Emmanuel Candés and I have just uploaded to the arXiv our paper “The power of convex relaxation: near-optimal matrix completion“, submitted to IEEE Inf. Theory. In this paper we study the matrix completion problem, which one can view as a sort of “non-commutative” analogue of the sparse recovery problem studied in the field of compressed sensing, although there are also some other significant differences between the two problems. The sparse recovery problem seeks to recover a sparse vector  from some linear measurements
from some linear measurements  , where A is a known
, where A is a known 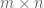 matrix. For general x, classical linear algebra tells us that if m < n, then the problem here is underdetermined and has multiple solutions; but under the additional assumption that x is sparse (most of the entries are zero), it turns out (under various hypotheses on the measurement matrix A, and in particular if A contains a sufficient amount of “randomness” or “incoherence”) that exact recovery becomes possible in the underdetermined case. Furthermore, recovery is not only theoretically possible, but is also computationally practical in many cases; in particular, under some assumptions on A, one can recover x by minimising the convex norm
matrix. For general x, classical linear algebra tells us that if m < n, then the problem here is underdetermined and has multiple solutions; but under the additional assumption that x is sparse (most of the entries are zero), it turns out (under various hypotheses on the measurement matrix A, and in particular if A contains a sufficient amount of “randomness” or “incoherence”) that exact recovery becomes possible in the underdetermined case. Furthermore, recovery is not only theoretically possible, but is also computationally practical in many cases; in particular, under some assumptions on A, one can recover x by minimising the convex norm 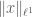 over all solutions to Ax=b.
over all solutions to Ax=b.
Now we turn to the matrix completion problem. Instead of an unknown vector , we now have an unknown matrix ![M = (m_{ij})_{i \in [n_1], j \in [n_2]} \in {\Bbb R}^{n_1 \times n_2}](https://s0.wp.com/latex.php?latex=M+%3D+%28m_%7Bij%7D%29_%7Bi+%5Cin+%5Bn_1%5D%2C+j+%5Cin+%5Bn_2%5D%7D+%5Cin+%7B%5CBbb+R%7D%5E%7Bn_1+%5Ctimes+n_2%7D&bg=ffffff&fg=545454&s=0&c=20201002) (we use the shorthand
(we use the shorthand ![[n] := \{1,\ldots,n\}](https://s0.wp.com/latex.php?latex=%5Bn%5D+%3A%3D+%5C%7B1%2C%5Cldots%2Cn%5C%7D&bg=ffffff&fg=545454&s=0&c=20201002) here). We will take a specific type of underdetermined linear measurement of M, namely we pick a random subset
here). We will take a specific type of underdetermined linear measurement of M, namely we pick a random subset ![\Omega \subset [n_1] \times [n_2]](https://s0.wp.com/latex.php?latex=%5COmega+%5Csubset+%5Bn_1%5D+%5Ctimes+%5Bn_2%5D&bg=ffffff&fg=545454&s=0&c=20201002) of the matrix array
of the matrix array ![[n_1] \times [n_2]](https://s0.wp.com/latex.php?latex=%5Bn_1%5D+%5Ctimes+%5Bn_2%5D&bg=ffffff&fg=545454&s=0&c=20201002) of some cardinality
of some cardinality  , and form the random sample
, and form the random sample  of M.
of M.
Of course, with no further information on M, it is impossible to complete the matrix M from the partial information  – we only have
– we only have  pieces of information and need
pieces of information and need  . But suppose we also know that M is low-rank, e.g. has rank less than r; this is an analogue of sparsity, but for matrices rather than vectors. Then, in principle, we have reduced the number of degrees of freedom for M from to something more like
. But suppose we also know that M is low-rank, e.g. has rank less than r; this is an analogue of sparsity, but for matrices rather than vectors. Then, in principle, we have reduced the number of degrees of freedom for M from to something more like  , and so (in analogy with compressed sensing) one may now hope to perform matrix completion with a much smaller fraction of samples, and in particular with m close to
, and so (in analogy with compressed sensing) one may now hope to perform matrix completion with a much smaller fraction of samples, and in particular with m close to 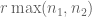 .
.
