
As in all previous posts in this series, we adopt the following asymptotic notation: 
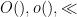



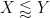

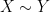
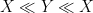
The purpose of this (rather technical) post is both to roll over the polymath8 research thread from this previous post, and also to record the details of the latest improvement to the Type I estimates (based on exploiting additional averaging and using Deligne’s proof of the Weil conjectures) which lead to a slight improvement in the numerology.
In order to obtain this new Type I estimate, we need to strengthen the previously used properties of “dense divisibility” or “double dense divisibility” as follows.
Definition 1 (Multiple dense divisibility) Let
. For each natural number
, we define a notion of
-tuply
-dense divisibility recursively as follows:
- Every natural number
is
-tuply
- If
and
are natural numbers with
, and
, one can find a factorisation
with
such that
-tuply
is
-tuply
We let
denote the set of
-tuply densely divisible” as “densely divisible”, “
-tuply densely divisible” as “doubly densely divisible”, and so forth; we also abbreviate
as
.
Given any finitely supported sequence 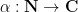
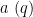

We now recall the key concept of a coefficient sequence, with some slight tweaks in the definitions that are technically convenient for this post.
Definition 2 A coefficient sequence is a finitely supported sequence
that obeys the bounds
for all
is the divisor function.
- (i) A coefficient sequence
is said to be located at scale
for some
if it is supported on an interval of the form
for some
.
- (ii) A coefficient sequence
for any
, any fixed
, and any primitive residue class
.
- (iii) A coefficient sequence
is said to be smooth if it takes the form
for some smooth function
supported on an interval of size
and obeying the derivative bounds
for all fixed
(note that the implied constant in the
notation may depend on

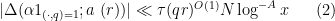

Note that we allow sequences to be smooth at scale 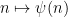
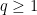

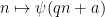

Now we adapt the Type I estimate to the
Definition 3 (Type I estimates) Let
,
, and
be fixed quantities, and let
be an arbitrary bounded subset of
, let
, and let
a primitive congruence class. We say that
holds if, whenever
are quantities with
for some fixed
, and
are coefficient sequences located at scales
respectively, with
obeying a Siegel-Walfisz theorem, we have
for any fixed
. Here, as in previous posts,
denotes the square-free natural numbers whose prime factors lie in
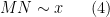
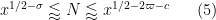
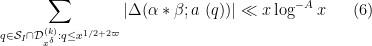
The main theorem of this post is then
Theorem 4 (Improved Type I estimate) We have
whenever
and
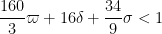

In practice, the first condition here is dominant. Except for weakening double dense divisibility to quadruple dense divisibility, this improves upon the previous Type I estimate that established ![{Type^{(2)}_I[\varpi,\delta,\sigma]}](https://s0.wp.com/latex.php?latex=%7BType%5E%7B%282%29%7D_I%5B%5Cvarpi%2C%5Cdelta%2C%5Csigma%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
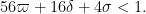
As in previous posts, Type I estimates (when combined with existing Type II and Type III estimates) lead to distribution results of Motohashi-Pintz-Zhang type. For any fixed 
![{MPZ^{(k)}[\varpi,\delta]}](https://s0.wp.com/latex.php?latex=%7BMPZ%5E%7B%28k%29%7D%5B%5Cvarpi%2C%5Cdelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \sum_{q \in {\mathcal S}_I \cap {\mathcal D}_{x^\delta}^{(k)}: q \leq x^{1/2+2\varpi}} |\Delta(\Lambda 1_{[x,2x]}; a\ (q))| \ll x \log^{-A} x \ \ \ \ \ (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csum_%7Bq+%5Cin+%7B%5Cmathcal+S%7D_I+%5Ccap+%7B%5Cmathcal+D%7D_%7Bx%5E%5Cdelta%7D%5E%7B%28k%29%7D%3A+q+%5Cleq+x%5E%7B1%2F2%2B2%5Cvarpi%7D%7D+%7C%5CDelta%28%5CLambda+1_%7B%5Bx%2C2x%5D%7D%3B+a%5C+%28q%29%29%7C+%5Cll+x+%5Clog%5E%7B-A%7D+x+%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=0&c=20201002)
for any fixed 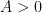

![{MPZ^{(4)}[\varpi,\delta]}](https://s0.wp.com/latex.php?latex=%7BMPZ%5E%7B%284%29%7D%5B%5Cvarpi%2C%5Cdelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) whenever
whenever 
Proof: Setting 

![{Type^{(4)}_{II}[\varpi,\delta]}](https://s0.wp.com/latex.php?latex=%7BType%5E%7B%284%29%7D_%7BII%7D%5B%5Cvarpi%2C%5Cdelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

and

The second condition is implied by the first and can be deleted.
From this previous post we know that ![{Type'_{II}[\varpi,\delta], Type''_{II}[\varpi,\delta]}](https://s0.wp.com/latex.php?latex=%7BType%27_%7BII%7D%5B%5Cvarpi%2C%5Cdelta%5D%2C+Type%27%27_%7BII%7D%5B%5Cvarpi%2C%5Cdelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
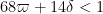
while ![{Type^{(4)}_{III}[\varpi,\delta,\sigma]}](https://s0.wp.com/latex.php?latex=%7BType%5E%7B%284%29%7D_%7BIII%7D%5B%5Cvarpi%2C%5Cdelta%2C%5Csigma%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Again, these conditions are implied by (8). The claim then follows from the Heath-Brown identity and dyadic decomposition as in this previous post.

As before, we let ![{DHL[k_0,2]}](https://s0.wp.com/latex.php?latex=%7BDHL%5Bk_0%2C2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
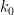
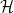
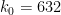 .
.
This follows from the Pintz sieve, as discussed below the fold. Combining this with the best known prime tuples, we obtain that there are infinitely many prime gaps of size at most 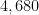
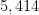
— 1. Multiple dense divisibility —
We record some useful properties of dense divisibility.
Lemma 7 (Properties of dense divisibility) Let
- (i) If
is a factor of
-densely divisible. Similarly, if
is a multiple of
-densely divisible.
- (ii) If
are
is also
- (iii) Any
- (iv) If
-smooth and square-free for some
, and
, then
Proof: (i) is easily established by induction on 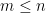
![{n \geq [m,n]^{1/2}}](https://s0.wp.com/latex.php?latex=%7Bn+%5Cgeq+%5Bm%2Cn%5D%5E%7B1%2F2%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{a := \frac{[m,n]}{n}}](https://s0.wp.com/latex.php?latex=%7Ba+%3A%3D+%5Cfrac%7B%5Bm%2Cn%5D%7D%7Bn%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The claim (iii) is easily established by induction on 

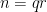





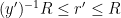
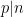
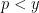
Finally we consider the 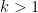
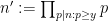
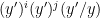
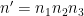

and

and thus

Now we divide into several cases. Suppose first that 

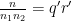


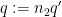
Now suppose that 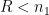
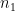

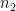
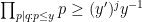
Finally, suppose that 


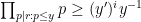
Now we record the criterion for using 
Proposition 8 (Criterion for DHL) Let
be such that
and real numbers
and
where
Then



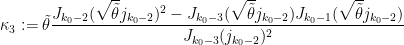




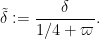
Proof: We use the Pintz sieve from this post, repeating the proof of Theorem 5 from that post (and using the explicit formulae for 
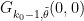

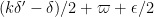


Applying this proposition with 
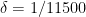

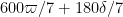

![{DHL[632,2]}](https://s0.wp.com/latex.php?latex=%7BDHL%5B632%2C2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
— 2. van der Corput estimates —
In this section we generalise the van der Corput estimates from Section 1 of this previous post to wider classes of “structured functions” than rational phases. We will adopt an axiomatic approach, laying out the precise axioms that we need a given class of structured functions to obey:
Definition 9 (Structured functions) Let
of collections
of functions
defined on subsets
of
for each prime
and every
; an element of
and modulus
. Furthermore we place an equivalence relation
on each class
- (i) (Monotonicity) One has
whenever
. Furthermore, if
, the equivalence relations on
agree on their common domain of definition.
- (ii) (Near-total definition) If
, then the domain
consists of
points removed.
- (iii) (Pointwise bound) If
for all
- (iv) (Conjugacy) If
for some
.
- (v) (Multiplication) If
, then the pointwise product
(on the common domain of definition) can be expressed as the sum of
functions
(which we will call the components of
- (vi) (Translation invariance) If
, then the function
(defined on the translation
of the domain of definition of
- (vii) (Dilation invariance) If
, then the function
(defined on the dilation
of the domain of definition of
) lies in
- (viii) (Polynomial phases) If
is a polynomial of degree at most
, then the function
lies in
. More generally, if
lies in
. Furthermore, if
, this operation respects the equivalence relation
if and only if
. Finally, if
and
.
- (ix) (Almost orthogonality) If
respectively, one has
for an algebraic integer
, with the error term
being Galois-absolute in the sense that all Galois conjugates of the error term are also
.
- (x) (Integration) Suppose that
contains a component equivalent to
. Suppose also that
such that
.
Example 1 (Polynomial phases) Let
, where
will be declared equivalent if
differ only in the constant term. Note from the Chinese remainder theorem that the function
is then also a structured function of complexity at most
Example 2 (Polynomial phases twisted by characters) Let
, where
is a phase,
are polynomials of degree at most
, and the
are Dirichlet characters of order
is then also a structured function of complexity at most
is undefined (instead of vanishing) when
.
Example 3 (Rational phases) Let
, where
monic, with the function only defined when
, then this is a class of structured functions (again, the almost orthogonality axiom requires the Weil conjectures for curves). We declare two structured functions to be equivalent if they agree up to a constant phase on their common domain of definition. Note from the Chinese remainder theorem that the function
is then also a structured function of complexity at most
Example 4 (Trace weights) Let
not in
of the
. If, for every prime
of the form
where
with at most
is a lisse
to be equivalent if one has
and
for some geometrically isotypic sheaves
whose geometrically irreducible components are isomorphic. The almost orthogonality now is deeper, being a consequence of Deligne’s second proof of the Weil conjectures, and also using a form of Schur’s lemma for sheaves; see Section 5 of this paper of Fouvry, Kowalski, and Michel. The integration axiom follows from Lemma 5.3 of the same paper. This class of structured functions includes the previous three classes, but also includes Kloosterman-type objects such as
(and many other exponential sums) besides. (Indeed, it basically closed under the operations of Fourier transforms, convolution, and pullback, as long as certain degenerate cases are avoided.)
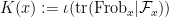
We now turn to the problem of obtaining non-trivial bounds for the expression

where 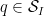

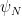

since one has 






We first need a lemma:
Lemma 10 (Fundamental theorem of calculus) Let
be a class of structured functions. Let
, let
. Let
for all
for which this identity is well-defined. Then there exists a polynomial
of degree at most
such that
for all
Proof: By dilating by 






for some coefficients 

then 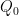
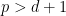




Now we can state the van der Corput estimate.
Proposition 11 (van der Corput) Let
be a structured function of modulus
be fixed, and let
denote the set of sufficiently large primes
of degree at most
, and let
. Then for any
, and any coefficient sequence function
which is smooth at scale
where
,
, and
, where the sum is implicitly assumed to range over those
is defined.

