Now that we have developed the basic probabilistic tools that we will need, we now turn to the main subject of this course, namely the study of random matrices. There are many random matrix models (aka matrix ensembles) of interest – far too many to all be discussed in a single course. We will thus focus on just a few simple models. First of all, we shall restrict attention to square matrices 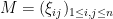 , where
, where  is a (large) integer and the
is a (large) integer and the  are real or complex random variables. (One can certainly study rectangular matrices as well, but for simplicity we will only look at the square case.) Then, we shall restrict to three main models:
are real or complex random variables. (One can certainly study rectangular matrices as well, but for simplicity we will only look at the square case.) Then, we shall restrict to three main models:
- Iid matrix ensembles, in which the coefficients are iid random variables with a single distribution
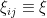 . We will often normalise
. We will often normalise  to have mean zero and unit variance. Examples of iid models include the Bernouli ensemble (aka random sign matrices) in which the are signed Bernoulli variables, the real gaussian matrix ensemble in which
to have mean zero and unit variance. Examples of iid models include the Bernouli ensemble (aka random sign matrices) in which the are signed Bernoulli variables, the real gaussian matrix ensemble in which 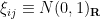 , and the complex gaussian matrix ensemble in which
, and the complex gaussian matrix ensemble in which 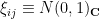 .
.
- Symmetric Wigner matrix ensembles, in which the upper triangular coefficients ,
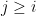 are jointly independent and real, but the lower triangular coefficients ,
are jointly independent and real, but the lower triangular coefficients ,  are constrained to equal their transposes:
are constrained to equal their transposes: 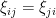 . Thus
. Thus  by construction is always a real symmetric matrix. Typically, the strictly upper triangular coefficients will be iid, as will the diagonal coefficients, but the two classes of coefficients may have a different distribution. One example here is the symmetric Bernoulli ensemble, in which both the strictly upper triangular and the diagonal entries are signed Bernoulli variables; another important example is the Gaussian Orthogonal Ensemble (GOE), in which the upper triangular entries have distribution
by construction is always a real symmetric matrix. Typically, the strictly upper triangular coefficients will be iid, as will the diagonal coefficients, but the two classes of coefficients may have a different distribution. One example here is the symmetric Bernoulli ensemble, in which both the strictly upper triangular and the diagonal entries are signed Bernoulli variables; another important example is the Gaussian Orthogonal Ensemble (GOE), in which the upper triangular entries have distribution  and the diagonal entries have distribution
and the diagonal entries have distribution 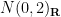 . (We will explain the reason for this discrepancy later.)
. (We will explain the reason for this discrepancy later.)
- Hermitian Wigner matrix ensembles, in which the upper triangular coefficients are jointly independent, with the diagonal entries being real and the strictly upper triangular entries complex, and the lower triangular coefficients , are constrained to equal their adjoints:
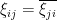 . Thus by construction is always a Hermitian matrix. This class of ensembles contains the symmetric Wigner ensembles as a subclass. Another very important example is the Gaussian Unitary Ensemble (GUE), in which all off-diagional entries have distribution
. Thus by construction is always a Hermitian matrix. This class of ensembles contains the symmetric Wigner ensembles as a subclass. Another very important example is the Gaussian Unitary Ensemble (GUE), in which all off-diagional entries have distribution 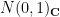 , but the diagonal entries have distribution .
, but the diagonal entries have distribution .
Given a matrix ensemble , there are many statistics of that one may wish to consider, e.g. the eigenvalues or singular values of , the trace and determinant, etc. In these notes we will focus on a basic statistic, namely the operator norm
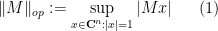
of the matrix . This is an interesting quantity in its own right, but also serves as a basic upper bound on many other quantities. (For instance, 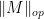 is also the largest singular value
is also the largest singular value 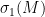 of and thus dominates the other singular values; similarly, all eigenvalues
of and thus dominates the other singular values; similarly, all eigenvalues 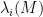 of clearly have magnitude at most .) Because of this, it is particularly important to get good upper tail bounds
of clearly have magnitude at most .) Because of this, it is particularly important to get good upper tail bounds

on this quantity, for various thresholds  . (Lower tail bounds are also of interest, of course; for instance, they give us confidence that the upper tail bounds are sharp.) Also, as we shall see, the problem of upper bounding can be viewed as a non-commutative analogue of upper bounding the quantity
. (Lower tail bounds are also of interest, of course; for instance, they give us confidence that the upper tail bounds are sharp.) Also, as we shall see, the problem of upper bounding can be viewed as a non-commutative analogue of upper bounding the quantity 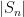 studied in Notes 1. (The analogue of the central limit theorem in Notes 2 is the Wigner semi-circular law, which will be studied in the next set of notes.)
studied in Notes 1. (The analogue of the central limit theorem in Notes 2 is the Wigner semi-circular law, which will be studied in the next set of notes.)
An  matrix consisting entirely of
matrix consisting entirely of  s has an operator norm of exactly , as can for instance be seen from the Cauchy-Schwarz inequality. More generally, any matrix whose entries are all uniformly
s has an operator norm of exactly , as can for instance be seen from the Cauchy-Schwarz inequality. More generally, any matrix whose entries are all uniformly  will have an operator norm of
will have an operator norm of  (which can again be seen from Cauchy-Schwarz, or alternatively from Schur’s test, or from a computation of the Frobenius norm). However, this argument does not take advantage of possible cancellations in . Indeed, from analogy with concentration of measure, when the entries of the matrix are independent, bounded and have mean zero, we expect the operator norm to be of size
(which can again be seen from Cauchy-Schwarz, or alternatively from Schur’s test, or from a computation of the Frobenius norm). However, this argument does not take advantage of possible cancellations in . Indeed, from analogy with concentration of measure, when the entries of the matrix are independent, bounded and have mean zero, we expect the operator norm to be of size 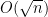 rather than . We shall see shortly that this intuition is indeed correct. (One can see, though, that the mean zero hypothesis is important; from the triangle inequality we see that if we add the all-ones matrix (for instance) to a random matrix with mean zero, to obtain a random matrix whose coefficients all have mean , then at least one of the two random matrices necessarily has operator norm at least
rather than . We shall see shortly that this intuition is indeed correct. (One can see, though, that the mean zero hypothesis is important; from the triangle inequality we see that if we add the all-ones matrix (for instance) to a random matrix with mean zero, to obtain a random matrix whose coefficients all have mean , then at least one of the two random matrices necessarily has operator norm at least  .)
.)
As mentioned before, there is an analogy here with the concentration of measure phenomenon, and many of the tools used in the latter (e.g. the moment method) will also appear here. (Indeed, we will be able to use some of the concentration inequalities from Notes 1 directly to help control and related quantities.) Similarly, just as many of the tools from concentration of measure could be adapted to help prove the central limit theorem, several the tools seen here will be of use in deriving the semi-circular law.
The most advanced knowledge we have on the operator norm is given by the Tracy-Widom law, which not only tells us where the operator norm is concentrated in (it turns out, for instance, that for a Wigner matrix (with some additional technical assumptions), it is concentrated in the range ![{[2\sqrt{n} - O(n^{-1/6}), 2\sqrt{n} + O(n^{-1/6})]}](https://s0.wp.com/latex.php?latex=%7B%5B2%5Csqrt%7Bn%7D+-+O%28n%5E%7B-1%2F6%7D%29%2C+2%5Csqrt%7Bn%7D+%2B+O%28n%5E%7B-1%2F6%7D%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ), but what its distribution in that range is. While the methods in this set of notes can eventually be pushed to establish this result, this is far from trivial, and will only be briefly discussed here. (We may return to the Tracy-Widom law later in this course, though.)
), but what its distribution in that range is. While the methods in this set of notes can eventually be pushed to establish this result, this is far from trivial, and will only be briefly discussed here. (We may return to the Tracy-Widom law later in this course, though.)
— 1. The epsilon net argument —
The slickest way to control is via the moment method. But let us defer using this method for the moment, and work with a more “naive” way to control the operator norm, namely by working with the definition (1). From that definition, we see that we can view the upper tail event  as a union of many simpler events:
as a union of many simpler events:

where 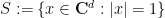 is the unit sphere in the complex space
is the unit sphere in the complex space 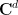 .
.
The point of doing this is that the event  is easier to control than the event , and can in fact be handled by the concentration of measure estimates we already have. For instance:
is easier to control than the event , and can in fact be handled by the concentration of measure estimates we already have. For instance:
Lemma 1 Suppose that the coefficients of are independent, have mean zero, and uniformly bounded in magnitude by . Let  be a unit vector in
be a unit vector in 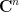 . Then for sufficiently large
. Then for sufficiently large  (larger than some absolute constant), one has
(larger than some absolute constant), one has

for some absolute constants  .
.
Proof: Let 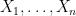 be the rows of , then the column vector
be the rows of , then the column vector  has coefficients
has coefficients  for
for  . if we let
. if we let 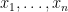 be the coefficients of , so that
be the coefficients of , so that  , then is just
, then is just 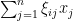 . Applying standard concentration of measure results (e.g. Exercise 4, Exercise 5, or Theorem 9 from Notes 1), we see that each is uniformly subgaussian, thus
. Applying standard concentration of measure results (e.g. Exercise 4, Exercise 5, or Theorem 9 from Notes 1), we see that each is uniformly subgaussian, thus

for some absolute constants . In particular, we have
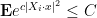
for some (slightly different) absolute constants . Multiplying these inequalities together for all  , we obtain
, we obtain

and the claim then follows from Markov’s inequality. 
Thus (with the hypotheses of Proposition 1), we see that for each individual unit vector , we have  with overwhelming probability. It is then tempting to apply the union bound and try to conclude that
with overwhelming probability. It is then tempting to apply the union bound and try to conclude that 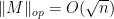 with overwhelming probability also. However, we encounter a difficulty: the unit sphere
with overwhelming probability also. However, we encounter a difficulty: the unit sphere  is uncountable, and so we are taking the union over an uncountable number of events. Even though each event occurs with exponentially small probability, the union could well be everything.
is uncountable, and so we are taking the union over an uncountable number of events. Even though each event occurs with exponentially small probability, the union could well be everything.
Of course, it is extremely wasteful to apply the union bound to an uncountable union. One can pass to a countable union just by working with a countable dense subset of the unit sphere instead of the sphere itself, since the map  is continuous. Of course, this is still an infinite set and so we still cannot usefully apply the union bound. However, the map is not just continuous; it is Lipschitz continuous, with a Lipschitz constant of . Now, of course there is some circularity here because is precisely the quantity we are trying to bound. Nevertheless, we can use this stronger continuity to refine the countable dense subset further, to a finite dense subset of , at the slight cost of modifying the threshold by a constant factor. Namely:
is continuous. Of course, this is still an infinite set and so we still cannot usefully apply the union bound. However, the map is not just continuous; it is Lipschitz continuous, with a Lipschitz constant of . Now, of course there is some circularity here because is precisely the quantity we are trying to bound. Nevertheless, we can use this stronger continuity to refine the countable dense subset further, to a finite dense subset of , at the slight cost of modifying the threshold by a constant factor. Namely:
Lemma 2 Let  be a maximal
be a maximal  -net of the sphere , i.e. a set of points in that are separated from each other by a distance of at least , and which is maximal with respect to set inclusion. Then for any matrix with complex coefficients, and any
-net of the sphere , i.e. a set of points in that are separated from each other by a distance of at least , and which is maximal with respect to set inclusion. Then for any matrix with complex coefficients, and any 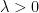 , we have
, we have
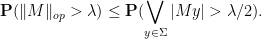
Proof: By (1) (and compactness) we can find 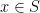 such that
such that

