
You are currently browsing the tag archive for the ‘von Mangoldt function’ tag.
Kaisa Matomäki, Xuancheng Shao, Joni Teräväinen, and myself have just uploaded to the arXiv our preprint “Higher uniformity of arithmetic functions in short intervals I. All intervals“. This paper investigates the higher order (Gowers) uniformity of standard arithmetic functions in analytic number theory (and specifically, the Möbius function 

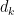
![{(X,X+H]}](https://s0.wp.com/latex.php?latex=%7B%28X%2CX%2BH%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


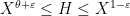
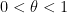

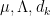
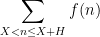
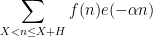
 , where
, where 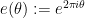 . For applications in the additive combinatorics of such functions , it is also necessary to consider more general correlations, such as polynomial correlations
. For applications in the additive combinatorics of such functions , it is also necessary to consider more general correlations, such as polynomial correlations 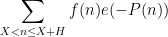
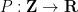 is a polynomial of some fixed degree, or more generally
is a polynomial of some fixed degree, or more generally 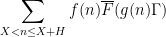
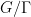 is a nilmanifold of fixed degree and dimension (and with some control on structure constants),
is a nilmanifold of fixed degree and dimension (and with some control on structure constants), 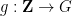 is a polynomial map, and
is a polynomial map, and  is a Lipschitz function (with some bound on the Lipschitz constant). Indeed, thanks to the inverse theorem for the Gowers uniformity norm, such correlations let one control the Gowers uniformity norm of (possibly after subtracting off some renormalising factor) on such short intervals , which can in turn be used to control other multilinear correlations involving such functions.
is a Lipschitz function (with some bound on the Lipschitz constant). Indeed, thanks to the inverse theorem for the Gowers uniformity norm, such correlations let one control the Gowers uniformity norm of (possibly after subtracting off some renormalising factor) on such short intervals , which can in turn be used to control other multilinear correlations involving such functions.
Traditionally, asymptotics for such sums are expressed in terms of a “main term” of some arithmetic nature, plus an error term that is estimated in magnitude. For instance, a sum such as 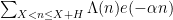
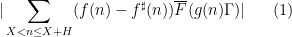
 variable to be restricted further to a subprogression of , but let us ignore this minor extension for this discussion). There is some flexibility in how to choose these approximants, but we eventually found it convenient to use the following choices.
variable to be restricted further to a subprogression of , but let us ignore this minor extension for this discussion). There is some flexibility in how to choose these approximants, but we eventually found it convenient to use the following choices.
- For the Möbius function
, as per the Möbius pseudorandomness conjecture. (One could choose a more sophisticated approximant in the presence of a Siegel zero, as I did with Joni in this recent paper, but we do not do so here.)
- For the von Mangoldt function
, where
and
.
- For the divisor functions
for some explicit polynomials
, chosen so that
and
The objective is then to obtain bounds on sums such as (1) that improve upon the “trivial bound” that one can get with the triangle inequality and standard number theory bounds such as the Brun-Titchmarsh inequality. For 


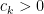

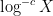

Our main estimates on sums of the form (1) work in the following ranges:
- For
, one can obtain strongly logarithmic savings on (1) for
, and power savings for
.
- For
, one can obtain weakly logarithmic savings for
.
- For
, one can obtain power savings for
.
- For
, one can obtain power savings for
.
Conjecturally, one should be able to obtain power savings in all cases, and lower 
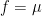
By combining these results with tools from additive combinatorics, one can obtain a number of applications:
- Direct insertion of our bounds in the recent work of Kanigowski, Lemanczyk, and Radziwill on the prime number theorem on dynamical systems that are analytic skew products gives some improvements in the exponents there.
- We can obtain a “short interval” version of a multiple ergodic theorem along primes established by Frantzikinakis-Host-Kra and Wooley-Ziegler, in which we average over intervals of the form
.
- We can obtain a “short interval” version of the “linear equations in primes” asymptotics obtained by Ben Green, Tamar Ziegler, and myself in this sequence of papers, where the variables in these equations lie in short intervals
We now briefly discuss some of the ingredients of proof of our main results. The first step is standard, using combinatorial decompositions (based on the Heath-Brown identity and (for the 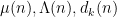
- Type
sums, which are basically of the form
for some weights
of controlled size and some cutoff
that is not too large;
- Type
sums, which are basically of the form
for some weights
of controlled size and some cutoffs
that are not too close to
or to
- Type
sums, which are basically of the form
for some weights
The precise ranges of the cutoffs 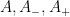
The Type
For the Type 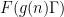
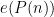