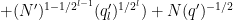
The 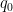
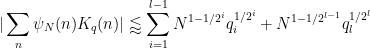
under reasonable non-degeneracy conditions. Assuming sufficient dense divisibility and in the regime 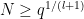


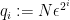
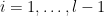

Proof: We induct on
We may factor 
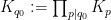


Observe that any given 

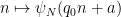

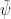
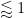

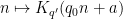
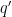
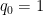


The claim is trivial (from the divisor bound) with 
By applying a similar reduction to before we may also assume that all prime factors of
We begin with the base case 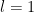

By completion of sums, it will suffice to show that

for all 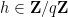

for all 
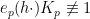
Now suppose that 

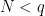

If we have 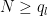

and the claim then follows by the induction hypothesis (concatenating 


Let 
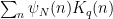
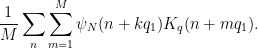
We factor
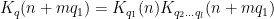
and by the divisor bound 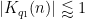
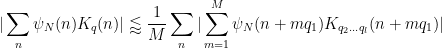
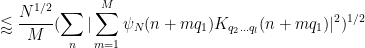
since the summand is only non-zero when 
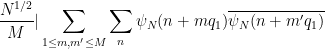
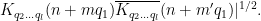
The diagonal contribution 



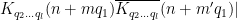
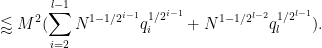
We observe that 
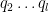


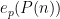
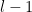


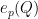





Applying the induction hypothesis, we may thus bound
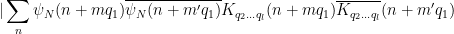
by
![\displaystyle \lessapprox (q_2 \ldots q_l, m-m') [ \sum_{i=2}^{l-1} N^{1-1/2^{i-1}} q_i^{1/2^{i-1}} + N^{1-1/2^{l-2}} q_l^{1/2^{l-1}} ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clessapprox+%28q_2+%5Cldots+q_l%2C+m-m%27%29+%5B+%5Csum_%7Bi%3D2%7D%5E%7Bl-1%7D+N%5E%7B1-1%2F2%5E%7Bi-1%7D%7D+q_i%5E%7B1%2F2%5E%7Bi-1%7D%7D+%2B+N%5E%7B1-1%2F2%5E%7Bl-2%7D%7D+q_l%5E%7B1%2F2%5E%7Bl-1%7D%7D+%5D+&bg=ffffff&fg=000000&s=0&c=20201002)

The contribution of the first two terms to (9) is acceptable thanks to Lemma 5 of this previous post, so the only contribution remaining to control is

We may bound

The first term is dominated by the 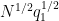
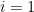

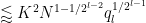
which is acceptable.
Remark 1 The above arguments relied on a
-process also becomes available (in principle, at least), thus potentially giving a slightly larger range of “exponent pairs”; however this looks complicated to implement (the role of polynomial phases now needs to be replaced by a more complicated class that involves things like the Fourier transforms of polynomial phases, as well as their “antiderivatives”) and will likely only produce rather small improvements in the final numerology.
We isolate a special case of the above result:
Corollary 12 Let the notation and assumptions be as in Proposition 11 with
,
and
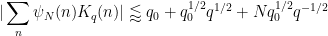

The dependence on
Proof: From the

giving the first claim of the proposition.
Similarly, from the

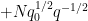
for any factorisation 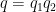
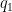
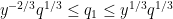
so that

and the second claim follows.
— 3. A two-dimensional exponential sum —
We now apply the above theory to obtain a new bound on a certain two-dimensional exponential sum that will show up in the Type I estimate.
Proposition 13 Let
be a
be of polynomial size, and let
. Let
be smooth sequences at scale
respectively. Then
Here the summations are implicitly restricted to those
for which the denominator in the phase is non-zero. We also have the bound


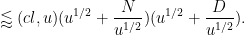
The main term here is 

Proof: We first claim that it suffices to verify the proposition when 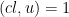


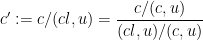
(where one computes the reciprocal of 
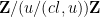
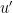
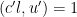


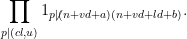
By the inclusion-exclusion formula and divisor bound, it thus suffices to show that for all 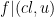
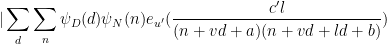
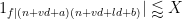
where 

or
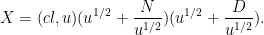
By the divisor bound, we see that there are 

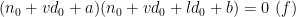

Making the change of variables 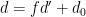


and

and one verifies that these two quantities bound the two possible values of 
Henceforth

and
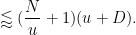
From completion of sums we have


so it will suffice to show that
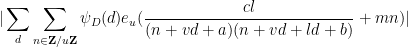

and

for any given 

where
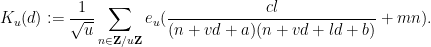
By the Chinese remainder theorem, this function factors as 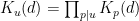

and 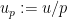




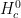


We claim that for any 
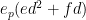

for some algebraic integer 

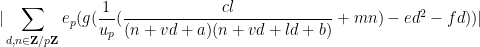
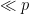
for all 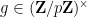
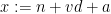


whenever 
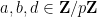
We now use a result of Hooley, which asserts that for any rational function 

provided that

is a geometrically generically irreducible curve (i.e. irreducible over an algebraic closure 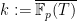

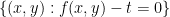
is a (possibly reducible or empty) curve for any 

For any 




is reducible in ![{k[x,y]}](https://s0.wp.com/latex.php?latex=%7Bk%5Bx%2Cy%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{{\Bbb F}_p[x,y,T] = {\Bbb F}_p[T][x,y]}](https://s0.wp.com/latex.php?latex=%7B%7B%5CBbb+F%7D_p%5Bx%2Cy%2CT%5D+%3D+%7B%5CBbb+F%7D_p%5BT%5D%5Bx%2Cy%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{{\Bbb F}_p[T]}](https://s0.wp.com/latex.php?latex=%7B%7B%5CBbb+F%7D_p%5BT%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{k_0[x,y]}](https://s0.wp.com/latex.php?latex=%7Bk_0%5Bx%2Cy%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
We now perform a technical reduction to deal with the problem that the field 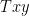
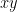
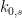
Assuming ![{k_{0,s}[x,y]}](https://s0.wp.com/latex.php?latex=%7Bk_%7B0%2Cs%7D%5Bx%2Cy%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{k_{0,s}[x]}](https://s0.wp.com/latex.php?latex=%7Bk_%7B0%2Cs%7D%5Bx%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{k_{0,s}[y]}](https://s0.wp.com/latex.php?latex=%7Bk_%7B0%2Cs%7D%5By%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{k_{0,s}(x)[y]}](https://s0.wp.com/latex.php?latex=%7Bk_%7B0%2Cs%7D%28x%29%5By%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{k_{0,s}(y)[x]}](https://s0.wp.com/latex.php?latex=%7Bk_%7B0%2Cs%7D%28y%29%5Bx%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


for some 



![{P \in k[x]}](https://s0.wp.com/latex.php?latex=%7BP+%5Cin+k%5Bx%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
— 4. Type I estimate —
We begin the proof of Theorem 4, closely following the arguments from Section 5 of this previous post or Section 2 of this previous post. One difference however will be that we will not discard the 

for some sufficiently slowly decaying 
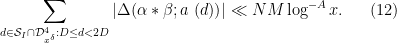
for any fixed 


be a sufficiently small fixed exponent.
By Lemma 11 of this previous post, we know that for all ![{[D,2D]}](https://s0.wp.com/latex.php?latex=%7B%5BD%2C2D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
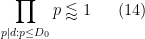
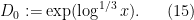
Specifically, the number of exceptions in the interval 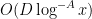
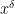

with 


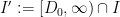
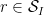

and
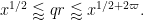
Here we use the easily verified fact that 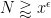
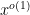
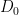
By dyadic decomposition, it thus suffices to show that

for any fixed 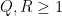


Fix 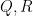

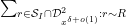

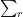

We now split the discrepancy
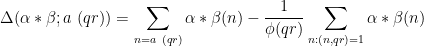
as the sum of the subdiscrepancies
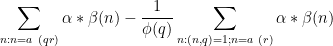
and

In Section 5 of this previous post, it was established (using the Bombieri-Vinogradov theorem) that


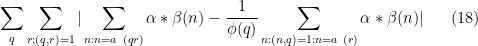

It will suffice to prove the slightly stronger statement


for all 
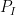
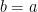

We use the dispersion method. We write the left-hand side of (19) as

for some bounded sequence 

so from the Cauchy-Schwarz inequality and crude estimates it suffices to show that
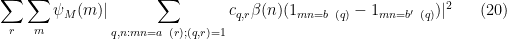

for any fixed 




where 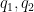
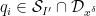



Observe that 


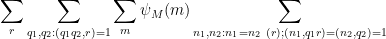

note that these inverses in the various rings 
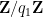

We may write 



for some 

At this stage in previous posts we isolated the coprime case 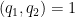

Applying completion of sums (Section 2 from this previous post), we can express the left-hand side of (22) as a main term

![\displaystyle c_{q_1,} \overline{c_{q_2,r}} \beta(n) \overline{\beta(n+kr)} (\sum_{m} \psi_M(m)) \frac{1}{r[q_1,q_2]} 1_{b/n = b'/(n+kr)\ ((q_1,q_2))}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++c_%7Bq_1%2C%7D+%5Coverline%7Bc_%7Bq_2%2Cr%7D%7D+%5Cbeta%28n%29+%5Coverline%7B%5Cbeta%28n%2Bkr%29%7D+%28%5Csum_%7Bm%7D+%5Cpsi_M%28m%29%29+%5Cfrac%7B1%7D%7Br%5Bq_1%2Cq_2%5D%7D+1_%7Bb%2Fn+%3D+b%27%2F%28n%2Bkr%29%5C+%28%28q_1%2Cq_2%29%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
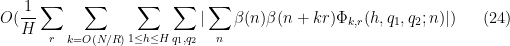
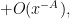

 is the phase
is the phase 
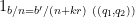
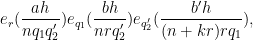
where 
Let us first deal with the main term (23). The contribution of the coprime case 

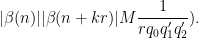
We may estimate 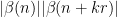
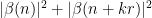


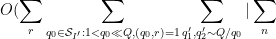

The 

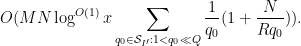
Since 

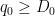

By (16) and (15), this is 
It remains to control (24). We may assume that 
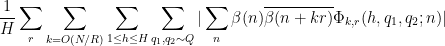

Using (25), it will suffice to show that
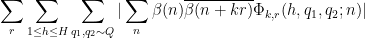
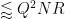
for each
We now work with a single 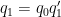
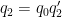
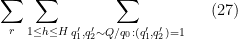


for each 
Henceforth we work with a single choice of

From (25) and (17), this follows from the assertion that

but this follows from (4), (5) if 

As 
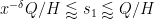
and thus
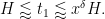
Factoring out 

and
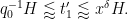
By dyadic decomposition, it thus suffices to show that

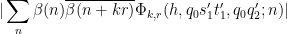
whenever 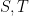
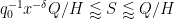
and

and
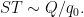
We rearrange this estimate as
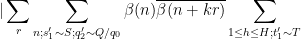

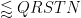
for some bounded sequence 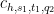

By Cauchy-Schwarz and crude estimates, it then suffices to show that

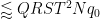
where
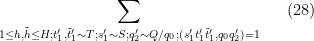