This type of problem comes up in several real-world applications, most famously in the Netflix prize. The Netflix prize problem is to be able to predict a very large ratings matrix M, whose rows are the customers, whose columns are the movies, and the entries are the rating that each customer would hypothetically assign to each movie. Of course, not every customer has rented every movie from Netflix, and so only a small fraction of this matrix is actually known. However, if one makes the assumption that most customers’ rating preference is determined by only a small number of characteristics of the movie (e.g. genre, lead actor/actresses, director, year, etc.), then the matrix should be (approximately) low rank, and so the above type of analysis should be useful (though of course it is not going to be the only tool of use in this messy, real-world problem).
Actually, one expects to need to oversample the matrix by a logarithm or two in order to have a good chance of exact recovery, if one is sampling randomly. This can be seen even in the rank one case r=1, in which  is the product of a column vector and a row vector; let’s consider square matrices
is the product of a column vector and a row vector; let’s consider square matrices  for simplicity. Observe that if the sampled coordinates
for simplicity. Observe that if the sampled coordinates  completely miss one of the rows of the matrix, then the corresponding element of u has gone completely unmeasured, and one cannot hope to complete this row of the matrix. Thus one needs to sample every row (and also every column) of the
completely miss one of the rows of the matrix, then the corresponding element of u has gone completely unmeasured, and one cannot hope to complete this row of the matrix. Thus one needs to sample every row (and also every column) of the  matrix. The solution to the coupon collector’s problem then tells us that one needs about
matrix. The solution to the coupon collector’s problem then tells us that one needs about  samples to achieve this goal. In fact, the theory of Erdős-Rényi random graphs tells us that the bipartite graph induced by becomes almost surely connected beyond this threshold, which turns out to be exactly what is needed to perform matrix completion for rank 1 matrices.
samples to achieve this goal. In fact, the theory of Erdős-Rényi random graphs tells us that the bipartite graph induced by becomes almost surely connected beyond this threshold, which turns out to be exactly what is needed to perform matrix completion for rank 1 matrices.
On the other hand, one cannot hope to complete the matrix if some of the singular vectors of the matrix are extremely sparse. For instance, in the Netflix problem, a singularly idiosyncratic customer (or dually, a singularly unclassifiable movie) may give rise to a row or column of M that has no relation to the rest of the matrix, occupying its own separate component of the singular value decomposition of M; such a row or column is then impossible to complete exactly without sampling the entirety of that row or column. Thus, to get exact matrix completion from a small fraction of entries, one needs some sort of incoherence assumption on the singular vectors, which spreads them out across all coordinates in a roughly even manner, as opposed to being concentrated on just a few values.
In a recent paper, Candés and Recht proposed solving the matrix completion problem by minimising the nuclear norm (or trace norm)

amongst all matrices consistent with the observed data . This nuclear norm is the non-commutative counterpart to the 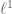 norm for vectors, and so this algorithm is analogous to the minimisation (or basis pursuit) algorithm which is effective for compressed sensing (though not the only such algorithm for this task). They showed, roughly speaking, that exact matrix completion (for, say, square matrices for simplicity) is ensured with high probability so long as the singular vectors obey a certain incoherence property (basically, their
norm for vectors, and so this algorithm is analogous to the minimisation (or basis pursuit) algorithm which is effective for compressed sensing (though not the only such algorithm for this task). They showed, roughly speaking, that exact matrix completion (for, say, square matrices for simplicity) is ensured with high probability so long as the singular vectors obey a certain incoherence property (basically, their 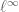 norm should be close to the minimal possible value, namely
norm should be close to the minimal possible value, namely 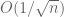 ), so long as one had the condition
), so long as one had the condition
 .
.
This differs from the presumably optimal threshold of 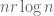 by a factor of about
by a factor of about  .
.
The main result of our paper is to mostly eliminate this gap, at the cost of a stronger hypothesis on the matrix being measured:
Main theorem. (Informal statement) Suppose the  matrix M has rank r and obeys a certain “strong incoherence property”. Then with high probability, nuclear norm minimisation will recover M from a random sample provided that
matrix M has rank r and obeys a certain “strong incoherence property”. Then with high probability, nuclear norm minimisation will recover M from a random sample provided that 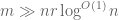 , where
, where  .
.