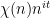



 range in various dyadic intervals. Using the known multidimensional equidistribution theory of polynomial maps in nilmanifolds, one can eventually show in the non-abelian case that this sequence either has enough equidistribution to give cancellation, or else the nilsequence involved can be replaced with one from a lower dimensional nilmanifold, in which case one can apply an induction hypothesis.
range in various dyadic intervals. Using the known multidimensional equidistribution theory of polynomial maps in nilmanifolds, one can eventually show in the non-abelian case that this sequence either has enough equidistribution to give cancellation, or else the nilsequence involved can be replaced with one from a lower dimensional nilmanifold, in which case one can apply an induction hypothesis.
For the type
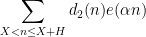

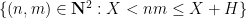 into a number of arithmetic progressions, and then uses equidistribution theory to establish cancellation of sequences such as
into a number of arithmetic progressions, and then uses equidistribution theory to establish cancellation of sequences such as  on the majority of these progressions. As it turns out, this strategy works well in the regime
on the majority of these progressions. As it turns out, this strategy works well in the regime 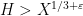 unless the nilsequence involved is “major arc”, but the latter case is treatable by existing methods as discussed previously; this is why the exponent for our
unless the nilsequence involved is “major arc”, but the latter case is treatable by existing methods as discussed previously; this is why the exponent for our 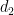 result can be as low as
result can be as low as  .
.
In a sequel to this paper (currently in preparation), we will obtain analogous results for almost all intervals ![{(x,x+H]}](https://s0.wp.com/latex.php?latex=%7B%28x%2Cx%2BH%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{[X,2X]}](https://s0.wp.com/latex.php?latex=%7B%5BX%2C2X%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Joni Teräväinen and myself have just uploaded to the arXiv our preprint “Quantitative bounds for Gowers uniformity of the Möbius and von Mangoldt functions“. This paper makes quantitative the Gowers uniformity estimates on the Möbius function
To discuss the results we first discuss the situation of the Möbius function, which is technically simpler in some (though not all) ways. We assume familiarity with Gowers norms and standard notations around these norms, such as the averaging notation ![{\mathop{\bf E}_{n \in [N]}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
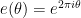
![\displaystyle \mathop{\bf E}_{n \in [N]} \mu(n) = o(1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmu%28n%29+%3D+o%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
 . With Vinogradov-Korobov error term, the prime number theorem is strengthened to
. With Vinogradov-Korobov error term, the prime number theorem is strengthened to ![\displaystyle \mathop{\bf E}_{n \in [N]} \mu(n) \ll \exp( - c \log^{3/5} N (\log \log N)^{-1/5} );](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmu%28n%29+%5Cll+%5Cexp%28+-+c+%5Clog%5E%7B3%2F5%7D+N+%28%5Clog+%5Clog+N%29%5E%7B-1%2F5%7D+%29%3B&bg=ffffff&fg=000000&s=0&c=20201002)
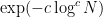 type factors) as pseudopolynomial decay. Equivalently, we obtain pseudopolynomial decay of Gowers
type factors) as pseudopolynomial decay. Equivalently, we obtain pseudopolynomial decay of Gowers 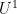 seminorm of :
seminorm of : ![\displaystyle \| \mu \|_{U^1([N])} \ll \exp( - c \log^{3/5} N (\log \log N)^{-1/5} ).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5E1%28%5BN%5D%29%7D+%5Cll+%5Cexp%28+-+c+%5Clog%5E%7B3%2F5%7D+N+%28%5Clog+%5Clog+N%29%5E%7B-1%2F5%7D+%29.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \mu \|_{U^1([N])} \ll_\varepsilon N^{-1/2+\varepsilon}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5E1%28%5BN%5D%29%7D+%5Cll_%5Cvarepsilon+N%5E%7B-1%2F2%2B%5Cvarepsilon%7D&bg=ffffff&fg=000000&s=0&c=20201002)
 .
.
