
Jon Bennett and I have just uploaded to the arXiv our paper “Adjoint Brascamp-Lieb inequalities“. In this paper, we observe that the family of multilinear inequalities known as the Brascamp-Lieb inequalities (or Holder-Brascamp-Lieb inequalities) admit an adjoint formulation, and explore the theory of these adjoint inequalities and some of their consequences.
To motivate matters let us review the classical theory of adjoints for linear operators. If one has a bounded linear operator 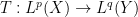

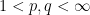
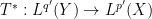

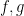
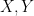
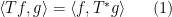
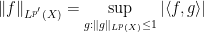
 (and similarly for
(and similarly for  ), one can show that
), one can show that  has the same operator norm as
has the same operator norm as  .
.
There is a slightly different way to proceed using Hölder’s inequality. For sake of exposition let us make the simplifying assumption that 

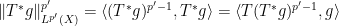
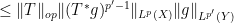
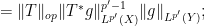
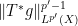 we obtain
we obtain  , and a similar argument also recovers the reverse inequality.
, and a similar argument also recovers the reverse inequality.
The first argument also extends to some extent to multilinear operators. For instance if one has a bounded bilinear operator 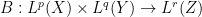

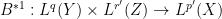
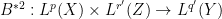

 . It is also possible, formally at least, to adapt the Hölder inequality argument to reach the same conclusion.
. It is also possible, formally at least, to adapt the Hölder inequality argument to reach the same conclusion.
In this paper we observe that the Hölder inequality argument can be modified in the case of Brascamp-Lieb inequalities to obtain a different type of adjoint inequality. (Continuous) Brascamp-Lieb inequalities take the form

 and surjective linear maps
and surjective linear maps 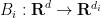 , where
, where 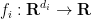 are arbitrary non-negative measurable functions and
are arbitrary non-negative measurable functions and  is the best constant for which this inequality holds for all such
is the best constant for which this inequality holds for all such  . [There is also another inequality involving variances with respect to log-concave distributions that is also due to Brascamp and Lieb, but it is not related to the inequalities discussed here.] Well known examples of such inequalities include Hölder’s inequality and the sharp Young convolution inequality; another is the Loomis-Whitney inequality, the first non-trivial example of which is
. [There is also another inequality involving variances with respect to log-concave distributions that is also due to Brascamp and Lieb, but it is not related to the inequalities discussed here.] Well known examples of such inequalities include Hölder’s inequality and the sharp Young convolution inequality; another is the Loomis-Whitney inequality, the first non-trivial example of which is 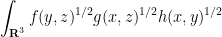

 . There are also discrete analogues of these inequalities, in which the Euclidean spaces
. There are also discrete analogues of these inequalities, in which the Euclidean spaces 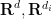 are replaced by discrete abelian groups, and the surjective linear maps
are replaced by discrete abelian groups, and the surjective linear maps  are replaced by discrete homomorphisms.
are replaced by discrete homomorphisms.
The operation 
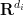

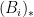
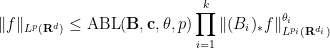
 and various exponents
and various exponents  , where
, where 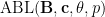 is the optimal constant for which the above inequality holds for all such
is the optimal constant for which the above inequality holds for all such  ; informally, such inequalities control the
; informally, such inequalities control the  norm of a non-negative function in terms of its marginals. It turns out that every Brascamp-Lieb inequality generates a family of adjoint Brascamp-Lieb inequalities (with the exponent
norm of a non-negative function in terms of its marginals. It turns out that every Brascamp-Lieb inequality generates a family of adjoint Brascamp-Lieb inequalities (with the exponent  being less than or equal to
being less than or equal to  ). For instance, the adjoints of the Loomis-Whitney inequality (2) are the inequalities
). For instance, the adjoints of the Loomis-Whitney inequality (2) are the inequalities 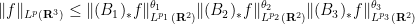
 , all
, all  summing to , and all
summing to , and all 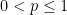 , where the
, where the 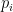 exponents are defined by the formula
exponents are defined by the formula 
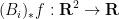 are the marginals of :
are the marginals of : 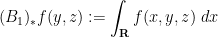
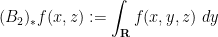
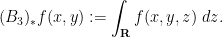
One can derive these adjoint Brascamp-Lieb inequalities from their forward counterparts by a version of the Hölder inequality argument mentioned previously, in conjunction with the observation that the pushforward maps 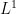
We have located a modest number of applications of the adjoint Brascamp-Lieb inequality (but hope that there will be more in the future):
- The inequalities become equalities at
; taking a derivative at this value (in the spirit of the replica trick in physics) we recover the entropic Brascamp-Lieb inequalities of Carlen and Cordero-Erausquin. For instance, the derivative of the adjoint Loomis-Whitney inequalities at
- The adjoint Loomis-Whitney inequalities, together with a few more applications of Hölder’s inequality, implies the log-concavity of the Gowers uniformity norms on non-negative functions, which was previously observed by Shkredov and by Manners.
- Averaging the adjoint Loomis-Whitney inequalities over coordinate systems gives reverse
norms or entropies of the
-plane transform in
are chosen in a dimensionally consistent fashion).
We also record a number of variants of the adjoint Brascamp-Lieb inequalities, including discrete variants, and a reverse inequality involving 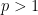

