%5B3%5D%5En&bg=ffffff&fg=545454&s=0&c=20201002)

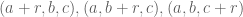
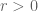
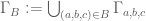
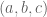
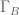
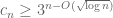
Question II.A: Using the Elkin bound on Behrend sets, what is the precise lower bound one gets? (Solymosi.46.5 notes that we should restrict the Behrend set to scale 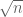
Question II.B: What does one get for higher k than 3? Presumably one would use the O’Bryant bound (O’Bryant.126).
Question II.C: Do the examples from Section I extend to give competitive lower bounds for large n?
Question II.D: Are there better ways to avoid triangles or corners in two dimensions than simply lifting up the Behrend example from one dimension?
— III. Miscellanous facts about
Using the colouring Hales-Jewett theorem, one can show that for every m, one has 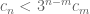
Question III.A: Anything else we can say about the
Note: as pointed out in Gasarch.45.5, Hindman and Tressler have recently established that 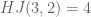


— IV. Related problems —
Let 
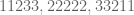

It is clear that 
Elsholtz.43 proposed modifying the construction of (6) to give a similar lower bound on
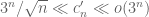
Question IV.A. Can we improve the lower bound in (8)?
Question IV.B. Can we get good bounds on 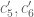
Define 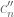

![x, r \in ({\Bbb Z}/3{\Bbb Z})^n \equiv [3]^n](https://s0.wp.com/latex.php?latex=x%2C+r+%5Cin+%28%7B%5CBbb+Z%7D%2F3%7B%5CBbb+Z%7D%29%5En+%5Cequiv+%5B3%5D%5En&bg=ffffff&fg=545454&s=0&c=20201002)
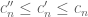
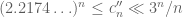
Question IV.C. Can we improve on these bounds in any way?
Question IV.D. What are the first few values of 
[Update, Feb 7: I will now maintain a running table of the current “world records” for 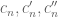
[Update, Feb 8: A more complete (and up-to-date) spreadsheet can now be found here.]
| n | |
|
|
| 0 | 1 | 1 | 1 |
| 1 | 2 | 2 | 2 |
| 2 | 6 | 6 | 4 |
| 3 | 18 | 16 | 9 |
| 4 | 52 | 43 | 20 |
| 5 | [150,154] | [96,129] | 45 |
| 6 | [450,462] | [258,387] | 112 |
| 7 | [1302,1386] | [688,1161] | [236,292] |
| 8 | [3780,4158] | [1849,3483] | [472,773] |
| 9 | [11340,12474] | [4128,10449] | [1008,2075] |
| 10 | [32864,37422] | [11094,31347] | [2240,5632] |
| 11 | [95964,112266] | [29584,94041] | [5040,15425] |
| 12 | [287892,336798] | [79507,282123] | [12544,42569] |
| 13 | [837850,1010394] | [175504,846369] | [26432,118237] |
| 14 | [2458950,3031182] | [477042,2539107] | [52864,330222] |
| 15 | [7376850,9093946] | [1272112,7617321] | [112896,926687] |
 |
![{}[3^{n-O(\sqrt{\log n})}, o(3^n)]](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5E%7Bn-O%28%5Csqrt%7B%5Clog+n%7D%29%7D%2C+o%283%5En%29%5D&bg=ffffff&fg=545454&s=0&c=20201002) |
![{}[\Omega(\frac{3^n}{\sqrt{n}}), o(3^n)]](https://s0.wp.com/latex.php?latex=%7B%7D%5B%5COmega%28%5Cfrac%7B3%5En%7D%7B%5Csqrt%7Bn%7D%7D%29%2C+o%283%5En%29%5D&bg=ffffff&fg=545454&s=0&c=20201002) |
![{}[(2.21\ldots)^n, O(\frac{3^n}{n})]](https://s0.wp.com/latex.php?latex=%7B%7D%5B%282.21%5Cldots%29%5En%2C+O%28%5Cfrac%7B3%5En%7D%7Bn%7D%29%5D&bg=ffffff&fg=545454&s=0&c=20201002) |
- green – obtained via the inequality (1)
- orange – obtained via the inequality (2)
- lavender – uses the inequality
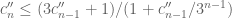
— V. Szemeredi’s proof of Roth’s theorem —
Szemeredi provided a short proof of Roth’s theorem by purely combinatorial means, and also famously proved the full case of Szemeredi’s theorem by much more intricate combinatorial argument. Both arguments are based on the density increment method. In the setting of 

Then one can find a line-free set 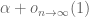
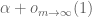
Szemeredi’s proof of Roth’s theorem proceeds by first showing that a dense set A contains a large cube Q, and thus (if it is free of algebraic lines) must completely avoid the set 
Question V.A: Is there some way to adapt this argument to density Hales-Jewett, or at least to the corners problem? The sparsity of lines is a serious difficulty, see Tao.118, Solymosi.135.
