
Let 

![{H[X]}](https://s0.wp.com/latex.php?latex=%7BH%5BX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle H[X] = -\sum_{s \in S} {\bf P}[X = s] \log {\bf P}[X = s].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+H%5BX%5D+%3D+-%5Csum_%7Bs+%5Cin+S%7D+%7B%5Cbf+P%7D%5BX+%3D+s%5D+%5Clog+%7B%5Cbf+P%7D%5BX+%3D+s%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
Lemma 1 (Gibbs variational formula) Letbe a function. Then
![\displaystyle \log \sum_{s \in S} \exp(f(s)) = \sup_X {\bf E} f(X) + {\bf H}[X]. \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clog+%5Csum_%7Bs+%5Cin+S%7D+%5Cexp%28f%28s%29%29+%3D+%5Csup_X+%7B%5Cbf+E%7D+f%28X%29+%2B+%7B%5Cbf+H%7D%5BX%5D.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: Note that shifting 



![\displaystyle 0 = \sup_X \sum_{s \in S} {\bf P}[X = s] \log {\bf P}[Y = s] -\sum_{s \in S} {\bf P}[X = s] \log {\bf P}[X = s].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++0+%3D+%5Csup_X+%5Csum_%7Bs+%5Cin+S%7D+%7B%5Cbf+P%7D%5BX+%3D+s%5D+%5Clog+%7B%5Cbf+P%7D%5BY+%3D+s%5D+-%5Csum_%7Bs+%5Cin+S%7D+%7B%5Cbf+P%7D%5BX+%3D+s%5D+%5Clog+%7B%5Cbf+P%7D%5BX+%3D+s%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
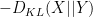 , where
, where 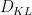 denotes Kullback-Leibler divergence. One can also interpret this inequality as a special case of the Fenchel–Young inequality relating the conjugate convex functions
denotes Kullback-Leibler divergence. One can also interpret this inequality as a special case of the Fenchel–Young inequality relating the conjugate convex functions  and
and  .)
.) 
In this note I would like to use this variational formula (which is also known as the Donsker-Varadhan variational formula) to give another proof of the following inequality of Carbery.
Theorem 2 (Generalized Cauchy-Schwarz inequality) Let, let
be finite non-empty sets, and let
be functions for each
. Let
and
be positive functions for each
where
is the quantity
where
is the set of all tuples
such that
for
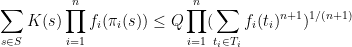

Thus for instance, the identity is trivial for 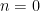

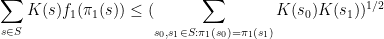

 the inequality reads
the inequality reads 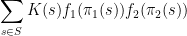
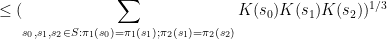

 , the existing proofs require the “tensor power trick” in order to reduce to the case when the
, the existing proofs require the “tensor power trick” in order to reduce to the case when the  are step functions (in which case the inequality can be proven elementarily, as discussed in the above paper of Carbery).
are step functions (in which case the inequality can be proven elementarily, as discussed in the above paper of Carbery).
We now prove this inequality. We write 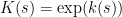
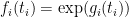