The contribution of the diagonal case 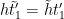



Note that 

![\displaystyle (h\tilde t'_1-\tilde h t'_1, q_0 s'_1 [t'_1, \tilde t'_1] q'_2) \lessapprox H^2 S T^2 Q / q_0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%28h%5Ctilde+t%27_1-%5Ctilde+h+t%27_1%2C+q_0+s%27_1+%5Bt%27_1%2C+%5Ctilde+t%27_1%5D+q%27_2%29+%5Clessapprox+H%5E2+S+T%5E2+Q+%2F+q_0.&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: Setting 
![\displaystyle \sum_{1 \leq h,\tilde h \leq H; t'_1,\tilde t'_1 \sim T: (t'_1\tilde t'_1,w)=1; h\tilde t'_1 \neq \tilde h t'_1} (h\tilde t'_1-\tilde h t'_1, [t'_1, \tilde t'_1] w) \lessapprox H^2 T^2](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csum_%7B1+%5Cleq+h%2C%5Ctilde+h+%5Cleq+H%3B+t%27_1%2C%5Ctilde+t%27_1+%5Csim+T%3A+%28t%27_1%5Ctilde+t%27_1%2Cw%29%3D1%3B+h%5Ctilde+t%27_1+%5Cneq+%5Ctilde+h+t%27_1%7D+%28h%5Ctilde+t%27_1-%5Ctilde+h+t%27_1%2C+%5Bt%27_1%2C+%5Ctilde+t%27_1%5D+w%29+%5Clessapprox+H%5E2+T%5E2&bg=ffffff&fg=000000&s=0&c=20201002)
for each fixed 
![\displaystyle (h\tilde t'_1-\tilde h t'_1, [t'_1, \tilde t'_1] w) \leq \sum_{d|w} \sum_{e: (d,e)=1} de 1_{de| h\tilde t'_1-\tilde h t'_1} 1_{e|[t'_1,\tilde t'_1]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%28h%5Ctilde+t%27_1-%5Ctilde+h+t%27_1%2C+%5Bt%27_1%2C+%5Ctilde+t%27_1%5D+w%29+%5Cleq+%5Csum_%7Bd%7Cw%7D+%5Csum_%7Be%3A+%28d%2Ce%29%3D1%7D+de+1_%7Bde%7C+h%5Ctilde+t%27_1-%5Ctilde+h+t%27_1%7D+1_%7Be%7C%5Bt%27_1%2C%5Ctilde+t%27_1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
it suffices to show that
![\displaystyle \sum_{1 \leq h,\tilde h \leq H; t'_1,\tilde t'_1 \sim T: (t'_1\tilde t'_1,w)=1; h\tilde t'_1 \neq \tilde h t'_1} 1_{de| h\tilde t'_1-\tilde h t'_1} 1_{e|[t'_1,\tilde t'_1]} \lessapprox \frac{H^2 T^2}{de^2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csum_%7B1+%5Cleq+h%2C%5Ctilde+h+%5Cleq+H%3B+t%27_1%2C%5Ctilde+t%27_1+%5Csim+T%3A+%28t%27_1%5Ctilde+t%27_1%2Cw%29%3D1%3B+h%5Ctilde+t%27_1+%5Cneq+%5Ctilde+h+t%27_1%7D+1_%7Bde%7C+h%5Ctilde+t%27_1-%5Ctilde+h+t%27_1%7D+1_%7Be%7C%5Bt%27_1%2C%5Ctilde+t%27_1%5D%7D+%5Clessapprox+%5Cfrac%7BH%5E2+T%5E2%7D%7Bde%5E2%7D&bg=ffffff&fg=000000&s=0&c=20201002)
for all coprime 
If 
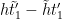
![{[t'_1,\tilde t'_1]}](https://s0.wp.com/latex.php?latex=%7B%5Bt%27_1%2C%5Ctilde+t%27_1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

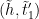

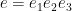
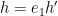


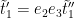
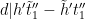

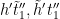


From this lemma, we see that for each fixed choice of 
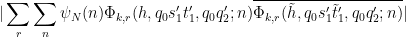
![\displaystyle \lessapprox H^{-2} q_0^2 RN (h\tilde t'_1-\tilde h t'_1, q_0 s'_1 [t'_1, \tilde t'_1] q'_2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clessapprox+H%5E%7B-2%7D+q_0%5E2+RN+%28h%5Ctilde+t%27_1-%5Ctilde+h+t%27_1%2C+q_0+s%27_1+%5Bt%27_1%2C+%5Ctilde+t%27_1%5D+q%27_2%29&bg=ffffff&fg=000000&s=0&c=20201002)
Thus far the arguments have been essentially identical to that in the previous post, except that we have retained the 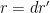

and

which are conditions which we will verify later. By dyadic decomposition, and the triangle inequality in



and all 

![\displaystyle u:= r'q_0 s'_1 [t'_1, \tilde t'_1] q'_2. \ \ \ \ \ (31)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++u%3A%3D+r%27q_0+s%27_1+%5Bt%27_1%2C+%5Ctilde+t%27_1%5D+q%27_2.+%5C+%5C+%5C+%5C+%5C+%2831%29&bg=ffffff&fg=000000&s=0&c=20201002)
Note that if the 


We write the above estimate as

where
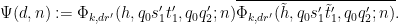
We now perform Weyl differencing. Set 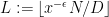


and so it suffices to show that

By Cauchy-Schwarz, it suffices to show that
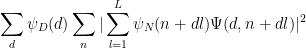
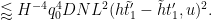
We restrict 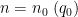



From (26) we see that the quantity 
![\displaystyle d r' q_0 s'_1 [t'_1,\tilde t'_1] q'_2](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++d+r%27+q_0+s%27_1+%5Bt%27_1%2C%5Ctilde+t%27_1%5D+q%27_2&bg=ffffff&fg=000000&s=0&c=20201002)
is square-free, and in that case it takes the form
![\displaystyle \Psi(d,n) = \alpha_{n_0,d_0} e_d(\frac{c_0}{n}) e_{r's'_1[t'_1,\tilde t'_1]}(\frac{c_1}{dn} ) e_{q'_2}( \frac{c_2}{d(n+kdr')} )](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CPsi%28d%2Cn%29+%3D+%5Calpha_%7Bn_0%2Cd_0%7D+e_d%28%5Cfrac%7Bc_0%7D%7Bn%7D%29+e_%7Br%27s%27_1%5Bt%27_1%2C%5Ctilde+t%27_1%5D%7D%28%5Cfrac%7Bc_1%7D%7Bdn%7D+%29+e_%7Bq%27_2%7D%28+%5Cfrac%7Bc_2%7D%7Bd%28n%2Bkdr%27%29%7D+%29+&bg=ffffff&fg=000000&s=0&c=20201002)
when restricted to 
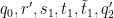
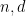
![\displaystyle (c_1,r's'_1[t'_1,\tilde t'_1]) = (h\tilde t'_1 - \tilde h t'_1,r's'_1[t'_1,\tilde t'_1])](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%28c_1%2Cr%27s%27_1%5Bt%27_1%2C%5Ctilde+t%27_1%5D%29+%3D+%28h%5Ctilde+t%27_1+-+%5Ctilde+h+t%27_1%2Cr%27s%27_1%5Bt%27_1%2C%5Ctilde+t%27_1%5D%29&bg=ffffff&fg=000000&s=0&c=20201002)
and

adopting the convention that 




![{v = 0\ (r's'_1[t'_1,\tilde t'_1])}](https://s0.wp.com/latex.php?latex=%7Bv+%3D+0%5C+%28r%27s%27_1%5Bt%27_1%2C%5Ctilde+t%27_1%5D%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{c_3:= c_1 q'_2 + c_2 r's'_1[t'_1,\tilde t'_1]}](https://s0.wp.com/latex.php?latex=%7Bc_3%3A%3D+c_1+q%27_2+%2B+c_2+r%27s%27_1%5Bt%27_1%2C%5Ctilde+t%27_1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
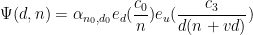
and note that

We thus have

and therefore
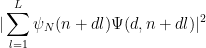
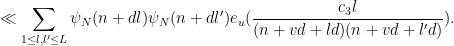
It thus suffices to show that
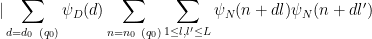
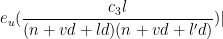

Shifting 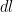




The contribution of the diagonal case 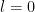
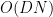
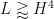



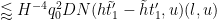
for each non-zero
Performing a Taylor expansion, we can write
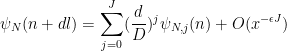
for any fixed 

Absorbing the 

for coefficient sequences 
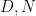



and

Using the former bound when 

![\displaystyle (c_3l,u) [ u^{1/2} ( 1 + (D/q_0)^{1/2} u^{1/6} x^{\delta/6} + \frac{D/q_0}{u^{1/2}}) + \frac{N/q_0}{u^{1/2}} (u^{1/2} + \frac{D/q_0}{u^{1/2}})].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%28c_3l%2Cu%29+%5B+u%5E%7B1%2F2%7D+%28+1+%2B+%28D%2Fq_0%29%5E%7B1%2F2%7D+u%5E%7B1%2F6%7D+x%5E%7B%5Cdelta%2F6%7D+%2B+%5Cfrac%7BD%2Fq_0%7D%7Bu%5E%7B1%2F2%7D%7D%29+%2B+%5Cfrac%7BN%2Fq_0%7D%7Bu%5E%7B1%2F2%7D%7D+%28u%5E%7B1%2F2%7D+%2B+%5Cfrac%7BD%2Fq_0%7D%7Bu%5E%7B1%2F2%7D%7D%29%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
Since

and

Since 
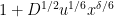
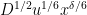

From (29) we already have 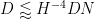



and conversely


Inserting these bounds and discarding the remaining powers of

and
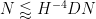
and

We rearrange these as



Applying the bounds on
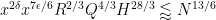
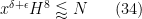

The third bound follows since 


The bound (35) is implied by (34) and may thus be dropped. We have

so the remaining three bounds may be rewritten as

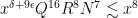
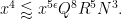
Since 
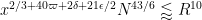


From (16) we have 
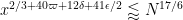

Since 


which we rearrange as

and the claim follows.

