
You are currently browsing the tag archive for the ‘ultrafilters’ tag.
A major topic of interest of analytic number theory is the asymptotic behaviour of the Riemann zeta function 

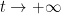
![{\log |\zeta|: {\bf C} \rightarrow [-\infty,+\infty]}](https://s0.wp.com/latex.php?latex=%7B%5Clog+%7C%5Czeta%7C%3A+%7B%5Cbf+C%7D+%5Crightarrow+%5B-%5Cinfty%2C%2B%5Cinfty%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
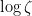
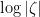
One has the classical estimate
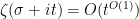
 and
and 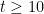 (say), so that
(say), so that 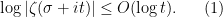
(See e.g. Exercise 37 from Supplement 3.) In view of this, let us define the normalised log-magnitudes ![{F_T: {\bf C} \rightarrow [-\infty,+\infty]}](https://s0.wp.com/latex.php?latex=%7BF_T%3A+%7B%5Cbf+C%7D+%5Crightarrow+%5B-%5Cinfty%2C%2B%5Cinfty%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
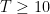
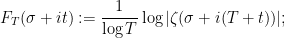
informally, this is a normalised window into 
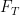
- (i) The bound (1) implies that
, thus for any compact set
we have
for
and
sufficiently large. In fact the implied constant in
only depends on the projection of
- (ii) For
, we have the bounds
which implies that
to zero in the region
.
- (iii) The functional equation, together with the symmetry
, implies that
which by Exercise 17 of Supplement 3 shows that
as
. In particular, when combined with the previous item, we see that
converges locally uniformly as
in the region
.
- (iv) From Jensen’s formula (Theorem 16 of Supplement 2) we see that
is a subharmonic function, and thus
for any disk
, where the integral is with respect to area measure. From this and (ii) we conclude that
for any disk with
and sufficiently large
in the limit
for sufficiently large

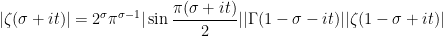

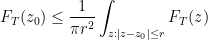

From (iv) and the usual Arzela-Ascoli diagonalisation argument, we see that the 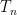
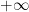

- (i)
.
- (ii)
.
- (iii) We have the functional equation
for all
for
.
- (iv)
Unfortunately, (i)-(iv) fail to characterise 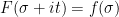
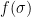


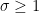

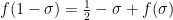


We pause to address one minor technicality. We have defined 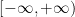
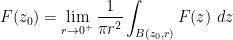
for any 

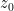
By a classical theorem of Riesz, a function 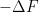
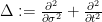

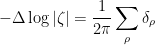
away from the real axis, where 
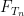

where 

Thus
Using this machinery, we can recover many classical theorems about the Riemann zeta function by “soft” arguments that do not require extensive calculation. Here are some examples:
Theorem 1 The Riemann hypothesis implies the Lindelöf hypothesis.
Proof: It suffices to show that any limiting profile 
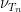
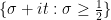

In fact, we have the following sharper statement:
Theorem 2 (Backlund) The Lindelöf hypothesis is equivalent to the assertion that for any fixed
, the number of zeroes in the region
is
as
Proof: If the latter claim holds, then for any 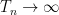




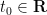
Conversely, suppose the claim fails, then we can find a sequence 
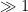
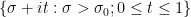
Theorem 3 (Littlewood) Assume the Lindelöf hypothesis. Then for any fixed
, the number of zeroes in the region
is
as
Proof: By the previous arguments, the only possible normalised limiting profile for 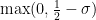
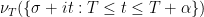

Even without the Lindelöf hypothesis, we have the following result:
Theorem 4 (Titchmarsh) For any fixed
zeroes in the region
Among other things, this theorem recovers a classical result of Littlewood that the gaps between the imaginary parts of the zeroes goes to zero, even without assuming unproven conjectures such as the Riemann or Lindelöf hypotheses.
Proof: Suppose for contradiction that this were not the case, then we can find 
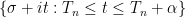