Once one restricts to arithmetic progressions, the situation gets worse: the Siegel-Walfisz theorem gives the bound
![\displaystyle \| \mu 1_{a \hbox{ mod } q}\|_{U^1([N])} \ll_A \log^{-A} N \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+1_%7Ba+%5Chbox%7B+mod+%7D+q%7D%5C%7C_%7BU%5E1%28%5BN%5D%29%7D+%5Cll_A+%5Clog%5E%7B-A%7D+N+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
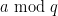 and any , but with the catch that the implied constant is ineffective in . This ineffectivity cannot be removed without further progress on the notorious Siegel zero problem.
and any , but with the catch that the implied constant is ineffective in . This ineffectivity cannot be removed without further progress on the notorious Siegel zero problem.
In 1937, Davenport was able to show the discorrelation estimate
![\displaystyle \mathop{\bf E}_{n \in [N]} \mu(n) e(-\alpha n) \ll_A \log^{-A} N](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmu%28n%29+e%28-%5Calpha+n%29+%5Cll_A+%5Clog%5E%7B-A%7D+N&bg=ffffff&fg=000000&s=0&c=20201002) uniformly in
uniformly in  , which leads (by standard Fourier arguments) to the Fourier uniformity estimate
, which leads (by standard Fourier arguments) to the Fourier uniformity estimate ![\displaystyle \| \mu \|_{U^2([N])} \ll_A \log^{-A} N.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5E2%28%5BN%5D%29%7D+%5Cll_A+%5Clog%5E%7B-A%7D+N.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \mu \|_{U^2([N])} \ll \log^{-c} N \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5E2%28%5BN%5D%29%7D+%5Cll+%5Clog%5E%7B-c%7D+N+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002) .
.
For the situation with the 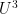
![\displaystyle \mathop{\bf E}_{n \in [N]} \mu(n) \overline{F}(g(n) \Gamma) \ll_{A,F,G/\Gamma} \log^{-A} N \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmu%28n%29+%5Coverline%7BF%7D%28g%28n%29+%5CGamma%29+%5Cll_%7BA%2CF%2CG%2F%5CGamma%7D+%5Clog%5E%7B-A%7D+N+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002) , any degree two (filtered) nilmanifold , any polynomial sequence , and any Lipschitz function ; again, the implied constants are ineffective. On the other hand, in a separate paper of Ben Green and myself, we established the following inverse theorem: if for instance we knew that
, any degree two (filtered) nilmanifold , any polynomial sequence , and any Lipschitz function ; again, the implied constants are ineffective. On the other hand, in a separate paper of Ben Green and myself, we established the following inverse theorem: if for instance we knew that ![\displaystyle \| \mu \|_{U^3([N])} \geq \delta](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5E3%28%5BN%5D%29%7D+%5Cgeq+%5Cdelta&bg=ffffff&fg=000000&s=0&c=20201002)
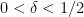 , then there exists a degree two nilmanifold of dimension
, then there exists a degree two nilmanifold of dimension 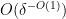 , complexity , a polynomial sequence , and Lipschitz function of Lipschitz constant
, complexity , a polynomial sequence , and Lipschitz function of Lipschitz constant 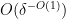 such that
such that ![\displaystyle \mathop{\bf E}_{n \in [N]} \mu(n) \overline{F}(g(n) \Gamma) \gg \exp(-\delta^{-O(1)}).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmu%28n%29+%5Coverline%7BF%7D%28g%28n%29+%5CGamma%29+%5Cgg+%5Cexp%28-%5Cdelta%5E%7B-O%281%29%7D%29.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \mu \|_{U^3([N])} = o(1).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5E3%28%5BN%5D%29%7D+%3D+o%281%29.&bg=ffffff&fg=000000&s=0&c=20201002)
 produced by this argument is completely ineffective: obtaining a bound on when this quantity dips below a given threshold
produced by this argument is completely ineffective: obtaining a bound on when this quantity dips below a given threshold  depends on the implied constant in (3) for some whose dimension depends on , and the dependence on obtained in this fashion is ineffective in the face of a Siegel zero.
depends on the implied constant in (3) for some whose dimension depends on , and the dependence on obtained in this fashion is ineffective in the face of a Siegel zero.
For higher norms 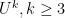

