
Ben Green, Freddie Manners and I have just uploaded to the arXiv our preprint “Sumsets and entropy revisited“. This paper uses entropy methods to attack the Polynomial Freiman-Ruzsa (PFR) conjecture, which we study in the following two forms:
Conjecture 1 (Weak PFR over) Let
be a finite non-empty set whose doubling constant
is at most
. Then there is a subset
of
of density
that has affine dimension
(i.e., it is contained in an affine space of dimension
Conjecture 2 (PFR over) Let
be a non-empty set whose doubling constant
is at most
cosets of a subspace of cardinality at most
.
Our main results are then as follows.
Theorem 3 If, then
- (i) There is a subset
- (ii) There is a subset
of affine dimension
goes to zero as
).
- (iii) If Conjecture 2 holds, then there is a subset
The skew-dimension of a set is a quantity smaller than the affine dimension which is defined recursively; the precise definition is given in the paper, but suffice to say that singleton sets have dimension 
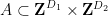
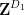
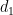
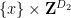
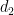


Part (i) of this theorem was implicitly proven by Pálvölgi and Zhelezov by a different method. Part (ii) with 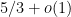

Our proof strategy is to establish these combinatorial additive combinatorics results by using entropic additive combinatorics, in which we replace sets 
For instance, the analogue of the combinatorial doubling constant 
![\displaystyle \sigma_{\mathrm{ent}}[X] := {\exp( \bf H}(X_1+X_2) - {\bf H}(X) )](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csigma_%7B%5Cmathrm%7Bent%7D%7D%5BX%5D+%3A%3D+%7B%5Cexp%28+%5Cbf+H%7D%28X_1%2BX_2%29+-+%7B%5Cbf+H%7D%28X%29+%29&bg=ffffff&fg=000000&s=0&c=20201002) in , where
in , where 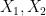 are independent copies of and
are independent copies of and 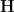 denotes Shannon entropy. There is also an analogue of the Ruzsa distance
denotes Shannon entropy. There is also an analogue of the Ruzsa distance 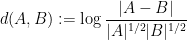
 of , namely the entropic Ruzsa distance
of , namely the entropic Ruzsa distance 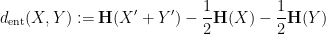
 are independent copies of
are independent copies of  respectively. (Actually, one thing we show in our paper is that the independence hypothesis can be dropped, and this only affects the entropic Ruzsa distance by a factor of three at worst.) Many of the results about sumsets and Ruzsa distance have entropic analogues, but the entropic versions are slightly better behaved; for instance, we have a contraction property
respectively. (Actually, one thing we show in our paper is that the independence hypothesis can be dropped, and this only affects the entropic Ruzsa distance by a factor of three at worst.) Many of the results about sumsets and Ruzsa distance have entropic analogues, but the entropic versions are slightly better behaved; for instance, we have a contraction property 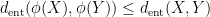
 is a homomorphism. In fact we have a refinement of this inequality in which the gap between these two quantities can be used to control the entropic distance between “fibers” of (in which one conditions
is a homomorphism. In fact we have a refinement of this inequality in which the gap between these two quantities can be used to control the entropic distance between “fibers” of (in which one conditions 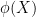 and
and 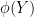 to be fixed). On the other hand, there are direct connections between the combinatorial and entropic sumset quantities. For instance, if
to be fixed). On the other hand, there are direct connections between the combinatorial and entropic sumset quantities. For instance, if 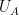 is a random variable drawn uniformly from , then
is a random variable drawn uniformly from , then ![\displaystyle \sigma_{\mathrm{ent}}[U_A] \leq \sigma[A].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csigma_%7B%5Cmathrm%7Bent%7D%7D%5BU_A%5D+%5Cleq+%5Csigma%5BA%5D.&bg=ffffff&fg=000000&s=0&c=20201002) has small doubling, then has small entropic doubling. In the converse direction, if has small entropic doubling, then is close (in entropic Ruzsa distance) to a uniform random variable
has small doubling, then has small entropic doubling. In the converse direction, if has small entropic doubling, then is close (in entropic Ruzsa distance) to a uniform random variable 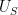 drawn from a set
drawn from a set  of small doubling; a version of this statement was proven in an old paper of myself, but we establish here a quantitatively efficient version, established by rewriting the entropic Ruzsa distance in terms of certain Kullback-Liebler divergences.
of small doubling; a version of this statement was proven in an old paper of myself, but we establish here a quantitatively efficient version, established by rewriting the entropic Ruzsa distance in terms of certain Kullback-Liebler divergences.