This point need not lie in . However, as is a maximal -net of , we know that lies within of some point  in (since otherwise we could add to and contradict maximality). Since
in (since otherwise we could add to and contradict maximality). Since  , we have
, we have

By the triangle inequality we conclude that

In particular, if , then  for some
for some  , and the claim follows.
, and the claim follows.
Remark 3 Clearly, if one replaces the maximal -net here with an maximal  -net for some other
-net for some other  (defined in the obvious manner), then we get the same conclusion, but with
(defined in the obvious manner), then we get the same conclusion, but with  replaced by
replaced by  .
.
Now that we have discretised the range of points to be finite, the union bound becomes viable again. We first make the following basic observation:
Lemma 4 (Volume packing argument) Let 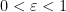 , and let be a -net of the sphere . Then has cardinality at most
, and let be a -net of the sphere . Then has cardinality at most  for some absolute constant
for some absolute constant 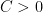 .
.
Proof: Consider the balls of radius 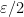 centred around each point in ; by hypothesis, these are disjoint. On the other hand, by the triangle inequality, they are all contained in the ball of radius
centred around each point in ; by hypothesis, these are disjoint. On the other hand, by the triangle inequality, they are all contained in the ball of radius 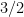 centred at the origin. The volume of the latter ball is at most the volume of any of the small balls, and the claim follows.
centred at the origin. The volume of the latter ball is at most the volume of any of the small balls, and the claim follows.
Exercise 5 Conversely, if is a maximal -net, show that has cardinality at least  for some absolute constant
for some absolute constant  .
.
And now we get an upper tail estimate:
Corollary 6 (Upper tail estimate for iid ensembles) Suppose that the coefficients of are independent, have mean zero, and uniformly bounded in magnitude by . Then there exists absolute constants such that
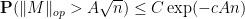
for all 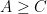 . In particular, we have
. In particular, we have 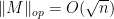 with overwhelming probability.
with overwhelming probability.
Proof: From Lemma 2 and the union bound, we have
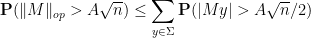
where is a maximal -net of . By Lemma 1, each of the probabilities  is bounded by
is bounded by 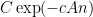 if is large enough. Meanwhile, from Lemma 4, has cardinality
if is large enough. Meanwhile, from Lemma 4, has cardinality  . If is large enough, the entropy loss of can be absorbed into the exponential gain of
. If is large enough, the entropy loss of can be absorbed into the exponential gain of  by modifying
by modifying  slightly, and the claim follows.
slightly, and the claim follows.
Exercise 7 If is a maximal 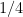 -net instead of a maximal -net, establish the following variant
-net instead of a maximal -net, establish the following variant

of Lemma 2. Use this to provide an alternate proof of Corollary 6.
The above result was for matrices with independent entries, but it easily extends to the Wigner case:
Corollary 8 (Upper tail estimate for Wigner ensembles) Suppose that the coefficients of are independent for , mean zero, and uniformly bounded in magnitude by , and let 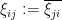 for . Then there exists absolute constants such that
for . Then there exists absolute constants such that
for all . In particular, we have with overwhelming probability.
Proof: From Corollary 6, the claim already holds for the upper-triangular portion of , as well as for the strict lower-triangular portion of . The claim then follows from the triangle inequality (adjusting the constants  appropriately).
appropriately).
Exercise 9 Generalise Corollary 6 and Corollary 8 to the case where the coefficients have uniform subgaussian tails, rather than being uniformly bounded in magnitude by .
Remark 10 What we have just seen is a simple example of an epsilon net argument, which is useful when controlling a supremum of random variables  such as (1), where each individual random variable
such as (1), where each individual random variable 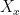 is known to obey a large deviation inequality (in this case, Lemma 1). The idea is to use metric arguments (e.g. the triangle inequality, see Lemma 2) to refine the set of parameters to take the supremum over to an -net
is known to obey a large deviation inequality (in this case, Lemma 1). The idea is to use metric arguments (e.g. the triangle inequality, see Lemma 2) to refine the set of parameters to take the supremum over to an -net 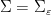 for some suitable , and then apply the union bound. One takes a loss based on the cardinality of the -net (which is basically the metric entropy or covering number of the original parameter space at scale ), but one can hope that the bounds from the large deviation inequality are strong enough (and the metric entropy bounds sufficiently accurate) to overcome this entropy loss.
for some suitable , and then apply the union bound. One takes a loss based on the cardinality of the -net (which is basically the metric entropy or covering number of the original parameter space at scale ), but one can hope that the bounds from the large deviation inequality are strong enough (and the metric entropy bounds sufficiently accurate) to overcome this entropy loss.
There is of course the question of what scale to use. In this simple example, the scale 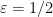 sufficed. In other contexts, one has to choose the scale more carefully. In more complicated examples with no natural preferred scale, it often makes sense to take a large range of scales (e.g.
sufficed. In other contexts, one has to choose the scale more carefully. In more complicated examples with no natural preferred scale, it often makes sense to take a large range of scales (e.g.  for
for  ) and chain them together by using telescoping series such as
) and chain them together by using telescoping series such as  (where
(where 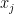 is the nearest point in
is the nearest point in 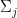 to for , and
to for , and 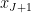 is by convention) to estimate the supremum, the point being that one can hope to exploit cancellations between adjacent elements of the sequence
is by convention) to estimate the supremum, the point being that one can hope to exploit cancellations between adjacent elements of the sequence 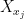 . This is known as the method of chaining. There is an even more powerful refinement of this method, known as the method of generic chaining, which has a large number of applications; see this book by Talagrand for a beautiful and systematic treatment of the subject. However, we will not use this method in this course.
. This is known as the method of chaining. There is an even more powerful refinement of this method, known as the method of generic chaining, which has a large number of applications; see this book by Talagrand for a beautiful and systematic treatment of the subject. However, we will not use this method in this course.
— 2. A symmetrisation argument (optional) —
We pause here to record an elegant symmetrisation argument that exploits convexity to allow us to reduce without loss of generality to the symmetric case 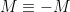 , albeit at the cost of losing a factor of
, albeit at the cost of losing a factor of  . We will not use this type of argument directly in these notes, but it is often used elsewhere in the literature.
. We will not use this type of argument directly in these notes, but it is often used elsewhere in the literature.
Let be any random matrix with mean zero, and let 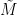 be an independent copy of . Then, conditioning on , we have
be an independent copy of . Then, conditioning on , we have
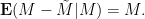
As the operator norm 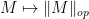 is convex, we can then apply Jensen’s inequality to conclude that
is convex, we can then apply Jensen’s inequality to conclude that
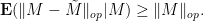
Undoing the conditioning over , we conclude that
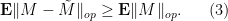
Thus, to upper bound the expected operator norm of , it suffices to upper bound the expected operator norm of  . The point is that even if is not symmetric (
. The point is that even if is not symmetric ( ),
), 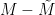 is automatically symmetric.
is automatically symmetric.
One can modify (3) in a few ways, given some more hypotheses on . Suppose now that 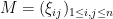 is a matrix with independent entries, thus has coefficients
is a matrix with independent entries, thus has coefficients 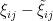 where
where  is an independent copy of . Introduce a random sign matrix
is an independent copy of . Introduce a random sign matrix 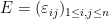 which is (jointly) independent of
which is (jointly) independent of  . Observe that as the distribution of is symmetric, that
. Observe that as the distribution of is symmetric, that

and thus

where  is the Hadamard product of
is the Hadamard product of 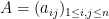 and
and 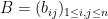 . We conclude from (3) that
. We conclude from (3) that

By the distributive law and the triangle inequality we have
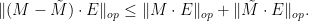
But as 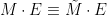 , the quantities
, the quantities  and
and  have the same expectation. We conclude the symmetrisation inequality
have the same expectation. We conclude the symmetrisation inequality

Thus, if one does not mind losing a factor of two, one has the freedom to randomise the sign of each entry of independently (assuming that the entries were already independent). Thus, in proving Corollary 6, one could have reduced to the case when the were symmetric, though in this case this would not have made the argument that much simpler.
Sometimes it is preferable to multiply the coefficients by a Gaussian rather than by a random sign. Again, let have independent entries with mean zero. Let  be a real gaussian matrix independent of , thus the
be a real gaussian matrix independent of , thus the 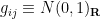 are iid. We can split
are iid. We can split 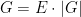 , where
, where 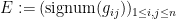 and
and 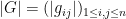 . Note that
. Note that  , ,
, ,  are independent, and is a random sign matrix. In particular, (4) holds. We now use
are independent, and is a random sign matrix. In particular, (4) holds. We now use
Exercise 11 If 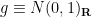 , show that
, show that  .
.
From this exercise we see that

and hence by Jensen’s inequality again

Undoing the conditional expectation in  and applying (4) we conclude the gaussian symmetrisation inequality
and applying (4) we conclude the gaussian symmetrisation inequality
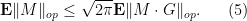
Thus, for instance, when proving Corollary 6, one could have inserted a random gaussian in front of each coefficient. This would have made the proof of Lemma 1 marginally simpler (as one could compute directly with gaussians, and reduce the number of appeals to concentration of measure results) but in this case the improvement is negligible. In other situations though it can be quite helpful to have the additional random sign or random gaussian factor present. For instance, we have the following result of Latala:
Theorem 12 Let be a matrix with independent mean zero entries, obeying the second moment bounds
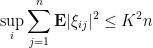
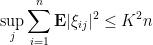
and the fourth moment bound

for some  . Then
. Then 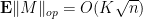 .
.
Proof: (Sketch only) Using (5) one can replace by 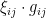 without much penalty. One then runs the epsilon-net argument with an explicit net, and uses concentration of measure results for gaussians (such as Theorem 8 from Notes 1) to obtain the analogue of Lemma 1. The details are rather intricate, and we refer the interested reader to Latala’s paper.
without much penalty. One then runs the epsilon-net argument with an explicit net, and uses concentration of measure results for gaussians (such as Theorem 8 from Notes 1) to obtain the analogue of Lemma 1. The details are rather intricate, and we refer the interested reader to Latala’s paper.
As a corollary of Theorem 12, we see that if we have an iid matrix (or Wigner matrix) of mean zero whose entries have a fourth moment of , then the expected operator norm is . The fourth moment hypothesis is sharp. To see this, we make the trivial observation that the operator norm of a matrix bounds the magnitude of any of its coefficients, thus
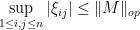
or equivalently that
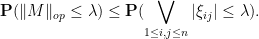
In the iid case , and setting 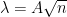 for some fixed independent of , we thus have
for some fixed independent of , we thus have