One can at least generate lots of cubes inside A without difficulty (Tao.102, Solymosi.135), lots of combinatorial lines with two elements inside A (Tao.130, Bukh.132, O’Donnell.133, Solymosi.135), and many unorganised subspaces in the complement of A (Tao.118, Solymosi.135), but this does not seem to be enough as yet.
Question V.B: What about using the techniques from Szemeredi’s big paper on Szemeredi’s theorem? (The immediate issue is that there is a key point where one needs to regularise a graph, and the relevant graph in HJ or even for corners is far too sparse; I’ll try to clarify this at some point.)
— A note on comments —
As in the first thread, please number your comments (starting with 200, then 201, etc.) and provide a title, to assist with following the comments. (Presumably, in future projects of this type, we will use a platform that allows for comment threading; see this post for further discussion.)

101 comments
Comments feed for this article
10 February, 2009 at 10:06 am
Michael Peake
241. Upper bound for
This proof is along the lines of Sune.90
Sune shows there is just one way to place 18 points in a cube,
and that at most 52 points fit in
Suppose 156 points may be chosen in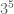 .
.
There must be 52 points in each slice of
Divide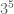 into nine cubes. There are 17 or 18 points in each cube, and one cube in each row and column has 18 points. For example
into nine cubes. There are 17 or 18 points in each cube, and one cube in each row and column has 18 points. For example
17, 17, 18
18, 17, 17
17, 18, 17
Cut the cubes further, into squares. The 18-point cubes must cut into three six-point slices x y and z, but the 17-point squares have more variation
pqr, stu, xyz
xyz, abc, def
ghk, xyz, lmn
Take the three cubes in the top row, and slice them along a different axis so they are psx, qty and ruz.
One of these cubes has 18 points, and so is xyz; so r=x and u=y.
Similar logic in second column gives u=x and c=y. So there is a contradiction.
There are four other ways to place the 17-point and 18-point cubes, but they all lead to contradictions.
So 156 points can’t be placed in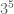
10 February, 2009 at 11:39 am
Terence Tao
242.
Michael: Nice! I’ve updated the spreadsheet and the table accordingly. Computing exactly may well be within reach now.
exactly may well be within reach now.
10 February, 2009 at 9:53 pm
Michael Peake
3^5.
The same proof works for 155 points, except for the case
17 17 18
17 17 17
18 17 17
and permutations of that. I can assume that, when sliced along
any axis, each cube has at least 17 points.
Cut the cubes into slices as in Michael.240.
Some of the slices must be x,y or z, as shown there
pqx rsy xyz
tuy abc yde
xyz yfg zhk
When the pqx cube is cut into squares along any of its three axes,
it has an x slice in third position. That forces the placement of
thirteen points in the cube, and needs four points to be
placed in the remaining 2x2x2 sub-cube. It turns out that pqx is either
yz’x or y’zx, where z’ is a z slice with one point removed.
If pqx = yz’x when sliced along one axis, then it is yz’x when sliced
along all three axes. Then the cube paz, from reslicing the diagonal,
is yaz along all three axes, which is impossible.
So pqx = y’zx when sliced along each axis, and rsy=tuy=zx’y
For the same reasons, zhk = zxy’
So cube qbh = zbx along all three axes, which is impossible.
I think this contradiction completes the proof.
10 February, 2009 at 10:09 pm
Michael Peake
244.
In 243., I made an error in the paragraph that begins “If pqx = yz’x”.
I just need the fact that a can’t have five points if yaz has no lines.
Also, at the end, b can’t have five points if zbx has no lines.
11 February, 2009 at 5:25 am
Michael Peake
245.
Recall that there is just one pattern to fit 18 points in a cube;
the three square slices of this pattern (along any axis) are x, y and z.
To fit 17 points in a cube, the only way is to remove one point from
either xyz, yzx or zxy.
This makes the proof in 243. easier because the slices are formed
by removing points from
yzx zxy xyz
zxy xyz yzx
xyz yzx zxy
Now the major diagonal of the cube is yyy, and six points must be removed from that. Four of the off-diagonal cubes must also lose points. That leaves 152 points, which contradicts the 155 points we started with.
11 February, 2009 at 9:46 am
Terence Tao
246.
Great! I’ve updated the table again (I see that the spreadsheet was already updated, excellent).
It would be interesting to see what the 150 lower bound example looks like in xyz notation, this may clarify what needs to be done to narrow the upper and lower bounds further.
11 February, 2009 at 12:46 pm
Kristal Cantwell
247. Let us look at the set of 150
points which form the lower
bound for c_5
It would consist of all points whose sum is not zero mod 3 with
all points with 5 coordinates equal to 1 or or all 5 points equal to 2 removed
combined with removal of all points
with one coordinate equal to 3 and the rest equal to
1 and the removal of all points with one coordinate
equal to 3 and the rest equal to 2
This gives the following
17 17 18
18 14 17
14 18 17
which gives let u equal x with one point removed
v = y with one point removed
and t =z with one point removed
uyz xvz xyz
xyz ??? xvz
??? xyz uyz
Note we have chosen three coordinates to be within
the cube and two other to determine
the position of the cube within the square
coordinates go from
one to three from left to right
and one to three upwards
xyz are squares determined
by one of the coordinates of the
cube. x (or any letter in the leftmost position)
corresponds to the
the square with coordinate equal
to one the letters in the next two positions correspond
to the squares with the coordinate equal to 2 and 3.