Our first main result is a “99% inverse theorem” for entropic Ruzsa distance: if 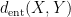


We now sketch how these tools are used to prove our main theorem. For (i), we reduce matters to establishing the following bilinear entropic analogue: given two non-empty finite subsets 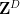
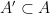
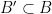
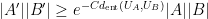
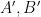 have skew-dimension at most
have skew-dimension at most  , for some absolute constant
, for some absolute constant  . This can be shown by an induction on
. This can be shown by an induction on 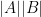 (say). One applies a non-trivial coordinate projection
(say). One applies a non-trivial coordinate projection 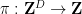 to . If
to . If 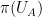 and
and 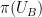 are very close in entropic Ruzsa distance, then the 99% inverse theorem shows that these random variables must each concentrate at a point (because
are very close in entropic Ruzsa distance, then the 99% inverse theorem shows that these random variables must each concentrate at a point (because  has no non-trivial finite subgroups), and can pass to a fiber of these points and use the induction hypothesis. If instead and are far apart, then by the behavior of entropy under projections one can show that the fibers of and
has no non-trivial finite subgroups), and can pass to a fiber of these points and use the induction hypothesis. If instead and are far apart, then by the behavior of entropy under projections one can show that the fibers of and  under
under  are closer on average in entropic Ruzsa distance of and themselves, and one can again proceed using the induction hypothesis.
are closer on average in entropic Ruzsa distance of and themselves, and one can again proceed using the induction hypothesis.
For parts (ii) and (iii), we first use an entropic version of an observation of Manners that sets of small doubling in
 take values in a torsion-free abelian group such as ; this turns out to follow from two applications of the entropy submodularity inequality. One corollary of this (and the behavior of entropy under projections) is that
take values in a torsion-free abelian group such as ; this turns out to follow from two applications of the entropy submodularity inequality. One corollary of this (and the behavior of entropy under projections) is that  and
and  worlds that is used to prove (ii), (iii): while (iii) relies on the still unproven PFR conjecture over , (ii) uses the unconditional progress on PFR by Konyagin, as detailed in this survey of Sanders. The argument has a similar inductive structure to that used to establish (i) (and if one is willing to replace by then the argument is in fact relatively straightforward and does not need any deep partial results on the PFR).
worlds that is used to prove (ii), (iii): while (iii) relies on the still unproven PFR conjecture over , (ii) uses the unconditional progress on PFR by Konyagin, as detailed in this survey of Sanders. The argument has a similar inductive structure to that used to establish (i) (and if one is willing to replace by then the argument is in fact relatively straightforward and does not need any deep partial results on the PFR).
As one byproduct of our analysis we also obtain an appealing entropic reformulation of Conjecture 2, namely that if
![\displaystyle d_{\mathrm{ent}}(X, U_H) \ll \sigma_{\mathrm{ent}}[X].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++d_%7B%5Cmathrm%7Bent%7D%7D%28X%2C+U_H%29+%5Cll+%5Csigma_%7B%5Cmathrm%7Bent%7D%7D%5BX%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle d_{\mathrm{ent}}(X, U_H) \ll_\varepsilon \sigma_{\mathrm{ent}}[X] + \sigma_{\mathrm{ent}}^{3+\varepsilon}[X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++d_%7B%5Cmathrm%7Bent%7D%7D%28X%2C+U_H%29+%5Cll_%5Cvarepsilon+%5Csigma_%7B%5Cmathrm%7Bent%7D%7D%5BX%5D+%2B+%5Csigma_%7B%5Cmathrm%7Bent%7D%7D%5E%7B3%2B%5Cvarepsilon%7D%5BX%5D&bg=ffffff&fg=000000&s=0&c=20201002)
 , by using Konyagin’s partial result towards the PFR.
, by using Konyagin’s partial result towards the PFR.

13 comments
Comments feed for this article
28 June, 2023 at 11:19 am
Anonymous
Is there a conjectured value for the best exponent in theorem 3(ii) (instead of 5/3)?