![\displaystyle \| \mu \|_{U^k([N])} \geq \delta](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5Ek%28%5BN%5D%29%7D+%5Cgeq+%5Cdelta&bg=ffffff&fg=000000&s=0&c=20201002)
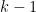 nilmanifold of dimension , complexity
nilmanifold of dimension , complexity 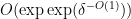 , a polynomial sequence , and Lipschitz function of Lipschitz constant
, a polynomial sequence , and Lipschitz function of Lipschitz constant 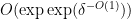 such that
such that ![\displaystyle \mathop{\bf E}_{n \in [N]} \mu(n) \overline{F}(g(n) \Gamma) \gg \exp\exp(-\delta^{-O(1)}).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmu%28n%29+%5Coverline%7BF%7D%28g%28n%29+%5CGamma%29+%5Cgg+%5Cexp%5Cexp%28-%5Cdelta%5E%7B-O%281%29%7D%29.&bg=ffffff&fg=000000&s=0&c=20201002)
 .) Meanwhile, the bound (3) was extended to arbitrary nilmanifolds by Ben and myself. Again, the two results when concatenated give the qualitative decay
.) Meanwhile, the bound (3) was extended to arbitrary nilmanifolds by Ben and myself. Again, the two results when concatenated give the qualitative decay ![\displaystyle \| \mu \|_{U^k([N])} = o(1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+%5C%7C_%7BU%5Ek%28%5BN%5D%29%7D+%3D+o%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
Our first result gives an effective decay bound:
Theorem 1 For any, we have
for some
This is off by a logarithm from the best effective bound (2) in the 
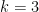
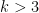
We have analogues of all the above results for the von Mangoldt function 
![\displaystyle \| \Lambda - 1 \|_{U^1([N])} \ll \exp( - c \log^{3/5} N (\log \log N)^{-1/5} )](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5CLambda+-+1+%5C%7C_%7BU%5E1%28%5BN%5D%29%7D+%5Cll+%5Cexp%28+-+c+%5Clog%5E%7B3%2F5%7D+N+%28%5Clog+%5Clog+N%29%5E%7B-1%2F5%7D+%29&bg=ffffff&fg=000000&s=0&c=20201002)
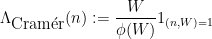
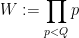
 is the quasipolynomial quantity
is the quasipolynomial quantity 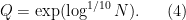
![\displaystyle \mathop{\bf E}_{n \in [N]} (\Lambda - \Lambda_{\hbox{Cram\'er}}(n)) e(-\alpha n) \ll_A \log^{-A} N](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%28%5CLambda+-+%5CLambda_%7B%5Chbox%7BCram%5C%27er%7D%7D%28n%29%29+e%28-%5Calpha+n%29+%5Cll_A+%5Clog%5E%7B-A%7D+N&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \Lambda - \Lambda_{\hbox{Cram\'er}}\|_{U^2([N])} \ll_A \log^{-A} N](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5CLambda+-+%5CLambda_%7B%5Chbox%7BCram%5C%27er%7D%7D%5C%7C_%7BU%5E2%28%5BN%5D%29%7D+%5Cll_A+%5Clog%5E%7B-A%7D+N&bg=ffffff&fg=000000&s=0&c=20201002) and (with an ineffective dependence on ), again regaining effectivity if is replaced by a sufficiently small constant . All the previously stated discorrelation and Gowers uniformity results for then have analogues for , and our main result is similarly analogous:
and (with an ineffective dependence on ), again regaining effectivity if is replaced by a sufficiently small constant . All the previously stated discorrelation and Gowers uniformity results for then have analogues for , and our main result is similarly analogous:
Theorem 2 For anyfor some
By standard methods, this result also gives quantitative asymptotics for counting solutions to various systems of linear equations in primes, with error terms that gain a factor of 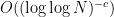
We now discuss the methods of proof, focusing first on the case of the Möbius function. Suppose first that there is no “Siegel zero”, by which we mean a quadratic character 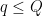
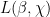