Exercise 5 Use limiting profiles to obtain the matching upper bound of
for the number of zeroes in
Remark 6 One can remove the need to take limiting profiles in the above arguments if one can come up with quantitative (or “hard”) substitutes for qualitative (or “soft”) results such as the unique continuation property for harmonic functions. This would also allow one to replace the qualitative decay rates
or
. Indeed, the classical proofs of the above theorems come with quantitative bounds that are typically of this form (see e.g. the text of Titchmarsh for details).
Exercise 7 Let
denote the quantity
, where the branch of the argument is taken by using a line segment connecting
to (say)
, and then to
. If we have a sequence
for
converges in the sense of distributions to the function
, or equivalently
Conclude in particular that if the Lindelöf hypothesis holds, then
as

A little bit more about the normalised limit profiles 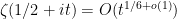

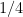

Better control on limiting profiles is available if we do not insist on controlling
(This is an extended blog post version of my talk “Ultraproducts as a Bridge Between Discrete and Continuous Analysis” that I gave at the Simons institute for the theory of computing at the workshop “Neo-Classical methods in discrete analysis“. Some of the material here is drawn from previous blog posts, notably “Ultraproducts as a bridge between hard analysis and soft analysis” and “Ultralimit analysis and quantitative algebraic geometry“‘. The text here has substantially more details than the talk; one may wish to skip all of the proofs given here to obtain a closer approximation to the original talk.)
Discrete analysis, of course, is primarily interested in the study of discrete (or “finitary”) mathematical objects: integers, rational numbers (which can be viewed as ratios of integers), finite sets, finite graphs, finite or discrete metric spaces, and so forth. However, many powerful tools in mathematics (e.g. ergodic theory, measure theory, topological group theory, algebraic geometry, spectral theory, etc.) work best when applied to continuous (or “infinitary”) mathematical objects: real or complex numbers, manifolds, algebraic varieties, continuous topological or metric spaces, etc. In order to apply results and ideas from continuous mathematics to discrete settings, there are basically two approaches. One is to directly discretise the arguments used in continuous mathematics, which often requires one to keep careful track of all the bounds on various quantities of interest, particularly with regard to various error terms arising from discretisation which would otherwise have been negligible in the continuous setting. The other is to construct continuous objects as limits of sequences of discrete objects of interest, so that results from continuous mathematics may be applied (often as a “black box”) to the continuous limit, which then can be used to deduce consequences for the original discrete objects which are quantitative (though often ineffectively so). The latter approach is the focus of this current talk.
The following table gives some examples of a discrete theory and its continuous counterpart, together with a limiting procedure that might be used to pass from the former to the latter:
| (Discrete) | (Continuous) | (Limit method) |
| Ramsey theory | Topological dynamics | Compactness |
| Density Ramsey theory | Ergodic theory | Furstenberg correspondence principle |
| Graph/hypergraph regularity | Measure theory | Graph limits |
| Polynomial regularity | Linear algebra | Ultralimits |
| Structural decompositions | Hilbert space geometry | Ultralimits |
| Fourier analysis | Spectral theory | Direct and inverse limits |
| Quantitative algebraic geometry | Algebraic geometry | Schemes |
| Discrete metric spaces | Continuous metric spaces | Gromov-Hausdorff limits |
| Approximate group theory | Topological group theory | Model theory |
As the above table illustrates, there are a variety of different ways to form a limiting continuous object. Roughly speaking, one can divide limits into three categories:
- Topological and metric limits. These notions of limits are commonly used by analysts. Here, one starts with a sequence (or perhaps a net) of objects
in a common space
, which one then endows with the structure of a topological space or a metric space, by defining a notion of distance between two points of the space, or a notion of open neighbourhoods or open sets in the space. Provided that the sequence or net is convergent, this produces a limit object
, which remains in the same space, and is “close” to many of the original objects
- Categorical limits. These notions of limits are commonly used by algebraists. Here, one starts with a sequence (or more generally, a diagram) of objects
or the inverse limit
of these objects, which is another object in the same category
- Logical limits. These notions of limits are commonly used by model theorists. Here, one starts with a sequence of objects
or of spaces
, each of which is (a component of) a model for given (first-order) mathematical language (e.g. if one is working in the language of groups,
or a new space
, which is still a model of the same language (e.g. if the spaces
.)
The purpose of this talk is to highlight the third type of limit, and specifically the ultraproduct construction, as being a “universal” limiting procedure that can be used to replace most of the limits previously mentioned. Unlike the topological or metric limits, one does not need the original objects
With so few requirements on the objects
Ultraproducts are not the only logical limit in the model theorist’s toolbox, but they are one of the simplest to set up and use, and already suffice for many of the applications of logical limits outside of model theory. In this post, I will set out the basic theory of these ultraproducts, and illustrate how they can be used to pass between discrete and continuous theories in each of the examples listed in the above table.
Apart from the initial “one-time cost” of setting up the ultraproduct machinery, the main loss one incurs when using ultraproduct methods is that it becomes very difficult to extract explicit quantitative bounds from results that are proven by transferring qualitative continuous results to the discrete setting via ultraproducts. However, in many cases (particularly those involving regularity-type lemmas) the bounds are already of tower-exponential type or worse, and there is arguably not much to be lost by abandoning the explicit quantitative bounds altogether.
I’ve just uploaded to the arXiv my joint paper with Vitaly Bergelson, “Multiple recurrence in quasirandom groups“, which is submitted to Geom. Func. Anal.. This paper builds upon a paper of Gowers in which he introduced the concept of a quasirandom group, and established some mixing (or recurrence) properties of such groups. A 
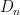
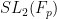