With the fourth moment hypothesis, one has from dominated convergence that
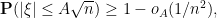
and so the right-hand side of (6) is asymptotically trivial. But with weaker hypotheses than the fourth moment hypothesis, the rate of convergence of 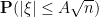 to can be slower, and one can easily build examples for which the right-hand side of (6) is
to can be slower, and one can easily build examples for which the right-hand side of (6) is 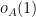 for every , which forces to typically be much larger than
for every , which forces to typically be much larger than  on the average.
on the average.
Remark 13 The symmetrisation inequalities remain valid with the operator norm replaced by any other convex norm on the space of matrices. The results are also just as valid for rectangular matrices as for square ones.
— 3. Concentration of measure —
Consider a random matrix of the type considered in Corollary 6 (e.g. a random sign matrix). We now know that the operator norm is of size with overwhelming probability. But there is much more that can be said. For instance, by taking advantage of the convexity and Lipschitz properties of , we have the following quick application of Talagrand’s inequality (Theorem 9 from Notes 1):
Proposition 14 Let be as in Corollary 6. Then for any , one has

for some absolute constants , where 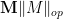 is a median value for . The same result also holds with
is a median value for . The same result also holds with 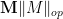 replaced by the expectation
replaced by the expectation  .
.
Proof: We view as a function  of the independent complex variables , thus
of the independent complex variables , thus  is a function from
is a function from 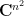 to
to  . The convexity of the operator norm tells us that is convex. The triangle inequality, together with the elementary bound
. The convexity of the operator norm tells us that is convex. The triangle inequality, together with the elementary bound
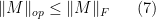
(easily proven by Cauchy-Schwarz), where

is the Frobenius norm (also known as the Hilbert-Schmidt norm or -Schatten norm), tells us that is Lipschitz with constant . The claim then follows directly from Talagrand’s inequality.
Exercise 15 Establish a similar result for the matrices in Corollary 8.
From Corollary 6 we know that the median or expectation of is of size ; we now know that concentrates around this median to width at most . (This turns out to be non-optimal; the Tracy-Widom law actually gives a concentration of  , under some additional assumptions on . Nevertheless this level of concentration is already non-trivial.)
, under some additional assumptions on . Nevertheless this level of concentration is already non-trivial.)
However, this argument does not tell us much about what the median or expected value of actually is. For this, we will need to use other methods, such as the moment method which we turn to next.
Remark 16 Talagrand’s inequality, as formulated in these notes, relies heavily on convexity. Because of this, we cannot apply this argument directly to non-convex matrix statistics, such as singular values 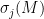 other than the largest singular value . Nevertheless, one can still use this inequality to obtain good concentration results, by using the convexity of related quantities, such as the partial sums
other than the largest singular value . Nevertheless, one can still use this inequality to obtain good concentration results, by using the convexity of related quantities, such as the partial sums  ; see this paper of Meckes. Other approaches include the use of alternate large deviation inequalities, such as those arising from log-Sobolev inequalities (see e.g. this book by Guionnet), or by using more abstract versions of Talagrand’s inequality (see this paper of Alon, Krivelevich, and Vu).
; see this paper of Meckes. Other approaches include the use of alternate large deviation inequalities, such as those arising from log-Sobolev inequalities (see e.g. this book by Guionnet), or by using more abstract versions of Talagrand’s inequality (see this paper of Alon, Krivelevich, and Vu).
— 4. The moment method —
We now bring the moment method to bear on the problem, starting with the easy moments and working one’s way up to the more sophisticated moments. It turns out that it is easier to work first with the case when is symmetric or Hermitian; we will discuss the non-symmetric case near the end of these notes.
The starting point for the moment method is the observation that for symmetric or Hermitian , the operator norm is equal to the 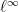 norm
norm

of the eigenvalues 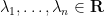 of . On the other hand, we have the standard linear algebra identity
of . On the other hand, we have the standard linear algebra identity
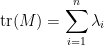
and more generally
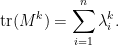
In particular, if 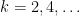 is an even integer, then
is an even integer, then 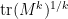 is just the
is just the 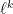 norm of these eigenvalues, and we have the inequalities
norm of these eigenvalues, and we have the inequalities
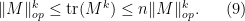
To put this another way, knowledge of the 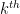 moment
moment  controls the operator norm up to a multiplicative factor of
controls the operator norm up to a multiplicative factor of 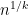 . Taking larger and larger
. Taking larger and larger  , we should thus obtain more accurate control on the operator norm. (This is basically the philosophy underlying the power method.)
, we should thus obtain more accurate control on the operator norm. (This is basically the philosophy underlying the power method.)
Remark 17 In most cases, one expects the eigenvalues to be reasonably uniformly distributed, in which case the upper bound in (9) is closer to the truth than the lower bound. One scenario in which this can be rigorously established is if it is known that the eigenvalues of all come with a high multiplicity. This is often the case for matrices associated with group actions (particularly those which are quasirandom in the sense of Gowers). However, this is usually not the case with most random matrix ensembles, and we must instead proceed by increasing as described above.
Let’s see how this method works in practice. The simplest case is that of the second moment  , which in the Hermitian case works out to
, which in the Hermitian case works out to
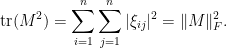
(Thus we see that (7) is just the  case of the lower inequality in (9), at least in the Hermitian case.)
case of the lower inequality in (9), at least in the Hermitian case.)
The expression 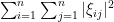 is easy to compute in practice. For instance, for the symmetric Bernoulli ensemble, this expression is exactly equal to
is easy to compute in practice. For instance, for the symmetric Bernoulli ensemble, this expression is exactly equal to 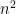 . More generally, if we have a Wigner matrix in which all off-diagonal entries have mean zero and unit variance, and the diagonal entries have mean zero and bounded variance (this is the case for instance for GOE), then the off-diagonal entries have mean , and by the law of large numbers we see that this expression is almost surely asymptotic to . (There is of course a dependence between the upper triangular and lower triangular entries, but this is easy to deal with by folding the sum into twice the upper triangular portion (plus the diagonal portion, which is lower order).)
. More generally, if we have a Wigner matrix in which all off-diagonal entries have mean zero and unit variance, and the diagonal entries have mean zero and bounded variance (this is the case for instance for GOE), then the off-diagonal entries have mean , and by the law of large numbers we see that this expression is almost surely asymptotic to . (There is of course a dependence between the upper triangular and lower triangular entries, but this is easy to deal with by folding the sum into twice the upper triangular portion (plus the diagonal portion, which is lower order).)
From the weak law of large numbers, we see in particular that one has

asymptotically almost surely.
Exercise 18 If the have uniformly sub-exponential tail, show that we in fact have (10) with overwhelming probability.
Applying (9), we obtain the bounds

asymptotically almost surely. This is already enough to show that the median of is at least 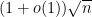 , which complements (up to constants) the upper bound of obtained from the epsilon net argument. But the upper bound here is terrible; we will need to move to higher moments to improve it.
, which complements (up to constants) the upper bound of obtained from the epsilon net argument. But the upper bound here is terrible; we will need to move to higher moments to improve it.
Accordingly, we now turn to the fourth moment. For simplicity let us assume that all entries have zero mean and unit variance. To control moments beyond the second moment, we will also assume that all entries are bounded in magnitude by some  . We expand
. We expand

To understand this expression, we take expectations:
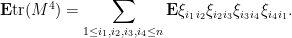
One can view this sum graphically, as a sum over length four cycles in the vertex set 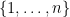 ; note that the four edges
; note that the four edges  are allowed to be degenerate if two adjacent
are allowed to be degenerate if two adjacent 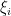 are equal. The value of each term
are equal. The value of each term
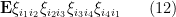
in this sum depends on what the cycle does.
Firstly, there is the case when all the four edges are distinct. Then the four factors  are independent; since we are assuming them to have mean zero, the term (12) vanishes. Indeed, the same argument shows that the only terms that do not vanish are those in which each edge is repeated at least twice. A short combinatorial case check then shows that, up to cyclic permutations of the
are independent; since we are assuming them to have mean zero, the term (12) vanishes. Indeed, the same argument shows that the only terms that do not vanish are those in which each edge is repeated at least twice. A short combinatorial case check then shows that, up to cyclic permutations of the  indices there are now only a few types of cycles in which the term (12) does not automatically vanish:
indices there are now only a few types of cycles in which the term (12) does not automatically vanish:
 , but
, but  are distinct from each other and from
are distinct from each other and from  .
.- and
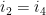 .
.
 , but
, but  is distinct from .
is distinct from .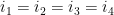 .
.
In the first case, the independence and unit variance assumptions tells us that (12) is , and there are 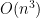 such terms, so the total contribution here to
such terms, so the total contribution here to 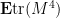 is at most . In the second case, the unit variance and bounded by tells us that the term is
is at most . In the second case, the unit variance and bounded by tells us that the term is  , and there are
, and there are 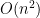 such terms, so the contribution here is
such terms, so the contribution here is  . Similarly, the contribution of the third type of cycle is , and the fourth type of cycle is
. Similarly, the contribution of the third type of cycle is , and the fourth type of cycle is 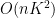 , so we can put it all together to get
, so we can put it all together to get

In particular, if we make the hypothesis 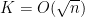 , then we have
, then we have
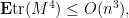
and thus by Markov’s inequality we see that for any  ,
,  with probability at least
with probability at least 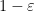 . Applying (9), this leads to the upper bound
. Applying (9), this leads to the upper bound
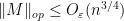
with probability at least ; a similar argument shows that for any fixed , one has
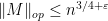
with high probability. This is better than the upper bound obtained from the second moment method, but still non-optimal.
Exercise 19 If  , use the above argument to show that
, use the above argument to show that

which in some sense improves upon (11) by a factor of  . In particular, if
. In particular, if  , conclude that the median of is at least
, conclude that the median of is at least  .
.
Now let us take a quick look at the sixth moment, again with the running assumption of a Wigner matrix in which all entries have mean zero, unit variance, and bounded in magnitude by . We have
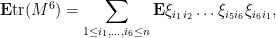
a sum over cycles of length 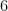 in . Again, most of the summands here vanish; the only ones which do not are those cycles in which each edge occurs at least twice (so in particular, there are at most three distinct edges).
in . Again, most of the summands here vanish; the only ones which do not are those cycles in which each edge occurs at least twice (so in particular, there are at most three distinct edges).
Classifying all the types of cycles that could occur here is somewhat tedious, but it is clear that there are going to be different types of cycles. But we can organise things by the multiplicity of each edge, leaving us with four classes of cycles to deal with:
- Cycles in which there are three distinct edges, each occuring two times.
- Cycles in which there are two distinct edges, one occuring twice and one occuring four times.
- Cycles in which there are two distinct edges, each occuring three times. (Actually, this case ends up being impossible, due to a “bridges of Königsberg” type of obstruction, but we will retain it for this discussion.)
- Cycles in which a single edge occurs six times.
It is not hard to see that summands coming from the first type of cycle give a contribution of , and there are 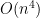 of these (because such cycles span at most four vertices). Similarly, the second and third types of cycles give a contribution of
of these (because such cycles span at most four vertices). Similarly, the second and third types of cycles give a contribution of 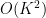 per summand, and there are
per summand, and there are  summands; finally, the fourth type of cycle gives a contribution of
summands; finally, the fourth type of cycle gives a contribution of 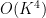 , with summands. Putting this together we see that
, with summands. Putting this together we see that
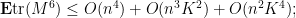
so in particular if we assume as before, we have

and if we then use (9) as before we see that

with probability , for any ; so we are continuing to make progress towards what we suspect (from the epsilon net argument) to be the correct bound of 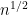 .
.
Exercise 20 If , use the above argument to show that