The question marks are for the cubes with 14 points. Are there problems with
having all the cubes having a value that is close to 18?
Is there a set of points having no combinatorial lines
with 5 coordinates varying from 1 to 3 such
that all of the cubes have value 17 or 18?
11 February, 2009 at 1:22 pm
Terence Tao
248. Conventions for xyz notation
I think it will be helpful to fix the conventions for the xyz notation. If we use Cartesian coordinates
13 23 33
12 22 32
11 21 31
to parameterise![{}[3]^2](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E2&bg=ffffff&fg=545454&s=0&c=20201002) , then (if I understand Michael’s posts correctly), x is the six-element set
, then (if I understand Michael’s posts correctly), x is the six-element set
* _ *
* * _
_ * *
(where * denotes elements of x and _ denotes non-elements), y is the six-element set
_ * *
* _ *
* * _
and z is the six-element set
* * _
_ * *
* _ *
and xyz is the unique 18-element line-free set in![{}[3]^3](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E3&bg=ffffff&fg=545454&s=0&c=20201002) (with the convention that abc is the set whose first slice is a, second slice is b, and third slice is c).
(with the convention that abc is the set whose first slice is a, second slice is b, and third slice is c).
Michael, does this match your conventions?
Also, when you say “to fit 17 points on the cube, the only way is to remove one point from xyz, yzx, or zxy”, are there some restrictions on what point one can remove? Clearly one can remove any point one wishes from xyz, but there seems to be more constraints for yzx and zxy.
11 February, 2009 at 1:41 pm
Terence Tao
249. A hyper-optimistic conjecture from 400-499
Over at the 400-499 thread, Gil Kalai.455 and Tim Gowers.459 have proposed a “hyper-optimistic” conjecture, and asked whether it could be falsified using the examples from this thread. Let me rephrase it as follows. Given a set![A \subset {}[3]^n](https://s0.wp.com/latex.php?latex=A+%5Csubset+%7B%7D%5B3%5D%5En&bg=ffffff&fg=545454&s=0&c=20201002) , define the weighted size
, define the weighted size 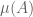 of A by the formula
of A by the formula
thus each slice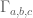 has weighted size 1 (and we have been referring to
has weighted size 1 (and we have been referring to  as “slices-equal measure” for this reason), and the whole cube
as “slices-equal measure” for this reason), and the whole cube ![{}[3]^n](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5En&bg=ffffff&fg=545454&s=0&c=20201002) has weighted size equal to the
has weighted size equal to the 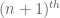 triangular number,
triangular number, 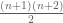 .
.
Example: in![{}[3]^2](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E2&bg=ffffff&fg=545454&s=0&c=20201002) , the diagonal points 11, 22, 33 each have weighted size 1, whereas the other six off-diagonal points have weighted size 1/2. The total weighted size of
, the diagonal points 11, 22, 33 each have weighted size 1, whereas the other six off-diagonal points have weighted size 1/2. The total weighted size of ![{}[3]^2](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E2&bg=ffffff&fg=545454&s=0&c=20201002) is 6.
is 6.
Let be the largest weighted size of a line-free set. For instance,
be the largest weighted size of a line-free set. For instance,  ,
,  , and
, and 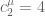 .
.
As in the unweighted case, every time we find a subset B of the grid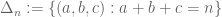 without equilateral triangles, it gives a line-free set
without equilateral triangles, it gives a line-free set 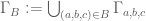 . The weighted size of this set is precisely the cardinality of B. Thus we have the lower bound
. The weighted size of this set is precisely the cardinality of B. Thus we have the lower bound 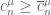 , where
, where  is the largest size of equilateral triangles in
is the largest size of equilateral triangles in 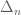 .
.
Hyper-optimistic conjecture: We in fact have . In other words, to get the optimal weighted size for a line-free set, one should take a set which is a union of slices
. In other words, to get the optimal weighted size for a line-free set, one should take a set which is a union of slices 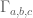 .
.
This conjecture, if true, will imply the DHJ theorem (see the 400-499 discussion for details). Note also that all our best lower bounds for the unweighted problem to date have been unions of slices. Also, the k=2 analogue of the conjecture is true, and is known as the LYM inequality (in fact, for k=2 we have for all n).
for all n).
If the conjecture is false, then perhaps this will be visible by computing upper and lower bounds for for small n. By hand I can check that
for small n. By hand I can check that 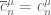 for n=0,1,2… but perhaps with all the above progress we can also get good bounds for n=3,4,5?
for n=0,1,2… but perhaps with all the above progress we can also get good bounds for n=3,4,5?
11 February, 2009 at 4:25 pm
Tyler Neylon
250. A hyper-optimistic conjecture
Could someone clarify the definition of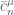 ?
