
You are currently browsing the tag archive for the ‘law of large numbers’ tag.
One of the major activities in probability theory is studying the various statistics that can be produced from a complex system with many components. One of the simplest possible systems one can consider is a finite sequence 
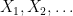

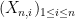

The first fundamental result about these sums is the law of large numbers (or LLN for short), which comes in two formulations, weak (WLLN) and strong (SLLN). To state these laws, we first must define the notion of convergence in probability.
Definition 1 Let
be a sequence of random variables taking values in a separable metric space
(e.g. the
or
), and let
be another random variable taking values in
. We say that
, one has
as
. Thus, if
are scalar, we have
as
The measure-theoretic analogue of convergence in probability is convergence in measure.
It is instructive to compare the notion of convergence in probability with almost sure convergence. it is easy to see that 


We have the following easy relationships between convergence in probability and almost sure convergence:
Exercise 2 Let
- (i) If
almost surely, show that
- (ii) Suppose that
for all
- (iii) If
of the
almost surely.
- (iv) If
are absolutely integrable and
as
- (v) (Urysohn subsequence principle) Suppose that every subsequence
that converges to
- (vi) Does the Urysohn subsequence principle still hold if “in probability” is replaced with “almost surely” throughout?
- (vii) If
or
is continuous, show that
converges in probability to
. More generally, if for each
,
is a sequence of scalar random variables that converge in probability to
, and
or
is continuous, show that
converges in probability to
. (Thus, for instance, if
converge in probability to
respectively, then
and
converge in probability to
and
respectively.
- (viii) (Fatou’s lemma for convergence in probability) If
.
- (ix) (Dominated convergence in probability) If
for all
and some absolutely integrable
converges to
.
Exercise 3 Let
- (i) Suppose that there is a random variable
. Show that
- (ii) Suppose that the
such that
almost surely).
We can now state the weak and strong law of large numbers, in the model case of iid random variables.
Theorem 4 (Law of large numbers, model case) Let
be an iid sequence of copies of an absolutely integrable random variable
, and for each natural number
denote the random variable
.
- (i) (Weak law of large numbers) The random variables
converge in probability to
.
- (ii) (Strong law of large numbers) The random variables
Informally: if 
It is instructive to compare the law of large numbers with what one can obtain from the Kolmogorov zero-one law, discussed in Notes 2. Observe that if the 





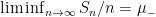

The law of large numbers asserts, roughly speaking, that the theoretical expectation 
There are several ways to prove the law of large numbers (in both forms). One basic strategy is to use the moment method – controlling statistics such as 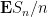

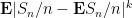


For the strong law of large numbers, one can also use methods relating to the theory of martingales, such as stopping time arguments and maximal inequalities; we present some classical arguments of Kolmogorov in this regard.
Read the rest of this entry »
Let X be a real-valued random variable, and let 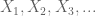
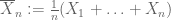
Weak law of large numbers. Suppose that the first moment
of X is finite. Then
converges in probability to
, thus
for every
.
Strong law of large numbers. Suppose that the first moment
.
[The concepts of convergence in probability and almost sure convergence in probability theory are specialisations of the concepts of convergence in measure and pointwise convergence almost everywhere in measure theory.]
(If one strengthens the first moment assumption to that of finiteness of the second moment 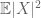
The weak law is easy to prove, but the strong law (which of course implies the weak law, by Egoroff’s theorem) is more subtle, and in fact the proof of this law (assuming just finiteness of the first moment) usually only appears in advanced graduate texts. So I thought I would present a proof here of both laws, which proceeds by the standard techniques of the moment method and truncation. The emphasis in this exposition will be on motivation and methods rather than brevity and strength of results; there do exist proofs of the strong law in the literature that have been compressed down to the size of one page or less, but this is not my goal here.

Recent Comments