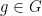

where 





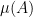
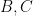

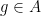
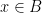
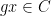



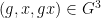

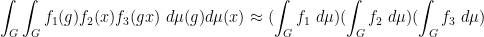
for any bounded functions 
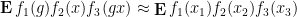
where 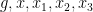
As observed in Gowers’ paper, one can iterate this observation to find “parallelopipeds” of any given dimension in dense subsets of 



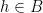
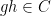
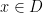
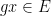
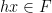
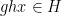

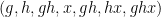

However, there are other tuples for which the above iteration argument does not seem to apply. One of the simplest tuples in this vein is the tuple 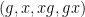

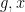
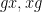


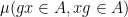

Theorem 1 Let
, we have
where
,
are drawn uniformly and independently at random from
is drawn uniformly at random from the conjugates of
for each fixed choice of
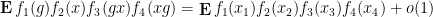
This is the probabilistic formulation of the above theorem; one can also phrase the theorem in other formulations (such as an integral formulation), and this is detailed in the paper. This theorem leads to a number of recurrence results; for instance, as a corollary of this result, we have

for almost all 
To me, the more interesting thing here is not the result itself, but how it is proven. Vitaly and I were not able to find a purely finitary way to establish this mixing theorem. Instead, we had to first use the machinery of ultraproducts (as discussed in this previous post) to convert the finitary statement about a quasirandom group to an infinitary statement about a type of infinite group which we call an ultra quasirandom group (basically, an ultraproduct of increasingly quasirandom finite groups). This is analogous to how the Furstenberg correspondence principle is used to convert a finitary combinatorial problem into an infinitary ergodic theory problem.
Ultra quasirandom groups come equipped with a finite, countably additive measure known as Loeb measure 

for “almost all” 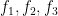
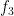
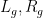

To establish this mixing theorem, we use the machinery of idempotent ultrafilters, which is a particularly useful tool for understanding the ergodic theory of actions of countable groups 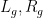
Idempotent ultrafilters are an extremely infinitary type of mathematical object (one has to use Zorn’s lemma no fewer than three times just to construct one of these objects!). So it is quite remarkable that they can be used to establish a finitary theorem such as Theorem 1, though as is often the case with such infinitary arguments, one gets absolutely no quantitative control whatsoever on the error terms 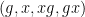
We also have some miscellaneous other results in the paper. It turns out that by using the triangle removal lemma from graph theory, one can obtain a recurrence result that asserts that whenever 