![\displaystyle \| \mu 1_{a \hbox{ mod } q}\|_{U^1([N])} \ll \exp(-\log^c N). \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Cmu+1_%7Ba+%5Chbox%7B+mod+%7D+q%7D%5C%7C_%7BU%5E1%28%5BN%5D%29%7D+%5Cll+%5Cexp%28-%5Clog%5Ec+N%29.+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathop{\bf E}_{n \in [N]} \mu(n) \overline{F}(g(n) \Gamma) \ll \exp(-\log^c N) \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%5Cmu%28n%29+%5Coverline%7BF%7D%28g%28n%29+%5CGamma%29+%5Cll+%5Cexp%28-%5Clog%5Ec+N%29+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002) nilmanifolds of dimension
nilmanifolds of dimension 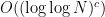 and complexity
and complexity 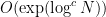 , all polynomial sequences
, all polynomial sequences  , and all Lipschitz functions of norm . If the nilmanifold had bounded dimension, then one could repeat the arguments of Ben and myself more or less verbatim to establish this claim from (5), which relied on the quantitative equidistribution theory on nilmanifolds developed in a separate paper of Ben and myself. Unfortunately, in the latter paper the dependence of the quantitative bounds on the dimension
, and all Lipschitz functions of norm . If the nilmanifold had bounded dimension, then one could repeat the arguments of Ben and myself more or less verbatim to establish this claim from (5), which relied on the quantitative equidistribution theory on nilmanifolds developed in a separate paper of Ben and myself. Unfortunately, in the latter paper the dependence of the quantitative bounds on the dimension  was not explicitly given. In an appendix to the current paper, we go through that paper to account for this dependence, showing that all exponents depend at most doubly exponentially in the dimension , which is barely sufficient to handle the dimension of that arises here.
was not explicitly given. In an appendix to the current paper, we go through that paper to account for this dependence, showing that all exponents depend at most doubly exponentially in the dimension , which is barely sufficient to handle the dimension of that arises here.
Now suppose we have a Siegel zero 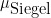
![\displaystyle \| (\mu - \mu_{\hbox{Siegel}}) 1_{a \hbox{ mod } q}\|_{U^1([N])} \ll \exp(-\log^c N) \ \ \ \ \ (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%28%5Cmu+-+%5Cmu_%7B%5Chbox%7BSiegel%7D%7D%29+1_%7Ba+%5Chbox%7B+mod+%7D+q%7D%5C%7C_%7BU%5E1%28%5BN%5D%29%7D+%5Cll+%5Cexp%28-%5Clog%5Ec+N%29+%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=0&c=20201002) . The Siegel approximant to is actually a little bit complicated, and to our knowledge the first appearance of this sort of approximant only appears as late as this 2010 paper of Germán and Katai. Our version of this approximant is defined as the multiplicative function such that
. The Siegel approximant to is actually a little bit complicated, and to our knowledge the first appearance of this sort of approximant only appears as late as this 2010 paper of Germán and Katai. Our version of this approximant is defined as the multiplicative function such that 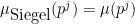
 , and
, and 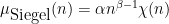 is coprime to all primes
is coprime to all primes 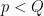 , and is a normalising constant given by the formula
, and is a normalising constant given by the formula 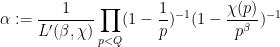
 and plays only a minor role in the analysis). This is a rather complicated formula, but it seems to be virtually the only choice of approximant that allows for bounds such as (7) to hold. (This is the one aspect of the problem where the von Mangoldt theory is simpler than the Möbius theory, as in the former one only needs to work with very rough numbers for which one does not need to make any special accommodations for the behavior at small primes when introducing the Siegel correction term.) With this starting point it is then possible to repeat the analysis of my previous papers with Ben and obtain the pseudopolynomial discorrelation bound
and plays only a minor role in the analysis). This is a rather complicated formula, but it seems to be virtually the only choice of approximant that allows for bounds such as (7) to hold. (This is the one aspect of the problem where the von Mangoldt theory is simpler than the Möbius theory, as in the former one only needs to work with very rough numbers for which one does not need to make any special accommodations for the behavior at small primes when introducing the Siegel correction term.) With this starting point it is then possible to repeat the analysis of my previous papers with Ben and obtain the pseudopolynomial discorrelation bound ![\displaystyle \mathop{\bf E}_{n \in [N]} (\mu - \mu_{\hbox{Siegel}})(n) \overline{F}(g(n) \Gamma) \ll \exp(-\log^c N)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%28%5Cmu+-+%5Cmu_%7B%5Chbox%7BSiegel%7D%7D%29%28n%29+%5Coverline%7BF%7D%28g%28n%29+%5CGamma%29+%5Cll+%5Cexp%28-%5Clog%5Ec+N%29+&bg=ffffff&fg=000000&s=0&c=20201002) as before, which when combined with Manners’ inverse theorem gives the doubly logarithmic bound