A result of a broadly similar nature, but with a rather different recovery algorithm and with a somewhat different range of applicability, was recently established by Keshavan, Oh, and Montanari. The strong incoherence property is somewhat technical, but is related to the Candés-Recht incoherence property and is satisfied by a number of reasonable random matrix models. The exponent O(1) here is reasonably civilised (ranging between 2 and 9, depending on the specific model and parameters being used).
The general strategy of proof is broadly similar to that in my first compressed sensing paper with Candés and Romberg, and also with the more recent paper of Candés and Recht. (The later papers, based around the restricted isometry property (RIP), are not directly applicable, as the possibility of concentrated singular values defeats the naive non-commutative analogue of the RIP. However, if one changes the measurement model by taking random Gaussian linear measurements of M (viewed as an -dimensional vector) rather than randomly sampling the entries, then one can recover an RIP-like property, together with most of the compressed sensing theory; see this paper of Recht, Fazel, and Parrilo.)
To begin the proof, one uses a duality argument (essentially just the Hahn-Banach theorem, combined with a standard computation of the (sub-)gradient of the nuclear norm) to equate the success of the nuclear norm minimisation with that of establishing the existence of a certain “dual certificate” matrix Y with certain technical properties relating to the sampling operator  , to the orthogonal projections
, to the orthogonal projections  to the spaces U, V generated by the left- and right- singular vectors
to the spaces U, V generated by the left- and right- singular vectors  appearing in the singular value decomposition
appearing in the singular value decomposition  of M, and also on the “sign pattern”
of M, and also on the “sign pattern”  of M. The strong incoherence property alluded to earlier is a condition on the matrix coefficients of
of M. The strong incoherence property alluded to earlier is a condition on the matrix coefficients of 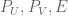 , basically saying that they behave in magnitude as if the singular vectors were distributed randomly.
, basically saying that they behave in magnitude as if the singular vectors were distributed randomly.
In order to locate this certificate, we perform a least-squares minimisation, which requires inverting and then estimating a certain operator arising from  . Inversion can be accomplished by using a useful selection lemma of Rudelson, but to obtain good estimates on the resulting certificate, we need to expand in Neumann series and estimate the spectral norm of a certain complicated combination of . The first few terms of this series were already controlled by Candés and Recht, using tools from high-dimensional geometry such as the non-commutative Khintchine inequality. However, these techniques do not seem to be able to fully exploit all the (increasingly non-commutative) cancellations present in these products of matrix operators after the fourth or fifth iterate or so, which is ultimately what causes the loss of in their result. To deal with this, we instead rely on the classical moment method, raising the operators involved to high powers and computing traces. As usual, this reduces us to considering certain sums over paths, which in this case are paths of horizontal, vertical, and “non-rook” moves in the grid . But the paths here end up being rather combinatorially complicated, resembling a “spider” with a compact body but many legs. Furthermore, there are some subtle cancellations in the coefficients (ultimately arising from identities such as
. Inversion can be accomplished by using a useful selection lemma of Rudelson, but to obtain good estimates on the resulting certificate, we need to expand in Neumann series and estimate the spectral norm of a certain complicated combination of . The first few terms of this series were already controlled by Candés and Recht, using tools from high-dimensional geometry such as the non-commutative Khintchine inequality. However, these techniques do not seem to be able to fully exploit all the (increasingly non-commutative) cancellations present in these products of matrix operators after the fourth or fifth iterate or so, which is ultimately what causes the loss of in their result. To deal with this, we instead rely on the classical moment method, raising the operators involved to high powers and computing traces. As usual, this reduces us to considering certain sums over paths, which in this case are paths of horizontal, vertical, and “non-rook” moves in the grid . But the paths here end up being rather combinatorially complicated, resembling a “spider” with a compact body but many legs. Furthermore, there are some subtle cancellations in the coefficients (ultimately arising from identities such as  ,
,  ,
,  , etc.) which need to be exploited in order to obtain near-optimal results, although in the bounded rank case r=O(1) it turns out that a relatively “low-tech” approach suffices (taking absolute values and using fairly crude estimates everywhere).