?
As far as generalizations of LYM go, let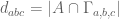 , and suppose
, and suppose 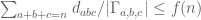 for all line-free
for all line-free  . Then Michael’s examples seem to suggest
. Then Michael’s examples seem to suggest 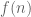 grows quickly – as opposed to
grows quickly – as opposed to 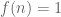 in LYM – so, intuitively, how do we hope for something like LYM?
in LYM – so, intuitively, how do we hope for something like LYM?
I don’t think this is exactly what’s needed, but we do have where
where  is the percent of lines passing through any single element of
is the percent of lines passing through any single element of 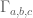 .
.
11 February, 2009 at 4:45 pm
Terence Tao
251. A hyper-optimistic conjecture
One can define in two equivalent ways. One of them is that it is the largest weighted size
in two equivalent ways. One of them is that it is the largest weighted size 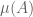 of a line-free set
of a line-free set ![A \subset [3]^n](https://s0.wp.com/latex.php?latex=A+%5Csubset+%5B3%5D%5En&bg=ffffff&fg=545454&s=0&c=20201002) which is the union of slices
which is the union of slices 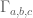 . (This is in contrast to
. (This is in contrast to  , which is the largest weighted size of any line-free set, not necessarily the union of slices.)
, which is the largest weighted size of any line-free set, not necessarily the union of slices.)
Another equivalent definition is that is the largest subset of the triangular grid
is the largest subset of the triangular grid 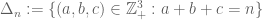 which contain no equilateral triangles. For instance, by deleting the two points (0,0,2) and (1,1,0) from
which contain no equilateral triangles. For instance, by deleting the two points (0,0,2) and (1,1,0) from 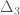 one removes all triangles, whereas removing one point is not enough, and so
one removes all triangles, whereas removing one point is not enough, and so  .
.
As for your second question, I don’t think we have yet a strategy for this, but one could imagine some sort of extremal combinatorics argument by showing that a line-free set which is not a union of slices can be “improved” to increase its weighted size, without losing the line-free property. Showing this rigorously, though, would be, well, hyper-optimistic.
(Incidentally, what you call f(n) would be what I would call an upper bound for .)
.)
11 February, 2009 at 7:15 pm
Jason Dyer
252. Hyper-optimist conjecture
Am I understanding this right?
Minimal deletion for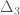 removes (0,3,0) (0,2,1) (2,1,0) (1,0,2), leaving 6 points. So
removes (0,3,0) (0,2,1) (2,1,0) (1,0,2), leaving 6 points. So 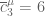 ?
?
11 February, 2009 at 7:48 pm
Terence Tao
253.
Well, that certainly makes the set triangle-free, so . If you know that you cannot make
. If you know that you cannot make 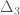 triangle-free by removing only three points, then yes,
triangle-free by removing only three points, then yes, 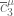 would equal 6.
would equal 6.
11 February, 2009 at 8:12 pm
Jason Dyer
254. Proof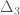 cannot be triangle free removing only 3 points
cannot be triangle free removing only 3 points
Yes, with only three removals each of these (non-overlapping) triangles must have one removal:
set A: (0,3,0) (0,2,1) (1,2,0)
set B: (0,1,2) (0,0,3) (1,0,2)
set C: (2,1,0) (2,0,1) (3,0,0)
Consider choices from set A:
(0,3,0) leaves triangle (0,2,1) (1,2,0) (1,1,1)
(0,2,1) forces a second removal at (2,1,0) [otherwise there is triangle at (1,2,0) (1,1,1) (2,1,0)] but then none of the choices for third removal work
(1,2,0) is symmetrical with (0,2,1)
12 February, 2009 at 12:49 am
Michael Peake
255.
Krystal.247: I think my 245 shows that, if all the cubes
have 17 or 18 points, then you have to delete ten points from
a full 9×18 pattern of xs, ys and zs. That leaves 152 points,
which is less than 9*17. So at least one cube has to have
16 or fewer points.
Another pattern of 150 points is this: Take the 450 points![{}[3]^6](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E6&bg=ffffff&fg=545454&s=0&c=20201002) which are
which are 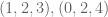 and permutations,
and permutations,
in
then select the 150 whose final coordinate is 1. That gives
this many points in each cube:
17 18 17
17 17 18
12 17 17
Terry.248: Yes, that matches what I meant by x,y and z;
yzx and zxy have a full line on the cube’s major diagonal
so you have to remove one of those three points to leave
a valid seventeen points.
12 February, 2009 at 7:32 am
Jason Dyer
256. Hyper-optimist conjecture
The case was originally proposed as a puzzle by Kobon Fujimura (who is best known for <a href=”Kobon Triangles).
case was originally proposed as a puzzle by Kobon Fujimura (who is best known for <a href=”Kobon Triangles).
I have been searching the recreational mathematics literature for any other mention of our problem but I haven’t found a reference.
12 February, 2009 at 7:51 am
Jason Dyer
(Meta) Coin puzzles
Fujimura’s version of is simply given a pyramid of 10 coins, what is the smallest number you need to remove so there are no equilateral triangles?
is simply given a pyramid of 10 coins, what is the smallest number you need to remove so there are no equilateral triangles?