In particular, if , conclude that the median of is at least 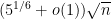 . Thus this is a (slight) improvement over Exercise 19.
. Thus this is a (slight) improvement over Exercise 19.
Let us now consider the general moment computation under the same hypotheses as before, with an even integer, and make some modest attempt to track the dependency of the constants on . Again, we have
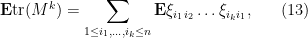
which is a sum over cycles of length . Again, the only non-vanishing expectations are those for which each edge occurs twice; in particular, there are at most 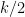 edges, and thus at most
edges, and thus at most 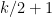 vertices.
vertices.
We divide the cycles into various classes, depending on which edges are equal to each other. (More formally, a class is an equivalence relation 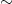 on a set of labels, say
on a set of labels, say  in which each equivalence class contains at least two elements, and a cycle of edges
in which each equivalence class contains at least two elements, and a cycle of edges  lies in the class associated to when we have that
lies in the class associated to when we have that 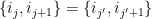 iff
iff  , where we adopt the cyclic notation
, where we adopt the cyclic notation  .)
.)
How many different classes could there be? We have to assign up to labels to edges, so a crude upper bound here is  .
.
Now consider a given class of cycle. It has  edges
edges  for some
for some  , with multiplicities
, with multiplicities 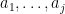 , where are at least and add up to . The edges span at most
, where are at least and add up to . The edges span at most 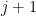 vertices; indeed, in addition to the first vertex , one can specify all the other vertices by looking at the first appearance of each of the edges in the path from to
vertices; indeed, in addition to the first vertex , one can specify all the other vertices by looking at the first appearance of each of the edges in the path from to 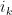 , and recording the final vertex of each such edge. From this, we see that the total number of cycles in this particular class is at most
, and recording the final vertex of each such edge. From this, we see that the total number of cycles in this particular class is at most  . On the other hand, because each has mean zero, unit variance and is bounded by , the
. On the other hand, because each has mean zero, unit variance and is bounded by , the 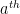 moment of this coefficient is at most
moment of this coefficient is at most  for any
for any  . Thus each summand in (13) coming from a cycle in this class has magnitude at most
. Thus each summand in (13) coming from a cycle in this class has magnitude at most
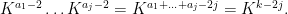
Thus the total contribution of this class to (13) is 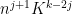 , which we can upper bound by
, which we can upper bound by

Summign up over all classes, we obtain the (somewhat crude) bound

and thus by (9)

and so by Markov’s inequality we have
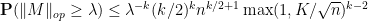
for all . This, for instance, places the median of at  . We can optimise this in by choosing to be comparable to
. We can optimise this in by choosing to be comparable to  , and so we obtain an upper bound of
, and so we obtain an upper bound of  for the median; indeed, a slight tweaking of the constants tells us that
for the median; indeed, a slight tweaking of the constants tells us that  with high probability.
with high probability.
The same argument works if the entries have at most unit variance rather than unit variance, thus we have shown
Proposition 21 (Weak upper bound) Let be a random Hermitian matrix, with the upper triangular entries , 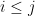 being independent with mean zero and variance at most , and bounded in magnitude by . Then with high probability.
being independent with mean zero and variance at most , and bounded in magnitude by . Then with high probability.
When 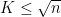 , this gives an upper bound of
, this gives an upper bound of 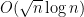 , which is still off by half a logarithm from the expected bound of . We will remove this half-logarithmic loss later in these notes.
, which is still off by half a logarithm from the expected bound of . We will remove this half-logarithmic loss later in these notes.
— 5. Computing the moment to top order —
Now let us consider the case when , and each entry has variance exactly . We have an upper bound

let us try to get a more precise answer here (as in Exercises 19, 20). Recall that each class of cycle contributed a bound of to this expression. If , we see that such expressions are  whenever
whenever 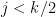 , where the
, where the  notation means that the decay rate as
notation means that the decay rate as  can depend on . So the total contribution of all such classes is .
can depend on . So the total contribution of all such classes is .
Now we consider the remaining classes with  . For such classes, each equivalence class of edges contains exactly two representatives, thus each edge is repeated exactly once. The contribution of each such cycle to (13) is exactly , thanks to the unit variance and independence hypothesis. Thus, the total contribution of these classes to
. For such classes, each equivalence class of edges contains exactly two representatives, thus each edge is repeated exactly once. The contribution of each such cycle to (13) is exactly , thanks to the unit variance and independence hypothesis. Thus, the total contribution of these classes to 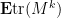 is equal to a purely combinatorial quantity, namely the number of cycles of length on in which each edge is repeated exactly once, yielding unique edges. We are thus faced with the enumerative combinatorics problem of bounding this quantity as precisely as possible.
is equal to a purely combinatorial quantity, namely the number of cycles of length on in which each edge is repeated exactly once, yielding unique edges. We are thus faced with the enumerative combinatorics problem of bounding this quantity as precisely as possible.
With edges, there are at most vertices traversed by the cycle. If there are fewer than vertices traversed, then there are at most  cycles of this type, since one can specify such cycles by identifying up to vertices in and then matching those coordinates with the vertices of the cycle. So we set aside these cycles, and only consider those cycles which traverse exactly vertices. Let us call such cycles (i.e. cycles of length with each edge repeated exactly once, and traversing exactly vertices) non-crossing cycles of length in . Our remaining task is then to count the number of non-crossing cycles.
cycles of this type, since one can specify such cycles by identifying up to vertices in and then matching those coordinates with the vertices of the cycle. So we set aside these cycles, and only consider those cycles which traverse exactly vertices. Let us call such cycles (i.e. cycles of length with each edge repeated exactly once, and traversing exactly vertices) non-crossing cycles of length in . Our remaining task is then to count the number of non-crossing cycles.
Example 22 Let  be distinct elements of . Then
be distinct elements of . Then  is a non-crossing cycle of length , as is
is a non-crossing cycle of length , as is 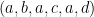 . Any cyclic permutation of a non-crossing cycle is again a non-crossing cycle.
. Any cyclic permutation of a non-crossing cycle is again a non-crossing cycle.
Exercise 23 Show that a cycle of length is non-crossing if and only if there exists a tree in of edges and vertices, such that the cycle lies in the tree and traverses each edge in the tree exactly twice.
Exercise 24 Let 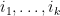 be a cycle of length . Arrange the integers
be a cycle of length . Arrange the integers  around a circle, and draw a line segment between two distinct integers
around a circle, and draw a line segment between two distinct integers  whenever
whenever  , with no between
, with no between  for which
for which  . Show that the cycle is non-crossing if and only if the number of line segments is exactly
. Show that the cycle is non-crossing if and only if the number of line segments is exactly  , and the line segments do not cross each other. This may help explain the terminology “non-crossing”.
, and the line segments do not cross each other. This may help explain the terminology “non-crossing”.
Now we can complete the count. If is a positive even integer, define a Dyck word of length to be the number of words consisting of left and right parentheses (, ) of length , such that when one reads from left to right, there are always at least as many left parentheses as right parentheses (or in other words, the parentheses define a valid nesting). For instance, the only Dyck word of length is  , the two Dyck words of length
, the two Dyck words of length  are
are  and
and 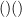 , and the five Dyck words of length are
, and the five Dyck words of length are

and so forth. (Dyck words are also closely related to Dyck paths.)
Lemma 25 The number of non-crossing cycles of length in is equal to  , where
, where  is the number of Dyck words of length . (The number is also known as the
is the number of Dyck words of length . (The number is also known as the 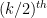 Catalan number.)
Catalan number.)
Proof: We will give a bijective proof. Namely, we will find a way to store a non-crossing cycle as a Dyck word, together with an (ordered) sequence of distinct elements from , in such a way that any such pair of a Dyck word and ordered sequence generates exactly one non-crossing cycle. This will clearly give the claim.
So, let us take a non-crossing cycle . We imagine traversing this cycle from to  , then from to
, then from to  , and so forth until we finally return to from . On each leg of this journey, say from
, and so forth until we finally return to from . On each leg of this journey, say from  to
to  , we either use an edge that we have not seen before, or else we are using an edge for the second time. Let us say that the leg from to is an innovative leg if it is in the first category, and a returning leg otherwise. Thus there are innovative legs and returning legs. Clearly, it is only the innovative legs that can bring us to vertices that we have not seen before. Since we have to visit distinct vertices (including the vertex we start at), we conclude that each innovative leg must take us to a new vertex. We thus record, in order, each of the new vertices we visit, starting at and adding another vertex for each innovative leg; this is an ordered sequence of distinct elements of . Next, traversing the cycle again, we write down a
, we either use an edge that we have not seen before, or else we are using an edge for the second time. Let us say that the leg from to is an innovative leg if it is in the first category, and a returning leg otherwise. Thus there are innovative legs and returning legs. Clearly, it is only the innovative legs that can bring us to vertices that we have not seen before. Since we have to visit distinct vertices (including the vertex we start at), we conclude that each innovative leg must take us to a new vertex. We thus record, in order, each of the new vertices we visit, starting at and adding another vertex for each innovative leg; this is an ordered sequence of distinct elements of . Next, traversing the cycle again, we write down a  whenever we traverse an innovative leg, and an
whenever we traverse an innovative leg, and an  otherwise. This is clearly a Dyck word. For instance, using the examples in Example 22, the non-crossing cycle
otherwise. This is clearly a Dyck word. For instance, using the examples in Example 22, the non-crossing cycle  gives us the ordered sequence
gives us the ordered sequence  and the Dyck word
and the Dyck word 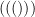 , while gives us the ordered sequence and the Dyck word
, while gives us the ordered sequence and the Dyck word  .
.
We have seen that every non-crossing cycle gives rise to an ordered sequence and a Dyck word. A little thought shows that the cycle can be uniquely reconstructed from this ordered sequence and Dyck word (the key point being that whenever one is performing a returning leg from a vertex  , one is forced to return along the unique innovative leg that discovered ). A slight variant of this thought also shows that every Dyck word of length and ordered sequence of distinct elements gives rise to a non-crossing cycle. This gives the required bijection, and the claim follows.
, one is forced to return along the unique innovative leg that discovered ). A slight variant of this thought also shows that every Dyck word of length and ordered sequence of distinct elements gives rise to a non-crossing cycle. This gives the required bijection, and the claim follows.
Next, we recall the classical formula for the Catalan number:
Exercise 26 Establish the recurrence
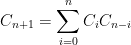
for any  (with the convention
(with the convention  ), and use this to deduce that
), and use this to deduce that

for all 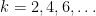 .
.
Exercise 27 Let be a positive even integer. Given a string of left parentheses and right parentheses which is not a Dyck word, define the reflection of this string by taking the first right parenthesis which does not have a matching left parenthesis, and then reversing all the parentheses after that right parenthesis. Thus, for instance, the reflection of 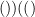 is
is 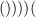 . Show that there is a bijection between non-Dyck words with left parentheses and right parentheses, and arbitrary words with left parentheses and right parentheses. Use this to give an alternate proof of (14).
. Show that there is a bijection between non-Dyck words with left parentheses and right parentheses, and arbitrary words with left parentheses and right parentheses. Use this to give an alternate proof of (14).
Note that 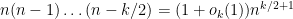 . Putting all the above computations together, we conclude
. Putting all the above computations together, we conclude
Theorem 28 (Moment computation) Let be a real symmetric random matrix, with the upper triangular elements , jointly independent with mean zero and variance one, and bounded in magnitude by 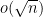 . Let be a positive even integer. Then we have
. Let be a positive even integer. Then we have
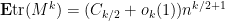
where is given by (14).
Remark 29 An inspection of the proof also shows that if we allow the to have variance at most one, rather than equal to one, we obtain the upper bound

Exercise 30 Show that Theorem 28 also holds for Hermitian random matrices. (Hint: The main point is that with non-crossing cycles, each non-innovative leg goes in the reverse direction to the corresponding innovative leg – why?)
Remark 31 Theorem 28 can be compared with the formula

derived in Notes 1, where 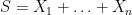 is the sum of iid random variables of mean zero and variance one, and
is the sum of iid random variables of mean zero and variance one, and

Exercise 24 shows that can be interpreted as the number of ways to join points on the circle by non-crossing chords. In a similar vein, 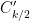 can be interpreted as the number of ways to join points on the circle by chords which are allowed to cross each other (except at the endpoints). Thus moments of Wigner-type matrices are in some sense the “non-crossing” version of moments of sums of random variables. We will discuss this phenomenon more when we turn to free probability in later notes.
can be interpreted as the number of ways to join points on the circle by chords which are allowed to cross each other (except at the endpoints). Thus moments of Wigner-type matrices are in some sense the “non-crossing” version of moments of sums of random variables. We will discuss this phenomenon more when we turn to free probability in later notes.
Combining Theorem 28 with (9) we obtain a lower bound