63 comments
Comments feed for this article
28 July, 2013 at 9:16 am
Terence Tao
While writing the above post, I got the strong sense that any further pushing of our current methods will become increasingly complicated, and lead to increasingly smaller returns; each new appication of Cauchy-Schwartz, in particular, can make the main term in an estimate somewhat better behaved, but at the cost of making a lot of error terms worse (and more numerous), and it becomes increasingly tricky to ensure that all these error terms remain dominated by the main term. When the time comes to start writing up the results of this project (which will probably begin fairly soon), we may have to consider a tradeoff between simplicity of exposition and the optimality of the results; would it be worth it, for instance, to add ten pages to the argument in order to reduce H by 10%?
One nice thing about the basic structure of Zhang’s argument, though, is that it is very modular; one can, for instance, swap in one Type I estimate for a fancier one and keep everything else unchanged. (For instance, as noted before, we can swap out the Type III estimates entirely, and revert to the previous Type I estimate, thus eliminating the need to use Deligne’s theorems.) So it should be relatively easy to designate one set of estimates as the “primary” version of the argument, and then remark on various ways to either strengthen the bounds (at the cost of increased complexity) or simplify the proof (at the cost of worse bounds).
28 July, 2013 at 11:04 am
Armin
What this project is aiming for is different so, perhaps it is asking too much, but it would be nice to see the simplest possible argument no matter the quality of the estimate. Did you make any progress in this sense compared to Zhang’s original proof?
28 July, 2013 at 11:07 am
andrescaicedo
I would think the best currently available bound should be included and proved in the paper.
That said, the write-up could take advantage of the modularity of the result, perhaps starting with the argument in https://terrytao.wordpress.com/2013/06/30/bounded-gaps-between-primes-polymath8-a-progress-report/#comment-236995 and then have later sections improve the estimates that came before, highlighting the needed adjustments in the argument. (This organic approach would also make clear how the results developed through the project, which some readers may find just as fascinating as the proofs themselves.)
This makes the paper longer, of course, and harder to write, but perhaps most useful, as readers could stop at the end of essentially any given section, and walk out with a complete proof, a decent estimate, and an idea of what details of the argument would admit further improving.
28 July, 2013 at 12:26 pm
Terence Tao
I like the idea of starting with the “minimal” proof needed to obtain a qualitative version of Zhang’s theorem (B[H] for some unspecified H) and then replacing things with fancier estimates later. Let me try to lay out what that “minimal” proof looks like.
1. First we need to show that![DHL[k_0,2]](https://s0.wp.com/latex.php?latex=DHL%5Bk_0%2C2%5D&bg=ffffff&fg=545454&s=0&c=20201002) for some
for some  implies
implies ![B[H]](https://s0.wp.com/latex.php?latex=B%5BH%5D&bg=ffffff&fg=545454&s=0&c=20201002) for some finite H. This is easy; we can just follow Zhang here and observe that for any
for some finite H. This is easy; we can just follow Zhang here and observe that for any  , the first
, the first  primes past
primes past  form an admissible
form an admissible  -tuple.
-tuple.
2. Then we need to show that![MPZ[\varpi,\delta]](https://s0.wp.com/latex.php?latex=MPZ%5B%5Cvarpi%2C%5Cdelta%5D&bg=ffffff&fg=545454&s=0&c=20201002) for some
for some  implies
implies ![DHL[k_0,2]](https://s0.wp.com/latex.php?latex=DHL%5Bk_0%2C2%5D&bg=ffffff&fg=545454&s=0&c=20201002) for some sufficiently large
for some sufficiently large  (we can initially work with the original formulation of MPZ involving smoothness, rather than the fancier versions involving dense divisibility). This is not too bad; the elementary Selberg sieve in https://terrytao.wordpress.com/2013/06/08/the-elementary-selberg-sieve-and-bounded-prime-gaps/ (using the “first-generation” weights
(we can initially work with the original formulation of MPZ involving smoothness, rather than the fancier versions involving dense divisibility). This is not too bad; the elementary Selberg sieve in https://terrytao.wordpress.com/2013/06/08/the-elementary-selberg-sieve-and-bounded-prime-gaps/ (using the “first-generation” weights  from the original Goldston-Pintz-Yildirim paper (or from Zhang’s paper) rather than the optimised Bessel weight) can do this after a certain lengthy amount of elementary number theory (no contour integration is required). (For the “minimal” proof we can set
from the original Goldston-Pintz-Yildirim paper (or from Zhang’s paper) rather than the optimised Bessel weight) can do this after a certain lengthy amount of elementary number theory (no contour integration is required). (For the “minimal” proof we can set 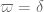 as Zhang does, although this does not actually lead to any significant simplifications in the argument.) Alternatively one could simply cite the paper of Motohashi-Pintz for this implication, although the implication is not completely explicit in that paper.
as Zhang does, although this does not actually lead to any significant simplifications in the argument.) Alternatively one could simply cite the paper of Motohashi-Pintz for this implication, although the implication is not completely explicit in that paper.
3. Then we need to show that![MPZ[\varpi,\delta]](https://s0.wp.com/latex.php?latex=MPZ%5B%5Cvarpi%2C%5Cdelta%5D&bg=ffffff&fg=545454&s=0&c=20201002) follows from Type I, Type II, and Type III estimates. Actually it turns out that we can do everything using a sufficiently good Type I/II estimate (one which can allow
follows from Type I, Type II, and Type III estimates. Actually it turns out that we can do everything using a sufficiently good Type I/II estimate (one which can allow  to be as large as 1/6), removing the need for Type III estimates. In this case, we can also use Vaughan’s identity rather than the Heath-Brown identity, which is not a major simplification but may be a bit more familiar to some readers (and allows one to avoid the combinatorial lemma on subset sums, although this lemma is rather easy). One still needs to use some sort of dyadic decomposition here (actually for technical reasons we use a finer-than-dyadic decomposition), but this is rather easy and standard.
to be as large as 1/6), removing the need for Type III estimates. In this case, we can also use Vaughan’s identity rather than the Heath-Brown identity, which is not a major simplification but may be a bit more familiar to some readers (and allows one to avoid the combinatorial lemma on subset sums, although this lemma is rather easy). One still needs to use some sort of dyadic decomposition here (actually for technical reasons we use a finer-than-dyadic decomposition), but this is rather easy and standard.
4. To prove a type I/II estimate, it turns out that the Type II argument can be used to cover both cases. (The Type I and Type II arguments are very similar, except at one stage where Cauchy-Schwarz is applied slightly differently in the two cases.) The ingredients needed here are
4.1. The Bombieri-Vinogradov theorem (which in turn is proven using the large sieve inequality, a Fourier decomposition into Dirichlet characters, and the Siegel-Walfisz theorem). This is a little lengthy, but completely standard, and we can cite for instance this paper of Bombieri-Friedlander-Iwaniec for the precise version of Bombieri-Vinogradov that we need.
4.2. The observation that most large numbers do not have an enormous number of small prime factors (less than
do not have an enormous number of small prime factors (less than 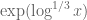 ); this is elementary but a little technical.
); this is elementary but a little technical.
4.3 A moderately complicated but elementary sequence of Cauchy-Schwarz and completion-of-sums type manipulations (based on the dispersion method), together with some standard bounds on mean values of divisor functions etc. (We have a minor simplification here over the textbook use of the dispersion method as used by Zhang and others, in that instead of having to estimate three different sums , one only needs to control an
, one only needs to control an  type sum, although this is not a major simplification since
type sum, although this is not a major simplification since  is the hardest of the three sums to control anyway. There is also a technical tradeoff: early versions of the Type I/II estimates (including Zhang’s) required a certain “controlled multiplicity” hypothesis on the congruence classes involved (in order to reduce to the case when two moduli
is the hardest of the three sums to control anyway. There is also a technical tradeoff: early versions of the Type I/II estimates (including Zhang’s) required a certain “controlled multiplicity” hypothesis on the congruence classes involved (in order to reduce to the case when two moduli  are coprime); we’ve now removed this hypothesis, but at the (minor) cost of having to carry around an additional parameter
are coprime); we’ve now removed this hypothesis, but at the (minor) cost of having to carry around an additional parameter 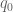 in the analysis (measuring the gcd of
in the analysis (measuring the gcd of  ). I’m not sure at this point which of these methods would be better for the “minimal” proof.
). I’m not sure at this point which of these methods would be better for the “minimal” proof.
4.4 A van der Corput estimate that gives a power saving for sums such as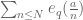 for
for  a small power of the smooth modulus
a small power of the smooth modulus  (I think with
(I think with  and using the Type II argument, we need a power saving with
and using the Type II argument, we need a power saving with  as small as
as small as 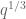 , which can be achieved using a double van der Corput + the Weil conjectures for curves. By splitting into Type I and Type II I think we only need a power saving for
, which can be achieved using a double van der Corput + the Weil conjectures for curves. By splitting into Type I and Type II I think we only need a power saving for  as small as
as small as  , which requires only one van der Corput + Weil conjectures for curves. (One can do a little better than this by splitting up the moduli more optimally, which is what one does for the most advanced Type I estimates, but perhaps we can avoid this for the “minimal” argument.)
, which requires only one van der Corput + Weil conjectures for curves. (One can do a little better than this by splitting up the moduli more optimally, which is what one does for the most advanced Type I estimates, but perhaps we can avoid this for the “minimal” argument.)
The van der Corput estimate is proven by an elementary application of Cauchy-Schwarz (following an old paper of Graham and Ringrose), together with the Weil conjectures for curves which in particular gives square root cancellation for sums of the form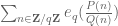 . This bound can simply be cited in the literature, but actually for the purposes of getting a qualitative result, we don’t need square root cancellation; any power saving should suffice. I had claimed earlier that an elementary argument of Kloosterman gives a non-trivial power saving for any exponential sum
. This bound can simply be cited in the literature, but actually for the purposes of getting a qualitative result, we don’t need square root cancellation; any power saving should suffice. I had claimed earlier that an elementary argument of Kloosterman gives a non-trivial power saving for any exponential sum 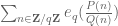 with
with non-constant, but actually, now that I look at it more carefully, I only see how to make Kloosterman’s argument work with the Kloosterman sum
non-constant, but actually, now that I look at it more carefully, I only see how to make Kloosterman’s argument work with the Kloosterman sum 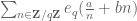 as it exploits a certain dilation symmetry in this sum which is not present in the general case. But presumably an elementary argument should be available (which would not need the Weil conjectures for curves; this can be proven using the elementary method of Stepanov, but even this requires the Riemann-Roch theorem and so is not completely elementary.)
as it exploits a certain dilation symmetry in this sum which is not present in the general case. But presumably an elementary argument should be available (which would not need the Weil conjectures for curves; this can be proven using the elementary method of Stepanov, but even this requires the Riemann-Roch theorem and so is not completely elementary.)
28 July, 2013 at 12:50 pm
Armin
One of the most inspiring aspects of this project was that it has brought to light so many different corners of various fields and linked them in such a beautiful way. Since you already have a number of experts involved in this project, why waste an opportunity to write a completely self-contained textbook? Each person will probably write a chapter or two. This would better serve future generations of mathematicians than a technical paper improving upon Zhang’s result. Right now you have to be a student of one of these experts to learn this material properly, but you have a chance to change this.
29 July, 2013 at 6:40 am
Gergely Harcos
I think the aim of this project would be best fulfilled by a research paper containing the optimal result. The extra 10 pages would be amply justified by the 10% reduction in . On the other hand, it would also be very useful to compile a set of lecture notes (for lecturing purposes) which are self-contained, avoid Deligne’s theorem, and yield a reasonably small
