
You are currently browsing the tag archive for the ‘free probability’ tag.
Suppose we have an 


where 
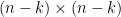





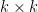


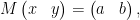
where 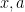
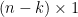




Using the invertibility of
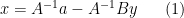
and substituting this into the second equation yields
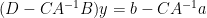
and thus (assuming that 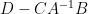

and then inserting this back into (1) gives

Comparing this with
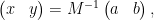
we have managed to express the inverse of

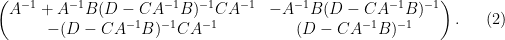
One can consider the inverse problem: given the inverse 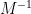
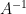


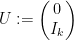
(with 


Then for any scalar 

and hence by (2)
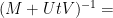

noting that the inverses here will exist for 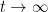
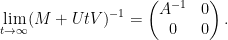
On the other hand, by the Woodbury matrix identity (discussed in this previous blog post), we have
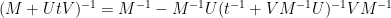
and hence on taking limits and comparing with the preceding identity, one has

This achieves the aim of expressing the inverse

In the 

where 
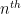
We can apply this identity to understand how the spectrum of an 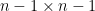

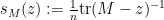

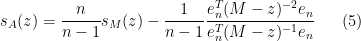
At this point we begin to proceed informally. Assume for sake of argument that the random matrix 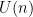


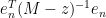
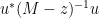

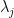
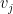

One can think of 



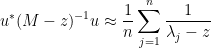
and thus

(that is to say, the diagonal entries of 
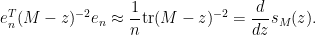
Inserting this into (5) and discarding terms of size 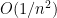

This can be viewed as a difference equation for the Stieltjes transform of top left minors of 

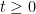

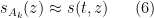
where 

with initial data 
Example 1 If
of the identity, then
. One checks that
is a steady state solution to (7), which is unsurprising given that all minors of
times the identity.
Example 2 If
, then by the semi-circular law (see previous notes) one has
(using an appropriate branch of the square root). One can then verify the self-similar solution
to (7), which is consistent with the fact that a top
when
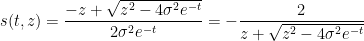
One can justify the approximation (6) given a sufficiently good well-posedness theory for the equation (7). We will not do so here, but will note that (as with the classical inviscid Burgers equation) the equation can be solved exactly (formally, at least) by the method of characteristics. For any initial position 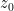

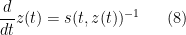
with initial data 

and thus 

and thus (7) may be solved implicitly via the equation
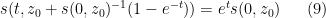
for all
Remark 3 In practice, the equation (9) may stop working when
crosses the real axis, as (7) does not necessarily hold in this region. It is a cute exercise (ultimately coming from the Cauchy-Schwarz inequality) to show that this crossing always happens, for instance if
necessarily has negative or zero imaginary part.
Example 4 Suppose we have
as in Example 1. Then (9) becomes
for any
, which after making the change of variables
becomes
as in Example 1.
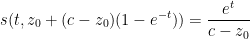
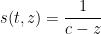
Example 5 Suppose we have
as in Example 2. Then (9) becomes
If we write
one can calculate that
and hence
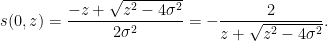
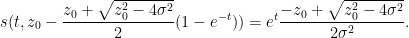

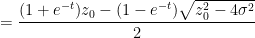
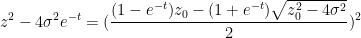
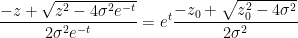

One can recover the spectral measure 

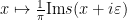


In this informal notation, we have for instance that

which can be interpreted as the fact that the Cauchy distributions 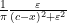
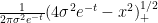
If we let 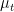


![{(0,1]}](https://s0.wp.com/latex.php?latex=%7B%280%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

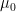
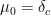



thus at height 
![{[-2\sigma \sqrt{\alpha}, 2\sigma \sqrt{\alpha}]}](https://s0.wp.com/latex.php?latex=%7B%5B-2%5Csigma+%5Csqrt%7B%5Calpha%7D%2C+2%5Csigma+%5Csqrt%7B%5Calpha%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
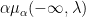


An interesting example of such a limiting Gelfand-Tsetlin pattern occurs when 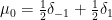
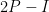


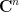
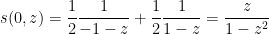
and so (9) in this case becomes
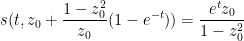
A tedious calculation then gives the solution
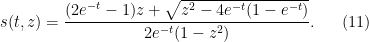
For 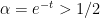

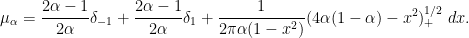
This reflects the interlacing property, which forces 
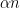



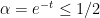
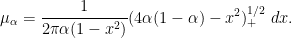
For 

There is presumably a direct geometric explanation of this fact (basically describing the singular values of the product of two random orthogonal projections to half-dimensional subspaces of
The evolution of 



for all 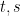
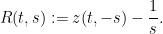
The equation (9) may be rewritten as
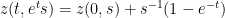
and hence


See these previous notes for a discussion of free probability topics such as the
Example 6 If
.
Example 7 If
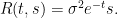
Example 8 If