12 comments
Comments feed for this article
30 June, 2023 at 3:59 am
adj
amazing adjoints
30 June, 2023 at 8:03 am
Anonymous
Hi Terry. Love your blog. I want to ask though, why are you linking to mathscinet papers? That severely limits accessibility.
1 July, 2023 at 12:49 pm
Terence Tao
This appears to be a recent change on mathscinet’s end. I would be open to suggestions for alternatives (in particular, a comparison with Zentralblatt or with doi).
30 June, 2023 at 11:36 am
Anonymous
Is it true that whenever the adjoint and forward constants are the same (in some sense indicating “no loss of information”) than the adjoint inequalities are also optimized by gaussians?
1 July, 2023 at 12:47 pm
Terence Tao
Actually, we found that in all non-degenerate cases that gaussians do *not* extremize the adjoint inequality; see Theorem 6.1. For instance, the adjoint Loomis-Whitney inequality is not optimized by gaussians, but instead by indicator functions of boxes (or more generally, Cartesian products ). This is despite the Loomis-Whitney inequality being optimized by gaussians (and with no loss in passing back and forth between the forward and adjoint inequalities). What seems to be going on here is that in order for gaussians to be good test functions for the forward inequality, the
). This is despite the Loomis-Whitney inequality being optimized by gaussians (and with no loss in passing back and forth between the forward and adjoint inequalities). What seems to be going on here is that in order for gaussians to be good test functions for the forward inequality, the  gaussians
gaussians  have to be related to each other in a very specific way; but for the adjoint inequality there is only one input
have to be related to each other in a very specific way; but for the adjoint inequality there is only one input  and the dual functions
and the dual functions  associated to that input are unlikely to obey this specific relation even if
associated to that input are unlikely to obey this specific relation even if  is gaussian.
is gaussian.
For the discrete analogues of these inequalities the situation is different; for both the forward and adjoint inequalities, indicator functions of subspaces serve as extremizers (Theorem 1.14).
2 July, 2023 at 9:11 am
s
Splundiferous
4 July, 2023 at 4:56 am
XG
Great results! Small thing: in the early derivation right after “Then for any reasonable function”, I think that one should replace q by p’.
6 July, 2023 at 1:46 pm
Quadratini Loacker
A small typo: Cordero-Erausquin instead of Cordero-Erasquin.
[Corrected, thanks – T.]
8 July, 2023 at 3:51 am
Tom Courtade
Unless I’m mistaken, a simple observation is that the adjoint BL inequality can be restated in terms of Rényi entropies, in a way that parallels the Cordero–Erausquin dual formulation of the BL inequalities. Namely, for a random vector with density
with density  , the adjoint BL inequality is equivalently restated as
, the adjoint BL inequality is equivalently restated as
for a suitable constant , where $h_p$ denotes the Rényi entropy of order
, where $h_p$ denotes the Rényi entropy of order  . As
. As  tends to Shannon entropy as
tends to Shannon entropy as  , the connection to the Cordero–Erausquin entropic formulation of BL is fairly transparent.
, the connection to the Cordero–Erausquin entropic formulation of BL is fairly transparent.
This rewriting of the adjoint BL inequality also suggests what other “reverse” formulations of the adjoint BL inequality might look like (Question 10.8 in your paper), since we know their dual entropic formulations. For instance, just based on pattern matching, one might conjecture the analogue to Barthe’s inequality would look something like this: For random vectors on
random vectors on  , do we have
, do we have
where the sup is over all couplings of the ‘s? Taking
‘s? Taking  would recover Barthe’s inequality.
would recover Barthe’s inequality.
10 July, 2023 at 2:12 pm
Terence Tao
Nice observation! We will add this to the next revision of the ms.
20 July, 2023 at 10:16 am
JojoPizza
Terence tao We need you in the field of Geometric complexity theory. Please contribute your time to advance this important field.
5 August, 2023 at 2:22 pm
Paul Pritchard
Small typo: “various” should be “variants” in the last sentence.
[Corrected, thanks – T.]