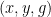
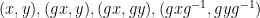
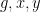
We also give some properties of a model example of an ultra quasirandom group, namely the ultraproduct 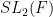

Roughly speaking, mathematical analysis can be divided into two major styles, namely hard analysis and soft analysis. The precise distinction between the two types of analysis is imprecise (and in some cases one may use a blend the two styles), but some key differences can be listed as follows.
- Hard analysis tends to be concerned with quantitative or effective properties such as estimates, upper and lower bounds, convergence rates, and growth rates or decay rates. In contrast, soft analysis tends to be concerned with qualitative or ineffective properties such as existence and uniqueness, finiteness, measurability, continuity, differentiability, connectedness, or compactness.
- Hard analysis tends to be focused on finitary, finite-dimensional or discrete objects, such as finite sets, finitely generated groups, finite Boolean combination of boxes or balls, or “finite-complexity” functions, such as polynomials or functions on a finite set. In contrast, soft analysis tends to be focused on infinitary, infinite-dimensional, or continuous objects, such as arbitrary measurable sets or measurable functions, or abstract locally compact groups.
- Hard analysis tends to involve explicit use of many parameters such as
,
,
, etc. In contrast, soft analysis tends to rely instead on properties such as continuity, differentiability, compactness, etc., which implicitly are defined using a similar set of parameters, but whose parameters often do not make an explicit appearance in arguments.
- In hard analysis, it is often the case that a key lemma in the literature is not quite optimised for the application at hand, and one has to reprove a slight variant of that lemma (using a variant of the proof of the original lemma) in order for it to be suitable for applications. In contrast, in soft analysis, key results can often be used as “black boxes”, without need of further modification or inspection of the proof.
- The properties in soft analysis tend to enjoy precise closure properties; for instance, the composition or linear combination of continuous functions is again continuous, and similarly for measurability, differentiability, etc. In contrast, the closure properties in hard analysis tend to be fuzzier, in that the parameters in the conclusion are often different from the parameters in the hypotheses. For instance, the composition of two Lipschitz functions with Lipschitz constant
instead of
In the lectures so far, focusing on the theory surrounding Hilbert’s fifth problem, the results and techniques have fallen well inside the category of soft analysis. However, we will now turn to the theory of approximate groups, which is a topic which is traditionally studied using the methods of hard analysis. (Later we will also study groups of polynomial growth, which lies on an intermediate position in the spectrum between hard and soft analysis, and which can be profitably analysed using both styles of analysis.)
Despite the superficial differences between hard and soft analysis, though, there are a number of important correspondences between results in hard analysis and results in soft analysis. For instance, if one has some sort of uniform quantitative bound on some expression relating to finitary objects, one can often use limiting arguments to then conclude a qualitative bound on analogous expressions on infinitary objects, by viewing the latter objects as some sort of “limit” of the former objects. Conversely, if one has a qualitative bound on infinitary objects, one can often use compactness and contradiction arguments to recover uniform quantitative bounds on finitary objects as a corollary.
Remark 1 Another type of correspondence between hard analysis and soft analysis, which is “syntactical” rather than “semantical” in nature, arises by taking the proofs of a soft analysis result, and translating such a qualitative proof somehow (e.g. by carefully manipulating quantifiers) into a quantitative proof of an analogous hard analysis result. This type of technique is sometimes referred to as proof mining in the proof theory literature, and is discussed in this previous blog post (and its comments). We will however not employ systematic proof mining techniques here, although in later posts we will informally borrow arguments from infinitary settings (such as the methods used to construct Gleason metrics) and adapt them to finitary ones.
Let us illustrate the correspondence between hard and soft analysis results with a simple example.
Proposition 1 Let
be a dense subset of
be a continuous function (giving the extended half-line
the usual order topology). Then the following statements are equivalent:
- (i) (Qualitative bound on infinitary objects) For all
, one has
.
- (ii) (Quantitative bound on finitary objects) There exists
such that
for all
.
In applications,
Proof: To see that (ii) implies (i), observe from density that every point 