29 June, 2023 at 2:06 pm
Terence Tao
The conjectured exponent is 1 (this is Conjecture 1).
29 June, 2023 at 8:47 am
Joe
In Theorem 3 (iii),’There’ should be typed in lowercase.
[Corrected, thanks – T.]
2 July, 2023 at 9:54 am
Gil Kalai
I find it surprising and remarkable that a result over Z can be derived from a similar result over Z/2Z. Terry, can you elaborate more on how it works?
2 July, 2023 at 12:49 pm
Terence Tao
For simplicity I will describe the argument in combinatorial language rather than entropic language, although the combinatorial argument doesn’t quite work as stated and one has to move to the entropy formulation to make everything go through. (Also to make the inductive argument close properly one has to work with a “bilinear” formulation in which one has two sets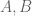 to induct on rather than a single set
to induct on rather than a single set  , but I will ignore this complication.)
, but I will ignore this complication.)
The first key observation is a remarkable observation of Manners that says, roughly speaking, that if a subset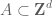 has small doubling, then
has small doubling, then  is also close (in Ruzsa distance) to the dilate
is also close (in Ruzsa distance) to the dilate 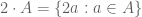 (which already strongly hints at the low dimensionality of a large portion of
(which already strongly hints at the low dimensionality of a large portion of  , but does not yet establish it). This comes from the inequality
, but does not yet establish it). This comes from the inequality 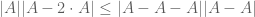 which is proven by a double counting argument similar to the one used to prove the Ruzsa triangle inequality
which is proven by a double counting argument similar to the one used to prove the Ruzsa triangle inequality  (the point being that because of the identity
(the point being that because of the identity 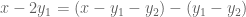 , every element of
, every element of 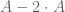 generates
generates  distinct pairs in
distinct pairs in 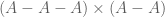 ).
).
If we project the integer lattice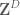 down to the finite field vector space
down to the finite field vector space 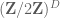 , then the dilate
, then the dilate 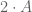 gets sent to 0. As a consequence, we see that the projection of
gets sent to 0. As a consequence, we see that the projection of  to
to 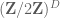 has to be quite small; also, since
has to be quite small; also, since  has small doubling, the projection has small doubling also. From this and the known progress on PFR, one can relate the projection of
has small doubling, the projection has small doubling also. From this and the known progress on PFR, one can relate the projection of  efficiently to a low dimensional subspace of
efficiently to a low dimensional subspace of 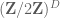 , whose inverse images are sublattices of
, whose inverse images are sublattices of 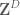 . If
. If  is much larger than the dimension of this subspace, one can (in the entropic setting) use this to locate a coset of this sublattice inside of which
is much larger than the dimension of this subspace, one can (in the entropic setting) use this to locate a coset of this sublattice inside of which  is still quite large, and has better doubling properties than the original set
is still quite large, and has better doubling properties than the original set  . An induction on the dimension
. An induction on the dimension  then lets one close the argument.
then lets one close the argument.
27 July, 2023 at 12:53 pm
CSperson
Why do you use the phrase “query complexity”?
29 July, 2023 at 11:09 am
Terence Tao
The terminology was first introduced to this context by Zhelezov and Pálvölgyi (see page 3 for the explanation).
31 July, 2023 at 6:19 am
CSperson
May be should be called ‘generalized decision tree complexity’ or something along those lines. Someone might know better on the analogy here.
10 October, 2023 at 9:52 am
Anonymous
It would be interesting to have an analog for Theorem 3 (i) for $F_2^n$. Possibly it may have some connections to the log rank conjecture in computer science?
10 October, 2023 at 2:14 pm
Terence Tao
We were actually able to get some sort of analogue in finite fields using these entropic methods, but it was really weird and we didn’t find a good use for it (or a clean statement). Roughly speaking, it is similar to 3(i) except that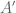 , instead of having query complexity
, instead of having query complexity 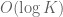 , is instead generated from a point via
, is instead generated from a point via 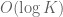 “extension” operations, where an extension from one set
“extension” operations, where an extension from one set 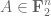 to another
to another 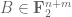 is one of the following three things:
is one of the following three things:
1. Short extension , and
, and  is a subset of
is a subset of 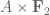 of relative density
of relative density 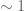 .