In the bounded case 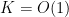 , we can combine this with Exercise 15 to conclude that the median (or mean) of is at least
, we can combine this with Exercise 15 to conclude that the median (or mean) of is at least 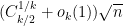 . On the other hand, from Stirling’s formula (Notes 0a) we see that
. On the other hand, from Stirling’s formula (Notes 0a) we see that  converges to as
converges to as 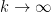 . Taking to be a slowly growing function of , we conclude
. Taking to be a slowly growing function of , we conclude
Proposition 32 (Lower bound) Let be a real symmetric random matrix, with the upper triangular elements , jointly independent with mean zero and variance one, and bounded in magnitude by . Then the median (or mean) of is at least 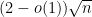 .
.
Remark 33 One can in fact obtain an exact asymptotic expansion of the moments as a polynomial in , known as the genus expansion of the moments. This expansion is however somewhat difficult to work with from a combinatorial perspective (except at top order) and will not be used here.
— 6. Removing the logarithm —
The upper bound in Proposition 21 loses a logarithm in comparison to the lower bound coming from Theorem 28. We now discuss how to remove this logarithm.
Suppose that we could eliminate the 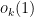 error in Theorem 28. Then from (9) we would have
error in Theorem 28. Then from (9) we would have
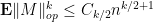
and hence by Markov’s inequality
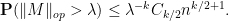
Applying this with  for some fixed , and setting to be a large multiple of , we see that
for some fixed , and setting to be a large multiple of , we see that  asymptotically almost surely, which on selecting to grow slowly in gives in fact that
asymptotically almost surely, which on selecting to grow slowly in gives in fact that  asymptotically almost surely, thus complementing the lower bound in Proposition 32.
asymptotically almost surely, thus complementing the lower bound in Proposition 32.
This argument was not rigorous because it did not address the error. Without a more quantitative accounting of this error, one cannot set as large as without losing control of the error terms; and indeed, a crude accounting of this nature will lose factors of  which are unacceptable. Nevertheless, by tightening the hypotheses a little bit and arguing more carefully, we can get a good bound, for in the region of interest:
which are unacceptable. Nevertheless, by tightening the hypotheses a little bit and arguing more carefully, we can get a good bound, for in the region of interest:
Theorem 34 (Improved moment bound) Let be a real symmetric random matrix, with the upper triangular elements , jointly independent with mean zero and variance one, and bounded in magnitude by  (say). Let be a positive even integer of size
(say). Let be a positive even integer of size  (say). Then we have
(say). Then we have
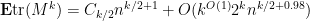
where is given by (14). In particular, from the trivial bound 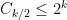 (which is obvious from the Dyck words definition) one has
(which is obvious from the Dyck words definition) one has

One can of course adjust the parameters 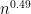 and
and 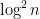 in the above theorem, but we have tailored these parameters for our application to simplify the exposition slightly.
in the above theorem, but we have tailored these parameters for our application to simplify the exposition slightly.
Proof: We may assume large, as the claim is vacuous for bounded .
We again expand using (13), and discard all the cycles in which there is an edge that only appears once. The contribution of the non-crossing cycles was already computed in the previous section to be
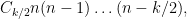
which can easily be computed (e.g. by taking logarithms, or using Stirling’s formula) to be 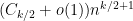 . So the only task is to show that the net contribution of the remaining cycles is
. So the only task is to show that the net contribution of the remaining cycles is  .
.
Consider one of these cycles  ; it has distinct edges for some (with each edge repeated at least once).
; it has distinct edges for some (with each edge repeated at least once).
We order the distinct edges by their first appearance in the cycle. Let be the multiplicities of these edges, thus the are all at least and add up to . Observe from the moment hypotheses that the moment  is bounded by
is bounded by  for . Since
for . Since  , we conclude that the expression
, we conclude that the expression

in (13) has magnitude at most  , and so the net contribution of the cycles that are not non-crossing is bounded in magnitude by
, and so the net contribution of the cycles that are not non-crossing is bounded in magnitude by
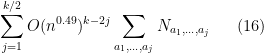
where range over integers that are at least and which add up to , and  is the number of cycles that are not non-crossing and have distinct edges with multiplicity (in order of appearance). It thus suffices to show that (16) is
is the number of cycles that are not non-crossing and have distinct edges with multiplicity (in order of appearance). It thus suffices to show that (16) is 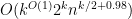 .
.
Next, we estimate for a fixed . Given a cycle , we traverse its legs (which each traverse one of the edges ) one at a time and classify them into various categories:
- High-multiplicity legs, which use an edge
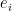 whose multiplicity
whose multiplicity  is larger than two.
is larger than two.
- Fresh legs, which use an edge with
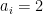 for the first time.
for the first time.
- Return legs, which use an edge with that has already been traversed by a previous fresh leg.
We also subdivide fresh legs into innovative legs, which take one to a vertex one has not visited before, and non-innovative legs, which take one to a vertex that one has visited before.
At any given point in time when traversing this cycle, we define an available edge to be an edge of multiplicity that has already been traversed by its fresh leg, but not by its return leg. Thus, at any given point in time, one travels along either a high-multiplicity leg, a fresh leg (thus creating a new available edge), or one returns along an available edge (thus removing that edge from availability).
Call a return leg starting from a vertex forced if, at the time one is performing that leg, there is only one available edge from , and unforced otherwise (i.e. there are two or more available edges to choose from).
We suppose that there are  high-multiplicity edges among the , leading to
high-multiplicity edges among the , leading to 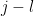 fresh legs and their return leg counterparts. In particular, the total number of high-multiplicity legs is
fresh legs and their return leg counterparts. In particular, the total number of high-multiplicity legs is

Since  , we conclude the bound
, we conclude the bound
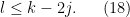
We assume that there are  non-innovative legs among the fresh legs, leaving
non-innovative legs among the fresh legs, leaving  innovative legs. As the cycle is not non-crossing, we either have or
innovative legs. As the cycle is not non-crossing, we either have or 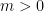 .
.
Similarly, we assume that there are  unforced return legs among the total return legs. We have an important estimate:
unforced return legs among the total return legs. We have an important estimate:
Lemma 35 (Not too many unforced return legs) We have
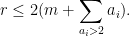
In particular, from (17), (18), we have

Proof: Let be a vertex visited by the cycle which is not the initial vertex . Then the very first arrival at comes from a fresh leg, which immediately becomes available. Each departure from may create another available edge from , but each subsequent arrival at will delete an available leg from , unless the arrival is along a non-innovative or high-multiplicity edge. (Note that one can loop from to itself and create an available edge, but this is along a non-innovative edge and so is not inconsistent with the previous statements.) Finally, any returning leg that departs from will also delete an available edge from .
This has two consequences. Firstly, if there are no non-innovative or high-multiplicity edges arriving at , then whenever one arrives at , there is at most one available edge from , and so every return leg from is forced. (And there will be only one such return leg.) If instead there are non-innovative or high-multiplicity edges arriving at , then we see that the total number of return legs from is at most one plus the number of such edges. In both cases, we conclude that the number of unforced return legs from is bounded by twice the number of non-innovative or high-multiplicity edges arriving at . Summing over , one obtains the claim.
Now we return to the task of counting , by recording various data associated to any given cycle contributing to this number. First, fix 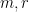 . We record the initial vertex of the cycle, for which there are possibilities. Next, for each high-multiplicity edge (in increasing order of ), we record all the locations in the cycle where this edge is used; the total number of ways this can occur for each such edge can be bounded above by
. We record the initial vertex of the cycle, for which there are possibilities. Next, for each high-multiplicity edge (in increasing order of ), we record all the locations in the cycle where this edge is used; the total number of ways this can occur for each such edge can be bounded above by  , so the total entropy cost here is
, so the total entropy cost here is 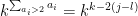 . We also record the final endpoint of the first occurrence of the edge for each such ; this list of
. We also record the final endpoint of the first occurrence of the edge for each such ; this list of 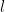 vertices in has at most
vertices in has at most 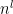 possibilities.
possibilities.
For each innovative leg, we record the final endpoint of that leg, leading to an additional list of vertices with at most  possibilities.
possibilities.
For each non-innovative leg, we record the position of that leg, leading to a list of numbers from , which has at most 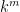 possibilities. We also record the position of the first time one already visited the vertex that the non-innovative leg is returning to, leading to a further list of numbers from
possibilities. We also record the position of the first time one already visited the vertex that the non-innovative leg is returning to, leading to a further list of numbers from 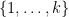 , and another possibilities.
, and another possibilities.
For each unforced return leg, we record the position of the corresponding fresh leg, leading to a list of numbers from , which has at most 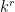 possibilities.
possibilities.
Finally, we record a Dyck-like word of length , in which we place a whenever the leg is innovative, and otherwise (the brackets need not match here). The total entropy cost here can be bounded above by  .
.
We now observe that all this data (together with  ) can be used to completely reconstruct the original cycle. Indeed, as one traverses the cycle, the data already tells us which edges are high-multiplicity, which ones are innovative, which ones are non-innovative, and which ones are return legs. In all edges in which one could possibly visit a new vertex, the location of that vertex has been recorded. For all unforced returns, the data tells us which fresh leg to backtrack upon to return to. Finally, for forced returns, there is only one available leg to backtrack to, and so one can reconstruct the entire cycle from this data.
) can be used to completely reconstruct the original cycle. Indeed, as one traverses the cycle, the data already tells us which edges are high-multiplicity, which ones are innovative, which ones are non-innovative, and which ones are return legs. In all edges in which one could possibly visit a new vertex, the location of that vertex has been recorded. For all unforced returns, the data tells us which fresh leg to backtrack upon to return to. Finally, for forced returns, there is only one available leg to backtrack to, and so one can reconstruct the entire cycle from this data.
As a consequence, for fixed 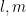 and , there are at most
and , there are at most

contributions to ; using (18), (35) we can bound this by
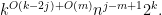
Summing over the possible values of (recalling that we either have or 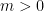 , and also that
, and also that  ) we obtain
) we obtain