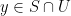
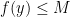
Conversely, to show that (i) implies (ii), we use the “compactness and contradiction” argument. Suppose for sake of contradiction that (ii) failed. Then for any natural number 

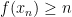
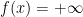
Remark 2 Note that the above deduction of (ii) from (i) is ineffective in that it gives no explicit bound on the uniform bound
in (ii). Without any further information on how the qualitative bound (i) is proven, this is the best one can do in general (and this is one of the most significant weaknesses of infinitary methods when used to solve finitary problems); but if one has access to the proof of (i), one can often finitise or proof mine that argument to extract an effective bound for
The above simple example illustrates that in order to get from an “infinitary” statement such as (i) to a “finitary” statement such as (ii), a key step is to be able to take a sequence 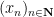
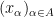
- (Topological limit) If the
- (Categorical limit) If the
to
or inverse limit
of these objects to form a limiting object
- (Logical limit) If the
or limiting space
that is a logical limit of the
The three types of limits are analogous in many ways, with a number of connections between them. For instance, in the study of groups of polynomial growth, both topological limits (using the metric notion of Gromov-Hausdorff convergence) and logical limits (using the ultralimit construction) are commonly used, and to some extent the two constructions are at least partially interchangeable in this setting. (See also these previous posts for the use of ultralimits as a substitute for topological limits.) In the theory of approximate groups, though, it was observed by Hrushovski that logical limits (and in particular, ultraproducts) are the most useful type of limit to connect finitary approximate groups to their infinitary counterparts. One reason for this is that one is often interested in obtaining results on approximate groups 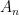

Logical limits are closely tied with non-standard analysis. Indeed, by applying an ultraproduct construction to standard number systems such as the natural numbers 

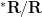
In these notes, we lay out the basic theory of ultraproducts and ultralimits (in particular, proving Los’s theorem, which roughly speaking asserts that ultralimits are limits in a logical sense, as well as the countable saturation property alluded to earlier). We also lay out some of the basic foundations of nonstandard analysis, although we will not rely too heavily on nonstandard tools in this course. Finally, we apply this general theory to approximate groups, to connect finite approximate groups to an infinitary type of approximate group which we will call an ultra approximate group. We will then study these ultra approximate groups (and models of such groups) in more detail in the next set of notes.
Remark 3 Throughout these notes (and in the rest of the course), we will assume the axiom of choice, in order to easily use ultrafilter-based tools. If one really wanted to expend the effort, though, one could eliminate the axiom of choice from the proofs of the final “finitary” results that one is ultimately interested in proving, at the cost of making the proofs significantly lengthier. Indeed, there is a general result of Gödel that any result which can be stated in the language of Peano arithmetic (which, roughly speaking, means that the result is “finitary” in nature), and can be proven in set theory using the axiom of choice (or more precisely, in the ZFC axiom system), can also be proven in set theory without the axiom of choice (i.e. in the ZF system). As this course is not focused on foundations, we shall simply assume the axiom of choice henceforth to avoid further distraction by such issues.
I have blogged a number of times in the past about the relationship between finitary (or “hard”, or “quantitative”) analysis, and infinitary (or “soft”, or “qualitative”) analysis. One way to connect the two types of analysis is via compactness arguments (and more specifically, contradiction and compactness arguments); such arguments can convert qualitative properties (such as continuity) to quantitative properties (such as bounded), basically because of the fundamental fact that continuous functions on a compact space are bounded (or the closely related fact that sequentially continuous functions on a sequentially compact space are bounded).
A key stage in any such compactness argument is the following: one has a sequence 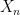
However, there is a slightly different approach, which I will call ultralimit analysis, which proceeds via the machinery of ultrafilters and ultraproducts; typically, the limit objects 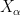
Ultralimit analysis is very closely related to nonstandard analysis. I already discussed some aspects of this relationship in an earlier post, and will expand upon it at the bottom of this post. Roughly speaking, the relationship between ultralimit analysis and nonstandard analysis is analogous to the relationship between measure theory and probability theory.
To illustrate how ultralimit analysis is actually used in practice, I will show later in this post how to take a qualitative infinitary theory – in this case, basic algebraic geometry – and apply ultralimit analysis to then deduce a quantitative version of this theory, in which the complexity of the various algebraic sets and varieties that appear as outputs are controlled uniformly by the complexity of the inputs. The point of this exercise is to show how ultralimit analysis allows for a relatively painless conversion back and forth between the quantitative and qualitative worlds, though in some cases the quantitative translation of a qualitative result (or vice versa) may be somewhat unexpected. In an upcoming paper of myself, Ben Green, and Emmanuel Breuillard (announced in the previous blog post), we will rely on ultralimit analysis to reduce the messiness of various quantitative arguments by replacing them with a qualitative setting in which the theory becomes significantly cleaner.
For sake of completeness, I also redo some earlier instances of the correspondence principle via ultralimit analysis, namely the deduction of the quantitative Gromov theorem from the qualitative one, and of Szemerédi’s theorem from the Furstenberg recurrence theorem, to illustrate how close the two techniques are to each other.
One way to study a general class of mathematical objects is to embed them into a more structured class of mathematical objects; for instance, one could study manifolds by embedding them into Euclidean spaces. In these (optional) notes we study two (related) embedding theorems for topological spaces:
- The Stone-Čech compactification, which embeds locally compact Hausdorff spaces into compact Hausdorff spaces in a “universal” fashion; and
- The Urysohn metrization theorem, that shows that every second-countable normal Hausdorff space is metrizable.
A (concrete) Boolean algebra is a pair 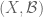