, etc.) which need to be exploited in order to obtain near-optimal results, although in the bounded rank case r=O(1) it turns out that a relatively “low-tech” approach suffices (taking absolute values and using fairly crude estimates everywhere).
The basic difficulty is that this spider can self-intersect in a large number of ways. Furthermore, it is not enough to track how often each vertex is traversed by this spider; one must also keep track of the various transitions the spider makes from one row to another, or from one column to another In some cases, the matrix coefficients arising from two of these transitions can “collapse” to a single matrix coefficient (due to identities such as ), replacing the combinatorial configuration of the spider with a “simpler” configuration. The strategy is then to exploit these identities to collapse the spider whenever possible, until no further cancellations remain, and it becomes safe to estimate everything by absolute values. This collapsing procedure is the most delicate portion of the paper, and is highly combinatorial in nature.
In a forthcoming paper of Candés and Plan, the exact recovery results here for noiseless measurement models will be extended to provide approximate recovery results in the presence of noise.


19 comments
Comments feed for this article
10 March, 2009 at 5:30 pm
davidspeyer
Typo in the first paragraph: “most of the entries are non-zero” should read “most of the entries are zero.” [Corrected, thanks – T.]
Sounds like interesting work!
10 March, 2009 at 11:53 pm
Dima
Matrix completion problems often come with an extra requirement that the solutions must be symmetric positive semi-definite. Then it is a particular kind of semidefinite programming, which is a generalisation of linear programming.
I wonder if you ever looked into extensing your condenced sensing technique to the semidefinite programming.
This would be wonderful news if something like this works there, too…
11 March, 2009 at 4:54 am
FhnuZoag
So, Prof Tao, are you actually working on the Netflix prize?
11 March, 2009 at 8:53 am
Terence Tao
Dear Dima,
Nuclear norm minimisation is already a convex optimisation program and so I would imagine that one could simply impose the semidefinite and symmetric conditions as an additional constraint and still get a computationally practical problem. It is not hard to show that if the original convex program recovered the correct solution, then the program with the additional a priori information on the solution added as a constraint would also recover the correct solution (providing, of course, that this a priori information is accurate). In fact any information of a convex nature can be incorporated easily. It may even be possible to improve the theoretical guarantees for recovery with this additional information, although this would require a complicated reworking of our random matrix calculations as one would be inserting additional projections into the dual certificate to try to “improve” it.
I believe there has been some experimentation to use SDPs instead of linear programs to improve the reach of compressed sensing, but I think the results so far are still rather partial and tentative.
Dear FhnuZoag: I am not directly working on this prize, but I understand that nuclear norm minimisation is already one of the techniques being incorporated into some of the competition efforts. Of course, being a messy real-world problem, one does not rely just on one tool, but on a wide variety of other methods as well, combined together in some empirically optimised fashion.
11 March, 2009 at 1:02 pm
john mangual
I don’t think there’s a single place in industry that isn’t trying to solve an underdetermined system of equations. I like the idea that a unique solution can exist if we impose other conditions on our solution (e.g. sparseness).
11 March, 2009 at 6:22 pm
Andrea Montanari
One interesting question is the following:
Assume that the graph induced by is uniformly random conditional on
is uniformly random conditional on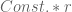 . Is then completion possible? For rank one this is
. Is then completion possible? For rank one this is
a minimum degree
true (but not so interesting).
If the answer is positive, then the logarithmic factor in the uniform model are just revealed entries.
revealed entries.
due to those columns/rows with less than
11 March, 2009 at 7:29 pm
Terence Tao
Dear Andrea,
I believe in the rank 1 case one also needs the graph induced by
one also needs the graph induced by  to be connected, otherwise one can multiply u on one connected component by a scalar and divide v on the same connected component by the same scalar and get a lack of uniqueness. But once one is connected and hits every row and column, one does get unique recovery in the rank 1 case. (But I guess connectedness becomes extremely likely once the mindegree is conditioned to be at least 3.)
to be connected, otherwise one can multiply u on one connected component by a scalar and divide v on the same connected component by the same scalar and get a lack of uniqueness. But once one is connected and hits every row and column, one does get unique recovery in the rank 1 case. (But I guess connectedness becomes extremely likely once the mindegree is conditioned to be at least 3.)