. On the other hand, it would also be very useful to compile a set of lecture notes (for lecturing purposes) which are self-contained, avoid Deligne’s theorem, and yield a reasonably small  . Finally, these lecture notes could be expanded into a textbook in the farther future.
. Finally, these lecture notes could be expanded into a textbook in the farther future.
29 July, 2013 at 7:17 am
Armin
The optimal result is H=2, and readers of this research paper are probably the same experts who already understand the arguments well enough following developments on this blog. The only real purpose of writing a technical paper is to create a template for the future book, and test run the collaborative process. For that reason, I certainly hope that Terry Tao will not be the one writing 95% of the paper. However, I am only an observer and I wish all the best for everyone involved in this project, regardless of the final product.
29 July, 2013 at 9:57 am
Gergely Harcos
I disagree that the optimal result is , perhaps the twin prime conjecture is false! By optimal result I meant the smallest
, perhaps the twin prime conjecture is false! By optimal result I meant the smallest  that the project was able to achieve. I also disagree that “The only real purpose of writing a technical paper is to create a template for the future book, and test run the collaborative process”. The aim of this project was to produce an
that the project was able to achieve. I also disagree that “The only real purpose of writing a technical paper is to create a template for the future book, and test run the collaborative process”. The aim of this project was to produce an  that is as small as possible, and in my opinion the purpose of writing the paper is to publish the result and have it checked by referees as any other theorem in mathematics. Not all the experts followed the developments on this blog, and in fact some future experts are not even born yet! Publishing a weaker result with a simpler proof, or writing a textbook should be regarded as a secondary goal or outcome of the project.
that is as small as possible, and in my opinion the purpose of writing the paper is to publish the result and have it checked by referees as any other theorem in mathematics. Not all the experts followed the developments on this blog, and in fact some future experts are not even born yet! Publishing a weaker result with a simpler proof, or writing a textbook should be regarded as a secondary goal or outcome of the project.
29 July, 2013 at 10:34 am
Armin
Those unborn experts is my deepest concern. Without commitment, I fear that after the initial excitement you will take the easy way out and abandon them after 20 pages of technical summary, and will not bear the project to its full term.
29 July, 2013 at 10:55 am
Gergely Harcos
I am not following you. By unborn experts I meant that a paper is written not only for the present, but also for the future. So it is necessary to produce a decent paper that will be stored in hundreds of libraries and websites (not only on this blog) just as any other scientific paper. On the other hand, the full proof is already written up in detail on this blog, so producing the paper really means to compile the material without the twists and turns that are characteristic in the research process (and nicely reflected on this blog), and of course adding the usual introduction to put the results into context. The final paper will contain a full proof of the stated result, just as any other research paper in mathematics.
29 July, 2013 at 12:41 pm
Mark Bennet
There seem to me to be three possible outcomes, which maybe merit two papers. The first is as elementary a proof as is currently possible of a finite prime gap which occurs infinitely often. The second is the absolute best we can do to prove a minimal prime gap with the techniques currently to hand. The third, which gives a route-map fpr the future, is a record of what has been tried and hasn’t worked, and some intelligent commentary on where new ideas may be needed. ie “if you do better than us with these ideas you might get to … & if you want to do better than that you need an idea we haven’t thought of yet.”
I think the intensity of this project conceals how rare it has been for these three questions to be open and viable in the timescale achieved here.
29 July, 2013 at 3:05 pm
Terence Tao
I think that, thanks to the modular structure of the argument, it should be possible to at least partially achieve the first and third of these objectives in a paper ostensibly focused on the second objective, since we can easily present multiple versions (including some conjectural ones that we can’t actually achieve yet) of each modular component of the argument.
It’s also not necessary for everything to go into a traditionally published paper; we can have a traditional refereed paper containing the best results we can currently establish, together with some additional blog posts, e.g. one post for the simplest possible proof and another for speculative improvements.
As for lecture notes and textbooks, my feeling here is that it is best to wait until the subject matures more. There will be more developments and followups to Zhang’s paper than the current polymath project (indeed, there have already been several other research papers that have built upon Zhang’s result outside of the polymath8 project) and it may take some time to get the proper perspective to digest all these results. (And actually it may be best for someone who is not as directly involved with the research to write a proper summary, cf. for instance Soundararajan’s Bull. AMS survey of the previous Goldston-Pintz-Yildirim breakthrough on prime gaps.)
29 July, 2013 at 3:00 am
James Hilferty
Dear Terry is there any truth in the rummer that you are a “pure mathematician” and not a practical one. I was having a discussion with my niece’s husband about the usefulness of the Gaussian Normal Distribution Curve (he is a professor of mathematics) and I think that I ran rings around and then he suggested without even a blush, that it was only a Hypothesis; and about the Central Limit Theory (which I believe in) and then that you are a Pure (not practical) mathematician; and I asked the obvious question “what’s the point of maths if it doesn’t work?
29 July, 2013 at 12:12 pm
Eytan Paldi
Perhaps (for the next improvement) it is better to reduce the lower bound on than improving type I estimate in theorem 4?
than improving type I estimate in theorem 4?
30 July, 2013 at 6:27 am
Aubrey de Grey
That doesn’t seem to be the situation at this point, as I understand it. Not only is there an apparently very robust obstacle to reducing the lower bound on sigma (in the form of an inability to handle efficiently what are being termed Type V sums), but also there is not all that much out there in terms of avenues for improving the Type III estimate, which would be needed in order to get more than a rather small increase in varpi (to around 1/82 from the current 1/85) even if sigma were reduced. Conversely, a really big breakthrough for Type I could potentially allow a large varpi even with sigma up at the 1/6 boundary that obviates Type III entirely; this avenue becomes even more attractive when one bears in mind that there is currently a whole cluster of promising-looking options for improving the current Type II bound of varpi=1/68, which is independent of sigma.
Whether there is actually any real chance of significantly improving the Type I estimate is a different matter, of course, as Terry has noted above. Also, it might turn out that the Type III estimate can be greatly improved after all, in which case the rationale for hacking at the lower bound on sigma would correspondingly increase. Maybe this means it’s worth briefly exploring Type III again now, even though it’s currently irrelevant, just to get a feel for whether the bulk of future effort would be best focused on Type I or on sigma?
29 July, 2013 at 10:54 pm
Stephan Goldammer (@StephGoldammer)
Math is easy.
30 July, 2013 at 6:48 am
Kamran Alam Khan
Reblogged this on Observer.
30 July, 2013 at 7:54 pm
Terence Tao
I’ve been asked a few times what the best value of H we can get without Deligne’s theory (relying just on the Weil conjectures), so I am recording the numerology here.
Without Deligne’s theorems, we lose the Type III estimates and so need to be at least
to be at least  (rather than
(rather than  ). Also, the most advanced Type I estimate (the “Level 5” one given in this blog post) also relies on Deligne’s theory, and so we must fall back to the previous Type I estimate (confusingly numbered “Level 6”) from this previous post, which holds (for doubly densely divisible moduli) for
). Also, the most advanced Type I estimate (the “Level 5” one given in this blog post) also relies on Deligne’s theory, and so we must fall back to the previous Type I estimate (confusingly numbered “Level 6”) from this previous post, which holds (for doubly densely divisible moduli) for 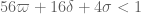 , which when
, which when  becomes
becomes  . There are also the Type II sums, but these hold for
. There are also the Type II sums, but these hold for 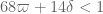 without Deligne’s theorems and so are not dominant.
without Deligne’s theorems and so are not dominant.
So one has to optimise subject to
subject to  , using the doubly densely divisible value for
, using the doubly densely divisible value for  , namely
, namely
(note that in previous posts the erroneous value of was used instead). Setting
was used instead). Setting  ,
, 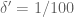 ,
, 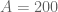 I can reach
I can reach  (and hence, by the prime tuples website,
(and hence, by the prime tuples website,  ); this can probably be optimised a little more. So currently Deligne’s theorems are giving a factor of three improvement or so. :)
); this can probably be optimised a little more. So currently Deligne’s theorems are giving a factor of three improvement or so. :)
31 July, 2013 at 3:53 am
Aubrey de Grey
Thank you! Out of interest: is it still the case that, at the cost of a further numerical hit from iterating vdC, one can also avoid the Weil conjectures, as you intimated a few weeks ago (replacing q^{1/2} by q^{3/4} ), or is that possibility precluded at this point by your concluding paragraph in the sketch of the minimal proof a few days ago? If it’s not precluded, can one yet say what minimal H would currently result in that case?
31 July, 2013 at 8:03 am
Terence Tao
I asked a question on MathOverflow about this last point (at http://mathoverflow.net/questions/138193/is-there-a-cheap-proof-of-power-savings-for-exponential-sums-over-finite-fields ) but there is still no definitive answer on that point yet. If we do somehow get a cheap bound of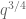 for rational exponential sums (a typical thing we would need is a bound on
for rational exponential sums (a typical thing we would need is a bound on  for non-zero
for non-zero  ), this wouldn’t increase the number of van der Corput’s needed, but it would roughly speaking halve the value of
), this wouldn’t increase the number of van der Corput’s needed, but it would roughly speaking halve the value of  obtained as a result. (Basically, after all the Cauchy-Schwarz, one has to gain something like
obtained as a result. (Basically, after all the Cauchy-Schwarz, one has to gain something like 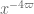 or
or  in the exponential sum over the trivial bound; Weil lets you save
in the exponential sum over the trivial bound; Weil lets you save 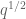 , but Kloosterman only saves
, but Kloosterman only saves  .) Halving
.) Halving  roughly corresponds to multiplying
roughly corresponds to multiplying  by
by 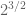 , and
, and  would increase by a little more than that, so we’d be looking at
would increase by a little more than that, so we’d be looking at  in the 50K range or so.
in the 50K range or so.
30 July, 2013 at 11:23 pm
Emmanuel Kowalski
I think example 4 (“trace weights”) might not, literally, work with your definition of structured class. The issue is the distinction between geometrically irreducible and arithmetically irreducible sheaves (in my papers with Fouvry and Michel, this explains why we work with geometrically isotypic sheaves instead of irreducible ones).
But this is relatively technical, and I am sure that there is no problem with the specific weights used for bounded gaps…
31 July, 2013 at 8:17 am
Terence Tao
Hmm, this is a subtlety that I did not previously appreciate, and it may complicate the axiomatisation I was hoping to use (in order not to have to deal with specific sheaves). Specifically, if one works with geometric isotypic sheaves only, then one loses the normalisation axiom; the (square of the ) L^2 norm of a trace weight is no longer , but instead
, but instead  for some algebraic integer
for some algebraic integer  (I think one can’t assume it to be a natural number, though I would like it if we could somehow prevent
(I think one can’t assume it to be a natural number, though I would like it if we could somehow prevent  from getting too small). As such, if two trace weights correlate, then they do not necessarily agree up to a phase, but instead could agree up to a more general algebraic number. In the specific application to the q-van der Corput process we are correlating trace weights which are translates of each other, so we probably can recover the phase property (at least if we have this lower bound on