This simple relationship (12) is essentially due to Nica and Speicher (thanks to Dima Shylakhtenko for this reference). It has the remarkable consequence that when 



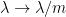
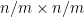

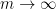

In a similar vein, if one defines the function
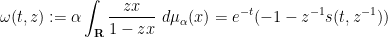
and inverts it to obtain a function 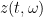
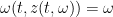
for all 
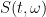
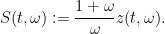
Writing

for any

and so (9) becomes
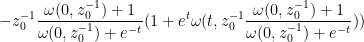

which simplifies to
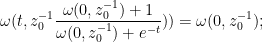
replacing 

and thus
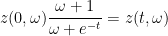
and hence
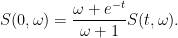
One can compute 
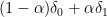



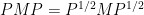
In the foundations of modern probability, as laid out by Kolmogorov, the basic objects of study are constructed in the following order:
- Firstly, one selects a sample space
, whose elements
represent all the possible states that one’s stochastic system could be in.
- Then, one selects a
-algebra
of events
(modeled by subsets of
in a countably additive manner, so that the entire sample space has probability
.
- Finally, one builds (commutative) algebras of random variables
(such as complex-valued random variables, modeled by measurable functions from
), and (assuming suitable integrability or moment conditions) one can assign expectations
to each such random variable.
In measure theory, the underlying measure space
However, it is possible to take the abstraction process one step further, and view the algebra of random variables and their expectations as being the foundational concept, and ignoring both the presence of the original sample space, the algebra of events, or the probability measure.
There are two reasons for wanting to shed (or abstract away) these previously foundational structures. Firstly, it allows one to more easily take certain types of limits, such as the large
Secondly, this abstract formalism allows one to generalise the classical, commutative theory of probability to the more general theory of non-commutative probability theory, which does not have a classical underlying sample space or event space, but is instead built upon a (possibly) non-commutative algebra of random variables (or “observables”) and their expectations (or “traces”). This more general formalism not only encompasses classical probability, but also spectral theory (with matrices or operators taking the role of random variables, and the trace taking the role of expectation), random matrix theory (which can be viewed as a natural blend of classical probability and spectral theory), and quantum mechanics (with physical observables taking the role of random variables, and their expected value on a given quantum state being the expectation). It is also part of a more general “non-commutative way of thinking” (of which non-commutative geometry is the most prominent example), in which a space is understood primarily in terms of the ring or algebra of functions (or function-like objects, such as sections of bundles) placed on top of that space, and then the space itself is largely abstracted away in order to allow the algebraic structures to become less commutative. In short, the idea is to make algebra the foundation of the theory, as opposed to other possible choices of foundations such as sets, measures, categories, etc..
[Note that this foundational preference is to some extent a metamathematical one rather than a mathematical one; in many cases it is possible to rewrite the theory in a mathematically equivalent form so that some other mathematical structure becomes designated as the foundational one, much as probability theory can be equivalently formulated as the measure theory of probability measures. However, this does not negate the fact that a different choice of foundations can lead to a different way of thinking about the subject, and thus to ask a different set of questions and to discover a different set of proofs and solutions. Thus it is often of value to understand multiple foundational perspectives at once, to get a truly stereoscopic view of the subject.]
It turns out that non-commutative probability can be modeled using operator algebras such as 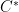
When one generalises the set of structures in one’s theory, for instance from the commutative setting to the non-commutative setting, the notion of what it means for a structure to be “universal”, “free”, or “independent” can change. The most familiar example of this comes from group theory. If one restricts attention to the category of abelian groups, then the “freest” object one can generate from two generators 
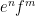
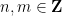
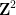
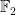
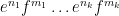

Similarly, when generalising classical probability theory to non-commutative probability theory, the notion of what it means for two or more random variables to be independent changes. In the classical (commutative) setting, two (bounded, real-valued) random variables 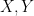
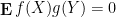
whenever 
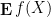
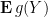
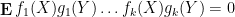
whenever 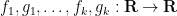
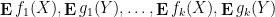
The concept of free independence was introduced by Voiculescu, and its study is now known as the subject of free probability. We will not attempt a systematic survey of this subject here; for this, we refer the reader to the surveys of Speicher and of Biane. Instead, we shall just discuss a small number of topics in this area to give the flavour of the subject only.
The significance of free probability to random matrix theory lies in the fundamental observation that random matrices which are independent in the classical sense, also tend to be independent in the free probability sense, in the large
Much as free groups are in some sense “maximally non-commutative”, freely independent random variables are about as far from being commuting as possible. For instance, if 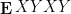
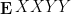

Another important (and closely related) analogy is that while the distribution of sums of independent commutative random variables can be quickly computed via the characteristic function (i.e. the Fourier transform of the distribution), the distribution of sums of freely independent non-commutative random variables can be quickly computed using the Stieltjes transform instead (or with closely related objects, such as the
As mentioned earlier, free probability is an excellent tool for computing various expressions of interest in random matrix theory, such as asymptotic values of normalised moments in the large 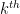



Recent Comments