Similarly, in the rank r case one needs to not be able to disconnect the graph by removing r-1 edges. But I guess that if the min-degree is at least 3r (say) then this is also highly unlikely.
It may be that these are the only conditions for information-theoretic recovery of the data in the general rank case; it is an interesting question, and possibly a tractable one (one basically has to understand the tangent space of the space of rank r matrices, and in particular how the zero entries of a matrix in that tangent space can be distributed).
17 March, 2009 at 12:58 am
Igor Carron
Dear Terry,
The upcoming paper by Candes and Plan is now located at:
Click to access NoisyCompletion.pdf
Cheers,
Igor.
18 March, 2009 at 10:11 pm
Andrea Montanari
Dear Terence,
we submitted a long version of our paper:
Click to access spectral16.pdf
Any feedback is welcome.
Andrea
19 March, 2009 at 12:33 am
Greg Kuperberg
The papers describe this matrix completion problem and algorithm as analogous to compressed sensing. But could compressed sensing be interpreted as a special case of matrix completion, namely for circulant matrices? (Or maybe generalized circulant, for some other abelian or even non-abelian group.)
19 March, 2009 at 6:07 am
Mark Meckes
Greg: I may be missing something obvious here, since I have only a vague passing familiarity with compressed sensing, but what is the connection with circulant matrices?
19 March, 2009 at 9:19 am
Greg Kuperberg
The point is that first, a circulant matrix is an expanded form of its first row, which is an arbitrary vector; and second, that you obtain the singular values of the circulant matrix by taking the Fourier transform of that vector. I don’t know enough details of compressed sensing to say this for sure, but this construction leads me to ask whether matrix completion is not just analogous to compressed sensing, but rather a generalization.
20 March, 2009 at 1:49 am
Terence Tao
Dear Greg,
Hmm, that’s a good observation. The compressed sensing problem of recovering a function with few Fourier coefficients from a sparse sample is indeed formally equivalent to recovering a circulant matrix with low rank from a sparse sample, and the recovery algorithm used in the former (L^1 minimisation of the Fourier transform) is a special case of the recovery algorithm used in the latter (minimisation of nuclear norm).
20 March, 2009 at 10:46 am
Greg Kuperberg
There are many special cases of the matrix completion problem that could be called compressed sensing. As I said more briefly in the parentheses,
suppose that the rows and columns of a matrix are indexed by elements of a group, and suppose that the entry M_{ab} only depends on a^{-1}b. Then this is a generalized kind of circulant matrix, particularly if the group is non-commutative, and the recovery algorithm is another kind of compressed sensing.
For this reason, matrix completion could just as well be called non-commutative compressed sensing. This is surely a useful viewpoint. Also this phrase “nuclear norm” makes this slightly less clear, since that norm is of course just the spectral ell^1 norm.
The next question of course is what theorems about compressed sensing are subsumed by the matrix completion version. If a result has been subsumed, that’s interesting for one reason; and if it hasn’t been, it’s also interesting because you can ask why not.
—-
Taking things in a different direction, when I just skim the moment estimates in the matrix completion paper, it reminds me of the moment version of the non-commutative central limit theorem. (I don’t mean the free probability version, although that one is also a moment story, but rather the standard quantum probability version.) This is known as the Giri-von-Waldenfels theorem. I think that it’s an interesting problem to work out non-moment versions of this result, i.e., versions that more resemble convergence in distribution. A key problem is to define what convergence in distribution should mean in the quantum case. (Again, in the case of free probability it’s easier, because the limiting distribution is bounded and thus determined by its moments.) In my arXiv paper “A tracial quantum central limit theorem”, I obtained a partial result in this direction.
24 March, 2009 at 2:03 pm
Terence Tao
Dear Greg,
The noncommutative circulant matrices are interesting, although they begin to fall outside of the scope of matrix completion as it becomes quite hard for such matrices to be low rank (the noncommutative Fourier transform, in addition to being sparse, has to avoid all the high-dimensional irreducible representations). The proofs of the matrix completion results mimic in many places the compressed sensing results (and now I have a better understanding as to why, thanks to your observation), but they are more complicated and give worse bounds. (For instance, applying the result of this paper directly to the problem of measuring a function with only r Fourier coefficients using as few samples as possible, we need nr log^6 n or so random samples, whereas our original result in that case gave r log n. (The factor of n discrepancy is due to the fact that in the circulant case, measuring one matrix entry automatically gives you another n-1 matrix entries for free, so that should be ignored.)