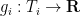
![\displaystyle \sup_X {\bf E} k(X) + \sum_{i=1}^n g_i(\pi_i(X)) + {\bf H}[X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_X+%7B%5Cbf+E%7D+k%28X%29+%2B+%5Csum_%7Bi%3D1%7D%5En+g_i%28%5Cpi_i%28X%29%29+%2B+%7B%5Cbf+H%7D%5BX%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \leq \frac{1}{n+1} \sup_{(X_0,\dots,X_n)} {\bf E} k(X_0)+\dots+k(X_n) + {\bf H}[X_0,\dots,X_n]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cleq+%5Cfrac%7B1%7D%7Bn%2B1%7D+%5Csup_%7B%28X_0%2C%5Cdots%2CX_n%29%7D+%7B%5Cbf+E%7D+k%28X_0%29%2B%5Cdots%2Bk%28X_n%29+%2B+%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_n%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle + \frac{1}{n+1} \sum_{i=1}^n \sup_{Y_i} (n+1) {\bf E} g_i(Y_i) + {\bf H}[Y_i]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%2B+%5Cfrac%7B1%7D%7Bn%2B1%7D+%5Csum_%7Bi%3D1%7D%5En+%5Csup_%7BY_i%7D+%28n%2B1%29+%7B%5Cbf+E%7D+g_i%28Y_i%29+%2B+%7B%5Cbf+H%7D%5BY_i%5D&bg=ffffff&fg=000000&s=0&c=20201002) ranges over random variables taking values in ,
ranges over random variables taking values in ,  range over tuples of random variables taking values in , and
range over tuples of random variables taking values in , and 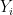 range over random variables taking values in
range over random variables taking values in 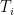 . Comparing the suprema, the claim now reduces to
. Comparing the suprema, the claim now reduces to
Lemma 3 (Conditional expectation computation) Let, where each
has the same distribution as
![\displaystyle {\bf H}[X_0,\dots,X_n] = (n+1) {\bf H}[X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_n%5D+%3D+%28n%2B1%29+%7B%5Cbf+H%7D%5BX%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle - {\bf H}[\pi_1(X)] - \dots - {\bf H}[\pi_n(X)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+-+%7B%5Cbf+H%7D%5B%5Cpi_1%28X%29%5D+-+%5Cdots+-+%7B%5Cbf+H%7D%5B%5Cpi_n%28X%29%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: We induct on 



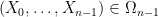
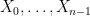
![\displaystyle {\bf H}[X_0,\dots,X_{n-1}] = n {\bf H}[X] - {\bf H}[\pi_1(X)] - \dots - {\bf H}[\pi_{n-1}(X)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%5D+%3D+n+%7B%5Cbf+H%7D%5BX%5D+-+%7B%5Cbf+H%7D%5B%5Cpi_1%28X%29%5D+-+%5Cdots+-+%7B%5Cbf+H%7D%5B%5Cpi_%7Bn-1%7D%28X%29%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
 has the same distribution as
has the same distribution as 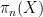 . For each value
. For each value 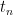 attained by , we can take conditionally independent copies of
attained by , we can take conditionally independent copies of  and conditioned to the events
and conditioned to the events 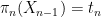 and
and 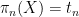 respectively, and then concatenate them to form a tuple in , with
respectively, and then concatenate them to form a tuple in , with 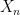 a further copy of that is conditionally independent of relative to
a further copy of that is conditionally independent of relative to  . One can the use the entropy chain rule to compute
. One can the use the entropy chain rule to compute ![\displaystyle {\bf H}[X_0,\dots,X_n] = {\bf H}[\pi_n(X_n)] + {\bf H}[X_0,\dots,X_n| \pi_n(X_n)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_n%5D+%3D+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_n%29%5D+%2B+%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_n%7C+%5Cpi_n%28X_n%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = {\bf H}[\pi_n(X_n)] + {\bf H}[X_0,\dots,X_{n-1}| \pi_n(X_n)] + {\bf H}[X_n| \pi_n(X_n)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_n%29%5D+%2B+%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%7C+%5Cpi_n%28X_n%29%5D+%2B+%7B%5Cbf+H%7D%5BX_n%7C+%5Cpi_n%28X_n%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = {\bf H}[\pi_n(X)] + {\bf H}[X_0,\dots,X_{n-1}| \pi_n(X_{n-1})] + {\bf H}[X_n| \pi_n(X_n)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D+%7B%5Cbf+H%7D%5B%5Cpi_n%28X%29%5D+%2B+%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%7C+%5Cpi_n%28X_%7Bn-1%7D%29%5D+%2B+%7B%5Cbf+H%7D%5BX_n%7C+%5Cpi_n%28X_n%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = {\bf H}[\pi_n(X)] + ({\bf H}[X_0,\dots,X_{n-1}] - {\bf H}[\pi_n(X_{n-1})])](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D+%7B%5Cbf+H%7D%5B%5Cpi_n%28X%29%5D+%2B+%28%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%5D+-+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_%7Bn-1%7D%29%5D%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle + ({\bf H}[X_n] - {\bf H}[\pi_n(X_n)])](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%2B+%28%7B%5Cbf+H%7D%5BX_n%5D+-+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_n%29%5D%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle ={\bf H}[X_0,\dots,X_{n-1}] + {\bf H}[X_n] - {\bf H}[\pi_n(X_n)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%5D+%2B+%7B%5Cbf+H%7D%5BX_n%5D+-+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_n%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
With a little more effort, one can replace