from getting too small). As such, if two trace weights correlate, then they do not necessarily agree up to a phase, but instead could agree up to a more general algebraic number. In the specific application to the q-van der Corput process we are correlating trace weights which are translates of each other, so we probably can recover the phase property (at least if we have this lower bound on  ).
).
I’ll have to think about how to fix this in a non-messy fashion…
[ADDED LATER: I think I can recover most of what is needed if one works over all embeddings of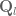 into
into 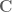 rather than just a fixed embedding, so that one never just works with a single algebraic integer, but all Galois conjugates of that integer (since at least one of them is guaranteed to be of magnitude at least one. Still working out the details…]
rather than just a fixed embedding, so that one never just works with a single algebraic integer, but all Galois conjugates of that integer (since at least one of them is guaranteed to be of magnitude at least one. Still working out the details…]
31 July, 2013 at 9:52 am
Terence Tao
OK, I think I repaired the problem. Trace weights are now defined using geometrically isotypic sheaves instead of geometrically irreducible ones; also for technical reasons I have to exclude the zero function 0 from this class. I claim that the almost orthogonality relation (in the regime when is large compared to all the conductors) now takes the form
is large compared to all the conductors) now takes the form 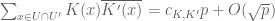 , where
, where 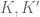 are trace weights of bounded conductor defined on
are trace weights of bounded conductor defined on  respectively, and
respectively, and  is an algebraic integer (of potentially unbounded height and perhaps very close to zero in the Archimedean sense, e.g.
is an algebraic integer (of potentially unbounded height and perhaps very close to zero in the Archimedean sense, e.g.  ), which is non-vanishing if and only if the geometrically irreducible representations associated to
), which is non-vanishing if and only if the geometrically irreducible representations associated to 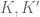 are isomorphic. (It is to get the “if” direction – which allows one to detect non-isomorphism through correlation – that I need to exclude 0 as a trace weight.) Furthermore, all Galois conjugates of the
are isomorphic. (It is to get the “if” direction – which allows one to detect non-isomorphism through correlation – that I need to exclude 0 as a trace weight.) Furthermore, all Galois conjugates of the  error remain of size
error remain of size  . In particular, I claim that if all Galois conjugates of
. In particular, I claim that if all Galois conjugates of 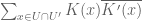 are
are 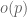 , then
, then 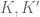 do not have common geometrically irreducible components. This allows us to demonstrate that the sheaves we need do not contain quadratic phase components, by reducing matters to bounding (all Galois conjugates of) a two-dimensional exponential sum which we can do by Hooley’s argument.
do not have common geometrically irreducible components. This allows us to demonstrate that the sheaves we need do not contain quadratic phase components, by reducing matters to bounding (all Galois conjugates of) a two-dimensional exponential sum which we can do by Hooley’s argument.
31 July, 2013 at 12:03 pm
Terence Tao
A slight correction: there is a complication due to the fact that even if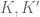 are non-zero and come from geometrically isotypic sheaves
are non-zero and come from geometrically isotypic sheaves  with isomorphic geometric components, it is possible for the trace of Frobenius to cancel out to zero on the geometrically trivial component of
with isomorphic geometric components, it is possible for the trace of Frobenius to cancel out to zero on the geometrically trivial component of  , so one cannot quite use the correlation
, so one cannot quite use the correlation 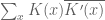 to detect isomorphism of the geometric components in general. However, I don’t think this can occur when one of the sheaves is rank one, which is the case we care about (specifically, one of the sheaves will be the pullback of an Artin-Schreier sheaf by a polynomial).
to detect isomorphism of the geometric components in general. However, I don’t think this can occur when one of the sheaves is rank one, which is the case we care about (specifically, one of the sheaves will be the pullback of an Artin-Schreier sheaf by a polynomial).
1 August, 2013 at 3:37 am
Philippe Michel
In addition to what Emmanuel said, in order to insure that there no “accidental cancellation” one can compute the sum over all extension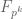 (say) of
(say) of 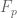 (which is possible here of course) the reason being that if
(which is possible here of course) the reason being that if  are complex numbers of modulus one,
are complex numbers of modulus one, 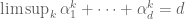 .
.
31 July, 2013 at 10:17 pm
Emmanuel Kowalski
The way we (i.e., FKM) handle this is to work with representatives of arithmetically irreducible, geometrically isotypic, weight 0 (middle extension) sheaves on P^1/F_p modulo geometric isomorphism.
Functions in such a set strongly quasi-orthogonal; when K=K’, the L^2 norm is about n^2, where n is the number of copies of the geometrically irreducible component of the sheaf.
They suffice to describe, e.g., general products, because the only missing (weight 0, etc) arithmetically irreducible sheaves are induced from P^1/F_q for some finite extension F_q/F_p, and the trace function of such an induced sheaf is zero.
(See, e.g., our paper on inverse theorems for Gowers norms of trace functions
Click to access gowers-prime-fields.pdf
to appear in Math. Proc. Cambridge Phil. Soc., especially section 5.)
I am not sure how good an axiomatiization one can really hope for (to my mind, this is somewhat similar to issues with the Selberg class compared with automorphic forms). For instance, one might want to add stabilitiy under the Fourier transform, and this adds further complexity; convolution (especially multiplicative convolution) is even trickier.
1 August, 2013 at 9:10 am
Terence Tao
Thanks for this! Yes, I have found Section 5 of your Gowers norm paper to be very helpful, thanks.
My motivation in trying to axiomatise things is not so much to try to get a complete axiomatisation of the trace weight functions (which is probably hopeless at this time, as you point out), but rather to try to “black box” all the information about trace weights that are needed for the application to bounded gaps between primes, for the benefit of readers who are not familiar with the trace weight formalism. I’ve tried to incorporate everything we actually use about trace weights into Definition 9 of this blog post; there is one additional thing we need beyond this, which is that functions of the form are sums of a bounded number of isotypic trace weights, where
are sums of a bounded number of isotypic trace weights, where  is a rational function of bounded degree such that
is a rational function of bounded degree such that 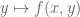 is not constant for any
is not constant for any  . (I think this follows from Deligne’s theorem and the Grothendieck-Lefschetz formula if one interprets the middle cohomology associated to the exponential sum
. (I think this follows from Deligne’s theorem and the Grothendieck-Lefschetz formula if one interprets the middle cohomology associated to the exponential sum  itself as a sheaf.)
itself as a sheaf.)
For working over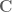 , I can see that picking one representative modulo geometric isomorphism of each isotypic trace weight works well as one gets the nice quasi-orthogonality property over
, I can see that picking one representative modulo geometric isomorphism of each isotypic trace weight works well as one gets the nice quasi-orthogonality property over 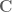 as a consequence. But I think I have to keep all coefficients algebraic integers in order to avoid cancellation issues (though, as Philippe points out, one could escape this by working with the companion sums instead, but this is much harder to “black box”, and would look quite a circuitous way to estimate an exponential sum over
as a consequence. But I think I have to keep all coefficients algebraic integers in order to avoid cancellation issues (though, as Philippe points out, one could escape this by working with the companion sums instead, but this is much harder to “black box”, and would look quite a circuitous way to estimate an exponential sum over 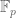 to readers not familiar with how the Weil conjectures are proven and used). Specifically, I need to show that the above trace weight
to readers not familiar with how the Weil conjectures are proven and used). Specifically, I need to show that the above trace weight  is associated to a sheaf does not contain any component that is the pullback of an Artin-Schreier sheaf by a quadratic polynomial. By decomposing
is associated to a sheaf does not contain any component that is the pullback of an Artin-Schreier sheaf by a quadratic polynomial. By decomposing  into components (but not working with a fixed representative in each geometric isomorphism class), I think I can show that the only way the above assertion fails is if there is a quadratic phase whose inner product with
into components (but not working with a fixed representative in each geometric isomorphism class), I think I can show that the only way the above assertion fails is if there is a quadratic phase whose inner product with  is of the form
is of the form 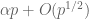 for some non-zero algebraic integer
for some non-zero algebraic integer  , where all Galois conjugates of the error term
, where all Galois conjugates of the error term  are also
are also  . Now this algebraic integer may be very small in the Archimedean sense (due to “unwanted cancellation”), but at least one Galois conjugate of it will be large, so one can win as long as one can show that all Galois conjugates of the inner product of
. Now this algebraic integer may be very small in the Archimedean sense (due to “unwanted cancellation”), but at least one Galois conjugate of it will be large, so one can win as long as one can show that all Galois conjugates of the inner product of  with a quadratic phase are
with a quadratic phase are  , which one can do using Hooley’s results on two-dimensional exponential sums. But this argument relies heavily on the coefficients remaining algebraic integers (though it would also work to have algebraic numbers whose denominator has bounded height, which sounds like is what would happen if one worked with your quasi-orthogonal basis).
, which one can do using Hooley’s results on two-dimensional exponential sums. But this argument relies heavily on the coefficients remaining algebraic integers (though it would also work to have algebraic numbers whose denominator has bounded height, which sounds like is what would happen if one worked with your quasi-orthogonal basis).
ADDED LATER: Actually, I can’t remember now why I thought I could ensure that the structure constant here was an algebraic integer, which means that my arguments above could fall apart (and then one would have to use Philippe’s suggestion of working with the companion sums instead). Have to run now, but will think about this…
here was an algebraic integer, which means that my arguments above could fall apart (and then one would have to use Philippe’s suggestion of working with the companion sums instead). Have to run now, but will think about this…
[Note: I had taken down this comment for editing, and only restored it after Emmanuel’s response below, which is why the timestamps are out of order. -T.]
1 August, 2013 at 8:33 am
Emmanuel Kowalski
I am certain that the “summing over y” construction does indeed give a trace function (of some weight 0 sheaf that may not be a middle extension, but can be adjusted to be so by changing few values), by the existence of higher direct images with compact support. The only issue is to control the conductor of the resulting sheaf, and this doesn’t seem obvious. Since one sums an exponential (instead of considering a more general operator with kernel k(x,y) which is a trace function in two variables), one can use the “classical” bounds for Betti numbers of Bombieri (and later Katz) to control the rank, and probably the number of ramification points is also fairly accessible. On the other hand, I don’t think I know how to handle the Swan conductors in this generality.
I am also pretty confident that the c_{K,K’} are known to algebraic integers, provided the local traces of the two sheaves involved are themselves algebraic integers (this local condition must be checked, like weight 0-type conditions, at all points of the underlying scheme, not just the F_p-points): this is a result of Deligne in SGA 7, Appendix to exposé XXI.
For problems like excluding certain types of summands, algebro-geometric arguments can often be made to work that parallel more intuitive (in some sense…) analytic arguments — an excellent example of a similar type is in Katz’s paper “Four lectures on Weil 2” (see https://web.math.princeton.edu/~nmk/arizona34.pdf, especially the interlude of Lecture IV and the following section). Our Gowers norms paper had similar features in early drafts where we tried to make the induction work using directly quasi-orthogonality instead of the current argument. One thing that algebraic arguments can exploit is that they don’t care about the conductor — orthogonality can be used at the level of Schur’s Lemma.