as before, which when combined with Manners’ inverse theorem gives the doubly logarithmic bound ![\displaystyle \| \mu - \mu_{\hbox{Siegel}} \|_{U^k([N])} \ll (\log\log N)^{-c_k}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%7C+%5Cmu+-+%5Cmu_%7B%5Chbox%7BSiegel%7D%7D+%5C%7C_%7BU%5Ek%28%5BN%5D%29%7D+%5Cll+%28%5Clog%5Clog+N%29%5E%7B-c_k%7D.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \mu_{\hbox{Siegel}} \|_{U^k([N])} \ll \log^{-c_k} N](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%7C+%5Cmu_%7B%5Chbox%7BSiegel%7D%7D+%5C%7C_%7BU%5Ek%28%5BN%5D%29%7D+%5Cll+%5Clog%5E%7B-c_k%7D+N&bg=ffffff&fg=000000&s=0&c=20201002) seems to play a rather essential component in the proof, even if it is absent in the final statement. We note that this approximant seems to be a useful tool to explore the “illusory world” of the Siegel zero further; see for instance the recent paper of Chinis for some work in this direction.
seems to play a rather essential component in the proof, even if it is absent in the final statement. We note that this approximant seems to be a useful tool to explore the “illusory world” of the Siegel zero further; see for instance the recent paper of Chinis for some work in this direction.
For the analogous problem with the von Mangoldt function (assuming a Siegel zero for sake of discussion), the approximant 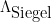
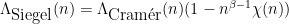
![\displaystyle \| (\Lambda - \Lambda_{\hbox{Siegel}}) 1_{a \hbox{ mod } q}\|_{U^1([N])} \ll \exp(-\log^c N).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%28%5CLambda+-+%5CLambda_%7B%5Chbox%7BSiegel%7D%7D%29+1_%7Ba+%5Chbox%7B+mod+%7D+q%7D%5C%7C_%7BU%5E1%28%5BN%5D%29%7D+%5Cll+%5Cexp%28-%5Clog%5Ec+N%29.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathop{\bf E}_{n \in [N]} (\Lambda - \Lambda_{\hbox{Siegel}})(n) \overline{F}(g(n) \Gamma) \ll \exp(-\log^c N) \ \ \ \ \ (8)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cbf+E%7D_%7Bn+%5Cin+%5BN%5D%7D+%28%5CLambda+-+%5CLambda_%7B%5Chbox%7BSiegel%7D%7D%29%28n%29+%5Coverline%7BF%7D%28g%28n%29+%5CGamma%29+%5Cll+%5Cexp%28-%5Clog%5Ec+N%29+%5C+%5C+%5C+%5C+%5C+%288%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \Lambda_{\hbox{Siegel}} \|_{U^k([N])} \ll \log^{-c_k} N.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%7C+%5CLambda_%7B%5Chbox%7BSiegel%7D%7D+%5C%7C_%7BU%5Ek%28%5BN%5D%29%7D+%5Cll+%5Clog%5E%7B-c_k%7D+N.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \| \Lambda - \Lambda_{\hbox{Siegel}} \|_{U^k([N])} \ll (\log\log N)^{-c_k}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5C%7C+%5CLambda+-+%5CLambda_%7B%5Chbox%7BSiegel%7D%7D+%5C%7C_%7BU%5Ek%28%5BN%5D%29%7D+%5Cll+%28%5Clog%5Clog+N%29%5E%7B-c_k%7D.&bg=ffffff&fg=000000&s=0&c=20201002) and are unbounded. There is a standard tool for getting around this issue, now known as the dense model theorem, which is the standard engine powering the transference principle from theorems about bounded functions to theorems about certain types of unbounded functions. However the quantitative versions of the dense model theorem in the literature are expensive and would basically weaken the doubly logarithmic gain here to a triply logarithmic one. Instead, we bypass the dense model theorem and directly transfer the inverse theorem for bounded functions to an inverse theorem for unbounded functions by using the densification approach to transference introduced by Conlon, Fox, and Zhao. This technique turns out to be quantitatively quite efficient (the dependencies of the main parameters in the transference are polynomial in nature), and also has the technical advantage of avoiding the somewhat tricky “correlation condition” present in early transference results which are also not beneficial for quantitative bounds.
and are unbounded. There is a standard tool for getting around this issue, now known as the dense model theorem, which is the standard engine powering the transference principle from theorems about bounded functions to theorems about certain types of unbounded functions. However the quantitative versions of the dense model theorem in the literature are expensive and would basically weaken the doubly logarithmic gain here to a triply logarithmic one. Instead, we bypass the dense model theorem and directly transfer the inverse theorem for bounded functions to an inverse theorem for unbounded functions by using the densification approach to transference introduced by Conlon, Fox, and Zhao. This technique turns out to be quantitatively quite efficient (the dependencies of the main parameters in the transference are polynomial in nature), and also has the technical advantage of avoiding the somewhat tricky “correlation condition” present in early transference results which are also not beneficial for quantitative bounds.
In principle, the above results can be improved for 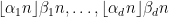
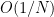
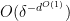
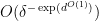
In analytic number theory, an arithmetic function is simply a function 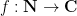