The expression (16) can then be bounded by

When is exactly , then all the must equal , and so the contribution of this case simplifies to  . For , the numbers
. For , the numbers  are non-negative and add up to
are non-negative and add up to 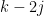 , and so the total number of possible values for these numbers (for fixed ) can be bounded crudely by
, and so the total number of possible values for these numbers (for fixed ) can be bounded crudely by 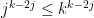 (for instance). Putting all this together, we can bound (16) by
(for instance). Putting all this together, we can bound (16) by
![\displaystyle 2^k [ k^{O(1)} n^{k/2} + \sum_{j=1}^{k/2-1} O(n^{0.49})^{k-2j} k^{O(k-2j) + O(1)} n^{j+1} k^{k-2j} ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+2%5Ek+%5B+k%5E%7BO%281%29%7D+n%5E%7Bk%2F2%7D+%2B+%5Csum_%7Bj%3D1%7D%5E%7Bk%2F2-1%7D+O%28n%5E%7B0.49%7D%29%5E%7Bk-2j%7D+k%5E%7BO%28k-2j%29+%2B+O%281%29%7D+n%5E%7Bj%2B1%7D+k%5E%7Bk-2j%7D+%5D&bg=ffffff&fg=000000&s=0&c=20201002)
which simplifies by the geometric series formula (and the hypothesis ) to
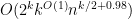
as required.
We can use this to conclude the following matching upper bound to Proposition 32, due to Bai and Yin:
Theorem 36 (Weak Bai-Yin theorem, upper bound) Let be a real symmetric matrix whose entries all have the same distribution , with mean zero, variance one, and fourth moment . Then for every independent of , one has  asymptotically almost surely. In particular,
asymptotically almost surely. In particular,  asymptotically almost surely; as another consequence, the median of is at most
asymptotically almost surely; as another consequence, the median of is at most 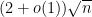 . (If is bounded, we see in particular from Proposition 32 that the median is in fact equal to .)
. (If is bounded, we see in particular from Proposition 32 that the median is in fact equal to .)
The fourth moment hypothesis is best possible, as seen in the discussion after Theorem 12. We will discuss some generalisations and improvements of this theorem in other directions below.
Proof: To obtain Theorem 36 from Theorem 34 we use the truncation method. We split each as 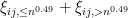 in the usual manner, and split
in the usual manner, and split 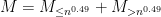 accordingly. We would like to apply Theorem 34 to
accordingly. We would like to apply Theorem 34 to  , but unfortunately the truncation causes some slight adjustment to the mean and variance of the
, but unfortunately the truncation causes some slight adjustment to the mean and variance of the 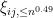 . The variance is not much of a problem; since had variance , it is clear that has variance at most , and it is easy to see that reducing the variance only serves to improve the bound (15). As for the mean, we use the mean zero nature of to write
. The variance is not much of a problem; since had variance , it is clear that has variance at most , and it is easy to see that reducing the variance only serves to improve the bound (15). As for the mean, we use the mean zero nature of to write
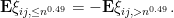
To control the right-hand side, we use the trivial inequality 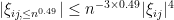 and the bounded fourth moment hypothesis to conclude that
and the bounded fourth moment hypothesis to conclude that

Thus we can write 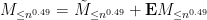 , where
, where 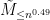 is the random matrix with coefficients
is the random matrix with coefficients
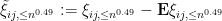
and 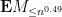 is a matrix whose entries have magnitude
is a matrix whose entries have magnitude 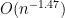 . In particular, by Schur’s test this matrix has operator norm
. In particular, by Schur’s test this matrix has operator norm 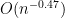 , and so by the triangle inequality
, and so by the triangle inequality
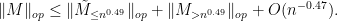
The error term is clearly negligible for large, and it will suffice to show that

and

asymptotically almost surely.
We first show (19). We can now apply Theorem 34 to conclude that
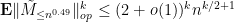
for any . In particular, we see from Markov’s inequality that (19) holds with probability at most
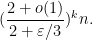
Setting to be a large enough multiple of (depending on ), we thus see that this event (19) indeed holds asymptotically almost surely (indeed, one can ensure it happens with overwhelming probability, by letting  grow slowly to infinity).
grow slowly to infinity).
Now we turn to (20). The idea here is to exploit the sparseness of the matrix 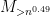 . First let us dispose of the event that one of the entries has magnitude larger than
. First let us dispose of the event that one of the entries has magnitude larger than  (which would certainly cause (20) to fail). By the union bound, the probability of this event is at most
(which would certainly cause (20) to fail). By the union bound, the probability of this event is at most

By the fourth moment bound on and dominated convergence, this expression goes to zero as . Thus, asymptotically almost surely, all entries are less than .
Now let us see how many non-zero entries there are in 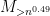 . By Markov’s inequality and the fourth moment hypothesis, each entry has a probability
. By Markov’s inequality and the fourth moment hypothesis, each entry has a probability  of being non-zero; by the first moment method, we see that the expected number of entries is
of being non-zero; by the first moment method, we see that the expected number of entries is 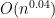 . As this is much less than , we expect it to be unlikely that any row or column has more than one entry. Indeed, from the union bound and independence, we see that the probability that any given row and column has at least two non-zero entries is at most
. As this is much less than , we expect it to be unlikely that any row or column has more than one entry. Indeed, from the union bound and independence, we see that the probability that any given row and column has at least two non-zero entries is at most
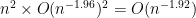
and so by the union bound again, we see that with probability at least  (and in particular, asymptotically almost surely), none of the rows or columns have more than one non-zero entry. As the entries have magnitude at most , the bound (20) now follows from Schur’s test, and the claim follows.
(and in particular, asymptotically almost surely), none of the rows or columns have more than one non-zero entry. As the entries have magnitude at most , the bound (20) now follows from Schur’s test, and the claim follows.
We can upgrade the asymptotic almost sure bound to almost sure boundedness:
Theorem 37 (Strong Bai-Yin theorem, upper bound) Let be a real random variable with mean zero, variance , and finite fourth moment, and for all  , let be an iid sequence with distribution , and set
, let be an iid sequence with distribution , and set 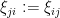 . Let
. Let 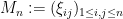 be the random matrix formed by the top left block. Then almost surely one has
be the random matrix formed by the top left block. Then almost surely one has  .
.
Exercise 38 By combining the above results with Proposition 32 and Exercise 15, show that with the hypotheses of Theorem 37 with bounded, one has 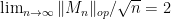 almost surely. (The same claim is true without the boundedness hypothesis; we will see this in the next set of notes, after we establish the semicircle law.)
almost surely. (The same claim is true without the boundedness hypothesis; we will see this in the next set of notes, after we establish the semicircle law.)
Proof: We first give ourselves an epsilon of room. It suffices to show that for each , one has

almost surely.
Next, we perform dyadic sparsification (as was done in the proof of the strong law of large numbers in Notes 1). Observe that any minor of a matrix has its operator norm bounded by that of the larger matrix; and so  is increasing in . Because of this, it will suffice to show (21) almost surely for restricted to a lacunary sequence, such as
is increasing in . Because of this, it will suffice to show (21) almost surely for restricted to a lacunary sequence, such as 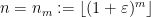 for
for 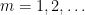 , as the general case then follows by rounding upwards to the nearest
, as the general case then follows by rounding upwards to the nearest 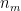 (and adjusting a little bit as necessary).
(and adjusting a little bit as necessary).
Once we sparsified, it is now safe to apply the Borel-Cantelli lemma (Exercise 1 of Notes 0), and it will suffice to show that
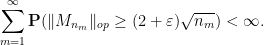
To bound the probabilities  , we inspect the proof of Theorem 36. Most of the contributions to this probability decay polynomially in (i.e. are of the form
, we inspect the proof of Theorem 36. Most of the contributions to this probability decay polynomially in (i.e. are of the form 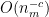 for some ) and so are summable. The only contribution which can cause difficulty is the contribution of the event that one of the entries of
for some ) and so are summable. The only contribution which can cause difficulty is the contribution of the event that one of the entries of 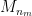 exceeds
exceeds  in magnitude; this event was bounded by
in magnitude; this event was bounded by

But if one sums over using Fubini’s theorem and the geometric series formula, we see that this expression is bounded by 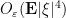 , which is finite by hypothesis, and the claim follows.
, which is finite by hypothesis, and the claim follows.
Now we discuss some variants and generalisations of the Bai-Yin result.
Firstly, we note that the results stated above require the diagonal and off-diagonal terms to have the same distribution. This is not the case for important ensembles such as the Gaussian Orthogonal Ensemble (GOE), in which the diagonal entries have twice as much variance as the off-diagonal ones. But this can easily be handled by considering the diagonal separately. For instance, consider a diagonal matrix  where the
where the  are identically distributed with finite second moment. The operator norm of this matrix is just
are identically distributed with finite second moment. The operator norm of this matrix is just  , and so by the union bound
, and so by the union bound
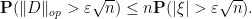
From the finite second moment and dominated convergence, the right-hand side is  , and so we conclude that for for every fixed ,
, and so we conclude that for for every fixed ,  asymptotically almost surely; diagonalising, we conclude that
asymptotically almost surely; diagonalising, we conclude that  asymptotically almost surely. Because of this and the triangle inequality, we can modify the diagonal by any amount with identical distribution and bounded second moment (a similar argument also works for non-identical distributions if one has uniform control of some moment beyond the second, such as the fourth moment) while only affecting all operator norms by
asymptotically almost surely. Because of this and the triangle inequality, we can modify the diagonal by any amount with identical distribution and bounded second moment (a similar argument also works for non-identical distributions if one has uniform control of some moment beyond the second, such as the fourth moment) while only affecting all operator norms by 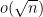 .
.
Exercise 39 Modify this observation to extend the weak and strong Bai-Yin theorems to the case where the diagonal entries are allowed to have different distribution than the off-diagonal terms, and need not be independent of each other or of the off-diagonal terms, but have uniformly bounded fourth moment.
Secondly, it is a routine matter to generalise the Bai-Yin result from real symmetric matrices to Hermitian matrices, basically for the same reasons that Exercise 30 works. We leave the details to the interested reader.
The Bai-Yin results also hold for iid random matrices, where has mean zero, unit variance, and bounded fourth moment; this is a result of Yin, Bai, and Krishnaiah. Because of the lack of symmetry, the eigenvalues need not be real, and the bounds (9) no longer apply. However, there is a substitute, namely the bound
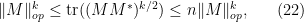
valid for any matrix with complex entries and every even positive integer .
Exercise 40 Prove (22).
It is possible to adapt all of the above moment calculations for in the symmetric or Hermitian cases to give analogous results for 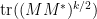 in the non-symmetric cases; we do not give the details here, but mention that the cycles now go back and forth along a bipartite graph with vertices in each class, rather than in the complete graph on vertices, although this ends up not to affect the enumerative combinatorics significantly. Another way of viewing this is through the simple observation that the operator norm of a non-symmetric matrix is equal to the operator norm of the augmented matrix
in the non-symmetric cases; we do not give the details here, but mention that the cycles now go back and forth along a bipartite graph with vertices in each class, rather than in the complete graph on vertices, although this ends up not to affect the enumerative combinatorics significantly. Another way of viewing this is through the simple observation that the operator norm of a non-symmetric matrix is equal to the operator norm of the augmented matrix
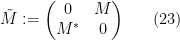
which is a 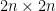 Hermitian matrix. Thus one can to some extent identify an iid matrix with a Wigner-type matrix , in which two blocks of that matrix are set to zero.
Hermitian matrix. Thus one can to some extent identify an iid matrix with a Wigner-type matrix , in which two blocks of that matrix are set to zero.
Exercise 41 If has singular values  , show that has eigenvalues
, show that has eigenvalues 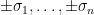 . This suggests that the theory of the singular values of an iid matrix should resemble to some extent the theory of eigenvalues of a Wigner matrix; we will see several examples of this phenomenon in later notes.
. This suggests that the theory of the singular values of an iid matrix should resemble to some extent the theory of eigenvalues of a Wigner matrix; we will see several examples of this phenomenon in later notes.
When one assumes more moment conditions on than bounded fourth moment, one can obtain substantially more precise asymptotics on than given by results such as Theorem 34, particularly if one also assumes that the underlying random variable is symmetric (i.e. 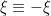 ). At a practical level, the advantage of symmetry is that it allows one to assume that the high-multiplicity edges in a cycle are traversed an even number of times; see the following exercise.
). At a practical level, the advantage of symmetry is that it allows one to assume that the high-multiplicity edges in a cycle are traversed an even number of times; see the following exercise.
Exercise 42 Let  be a bounded real random variable. Show that is symmetric if and only if
be a bounded real random variable. Show that is symmetric if and only if 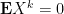 for all positive odd integers .
for all positive odd integers .
Next, extend the previous result to the case when is subgaussian rather than bounded. (Hint: The slickest way to do this is via the characteristic function  and analytic continuation; it is also instructive to find a “real-variable” proof that avoids the use of this function.)
and analytic continuation; it is also instructive to find a “real-variable” proof that avoids the use of this function.)
By using these methods, it is in fact possible to show that under various hypotheses, is concentrated in the range ![{[2\sqrt{n}-O(n^{-1/6}), 2\sqrt{n}+O(n^{-1/6})]}](https://s0.wp.com/latex.php?latex=%7B%5B2%5Csqrt%7Bn%7D-O%28n%5E%7B-1%2F6%7D%29%2C+2%5Csqrt%7Bn%7D%2BO%28n%5E%7B-1%2F6%7D%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , and even to get a universal distribution for the normalised expression
, and even to get a universal distribution for the normalised expression  , known as the Tracy-Widom law. See this paper of Soshnikov for details. There has also been a number of subsequent variants and refinements of this result (as well as counterexamples when not enough moment hypotheses are assumed); see for instance these papers of Soshnikov, Soshnikov-Fyodorov, Ruzmaikina, Péché, Vu, Soshnikov-Péché, Péché, Khorunzhiy and Tao-Vu for an (incomplete) sample of the work in this area. (Similar results for some non-independent distributions are also available, see e.g. this paper of Deift and Gioev, which (like many of the other references just cited) builds upon the original work of Tracy and Widom that handled special ensembles such as GOE and GUE.)
, known as the Tracy-Widom law. See this paper of Soshnikov for details. There has also been a number of subsequent variants and refinements of this result (as well as counterexamples when not enough moment hypotheses are assumed); see for instance these papers of Soshnikov, Soshnikov-Fyodorov, Ruzmaikina, Péché, Vu, Soshnikov-Péché, Péché, Khorunzhiy and Tao-Vu for an (incomplete) sample of the work in this area. (Similar results for some non-independent distributions are also available, see e.g. this paper of Deift and Gioev, which (like many of the other references just cited) builds upon the original work of Tracy and Widom that handled special ensembles such as GOE and GUE.)