(But of course there are certainly cases where it is indeed easier or better to use Galois conjugation…)
1 August, 2013 at 11:39 am
Terence Tao
Hmm, based on what you say I think now that I am not going to get algebraic integer roots for the normalised exponential sum after all, but rather algebraic integers divided by
after all, but rather algebraic integers divided by  , which makes the Galois theory approach useless.
, which makes the Galois theory approach useless.
Here’s the specific claim I need. Let be a rational function of bounded degree over
be a rational function of bounded degree over 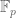 which obeys Hooley’s non-degeneracy conditions, namely that
which obeys Hooley’s non-degeneracy conditions, namely that 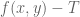 is generically geometrically irreducible, and for any given
is generically geometrically irreducible, and for any given  ,
, 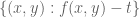 is a curve. We also assume that for any
is a curve. We also assume that for any  , the function
, the function 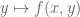 is non-constant. Then I need the function
is non-constant. Then I need the function  to be expressible (after tweaking by an error of
to be expressible (after tweaking by an error of  ) as a pure middle extension trace weight of bounded conductor whose sheaf contains no geometrically trivial component. (I think I also need the sheaf to be arithmetically semisimple, but I understand that one can reduce to this case automatically?)
) as a pure middle extension trace weight of bounded conductor whose sheaf contains no geometrically trivial component. (I think I also need the sheaf to be arithmetically semisimple, but I understand that one can reduce to this case automatically?)
For our specific application we have an explicit form of the rational function, but presumably this will not be too helpful (although it does allow one to verify Hooley’s criteria by ad hoc means).
of the rational function, but presumably this will not be too helpful (although it does allow one to verify Hooley’s criteria by ad hoc means).
Using Michel’s method of proceeding via the companion sums I think I can at least get the “no geometrically trivial” part of this claim, but not the boudned conductor claim. Namely,
If we set
then I think Hooley’s argument shows that the sum
takes the form
for some bounded number of complex numbers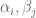 of modulus at most
of modulus at most 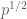 (these weights are also algebraic integers divided by
(these weights are also algebraic integers divided by 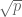 , but this does not seem to be exploitable information). Presumably the pushforward (or direct image) construction ensures that the
, but this does not seem to be exploitable information). Presumably the pushforward (or direct image) construction ensures that the 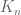 are the companion sums for the sheaf associated to
are the companion sums for the sheaf associated to  (possibly up to a sign correction
(possibly up to a sign correction  ), which would then imply that these
), which would then imply that these 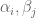 must then be the weights for that sheaf after allowing for cancellation. In particular, the H^2 of this sheaf cannot contain any weights of magnitude
must then be the weights for that sheaf after allowing for cancellation. In particular, the H^2 of this sheaf cannot contain any weights of magnitude  , as these cannot be canceled out by the
, as these cannot be canceled out by the 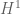 weights, so this should imply that the sheaf has no geometrically trivial component. This argument almost controls the dimension of
weights, so this should imply that the sheaf has no geometrically trivial component. This argument almost controls the dimension of 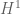 as well, except that there could potentially be
as well, except that there could potentially be 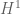 weights of magnitude 1 rather than
weights of magnitude 1 rather than 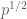 that get cancelled by the
that get cancelled by the  weights (or are we in a situation where we can assume that the weights in
weights (or are we in a situation where we can assume that the weights in  have magnitude exactly
have magnitude exactly 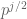 rather than being bounded above by
rather than being bounded above by 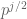 ? I am a little confused as to which weights we can assume to be pure instead of mixed in this business.)
? I am a little confused as to which weights we can assume to be pure instead of mixed in this business.)
As you say, this is a fairly roundabout way to do things – presumably there is a geometric way to deduce vanishing of the H^2 of the pushforward sheaf in terms of vanishing of the H^3 of the original two-dimensional sheaf, which in turn should be deducible from geometric methods rather than by Hooley’s analytic argument. (This still doesn’t help with the problem of controlling the Swan conductor though.)
2 August, 2013 at 2:23 pm
Terence Tao
It occurs to me that one possible way to get a “soft” bound for the Swan conductor that is uniform in p is to take an ultraproduct in p and work with l-adic sheaves over a pseudo-finite field rather than a finite field, as is discussed in https://terrytao.wordpress.com/2010/01/30/the-ultralimit-argument-and-quantitative-algebraic-geometry/ . The key technical thing to check is that Swan conductors are continuous with respect to ultraproducts, and also that the pushforward (or direct image) operation on sheaves commutes with ultraproducts. This would require a certain amount of delving into the finer points of sheaf cohomology, but this might possibly be worthwhile for other applications than bounded gaps between primes because once these sorts of regularity properties of ultraproducts are set up, one usually gets uniformity with respect to choice of coefficients or of base field more or less for free.
2 August, 2013 at 8:50 pm
Emmanuel Kowalski
Actually, I think the Swan conductors can be bounded in many cases by using again the Bombieri bounds for sums of Betti numbers.
Assume the constructed sheaf parameterizing the exponential sums does not contain the trivial representation and in fact is pure of weight 0 (at least for the moment.)
Basically, up to quantities one knows how to bound, the sum of Swan conductors is bounded by the Euler-Poincaré characteristic which is bounded by the sum of Betti numbers. At least if the H^1 is pure of weight 1, we can then get at its dimension as the limsup of
Tr( global Frobenius of F_q | H_1)
where q =p^k —> infinity. But this trace is (by definition of the sheaf and the trace formula) the q-companion sum of the original 2-variable character sum, and its expression as a sum of Weil numbers is controlled by the zeta function of these, whose number of roots is bounded by Bombieri (and/or Adolphoson — Sperber and/or Katz’s bounds on Betti numbers.)
(I suspect this is very likely just a “concrete” version of a spectral sequence argument…)
What I don’t know is how to do this for a general “transformation” with kernel psi(f(x,y)), i.e., bounding the conductor of
L(x)=sum_y K(y) psi(f(x,y))
in terms of the conductor of K and invariants of f, if K is not a rank 1 sheaf itself.
2 August, 2013 at 8:52 pm
Emmanuel Kowalski
Typos: in the limsup, one must divide by sqrt(q), of course.
Also the sums of Betti numbers are not the same at the beginning of the third paragraph (where I refer to the sheaf parameterizing the one-variable sum) and at the tend (where they refer to the 2-variable Artin-Schreier sheaf…)
3 August, 2013 at 7:51 am
Terence Tao
Great! So it seems that the only remaining issue is to ensure purity of the H^1 of the sheaf representing the sum . (Presumably H^2 is automatically pure, so it should not be difficult to show that this sheaf has no geometrically trivial component if Hooley’s criteria for full square root cancellation in
. (Presumably H^2 is automatically pure, so it should not be difficult to show that this sheaf has no geometrically trivial component if Hooley’s criteria for full square root cancellation in  applies.) Would one have to try to use Poincare duality here? (But there is this distinction between cohomology and cohomology with compact supports that I don’t understand…)
applies.) Would one have to try to use Poincare duality here? (But there is this distinction between cohomology and cohomology with compact supports that I don’t understand…)
p.s. I’m going on vacation starting today, so am going to have much slower response times for a while.
3 August, 2013 at 8:42 am
Emmanuel Kowalski
I will try to write down the argument carefully (and in suitable generality) in the next few days. Local purity has the advantage of being a pointwise property, and hence should be understandable (in that case) from properties of one variable character sums.
12 August, 2013 at 9:50 am
Emmanuel Kowalski
Actually, it seems that one can also estimate the conductor for sum_y K(y) psi(f(x,y)) in some decent amount of generality, using similar ideas. We (FKM) are preparing a note on this.
If it works out in sufficient generality, this might lead to a bound for the conductor of the Fourier transform which does not require Laumon’s deep theory of local Fourier transforms. (But it is not yet clear that this will indeed work…)
13 August, 2013 at 12:27 pm
Terence Tao
That’s great news! Modulo some checking of the remaining steps of the argument, I think this would be the only thing needed to complete the proof of the improved Type I estimate of this blog post.
Given the slowdown in activity in the last month or so, it looks to me like we have reached the stage where we should “declare victory” and start turning attention to the writing up of the results we have, and hopefully others in the future will be able to build further upon what we’ve done (or maybe find some dramatically different approach to these problems). Thanks to the modular nature of the argument, I think we can pull off a single paper that manages to contain both sides of the tradeoff between simplicity and optimality, e.g. containing the proof of both the improved Type I estimate that uses all the ell-adic cohomology theory, as well as the somewhat easier Type I estimate that “only” requires the Weil conjectures for curves, and similarly for a few other components of the argument. I can try to draft up a skeleton of what such a paper might look like and put it online for discussion.
13 August, 2013 at 2:22 pm
Aubrey de Grey
Just one question about that: how confident are the experts that k0 cannot be nudged down to 631? The difference to H is of course very slight compared to the strides achieved by each improvement made to varpi, but since the key headline of the paper will presumably be what H has been achieved, I would presume that there is quite a lot of value in being able to make a strong case that the advertised k0 really is the best that can be extracted from the best varpi/delta combination. I raise this partly because Eytan Paldi indicated two weeks ago that he had a potential improvement but then did not make further comment, and also because xfxie was historically leading the k0 charge but has not commented for a long while.
13 August, 2013 at 8:27 pm
xfxie
@Aubrey: I just did some modifications on my code to handle the changes in Terence’s new maple code ( https://terrytao.wordpress.com/2013/07/07/the-distribution-of-primes-in-doubly-densely-divisible-moduli/#comment-239872 ) — I did not comment for a while since I was too lazy to make the necessary modifications as I was busy in catching up a deadline during that time period.
The code did find some other solutions for =632 (Just put one of them to the
=632 (Just put one of them to the  table: http://www.cs.cmu.edu/~xfxie/project/admissible/k0table.html ). However, for
table: http://www.cs.cmu.edu/~xfxie/project/admissible/k0table.html ). However, for  =631, it cannot find a feasible solution in three runs — all three runs ended at a similar minimum value around (eps2-eps)=4.00414E-5. So it is highly possible that the solutions found by Terence and Gergely are already optimal for the current problem setting.
=631, it cannot find a feasible solution in three runs — all three runs ended at a similar minimum value around (eps2-eps)=4.00414E-5. So it is highly possible that the solutions found by Terence and Gergely are already optimal for the current problem setting.
14 August, 2013 at 12:50 pm
Eytan Paldi
Concerning Aubrey’s question, note that the criterion is
Using the constraint on , we may express the best
, we may express the best
 as
as  , implying the following expressions for
, implying the following expressions for 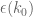 as a function of
as a function of 
Therefore . For
. For 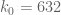 and Gergely's parameters
and Gergely's parameters  , we see that
, we see that
 .
.
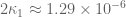 – which is much larger than
– which is much larger than
 and
and
 .
. 's are not "too sensitive" to small changes in
's are not "too sensitive" to small changes in
 , so the best strategy for
, so the best strategy for  (or even
(or even 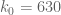 ) seems to increase
) seems to increase  (which is negative for the current value of
(which is negative for the current value of  ) by sufficiently decreasing
) by sufficiently decreasing  (but not too much – to keep
(but not too much – to keep 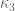 sufficiently small) and by sufficiently decreasing
sufficiently small) and by sufficiently decreasing 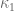 (by slightly increasing