whenever 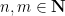


that counts the number of divisors of a natural number 
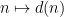
There are various approaches to multiplicative number theory, each of which focuses on different asymptotic statistics of arithmetic functions
- The summatory functions
of an arithmetic function
(if it exists).
- The logarithmic sums
of an arithmetic function
(if it exists).
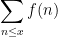


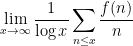
Here, we are normalising the arithmetic function 
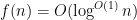

A classical case of interest is when 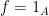
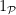
Typically, the logarithmic sums are relatively easy to control, but the summatory functions require more effort in order to obtain satisfactory estimates; see Exercise 6 below.
If an arithmetic function
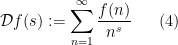
for various real or complex numbers 


In the elementary approach to multiplicative number theory presented in this set of notes, we consider Dirichlet series only for real numbers 
Remark 1 The elementary and complex-analytic approaches to multiplicative number theory are the two classical approaches to the subject. One could also consider a more “Fourier-analytic” approach, in which one studies convolution-type statistics such as
as
for various cutoff functions
, such as smooth, compactly supported functions. See this previous blog post for an instance of such an approach. Another related approach is the “pretentious” approach to multiplicative number theory currently being developed by Granville-Soundararajan and their collaborators. We will occasionally make reference to these more modern approaches in these notes, but will primarily focus on the classical approaches.
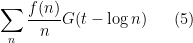
To reverse the process and derive control on summatory functions or logarithmic sums starting from control of Dirichlet series is trickier, and usually requires one to allow
The basic strategy of elementary multiplicative theory is to first gather useful estimates on the statistics of “smooth” or “non-oscillatory” functions, such as the constant function 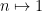
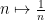

This is only an introduction to elementary multiplicative number theory techniques. More in-depth treatments may be found in this text of Montgomery-Vaughan, or this text of Bateman-Diamond.

Recent Comments