The most common type of coin puzzle (which goes back to Dudeney) involves changing one configuration of coins into another with a certain number of moves. For example, invert a pyramid of 10 coins in the smallest number of moves.
This article from the (highly recommended book) Games of No Chance analyzes this type of puzzle in detail.
12 February, 2009 at 10:46 am
Sune Kristian Jakobsen
257.
The set of all (a,b,c) in
Let be a set without equilateral triangles. If
be a set without equilateral triangles. If 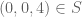 , there can only be one of (0,x,4-x) and (x,0,4-x) in S for x=1,2,3,4. Thus there can only be 5 elements in S with a=0 or b=0. The set of element with a,b>0 is isomorph to
, there can only be one of (0,x,4-x) and (x,0,4-x) in S for x=1,2,3,4. Thus there can only be 5 elements in S with a=0 or b=0. The set of element with a,b>0 is isomorph to  , so S can at most have 4 elements in this set. So
, so S can at most have 4 elements in this set. So  . Similar if S contain (0,4,0) or (4,0,0). So if
. Similar if S contain (0,4,0) or (4,0,0). So if  S doesn’t contain any of these. Also, S can’t contain all of (0,1,3), (0,3,1), (2,1,1). Similar for (3,0,1), (1,0,3),(1,2,1) and (1,3,0), (3,1,0), (1,1,2). So now we have found 6 elements not in S, but
S doesn’t contain any of these. Also, S can’t contain all of (0,1,3), (0,3,1), (2,1,1). Similar for (3,0,1), (1,0,3),(1,2,1) and (1,3,0), (3,1,0), (1,1,2). So now we have found 6 elements not in S, but  , so
, so 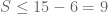 .
.
12 February, 2009 at 11:32 am
Sune Kristian Jakobsen
258.
The set of all (a,b,c) in
Let be a set without equilateral triangles. If
be a set without equilateral triangles. If 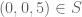 , there can only be one of (0,x,5-x) and (x,0,5-x) in S for x=1,2,3,4,5. Thus there can only be 6 elements in S with a=0 or b=0. The set of element with a,b>0 is isomorph to
, there can only be one of (0,x,5-x) and (x,0,5-x) in S for x=1,2,3,4,5. Thus there can only be 6 elements in S with a=0 or b=0. The set of element with a,b>0 is isomorph to 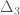 , so S can at most have 6 elements in this set. So
, so S can at most have 6 elements in this set. So  . Similar if S contain (0,5,0) or (5,0,0). So if
. Similar if S contain (0,5,0) or (5,0,0). So if 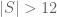 S doesn’t contain any of these. S can only contain 2 point in each of the following equilateral triangles:
S doesn’t contain any of these. S can only contain 2 point in each of the following equilateral triangles: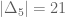 , so
, so  .
.
(3,1,1),(0,4,1),(0,1,4)
(4,1,0),(1,4,0),(1,1,3)
(4,0,1),(1,3,1),(1,0,4)
(1,2,2),(0,3,2),(0,2,3)
(3,2,0),(2,3,0),(2,2,1)
(3,0,2),(2,1,2),(2,0,3)
So now we have found 9 elements not in S, but
12 February, 2009 at 1:03 pm
Christian Elsholtz
259 About the constant c”(n): the value of c”(6)=112 has been proved by
Aaron Potechin: Maximal caps in AG (6, 3)
Journal Designs, Codes and Cryptography, Volume 46, Number 3 / March, 2008
http://www.springerlink.com/content/h003577g11112308/
This gives a new set of slightly improved upper bounds: for n=7 to 15 as follows:
{7, 292}, {8, 773}, {9, 2075}, {10, 5632}, {11, 15425},
{12, 42569}, {13, 118237}, {14, 330222}, {15, 926687}
A discussion of the problem on caps, with plenty of references, can also
be found in:
Yves Edel, Christian Elsholtz, Alfred Geroldinger, Silke Kubertin, Laurence Rackham: Zero-sum problems in finite abelian groups and affine caps.
Quarterly Journal of Mathematics 58 (2007), 159-186.
http://qjmath.oxfordjournals.org/cgi/content/abstract/58/2/159
12 February, 2009 at 1:29 pm
Jason Dyer
260.
Sune, could you give your explicit list for removals from ? I am unable to reproduce a triangle-free configuration from your description.
? I am unable to reproduce a triangle-free configuration from your description.
For example, (4,0,0) (0,4,0) (0,0,4) (2,1,1) (1,1,2) (1,2,1) leaves the triangle (2,2,0) (0,2,2) (2,0,2).
12 February, 2009 at 1:30 pm
Terence Tao
260. Updates to spreadsheet
I’ve updated the spreadsheet to take into account the above developments (in particular, adding entries for upper and lower bounds for and
and  . I’m using the trivial bounds
. I’m using the trivial bounds
and
but clearly we should be able to do better than these bounds.