30 comments
Comments feed for this article
11 December, 2023 at 1:04 pm
Anonymous
Thanks Prof Tao for this useful information. A new inequality might be the key to solving some difficult problems. Dr. Hayes
11 December, 2023 at 8:46 pm
Anonymous
“Kullback-Leibler divergence” is the correct spelling.
[Corrected, thanks – T.]
11 December, 2023 at 8:48 pm
Anonymous
Note: The comment software does not appear to allow for any identification of the commenter, but just prints the disembodied comment and attributes it to “Anonymous”.
I hope this can be fixed soon.
12 December, 2023 at 10:34 am
Anonymous
It won’t be fixed. It’s the new feature.
13 December, 2023 at 12:48 am
Anonymous
Who the f*ck is Anonymous????? … Terry Tao you might as well rename your blog to that of your gutless faceless proof-reader who persists in correcting every single tiny little unimportant spelling mistake for the simple reason of totally dominating this world renowned blog with his petulant presence … my name is Jenda Vondra and I’m from Australia and we Aussies can only take so much crap!
8 February, 2024 at 1:16 pm
Anonymous
What the heck bro 😭
12 December, 2023 at 12:40 am
Anonymous
We’re going to need a bigger number.
12 December, 2023 at 10:32 am
Anonymous
Yes, much bigger.
17 December, 2023 at 12:31 pm
Anonymous
even bigger than that
12 December, 2023 at 3:31 am
Tony Carbery
Thanks Terry, it’s great to see this inequality in a wider context!
12 December, 2023 at 7:45 am
Terence Tao
Now I remember where I saw this trick before – it appears in this paper of Carlen and Cordero-Erasquin in which they demonstrate using the Gibbs variational formula that the Brascamp-Lieb inequality is equivalent to an entropy version of that inequality. As the above example demonstrates, this equivalence extends to a more general class of inequalities than the classical Brascamp-Lieb inequalities (in that paper, for instance, they also note that it applies to spherical analogues of that inequality).
12 December, 2023 at 9:01 am
Anonymous
Is this apropos of anything? Does it have anything to do with the proof of PFR, beyond “this is an inequality about entropy that should be more widely known”?
12 December, 2023 at 10:36 am
Anonymous
Why does it have to be apropos of anything?
14 December, 2023 at 6:17 pm
Anonymous
In this comment, Prof. Tao read a paper about this inequality and decided to write a blog post.
15 December, 2023 at 6:00 pm
YahyaAA1
“… the inequality can be rewritten as …”
Surely, at this point, we have an equation, rather than an inequality? That’s what the “=” sign means usually. Unless, of course, it has a different meaning in the calc. of variations …
25 December, 2023 at 4:08 pm
Jose Alvarado
Thank you, Prof. Tao, for sharing this interesting approach.
I apologize if the validity of the following comment seems obvious, but it appears that we can deduce (from the proof of Lemma 3) a similar lemma with extra flexibility. The statement is as follows:
“
![\mathbf{H}[X',Y'] = \mathbf{H}[X'] + \mathbf{H}[Y'] - \mathbf{H}[g(Y')].](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BH%7D%5BX%27%2CY%27%5D+%3D+%5Cmathbf%7BH%7D%5BX%27%5D+%2B+%5Cmathbf%7BH%7D%5BY%27%5D+-+%5Cmathbf%7BH%7D%5Bg%28Y%27%29%5D.&bg=ffffff&fg=545454&s=0&c=20201002) ”
”
Does that make sense?
26 December, 2023 at 4:32 pm
Terence Tao
I think one may need a hypothesis that and
and  have the same distribution in order to reach this conclusion. (For instance, if
have the same distribution in order to reach this conclusion. (For instance, if  and
and  take completely disjoint values, then
take completely disjoint values, then  is empty and the claim cannot hold.)
is empty and the claim cannot hold.)
26 December, 2023 at 7:57 pm
JoseDAlvarado