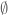

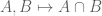

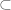

and meet
.
- We have the distributive laws
and
.
is the maximal element.
and
.
(More succinctly:
We can then define an abstract Boolean algebra 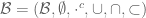

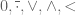
Clearly, every concrete Boolean algebra is an abstract Boolean algebra. In the converse direction, we have Stone’s representation theorem (see below), which asserts (among other things) that every abstract Boolean algebra is isomorphic to a concrete one (and even constructs this concrete representation of the abstract Boolean algebra canonically). So, up to (abstract) isomorphism, there is really no difference between a concrete Boolean algebra and an abstract one.
Now let us turn from Boolean algebras to 
A concrete 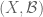
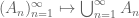

5. Any countable family 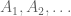
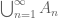
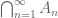
As with Boolean algebras, one can now define an abstract 
The answer turns out to be no, but the obstruction can be described precisely (namely, one needs to quotient out an ideal of “null sets” from the concrete 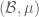

In the rest of this post, I will state and prove these representation theorems. They are not actually used directly in the rest of the course (and they will also require some results that we haven’t proven yet, most notably Tychonoff’s theorem), and so these notes are optional reading; but these theorems do help explain why it is “safe” to focus attention primarily on concrete
This post is in some ways an antithesis of my previous postings on hard and soft analysis. In those posts, the emphasis was on taking a result in soft analysis and converting it into a hard analysis statement (making it more “quantitative” or “effective”); here we shall be focusing on the reverse procedure, in which one harnesses the power of infinitary mathematics – in particular, ultrafilters and nonstandard analysis – to facilitate the proof of finitary statements.
Arguments in hard analysis are notorious for their profusion of “epsilons and deltas”. In the more sophisticated arguments of this type, one can end up having an entire army of epsilons 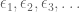

For those who practice hard analysis for a living (such as myself), it is natural to wonder if one can somehow “clean up” or “automate” all the epsilon management which one is required to do, and attain levels of elegance and conceptual clarity comparable to those in soft analysis, hopefully without sacrificing too much of the “elementary” or “finitary” nature of hard analysis in the process.

Recent Comments