12 February, 2009 at 1:56 pm
Jason Dyer
261. Lower bound for
One easy lower bound is to note that one can always go triangle free by removing (n,0,0), the triangle (n-2,1,1) (0,n-1,1) (0,1,n-1), and all points on the edges of and inside the same triangle.
For example, with remove (0,4,0), (1,2,1), (2,1,1), (1,1,2), (3,0,1), (2,0,2), and (1,0,3).
remove (0,4,0), (1,2,1), (2,1,1), (1,1,2), (3,0,1), (2,0,2), and (1,0,3).
Therefore a lower bound would be . (That is, the triangular number of n+1 with (n,0,0) removed and then the triangular number of n-1 removed, referring to the triangle (n-2,1,1) (0,n-1,1) (0,1,n-1).)
. (That is, the triangular number of n+1 with (n,0,0) removed and then the triangular number of n-1 removed, referring to the triangle (n-2,1,1) (0,n-1,1) (0,1,n-1).)
12 February, 2009 at 4:46 pm
Michael Peake
262. Three solutions for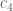
There are exactly three solutions for 52 points in![{}[3]^4](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E4&bg=ffffff&fg=545454&s=0&c=20201002)
 , x, y and z defined in Terry.248
, x, y and z defined in Terry.248
I use recent notation from
x’ is x with one point removed; that point in![{}[3]^4](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E4&bg=ffffff&fg=545454&s=0&c=20201002) is either 2222 or 3333. Likewise for y’ and z’
is either 2222 or 3333. Likewise for y’ and z’
All three solutions are made from full $latex Gamma_{abc}
Each row is a different solution.
xyz yz’x zxy’
y’zx zx’y xyz
z’xy xyz yzx’
12 February, 2009 at 6:27 pm
Jason Dyer
263. Finishing the calculations
I guess that’s what I get for typing and running — the bound at 261 is just 2n.
Also, 254 the proof can be much, much simpler: just note (3,0,0) or something symmetrical has to be removed, leaving 3 triangles which do not intersect, so 3 more removals are required.
12 February, 2009 at 8:04 pm
Michael Peake
264. Lower bound for
Another lower bound is 3(n-1), as you keep most of all three sides of the triangle. Remove the corners and the inner triangle.
12 February, 2009 at 8:23 pm
Jason Dyer
265. Lower bound for \overline{c}^mu_n
Michael, I have a counterexample for that at 260.
12 February, 2009 at 8:44 pm
Terence Tao
266. Wiki
We’ve started up a wiki for the polymath project at
http://michaelnielsen.org/polymath1/index.php?title=Main_Page
I’ve put in a page for the proofs of the best bounds for c_n for small n at
http://michaelnielsen.org/polymath1/index.php?title=Upper_and_lower_bounds
The last few sections still need some work. Of course, everyone is invited to contribute. (For lengthy new computations, it may be best to put the details on the wiki and announce an abridged version here.)
At some point I’ll try to do something similar for .
.
12 February, 2009 at 8:52 pm
Michael Peake
266. Lower bound for
You can fit nine points in a 15-point triangle (n=4),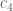 only uses seven points.
only uses seven points.
(013,022,031,103,202,301,130,220,310)
but the best result for
(022,112,121,202,220,310,301)
12 February, 2009 at 9:04 pm
Michael Peake
267. Lower bound for
Jason,
The triangle made up by (2,2,0),(2,0,2) and (0,2,2) is upside down.
It has a constant r=-2, so doesn’t apply to HJ sequences, which
use r as a number of columns.
I think you were right the first time, in 254., to do the long-winded proof.
12 February, 2009 at 9:12 pm
Terence Tao
268. Wiki
Here is a page for , the computation of which I have dubbed “Fujimura’s problem”:
, the computation of which I have dubbed “Fujimura’s problem”:
http://michaelnielsen.org/polymath1/index.php?title=Fujimura%27s_problem
Again, some cleanup is required to convert the blog comments into wiki format and to integrate the text smoothly.
12 February, 2009 at 10:49 pm
Michael Peake
269. Upper limit for
From looking at triangles in the lowest two rows, we have
12 February, 2009 at 11:29 pm
Michael Peake
270. Hyper-optimistic
My point in 266. was, does that contradict the hyper-optimistic conjecture?
13 February, 2009 at 4:25 am
Michael Peake
271. Upper limit for Fujimura ( )
)
There are triangles, and each point is in n of them, so you must remove at least (n+2)(n+1)/6 points to remove all triangles.
triangles, and each point is in n of them, so you must remove at least (n+2)(n+1)/6 points to remove all triangles. is (n+1)(n+2)/3.
is (n+1)(n+2)/3.