Oops… Of course, you are right! It is imperative to add a hypothesis concerning the random variables and
and  . Thanks for the clarification :)
. Thanks for the clarification :)
11 January, 2024 at 8:33 am
Joseph Malkoun
I have a small comment. If you have, say, only 2 real random variables, say and
and  , and you have
, and you have  data points
data points  in the
in the 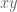 -plane, for
-plane, for  , one can, say, form the
, one can, say, form the  matrix
matrix  containing
containing  as its
as its  -th column. In order to talk about the sample covariance matrix of
-th column. In order to talk about the sample covariance matrix of  and
and  , one could of course follow the probability definition, but it also can be viewed geometrically in 2 steps: removing the mean value of
, one could of course follow the probability definition, but it also can be viewed geometrically in 2 steps: removing the mean value of  from
from  , for example, corresponds to orthogonal projection onto the orthogonal complement of
, for example, corresponds to orthogonal projection onto the orthogonal complement of  (
( components) in
components) in  . The covariance matrix is then the Gram matrix of the orthogonal projections (as in my previous sentence) of the 2 rows of
. The covariance matrix is then the Gram matrix of the orthogonal projections (as in my previous sentence) of the 2 rows of  .
.
Thus, in some sense, the language of probability is dual to the language of geometry. It is a bit like deciding whether to look at as
as  points in
points in 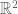 , or as
, or as 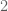 points in
points in  , which are of course dual points of view.
, which are of course dual points of view.
My remark is trivial, and of course known, but I wonder if it can be, or perhaps has been already made into a systematic transform/duality.
26 January, 2024 at 10:26 am
shannon7774
This looks a bit like reflection-positivity, maybe just because that uses Cauchy-Schwarz. Is there a quantum analogue, if you replace expectations with respect to measures by states, and replace random variables by self adjoint operators?
1 March, 2024 at 5:22 am
Jas, the Physicist
Yes.
8 February, 2024 at 2:44 am
Anonymous
Sir please explain the sphere emersion , I kindly request to you, thanking you sir with huge respect
8 February, 2024 at 1:15 pm
Anonymous
Our of context but, how would the Gibbs variational formula work for measure theoretic entropy? I don’t see it anywhere properly defined anyway except this blog
20 February, 2024 at 1:51 pm
Anonymous
Hey big bro you have to contribute to mathstackexchange the poor kids are trying to learn
24 April, 2024 at 11:00 am
Anonymous
Lmao yes nationalize math education
21 February, 2024 at 6:44 am
T Retsu
In the proof of Lemma 1, the inequality can be rewritten as:
There isn’t any in the
in the  .
.
[Actually, the identity was correct as originally written: note that![\textbf{P}[Y=s]](https://s0.wp.com/latex.php?latex=%5Ctextbf%7BP%7D%5BY%3Ds%5D&bg=ffffff&fg=545454&s=0&c=20201002) is equal to
is equal to  -T.]
-T.]
24 March, 2024 at 9:11 pm
Anonymous
Many thanks for the answer. It is correct. Lemma 1 is proven.
A question about the terminology:
convex conjugate
instead of “conjugate convex”
26 February, 2024 at 1:02 am
Anonymous
Dear prof. Tao,
Do you know in what regards these generalized inequalities could be lifted to infinite (perhaps uncountable sets S)?
7 March, 2024 at 6:05 pm
Anonymous
Thank you Prof Tao for working on cybersecurity for the federal government, I can’t wait to see your new work on lie algebra and prime numbers.
11 April, 2024 at 1:32 pm
Anonymous
“working for the federal government” aka being a slave of the state