61 comments
Comments feed for this article
10 January, 2010 at 8:17 am
Mark Meckes
Regarding the end of Remark 4, if you’ll forgive the immodesty, in this paper, I showed that one can get better concentration results for eigenvalues of symmetric matrices than Alon, Krivelevich, and Vu, by using actually the same version of Talagrand’s inequality you quoted previously (i.e. the more abstract version used by AKV is not necessary here).
10 January, 2010 at 9:12 am
Terence Tao
Thanks for the reference! I’ve updated the remark accordingly.
10 January, 2010 at 11:22 am
Mark Meckes
By the way, this post is by far the pedagogically nicest presentation I’ve ever seen of the moment method for random matrices. Beautiful!
10 January, 2010 at 3:43 pm
Paul Leopardi
Nice notes. I haven’t worked through them yet, but it looks like they would apply to the symmetric Wigner case where the diagonal entries are constant and the upper triangle is iid N(0,1), or iid with mean 0, variance 1 and bounded values: “Typically, the strictly upper triangular coefficients will be iid, as will the diagonal coefficients, but the two classes of coefficients may have a different distribution”. Working through the notes would then help me understand the moments of the Gram matrices for polynomial interpolation on the sphere.
Best, Paul
12 January, 2010 at 9:03 pm
254A, Notes 3a: Eigenvalues and sums of Hermitian matrices « What’s new
[…] values of non-Hermitian matrices (which is consistent with the discussion near Exercise 16 of Notes 3). However, the situation is markedly different when dealing with eigenvalues of non-Hermitian […]
13 January, 2010 at 4:29 am
Orr
I am having trouble understanding Lemma 1 and its proof: appearing on the right hand side, so it is not clear how you get the
appearing on the right hand side, so it is not clear how you get the  in
in  .
. occurs with probability at most
occurs with probability at most  seems inappropriate that there should be dependence on
seems inappropriate that there should be dependence on  . For instance, if the entries of the matrix are iid and taking
. For instance, if the entries of the matrix are iid and taking  , the probability of the event $|X_i \cdot x| \geq A$ converges to the probability that a Gaussian is greater than $A$, and that should remain bounded from below.
, the probability of the event $|X_i \cdot x| \geq A$ converges to the probability that a Gaussian is greater than $A$, and that should remain bounded from below.
Exercise 4, Exercise 5, or Theorem 9 from Notes 1 that you use do not have
And in the claim that
13 January, 2010 at 9:28 am
Terence Tao
Oops, you’re right, this is not the correct argument. I’ve replaced it with one which should be more correct (and which only holds for A sufficiently large, as it should.)
24 January, 2010 at 6:15 pm
Steven Heilman
Some minor typos?
1. Proof of Corollary 4: “…from Lemma 3, \Sigma [h]as cardinality…”
2. Section 2: “Suppose now that M={…} [is] a matrix”
3. After Exercise 4: Application of Jensen’s, needs \geq
4. Section 4, after (12): application of Markov’s inequality has extraneous E symbol?: “and thus by Markov’s inequality…”
{{\bf E} \hbox{tr}(M^4) \leq O_\epsilon(n^3)}
5. Beginning of Section 5: Now let [us?] consider…
6. Section 5, Example 1: If I’m not mistaken, the partition (a,b,c,d,b,c) is crossing. I think you meant (a,b,c,d,c,b), since this has the combinatorial label specified in the Proof of Lemma 9?
7. Is there any known connection between the expected operator norm of a random matrix and the projection constant of a finite dimensional Banach space? Maybe it is only vaguely related, but \lambda(X)\leq\sqrt{dim X} holds, where \lambda(X) is the projection constant of a Banach space X.
8. Near end of proof of Theorem 14: “each entry has a probability … probability[sic]”
30 January, 2010 at 9:57 pm
Anand Rajagopalan
Hi Professor,
Great notes!
A couple of minor typos:
-The occurrence of (a,b,c,d,b,c) in the proof of lemma 9 should be (a,b,c,d,c,b).
-The first inequality in section 6 should be reversed I think.
[Corrected, thanks – T.]
2 February, 2010 at 1:33 pm
254A, Notes 4: The semi-circular law « What’s new
[…] results in random matrix theory, namely the Wigner semi-circle law for Wigner matrices. Recall from previous notes that a Wigner Hermitian matrix ensemble is a random matrix ensemble of Hermitian matrices (thus ; […]
10 February, 2010 at 10:56 pm
245A, Notes 5: Free probability « What’s new
[…] a complex number). As before, we see that is a -linear functional that maps to . As we saw in Notes 3, the moment method for random matrices is based on a computation of the moments […]
5 March, 2010 at 1:47 pm
254A, Notes 7: The least singular value « What’s new
[…] the “soft edge” of the spectrum, that was discussed back in Notes 3, so one may at first think that the methods that were effective in controlling the latter, namely […]
14 March, 2010 at 11:33 am
254A, Notes 8: The circular law « What’s new
[…] the origin. Indeed, for iid matrices with subgaussian entries, one can show (using the methods from Notes 3) that the operator norm of is almost surely; this, combined with (2) and Laurent expansion, tells […]
31 March, 2010 at 9:24 am
PDEbeginner
Dear Prof. Tao,
I have some problems on how to estimate the median by the moments:
1. Ex 8: I don’t see how to obtain that the median of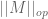 is at least
is at least  from the bounds therein and the assumption
from the bounds therein and the assumption  .
.
2. Argument immediately above Prop 8: I understood the estimate of sixth moments and that by Markov inequality, but didn’t know how to get the median estimate.
My questions are most probably very trivial, it would be very appreciated if you could give some hints.
31 March, 2010 at 10:11 am
Terence Tao
For exercise 8, use concentration of measure (Prop 7) to extract information about the median from the fourth moment.
For the second argument: if , then the median of
, then the median of  is necessarily at most
is necessarily at most  .
.
1 April, 2010 at 9:28 am
PDEbeginner
Dear Prof. Tao,
Thanks a lot for your help!
I think I got it. I think the condition is for applying Talagrand’s inequality.
is for applying Talagrand’s inequality.
As for the Talagrand’s inequality in note 1, I would like to give an immature suggestion (maybe it is wrong):
It seems that the -Lipschitz condition is a little confusing. At the first glance, one might think that the Talagrand’s inequality holds only when Lipschitz constant of
-Lipschitz condition is a little confusing. At the first glance, one might think that the Talagrand’s inequality holds only when Lipschitz constant of  is 1. After checking the proof, I think we only need that Lipschitz constant is bounded. So I think it could be better to add some remark near the Talagrand’s Theorem (if I am right).
is 1. After checking the proof, I think we only need that Lipschitz constant is bounded. So I think it could be better to add some remark near the Talagrand’s Theorem (if I am right).
31 March, 2010 at 9:26 am
PDEbeginner
sorry, the problem 2 is -th moment.
-th moment.
23 May, 2010 at 8:28 am
Anonymous
I have one question. Close to the end of this note, there is “From the finite second moment and dominated convergence, the right hand side is o_{\epsilon}(1)”.
I used the markov inequality to see that actually that right hand side is bounded by a constant, rather than o_{\epsilon}(1)”.
Could you expand on this argument? Thank you very much.
a typo: before “we inspect the proof of Theorem 14″, a right bracket is missing.
23 May, 2010 at 11:07 am
Terence Tao
From dominated convergence,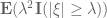 goes to zero as
goes to zero as 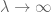 , if
, if 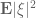 is finite.
is finite.
15 November, 2010 at 2:52 am
Guillaume
Dear Prof. Tao,
Unless I missed something, there appears to be a misprint in Lemma 9 (and at several subsequent places), the product should be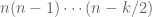 instead of
instead of  …
…
[Corrected, thanks – T.]
20 November, 2010 at 11:19 pm
Dai
Dear Prof. Tao,
At the end of section 4, you said “How many different classes could there be? We have to assign up to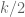 labels to
labels to  edges, so a crude upper bound here is
edges, so a crude upper bound here is 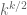 .”
.”
Why this is true? I think by this argument the crude upper bound should be . Maybe this problem is trivial for you. Thank you very much in advance.
. Maybe this problem is trivial for you. Thank you very much in advance.
[Oops, this was a typo (which unfortunately propagated throughout the section. Fixed now, – T.]
10 April, 2013 at 4:22 pm
Mustafa Said
Terry,
In the symmetrisation inequality (4), I think one can find an upper bound on the operator norm of the right hand side since when you introduce the random sign matrix E, it acts as an operator on M. There is a paper, “Restricted Schur Multipliers and their Applications,” by Timur Oikhberg that may help on this end.
4 November, 2013 at 1:48 pm
Real stable polynomials and the Kadison-Singer problem | What's new
[…] be, one might first try to compute the expected operator norm and then apply Proposition 1; see this previous blog post for examples of this strategy (and related strategies, based on comparing with more tractable […]
24 November, 2013 at 12:25 pm
Relatings turings use of norm (statistics) to eigenvalues | Peter's ruminations
[…] https://terrytao.wordpress.com/2010/01/09/254a-notes-3-the-operator-norm-of-a-random-matrix/ […]
5 August, 2014 at 2:57 pm
Yash Deshpande
A question regarding the estimate for :
: , it appears to me that one would need the end point of each non-innovative leg. This can be recorded using (for instance) the position of the innovative leg that first visited that vertex and incurs additional
, it appears to me that one would need the end point of each non-innovative leg. This can be recorded using (for instance) the position of the innovative leg that first visited that vertex and incurs additional 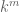 entropy cost. This does not change significantly the bound, in particular the estimate used ultimately is correct even with this modification.
entropy cost. This does not change significantly the bound, in particular the estimate used ultimately is correct even with this modification.
while recording the data for reconstructing the cycle
[Corrected, thanks – T.]
29 October, 2014 at 10:28 am
Marwin Mayer
Dear Prof. Tao,
I have a problem understanding a proof. (Here it is Proposition 11). You say “[…] we can combine this with Exercise 5 to conclude that the median (or mean) of {\|M\|_{op}} is at least {(C_{k/2}^{1/k}+o_k(1)) \sqrt{n}}”. But how can you use exercise 5 to conclude that?
Sincerely yours,
Marwin Mayer
29 October, 2014 at 10:42 am
Terence Tao
If the median of was less than
was less than 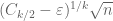 for some fixed
for some fixed  , then by using Exercise 5 one would have
, then by using Exercise 5 one would have  bounded by
bounded by 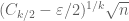 with overwhelming probability. One could then obtain an upper bound on the k^th moment that was of the form
with overwhelming probability. One could then obtain an upper bound on the k^th moment that was of the form  , contradicting the lower bound on this moment.
, contradicting the lower bound on this moment.