At an early stage in the project with Emmanuel we tried using various non-commutative tools, notably the non-commutative Khintchine inequality, but the high moment expressions we ended up facing were just too entangled together in a non-commutative way for such tools to simplify the expressions we were facing. It seems that the moment method is actually one of the more robust methods for doing things like controlling operator norms of products of random matrices, though the combinatorial tasks needed to execute the method can be really quite sizeable.
24 March, 2009 at 4:25 pm
Greg Kuperberg
Yeah I sort of figured that the log factors would be worse. Of course it raises the question of what’s better about circulant matrices, actual convergence/completion or merely the methods for obtaining bounds.
As for non-commutative circulant matrices, it is true that there is a relevant negative result concerning the structure of finite groups. Namely, if all irreps have dimension at most k, then the group G has an abelian subgroup of index at most f(k). However, I think that f may grow quickly enough that there is a middle ground, where the rank is not all that much larger than sparseness and yet G is not all that close to abelian.
Then too, when you have a non-commutative circulant matrix M, or indeed in any circumstance when M a priori commutes with some group action of a group G, then the spectrum of M is colored by the irreps of G. So in this case you have many natural variations of the nuclear norm obtained by assigning different weights to the irreps. Should each irrep be weighted by its dimension, as you will obtain by direct restriction of the ordinary nuclear norm? Or should it be weighted by 1, or by something in between? Well, maybe it’s as simple as that the sparseness promise is described with a weighting, and the convex relaxation should simply be chosen with the same weighting.
27 March, 2009 at 1:01 pm
Adam
Hello Professor Tao,
Have you seen this paper on a related method? Thought you might like to check this out:
http://arxiv.org/abs/0901.1898
– Adam
7 November, 2009 at 5:25 pm
Joe Smith
As I understand these papers (which is not well) the random sample from the matrix is drawn as though you had a single bin containing one ball for each element in the n1 x n2 matrix M and drew out balls randomly.
Would a more restricted and realistic sampling method allow tighter proofs?
Suppose:
1.) You have a bin (the “row” bin) containing n2 balls for each of the values 1 … n1. (IE there are n1 * n2 balls altogether in the row bin)
2.) You have n1 bins (the “column” bins), labelled 1 .. n1, each containing n2 balls marked consecutively 1 … n2
You draw a ball from the row bin (which gives you a row number) and then draw a ball from the “columns” bin corresponding to the row number you have just drawn. The combination of the two balls now identifies an entry.
Identifying entries in this way would be more realistic and should result in a subset which is less likely to grossly over or under represent some rows or columns and hence should allow slightly tighter bounds.
Just a thought.
1 April, 2010 at 7:32 am
Jagannathan Arjun S
Dr.Tao,
I apologize for my ignorance in advance and am thankful for the time taken in reading what i have put down.
I did read a few papers on matrix completion, in particular :
a. Candes and Recht :Exact matrix completion via convex optimization
b. Zhisu Zu et al: Fast and near-optimal matrix completion via randomized basis pursuit
To what i can interpret in the crudest sense is that:
1: first the linearly independent columns of a matrix A or rank r are selected by some suitable algorithm
2. Then the other columns are expressed as a linear combination of these columns.
Hence the entire purpose of this matrix completion algorithm is that using these basis vectors we fill in the entries of other rows.
I am an undergraduate working on data compression using compressive projection principal component analysis by J Fowler.
There we multiply a given data matrix with a random orthonormal matrix reducing the dimension and multiply.
then using the the transpose of the same random orthonormal matrix and use rayleigh ritz theory to approximate the real eigenvectors with the ritz vectors. Then we reconstruct using PCA.
This really works well for hyperspectral data but fails for normal images as the normalized ritz vectors are unaligned to the real eigen vectors significantly
The covariance varies significantly from that of the input images data. I wonder can this matrix completion be used for data compression by making just randomly selecting the basis vectors of the input image.
sorry for the trouble