(by slightly increasing 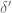 and thereby
and thereby  ). It seems that
). It seems that  is "too small" to cause any problem. To get some feeling of the dependence of the current upper bound of
is "too small" to cause any problem. To get some feeling of the dependence of the current upper bound of 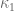 on
on 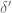 , observe that integration by parts of this (integral) bound gives
, observe that integration by parts of this (integral) bound gives
It seems that the
Note that depends on
depends on 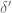 ,. It follows that by slightly increasing
,. It follows that by slightly increasing 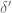 to
to  , the last upper bound on
, the last upper bound on
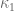 (for
(for  ) becomes
) becomes
 – a dramatic reduction!
– a dramatic reduction!
Therefore, it may be possible to get (or even
(or even
 .)
.)
Remarks:
1. I found an improvement to the current upper bound on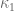 but unfortunately it seems to be numerically very minor one (few percents) so it is much better to use the above strategy of increasing
but unfortunately it seems to be numerically very minor one (few percents) so it is much better to use the above strategy of increasing 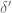 to sufficiently reduce
to sufficiently reduce 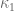 (Anyway, I intend to send this improvement in my next comment.)
(Anyway, I intend to send this improvement in my next comment.)
2. It is possible that the current bound of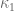 (via the current bound of its integrand
(via the current bound of its integrand  ) is quite crude (using only the fact that the function
) is quite crude (using only the fact that the function  is decreasing on
is decreasing on ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=545454&s=0&c=20201002) .) But one can exploit this monotonicity to get tight lower and upper numerical bounds for
.) But one can exploit this monotonicity to get tight lower and upper numerical bounds for 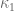 and its integrand – via corresponding lower and upper Riemann sums!
and its integrand – via corresponding lower and upper Riemann sums!
3. The current bound on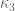 seems also to be quite crude. (the parameter A should be optimized – perhaps even for each dimension J – in its original formulation). It is interesting to note that a lower bound on
seems also to be quite crude. (the parameter A should be optimized – perhaps even for each dimension J – in its original formulation). It is interesting to note that a lower bound on 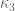 is given by the G-ratio (the coefficient in front of the exp.)
is given by the G-ratio (the coefficient in front of the exp.)
17 August, 2013 at 7:21 am
Aubrey de Grey
Thank you Eytan. In passing, I’m also wondering whether the current Deligne-avoiding k0 of 1788 can be nudged down, though of course this is of more marginal interest to most observers than the headline 632 value.
5 August, 2013 at 1:00 pm
Martin Maulhardt
Dear Mr Tao and Mr Harcos.
In connection with the papers you have suggested me to read, I have proved that there are infinitely many 4-tuples of consecutive primes of the form (Pk, Pk+1, Pk+2, Pk+3) where each dn+1 <= dn. An example is (31,37,41,43) and that this property is true for any finite length. This was the (still open) question raised by Erdos and Turan at the end of the paper Mr Harcos kindly provided.
I would be honored if you could take a look at my work on the address below and hope this might help you to continue the great work you (and others) are doing lowering the bound on Zhang's theorem.
http://martinmaulhardt.com/?page_id=91
11 August, 2013 at 4:35 pm
Fan
I hate to point out that the gist of Erdos’s result is the *strict* inequality i.o. (and similarly for the conjecture of three consecutive differences). The *non-strict* inequality can be obtained by very crude versions of PNT, e.g. Chebyshev's bound
i.o. (and similarly for the conjecture of three consecutive differences). The *non-strict* inequality can be obtained by very crude versions of PNT, e.g. Chebyshev's bound  ,
,
11 August, 2013 at 6:56 pm
martin maulhardt
Dear Fan,
Thanks very much for your comment. I didn’t know it was so trivial with non strict inequality. So the only value of my work is the elementary proof of this (non strict) inequalities. Do you know if the generalization I made : the inequalities between “even indexed” consecutive primes (P2k+4 – P2k+2 <= P2k+2 – Pk) satisfied infinitely many times are already known too? (they are proved on theorem 4 of my work).
If you (or anyone) know if this generalization already exists I would truly appreciate the information. If you think I can somehow return the help please let me know.
5 August, 2013 at 2:37 pm
abqmathteacher
In a practical context, I’ll note that, according to equation (1) on p. 5 of Soundararajan’s Bulletin review article, one expects gaps as large as 4680 to start to show up (but of course still be unusually large) for primes around 10^28, which is very small by cryptographic standards. Even just using PNT, gap size 4680 will be _average_ for primes around 10^2000 = 2^6750. Note that “An RSA key length of 3072 bits should be used if security is required beyond 2030” (Wikipedia), and one would expect gap size 4680 to at least not be unusual by that point. So by a certain stretch of the imagination—say, to a cryptographer working in 2040—4680 really could be seen as a “smallish” prime gap. Nice!
5 August, 2013 at 8:44 pm
Anonymous
Abqmathteacher, the bounded gap theorem doesn’t say anything about the expected gap between primes at arbitrary places. It just says that starting anywhere, if you keep searching upwards “forever”, you’ll eventually find a pair of primes separated by less than H. Remember H=4680 is just the best bound proved so far, but the problem inspiring all this work is actually to prove H=2. The expected gap at any particular place still gets arbitrarily large.
6 August, 2013 at 5:09 am
abqmathteacher
@Anonymous, you misunderstand me; sorry I didn’t spell it out more in my original comment. My point is that the original Zhang result of H=70,000,000, while theoretically groundbreaking, is a little underwhelming psychologically. A result that says “small [in some sense] gaps between primes recur infinitely often” is more impressive than one that just says “a certain finite [but rather large] gap or smaller recurs infinitely often”. (Isn’t that partly the point of this polymath project?) Clearly H=2 qualifies as (amazingly) small; H = 70,000,000 is rather large since one has to consider quite large primes before that qualifies as even an attainable gap, much less average, much less “small”. I was pointing out that H = 4680, while not obviously “small”, could be seen as such from a certain viewpoint, and I wanted to congratulate the project on getting to that point.
14 August, 2013 at 4:14 pm
Terence Tao
I’ve started an extremely minimal skeleton of a paper at
https://www.dropbox.com/sh/vmu141rph1xjqa0/buJWUGtsLD/Polymath8/newgap.pdfClick to access newgap.pdf
(with the source files available at
https://www.dropbox.com/sh/vmu141rph1xjqa0/buJWUGtsLD/Polymath8/https://www.dropbox.com/sh/j2r8yia6lkzk2gv/_5Sn7mNN3T )At this point there is no actual maths in the paper, just a proposed section outline. I’ve used the latest values of H in the headline results but of course this can be easily updated if there are further developments.
Once we agree on the general section structure, perhaps the next thing to discuss is the notation used (e.g. for the claims DHL, MPZ, etc.); I would default to the notation that has been developed in the course of this project, but it should be easy to change if needed. (I will try to use macros for some of the more complicated notation, so that changing that notation can be done in a single line of LaTeX code.)
If anyone is interested in helping edit the files, let me know and I will see if I can share the Dropbox folder. (Certainly I will need help on writing at least two sections of the paper, namely the narrow prime tuples section and the Deligne theory section. For most of the other sections, I can draw from previous blog posts to write a first draft at least.)
[Dropbox files moved, to deal with the problem that dropbox files in the public folder cannot be shared. -T.]
15 August, 2013 at 1:12 am
AndrewVSutherland
I can help with the narrow prime tuples section.
15 August, 2013 at 1:17 pm
Terence Tao
Great! It should hopefully be not too hard to write, as one can already crib a lot from your blog post over at http://sbseminar.wordpress.com/2013/07/02/the-quest-for-narrow-admissible-tuples/ as well as from the wiki.
15 August, 2013 at 8:46 am
Eytan Paldi
In the main theorem, should be
should be  .
.
[Corrected, thanks! -T]
15 August, 2013 at 4:07 pm
pigh3
RIght after Thm 2.2, Zhang’s original paper had .
.
[Corrected, thanks – T.]
15 August, 2013 at 11:17 pm
Philippe Michel
I ll be happy to help
16 August, 2013 at 2:19 am
Anonymous
You could set up a git repository instead of dropbox, so that people could work on their own versions of the files and git can pull patches from them. I’m not a fan of github but it has very nice collaboration tools for this sort of thing beyond git itself.
16 August, 2013 at 7:24 am
Philippe Michel
Maybe this is a good time to start a fresh new post devoted to the effective writing of the paper (or to decide of an different way to proceed) to share views and ideas on how redaction should be done.
Needless say I am in for helping on the writing Deligne/exponential sum section(s) and probably for other parts as well.
16 August, 2013 at 12:28 pm
Terence Tao
That’s a good idea, and thanks for offering to chip in! It may take a while before we get to the point where we can start writing seriously the Deligne stuff (it depends to some extent on how your writeup with Emmanuel and Etienne on the conductor bounds for pushforward sheaves turns out) but this is certainly something to discuss in the next post. I’ll try to set something up in a day or two (I’m hopping on a plane in a few hours).
Regarding alternatives to dropbox, I am familiar with Subversion, and with a lesser extent with Git, but the learning curve (particularly for the latter) is steeper with that for Dropbox, and for the fairly limited task we have at hand (writing a single paper) I think these more advanced version control platforms may be overkill. Of course, one pays a price for this, which is that Dropbox has more difficulty dealing with conflicts in which two people are trying to edit the same file. But I think we can coordinate this through the blog; I have split the paper up into one file for each section, and if people announce what section they are working on, one should be able to avoid serious conflicts in practice (particularly if we try to only modify the Dropbox files while connected to the internet). For instance, I am going to be working more or less exclusively on Section 2 (“Key subclaims”, or subtheorems.tex) for the next day or two to try to organise the overall logic, which of course we should also discuss in the next post.
17 August, 2013 at 2:08 am
Emmanuel Kowalski
I will also participate of course. I’ll also use my own subversion setup independently of the Dropbox, so this might also help limit any possible difficulties with editing conflicts.
I will probably sketch the conductor bound in a blog post next week. Interestingly, it really turns out to be better to proceed with the algebraic analogue of the companion sum argument, although the latter certainly gives the right idea of what is going on.
14 August, 2013 at 6:01 pm
Anonymous
Typographical comment on the paper: If you load the siunitx package (http://ctan.org/pkg/siunitx), you can write $H = \num{70000000}$ and get the correct output for the large number. (What you have now doesn’t look too good, I think.)
[Change made, thanks – T.]
17 August, 2013 at 1:12 am
Polymath8: Writing the paper | What's new
[…] some discussion at the previous post, we have tentatively decided on writing a single research paper, which contains (in a reasonably […]
23 October, 2013 at 1:00 pm
Anonymous
A question aside (maybe it was already asked in the previous threads):
Can the proof be generalized to arithmetic progressions ak+b, gcd(a,b)=1 ? That is, are there infinitely many pairs of primes at a distance at most Nb in such progression?
23 October, 2013 at 1:04 pm
Anonymous
I meant at a distance Na.
23 October, 2013 at 1:08 pm
Terence Tao
Yes, this should be the case; I currently have a graduate student checking the details of this. (One slight issue here is that whereas the original argument requires distribution results only for squarefree moduli, the extension to ak+b requires distribution results for moduli which are the product of a and a squarefree number, and so one needs a very slight generalisation of the existing distribution results. But this appears to only be a minor technical difficulty.)
18 November, 2013 at 6:04 pm
Math Blog Snippet | the Cyclic Grizzly
[…] He uses the Tarski theme with a modified CSS (to do things such as boxed theorems). As stated on his About page, he uses Luca Trevisan’s LaTeX to WordPress converter to write his more mathematically intensive posts. Above, you’ll see an example of how he uses LaTeX on his blog, excerpted from the post “An improved Type I estimate.” […]
16 May, 2018 at 10:16 am
Math Blog and how to write math equations using LaTeX $latex…$ | Adonis Diaries
[…] As stated on his About page, he uses Luca Trevisan’s LaTeX to WordPress converter to write his more mathematically intensive posts. Above, you’ll see an example of how he uses LaTeX on his blog, excerpted from the post “An improved Type I estimate.” […]