30 October, 2014 at 7:13 am
Marwin Mayer
Thank you very much! Now I understand it.
26 February, 2015 at 8:06 pm
elegantrium
Hi Dear Prof. Tao,
Is there any sharp result on the concentration inequality for schatten norm of a random matrix, where the Schatten norm is defined as in http://en.wikipedia.org/wiki/Schatten_norm?
Sincerely yours,
Jason
26 February, 2015 at 10:16 pm
Terence Tao
I would have a look at the article of Meckes http://www.ams.org/mathscinet-getitem?mr=2057479 (which considers general convex norms of random matrices).
23 October, 2015 at 8:06 am
275A, Notes 3: The weak and strong law of large numbers | What's new
[…] can obtain much sharper information on quantities such as the operator norm of a random matrix; see this previous blog post for further […]
17 November, 2015 at 11:27 pm
Canyi
Dear Prof. Tao,
It is known that for a matrix which is i.i.d., its spectral norm
which is i.i.d., its spectral norm  .
.
Now, I have a related and interesting about the spectral norm of the block circulant matrix defined as
where each is an i.i.d. matrix, and its elements have the distribution
is an i.i.d. matrix, and its elements have the distribution
for some .
.
Can we prove that for some constant
for some constant  with large probability?
with large probability?
18 November, 2015 at 8:33 am
Terence Tao
I expect that this should be provable by several of the methods in this post (e.g. I believe the moment method will eventually work, although the combinatorics are messy). There may be a more elegant approach using more advanced matrix inequalities (e.g. noncommutative Khinchin) or free probability methods, but I don’t immediately see such an argument.
6 February, 2016 at 3:24 pm
vj
Hi Prof. Tao,
The covering method gives a guarantee with probability 1-exp(-Omega(n)).
Can’t one get a similar probability bound in the trace power method by using
polynomial concentration results?
7 February, 2016 at 4:52 pm
Terence Tao
In principle yes, but one would have to apply concentration of measure results to polynomials of degree about , so one has to be careful regarding how the constants depend on degree. (But if one was content with an upper bound of the form
, so one has to be careful regarding how the constants depend on degree. (But if one was content with an upper bound of the form 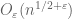 rather than
rather than  then one could work with polynomials of degree
then one could work with polynomials of degree 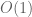 , in which case standard concentration of measure results would work without difficulty.)
, in which case standard concentration of measure results would work without difficulty.)
3 July, 2016 at 2:03 am
M
Dear Prof. Tao;
Would you please give me a hint on Exercise 1?
Thanks.
[Adapt the volume packing arguments used to prove Lemma 3. -T.]
3 July, 2016 at 9:48 am
M
OK, Thank you!
21 November, 2016 at 9:37 pm
Anonymous
Dear Prof. Tao,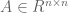 whose entries obey
whose entries obey
I have a question. For a matrix
we have .
.
Now my question is that for a matrix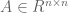 whose entries obey
whose entries obey
how could we prove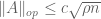 (this conclusion is right, but I do not know how to prove it)? Thanks a lot!
(this conclusion is right, but I do not know how to prove it)? Thanks a lot!
10 January, 2017 at 2:32 am
Anonymous
Minor typo in Lemma 3: the sphere in the lemma should be n-dimensional, should it not?
[Corrected, thanks – T.]
8 March, 2017 at 1:43 am
keej
I’m probably missing something simple, but I do not see why Exercise 7 requires . Each term (12) ends up being nonnegative, so to lower bound the sum it suffices to consider only the terms in the “first case,” of which there are 2n(n-1)(n-2) and each has value 1. By (9) it suffices to divide this by n and take the fourth root, which yields
. Each term (12) ends up being nonnegative, so to lower bound the sum it suffices to consider only the terms in the “first case,” of which there are 2n(n-1)(n-2) and each has value 1. By (9) it suffices to divide this by n and take the fourth root, which yields 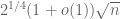 as desired.
as desired.
Could someone who did this please help me out?
[Fair enough; but this positivity is a special feature of the fourth moment and would not be available for the analogous assertions for higher moments. -T]
28 March, 2017 at 9:53 pm
keej
I see, thanks for the clarification!
25 December, 2017 at 5:44 am
AL Ray
Regarding Remark 1, I think that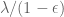 should actually be
should actually be  . I assume that the definition of 1/2-net coincides with \epsilon – net, in which case when plugging \epsilon = 1/2 we should be getting a factor of half and not 2.
. I assume that the definition of 1/2-net coincides with \epsilon – net, in which case when plugging \epsilon = 1/2 we should be getting a factor of half and not 2.
[Corrected, thanks – T.]
6 January, 2018 at 9:15 pm
Anonymous
A typo: In proposition 7,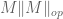 should be
should be 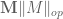 . [Corrected, thanks – T.]
. [Corrected, thanks – T.]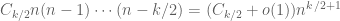 . Any hints?
. Any hints?
A question: I really do not know how to prove that
Thanks!
6 January, 2018 at 9:41 pm
Anonymous
PS: The difficulty is that could be large if
could be large if  is large.
is large.
6 January, 2018 at 10:13 pm
Anonymous
PSS: I can only show that .
.
7 January, 2018 at 12:12 am
Terence Tao
The decay rate in is allowed to depend on
is allowed to depend on  (see the beginning of section 5).
(see the beginning of section 5).
7 January, 2018 at 6:10 pm
Anonymous
I am sorry, but I am concerned with the beginning of the proof of Theorem 12. There it is but not $o_k(1)$. I don’t know how the independence on
but not $o_k(1)$. I don’t know how the independence on  disappears, since
disappears, since  could be very large when
could be very large when  is large. Could you please have a check? Thanks!
is large. Could you please have a check? Thanks!
15 January, 2018 at 3:21 am
Anonymous
Dear Terry,
In this post, you used the argument multiple times that
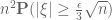
 due to the existence of
due to the existence of  . But Markov inequality will only give us
. But Markov inequality will only give us  which is canceled by
which is canceled by 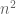 ahead. Do we need
ahead. Do we need 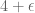 -th moment here? Or do I miss something?
-th moment here? Or do I miss something?
goes to 0 when
Best,
Jeffrey
15 January, 2018 at 1:22 pm
Terence Tao
Apply dominated convergence to the random variables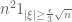 , which are pointwise dominated by
, which are pointwise dominated by 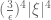 .
.
4 October, 2018 at 12:09 pm
Drew Brady
Is Prop 7 correct? I.e., Your argument shows that , where the norm on the right hand side is the Euclidean norm on
, where the norm on the right hand side is the Euclidean norm on 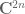 . Don’t you need, however that
. Don’t you need, however that 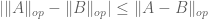 , in order for this argument to work out?
, in order for this argument to work out?
5 October, 2018 at 2:15 pm
Terence Tao
Yes, but this is immediate from the triangle inequality for the operator norm.
8 January, 2021 at 9:07 am
Tim
I have a question about Exercise 10. It seems that the cycle 1, 2, 1, 3, 1, 4, 1 (4 vertices, 6 edges) is a valid cycle to be counted, but it does not satisfy the condition in Exercise 10?
[Oops, there was an extra condition for the edges, now added. -T.]
14 January, 2021 at 3:08 pm
Anonymous
This is just a thought on the volume packing argument (Lemma 4). Each of the balls of radius centered points of the net accounts for some volume, but this volume in enclosed inside the larger ball of radius
centered points of the net accounts for some volume, but this volume in enclosed inside the larger ball of radius  . So is the upper bound on the cardinality just the ratio of the volume of the larger ball over the volume of a ball of radius
. So is the upper bound on the cardinality just the ratio of the volume of the larger ball over the volume of a ball of radius  ?
?
14 March, 2021 at 1:32 pm
Anonymous
Dear Professor Tao,
Do you know of some recent papers where finer volume packing arguments are used for things such as the operator norm, condition number etc. I was curious to learn more about these arguments.
9 January, 2022 at 12:15 pm
Tom Copeland
Numerous occurrences in analysis, enumerative geometry, combinatorics, probability, and physics of the sequence of double factorials of odd numbers in Remark 31 are noted in https://oeis.org/A001147 and refs therein, as well as associations to other number sequences, such as the Catalans. For the benefit of others, it would be nice to ref this post in the OEIS entry.
15 June, 2022 at 1:36 am
Aurelien
Very minor comment: In Lemma 1 in the RHS, shouldn’t A be squared? (as a result of applying Markov’s inequality)
[Corrected, thanks – T.]
17 March, 2024 at 5:13 pm
Anonymous
Dear Professor Tao,
I am very confused about the bound before weak Bai-Yin theorem, you said that
by the geometric series formula (and the hypothesis ), we can get the following bound, here I have two questions. The first is that the geometric series doesn’t converge here and the bound I get is of the form O(2^kk^O(1)n^0.99k) and I can’t get rid of the 0.49k. The second is I’m not sure how to use the log bound for k. I would appreciate it very much if you could bother to answer it. Thanks a lot!
), we can get the following bound, here I have two questions. The first is that the geometric series doesn’t converge here and the bound I get is of the form O(2^kk^O(1)n^0.99k) and I can’t get rid of the 0.49k. The second is I’m not sure how to use the log bound for k. I would appreciate it very much if you could bother to answer it. Thanks a lot!
30 March, 2024 at 6:22 pm
Anonymous
I’m not sure if I’m following the use of Markov’s inequality in lemma 2.3.1. We have that![E[e^{c|Mx|^{2}}] \leq C^{n}](https://s0.wp.com/latex.php?latex=E%5Be%5E%7Bc%7CMx%7C%5E%7B2%7D%7D%5D+%5Cleq+C%5E%7Bn%7D&bg=ffffff&fg=545454&s=0&c=20201002) . My understanding of the application of Markov’s inequality is as follows:
. My understanding of the application of Markov’s inequality is as follows:
I must be doing something wrong?
31 March, 2024 at 6:25 am
Anonymous
Nevermind, I think the constants are different in the proof and in the statement.
31 March, 2024 at 12:40 pm
Anonymous
Dear Professor Tao,
I’m very confused about the bound before the weak Bai-Yin theorem. You said that by the geometric series formula and , we can get the bound
, we can get the bound  . My question is that the geometric series doesn’t converge here and the bound I get is of the form
. My question is that the geometric series doesn’t converge here and the bound I get is of the form  . I would appreciate it very much if you could bother to answer it. Thanks a lot!
. I would appreciate it very much if you could bother to answer it. Thanks a lot!
[The dominant term here is when , which gives the
, which gives the  bound; the other terms decay at an exponential rate away from this value. -T]
bound; the other terms decay at an exponential rate away from this value. -T]