So an upper limit for
13 February, 2009 at 7:39 am
Terence Tao
272. Hyper-optimistic
Dear Michael, it’s not clear yet whether this example violates the hyper-optimistic one, because the extremiser for the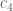 problem is not going to be the extremiser for the
problem is not going to be the extremiser for the 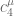 problem. Indeed, the
problem. Indeed, the 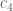 example, involving only seven of the slices, will have a weighted size of 7, whereas the
example, involving only seven of the slices, will have a weighted size of 7, whereas the  example has a weighted size of 9. To contradict the conjecture we would need to find a line-free set in
example has a weighted size of 9. To contradict the conjecture we would need to find a line-free set in ![{}[3]^4](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E4&bg=ffffff&fg=545454&s=0&c=20201002) with a weighted size exceeding 9.
with a weighted size exceeding 9.
Incidentally, I found the lower bound for
for 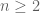 , since one can always take an extremiser in
, since one can always take an extremiser in 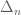 , add a new edge to the triangular grid and put two points on it so that the triangle these two points generate doesn’t have the third point in the extremiser.
, add a new edge to the triangular grid and put two points on it so that the triangle these two points generate doesn’t have the third point in the extremiser.
Given how this thread is filling up, I will probably start a fresh thread in a day or so. The wiki is very helpful in this regard, it reduces the extent to which I will have to summarise all the progress…
13 February, 2009 at 7:49 am
Jason Dyer
272. When r<0
re: Peake.267, yes, I see now. I don’t remember r ever being defined as positive so I never thought about the case. (2,0,2) (2,2,0) (0,2,2) would be 1133, 1122, and 2233 which form no combinatorial lines.
That does bring the interesting question of: is there anything important about this problem relating to the cases of r<0? They might affect the “subcubes” from O’Donnell.422 which seem to be working with “partial” combinatorial lines. Calling the points a, b and c: a and b form a partial combinatorial line, b and c do, and a and c do, but a, b, and c do not form a line together. I believe this situation may be unique for the r<0 case.
Also, it means there are two variants of Fujimura, and while r<0 doesn’t apply to our problem it might be worth looking into as a side project (or at least noting it as a separate case).
13 February, 2009 at 8:48 am
Sune Kristian Jakobsen
273.
Michael.219: “This method gives a lower bound for c_99 that is bigger than 3^98.” and![{}[3]^{99}](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E%7B99%7D&bg=ffffff&fg=545454&s=0&c=20201002) of density
of density  that still has no combinatorial line.”
that still has no combinatorial line.”
Terry.467: “We also have an example of a subset of
Then why is c_96/3^96=0.006155058319549. Shouldn’t it be >1/3?
13 February, 2009 at 8:49 am
Sune Kristian Jakobsen
273b
The number I mentioned is L98 in the spreadsheet: Lower bound for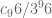
13 February, 2009 at 12:04 pm
Kristal Cantwell
The two examples we have for a lower bound for c_5 being 150 have cubes with 14 and 12 points is there an example with all cubes 16 or higher
and total 150 or higher? Or failing that all cubes 15 or higher and total 150 or higher?
13 February, 2009 at 4:14 pm
Thomas Sauvaget
275. : an example
: an example
Inspired by the previous discussion, I think I’ve found an example showing that , I’d be grateful if someone could check it.
, I’d be grateful if someone could check it.
I’m using slightly different notations: instead of cartesian coordinates I’m using left-to-right ordering of words recursively to make visualisation easy. Namely, when is even increase upwards, when
is even increase upwards, when  is odd increase righwards. In this way we can deal with 2-dimensional patterns only. For example
is odd increase righwards. In this way we can deal with 2-dimensional patterns only. For example ![{}[3]^3](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E3&bg=ffffff&fg=545454&s=0&c=20201002) looks like this:
looks like this:
131 132 133 231 232 233 331 332 333
121 122 123 221 222 223 321 322 323
111 112 113 211 212 213 311 312 313
Given those notations here is what I think is a 154-element line-free pattern in![{}[3]^5](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E5&bg=ffffff&fg=545454&s=0&c=20201002) :
:
The bottom-left black element is 11111 (not in the set), and so on. The two lone red elements are removed (Michael’s idea, here these are 12222 and 13333), then I found that removing the 6 other red elements leads to a line-free set (note that these 6 red elements are all on a super-diagonal). Total is thus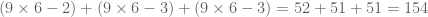 . This would also fit with the OEIS sequence A052979 mentionned above.
. This would also fit with the OEIS sequence A052979 mentionned above.
I’ve built the example recursively by matching lower conditions starting from the bottom left square, first killing straight lines then diagonals, then doing the same with the other
square, first killing straight lines then diagonals, then doing the same with the other 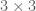 squares from
squares from ![{}[3]^4](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E4&bg=ffffff&fg=545454&s=0&c=20201002) . In fact there is still some freedom in the pattern: the two squares I’ve circled with blue could have any of the 3 elementary
. In fact there is still some freedom in the pattern: the two squares I’ve circled with blue could have any of the 3 elementary 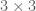 patterns, but here I’ve chosen the most symmetric ones.
patterns, but here I’ve chosen the most symmetric ones.
It seems that this construction is fairly topological and systematic, it may well be possible to get an explicit recursive formulation, and thus a formula for estimating . I’ll try to come back to it if indeed the example is correct.