.
2. Dense extension. is a subset of
is a subset of 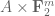 of relative density
of relative density  (say).
(say).
3. Freiman extension. is a graph
is a graph 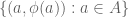 where
where 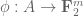 is a “99% Freiman homomorphism”.
is a “99% Freiman homomorphism”.
Of course, we believe the “correct” statement in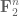 to be the polynomial Freiman-Ruzsa conjecture (Conjecture 2). We have some thoughts on how to improve the current state of the art towards this conjecture, but we don’t see a way to resolve it completely at this point.
to be the polynomial Freiman-Ruzsa conjecture (Conjecture 2). We have some thoughts on how to improve the current state of the art towards this conjecture, but we don’t see a way to resolve it completely at this point.
28 October, 2023 at 8:49 pm
Kaiyi Huang
Hello Terence,
Thanks for your blog post and paper. I am a graduate student recently reading this paper in order to present in a fall school. I find it very accessible and inspiring. However, there are a few questions listed below.
1. In proving the small Ruzsa distance results, the construction of on which the uniform distribution is close to
on which the uniform distribution is close to  induces a Bernoulli random variable
induces a Bernoulli random variable  . Is it a common trick to introduce this
. Is it a common trick to introduce this  ? Can we improve the results in Proposition 1.2 by reducing/removing the
? Can we improve the results in Proposition 1.2 by reducing/removing the 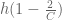 term?
term?
2. The bilinear forms you use in Theorems 7.3 and 9.3 are very different from that of 1.6. How did you come up with the inequality and specifically the functions ?
?
3. Do you have any conjecture on how to further improve Theorem 1.11? Do you think this is the best the entropic method can achieve with a function similar to Theorem 9.3?
Theorem 9.3?
4. What are some future directions? Do we have to come up with some statement different from Theorem 1.11 to attack the conjectures?
4. In the proof of 1.4 in Section 4, I think all the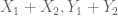 should be replaced by
should be replaced by  , respectively. Of course, this typo does not affect the results.
, respectively. Of course, this typo does not affect the results.
Thanks for reading the questions.
1 November, 2023 at 4:49 pm
Terence Tao
We did not try too strenuously to optimize the arguments, and it is very plausible that by applying entropy inequalities in a slightly different way one could get superior results. Introducing a boolean variable such as to restrict to a “good” event (or to the complementary “exceptional” event) in order to access facts that are available conditioning to that event, is a common trick in this subject.
to restrict to a “good” event (or to the complementary “exceptional” event) in order to access facts that are available conditioning to that event, is a common trick in this subject.
In these sorts of iterative arguments, the bounding functions is usually not known in advance – one first works out what the inductive step gives, which in this case is some assertion of the form “if
is usually not known in advance – one first works out what the inductive step gives, which in this case is some assertion of the form “if 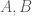 have a certain entropy distance
have a certain entropy distance 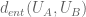 , then I can find some better pair
, then I can find some better pair 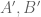 obeying one of several possible improved bounds”, and then one has to hunt for a clean choice of function
obeying one of several possible improved bounds”, and then one has to hunt for a clean choice of function  for which the inductive step will close properly. This often takes some trial and error, especially if the inductive step does not produce a single bound, but rather a disjunction of several possible bounds. Usually one has to explore a few iterations of the inductive step to get a feel of how the bounds might grow in order to propose a guess for
for which the inductive step will close properly. This often takes some trial and error, especially if the inductive step does not produce a single bound, but rather a disjunction of several possible bounds. Usually one has to explore a few iterations of the inductive step to get a feel of how the bounds might grow in order to propose a guess for  , try to close the induction for that
, try to close the induction for that  , and tweak the choice if it didn’t quite work.
, and tweak the choice if it didn’t quite work.
We have a forthcoming paper (with Timothy Gowers) with some significant improvements to the results. Will hopefully be able to report more on this soon. (We will also correct the typos in Section 4 in the next revision of the ms.)
13 November, 2023 at 9:41 am
On a conjecture of Marton | What's new
[…] constant at most is unclear (and perhaps even false). However, it turns out (as discussed in this recent paper of myself with Green and Manners) that things are much better. Here, the analogue of a subset in is a random variable taking […]