. I’ll try to come back to it if indeed the example is correct.
13 February, 2009 at 5:07 pm
Terence Tao
276: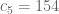
Dear Thomas,
It unfortunately seems to me that the bottom row of the middle![{}[3]^4](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E4&bg=ffffff&fg=545454&s=0&c=20201002) contains some horizontal lines (e.g. the three centres of the three
contains some horizontal lines (e.g. the three centres of the three ![{}[3]^2](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E2&bg=ffffff&fg=545454&s=0&c=20201002) ‘s in this bottom row). There are also some lines on the top row and on the left and right columns of this middle
‘s in this bottom row). There are also some lines on the top row and on the left and right columns of this middle ![{}[3]^4](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E4&bg=ffffff&fg=545454&s=0&c=20201002) .
.
(If you write each of the![{}[3]^2](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E2&bg=ffffff&fg=545454&s=0&c=20201002) ‘s in xyz notation, one sees the problem; there are a bunch of rows and columns which only have two of the three patterns x, y, z and so let some lines slip in. The
‘s in xyz notation, one sees the problem; there are a bunch of rows and columns which only have two of the three patterns x, y, z and so let some lines slip in. The ![{}[3]^2](https://s0.wp.com/latex.php?latex=%7B%7D%5B3%5D%5E2&bg=ffffff&fg=545454&s=0&c=20201002) ‘s with three red squares in them are the intersection of two of the x, y, z and can kill more lines, but unfortunately this doesn’t cover all the possible lines.)
‘s with three red squares in them are the intersection of two of the x, y, z and can kill more lines, but unfortunately this doesn’t cover all the possible lines.)
But it could be that some permutation of this sort of strategy could work… it may provide the first good example we have which is not based off of the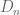 set.
set.
13 February, 2009 at 8:13 pm
Bounds for the first few density Hales-Jewett numbers, and related quantities « What’s new
[…] 2009 in math.CO | Tags: polymath1 | by Terence Tao This thread is a continuation of the previous thread here on the polymath1 project. Currently, activity is focusing on the following […]
13 February, 2009 at 8:14 pm
Terence Tao
277. Thread moving
As this thread is beginning to get quite long, I am moving it to a new thread, starting at 700:
14 February, 2009 at 12:24 am
Michael Peake
277. lower bound of
I tried a pattern of points based on Terry.39’s suggestion. It seems to give asymptotic results similar to what he thought.
First define a sequence, of all positive numbers which, in base 3, do not contain a 1. Add 1 to all multiples of 3 in this sequence. This sequence does not contain a length-3 arithmetic progression.
It starts 1,2,7,8,19,20,25,26,55, …
Second, list all the (abc) triples for which the larger two differ by a number
from the sequence, excluding the case when the smaller two differ by 1, but then including the case when (a,b,c) is a permutation of N/3+(-1,0,1)
This had numerical asymptotics for close to
close to
$latex 1.2-\sqrt(\log(n)) between n=1000 and n=10000
Sune.273: Sorry, I haven’t written all the numbers in yet for my pattern – I am only up to 70, so another formula is used to give lower bounds after that.
19 February, 2009 at 4:16 pm
A quick review of the polymath project « What Is Research?
[…] By this time, Gowers’ blog was receiving hundreds of comments, mostly comments by Gowers himself, but also including comments from distinguished mathematicians such as Terence Tao. Tao has his own blog, and he published a post giving the background of the Hales-Jewett theorem and a later post with some of his own ideas about the problem. […]
25 March, 2009 at 12:13 am
An Open Discussion and Polls: Around Roth’s Theorem « Combinatorics and more
[…] (as a little spin off to the polymath1 project, (look especially here and here)) if you have any thoughts about where the truth is for these problems, or about how to […]
11 April, 2009 at 11:17 am
Seva
278. Edel?
Just to remark that the upper bound for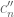 , ascribed in 228. to Edel, is actually present in Meshulam’s paper, in the most explicit form.
, ascribed in 228. to Edel, is actually present in Meshulam’s paper, in the most explicit form.
12 May, 2009 at 6:26 am
Around the Cap-Set problem (B) « Combinatorics and more
[…] An affine line are three vectors so that for every . A cap set is a subset of without an affine line. The cap set problem asks for the maximum size of a cap set. For information on the cap set problem itself look here. For questions regarding density of sets avoiding other types of lines look here. […]
16 July, 2009 at 1:06 pm
The Polynomial Hirsch Conjecture: A proposal for Polymath3 « Combinatorics and more
[…] the idea of attempting a “polymath”-style open collaboration (see here, here and here) aiming to have some progress for these conjectures. (The Hirsch conjecture and the polynomial […]
1 May, 2010 at 10:42 am
Michael Nielsen » Introduction to the Polymath Project and “Density Hales-Jewett and Moser Numbers”
[…] evolved. Four days after Gowers opened his blog up for discussion, Terence Tao used his blog to start a discussion aimed at understanding the behaviour of for small . This discussion rapidly gained momentum, and […]