In this final lecture in the Marker lecture series, I discuss the recent work of Bourgain, Gamburd, and Sarnak on how arithmetic combinatorics and expander graphs were used to sieve for almost primes in various algebraic sets.
In previous lectures, we considered the problem of detecting tuples of primes in various linear or convex sets; in particular, we considered the size of sets of the form  , where
, where  is the set of primes, and V is some affine subspace of
is the set of primes, and V is some affine subspace of 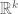 . (For instance, the twin prime conjecture would correspond to the case when k=2 and
. (For instance, the twin prime conjecture would correspond to the case when k=2 and  , while the Green-Tao theorem would correspond to the case
, while the Green-Tao theorem would correspond to the case  . We refer to elements of
. We refer to elements of  as prime points. The prime tuples conjecture implies the following qualitative criterion for when such a set of prime points should be “large”:
as prime points. The prime tuples conjecture implies the following qualitative criterion for when such a set of prime points should be “large”:
Qualitative prime tuples conjecture. Let V be an affine subspace of . Suppose that
- (No obstructions at infinity) For any N,
 affinely spans all of V, where
affinely spans all of V, where  . (In particular, is non-empty.)
. (In particular, is non-empty.)
- (No obstructions at q) For any
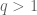 ,
,  affinely spans all of V, where
affinely spans all of V, where  . (In particular, is non-empty.)
. (In particular, is non-empty.)
Then affinely spans all of V. (In particular, V contains at least one prime point.)
Both of the hypotheses in this conjecture are easily verified for any given V, the first by (integer) linear programming and the second by modular arithmetic. This conjecture would imply several other results and conjectures in number theory, including the twin prime conjecture and the Green-Tao theorem. Needless to say, it remains open in general (though the results mentioned in the previous lecture give partial results in the case when V is at least two-dimensional and non-degenerate).
Now we attempt to generalise the above conjecture to the setting in which V is an algebraic variety rather than an affine subspace. (This would cover some famous open problems in number theory, for instance the Landau problem that asks whether there are infinitely many primes of the form 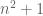 .) The notion of a set affinely spanning V is then naturally replaced by the notion of a set being Zariski dense in V, which means that the set is not contained in any strictly smaller subvariety of V. One could then formulate a naive generalisation of the above conjecture by replacing “affine space” and “affinely spans all of” with “algebraic variety” and “is Zariski dense in” respectively. However, the hypotheses are now no longer easy to verify; indeed, just the problem of determining whether V contains an integer point
.) The notion of a set affinely spanning V is then naturally replaced by the notion of a set being Zariski dense in V, which means that the set is not contained in any strictly smaller subvariety of V. One could then formulate a naive generalisation of the above conjecture by replacing “affine space” and “affinely spans all of” with “algebraic variety” and “is Zariski dense in” respectively. However, the hypotheses are now no longer easy to verify; indeed, just the problem of determining whether V contains an integer point 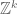 is essentially Hilbert’s tenth problem, which by Matiyasevich’s theorem is known to be undecidable for general V. Indeed, since one can encode any computable set in terms of the integer points of a variety V, it is not too difficult to see that this conjecture fails in general. (An amusing historical connection here: one of the first demonstrations of the undecidability of Hilbert’s tenth problem by Robinson, Davis, and Putnam was conditional on the existence of arbitrarily long progressions of primes (i.e. the Green-Tao theorem), although subsequent proofs did not need this fact.)
is essentially Hilbert’s tenth problem, which by Matiyasevich’s theorem is known to be undecidable for general V. Indeed, since one can encode any computable set in terms of the integer points of a variety V, it is not too difficult to see that this conjecture fails in general. (An amusing historical connection here: one of the first demonstrations of the undecidability of Hilbert’s tenth problem by Robinson, Davis, and Putnam was conditional on the existence of arbitrarily long progressions of primes (i.e. the Green-Tao theorem), although subsequent proofs did not need this fact.)
Since arbitrary algebraic varieties are far too general to have any hope of a reasonable theory, one should look for prime points in much more special sets. An important class here is that of an orbit  in , where b is some vector in and
in , where b is some vector in and  is some finitely generated subgroup of
is some finitely generated subgroup of  . (One can also consider the slightly more general set of images
. (One can also consider the slightly more general set of images  under a polynomial map, but for simplicity let us stick to just orbits.) Of course one should take b to be primitive (not a multiple of any smaller vector), since one clearly will have a difficult time finding prime points in otherwise.
under a polynomial map, but for simplicity let us stick to just orbits.) Of course one should take b to be primitive (not a multiple of any smaller vector), since one clearly will have a difficult time finding prime points in otherwise.
The orbit will be Zariski dense in some algebraic variety V, and is clearly a collection of integer points (though it may not cover all of  ). Assuming no local obstructions at infinity or at q (which means that
). Assuming no local obstructions at infinity or at q (which means that  and
and  are Zariski dense in V), one could then conjecture that
are Zariski dense in V), one could then conjecture that  is also Zariski dense in V (which, if V is infinite, would in particular imply that the orbit contains infinitely many prime points).
is also Zariski dense in V (which, if V is infinite, would in particular imply that the orbit contains infinitely many prime points).
For simplicity let us restrict attention to the two-dimensional case k=2, which is already highly non-trivial; Bourgain, Gamburd and Sarnak have recently begun to get some preliminary results in k=3 but I will not discuss them here. Thus is now a finitely generated subgroup of 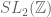 . If this subgroup is elementary – e.g. if it is cyclic – then the orbit can be exponentially sparse (a ball of radius R may only contain
. If this subgroup is elementary – e.g. if it is cyclic – then the orbit can be exponentially sparse (a ball of radius R may only contain  points), and it becomes extremely difficult to do any sieving or primality detection. (In this case, the problem becomes comparable to such notoriously difficult questions as whether there are infinitely many Mersenne primes.) It thus makes sense to restrict attention to non-elementary subgroups of – groups which contain a copy of the free non-abelian group on two generators, or equivalently any group whose Zariski closure is all of
points), and it becomes extremely difficult to do any sieving or primality detection. (In this case, the problem becomes comparable to such notoriously difficult questions as whether there are infinitely many Mersenne primes.) It thus makes sense to restrict attention to non-elementary subgroups of – groups which contain a copy of the free non-abelian group on two generators, or equivalently any group whose Zariski closure is all of 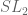 (or equivalently yet again, a group whose limit set consists of more than one point). In this situation, Bourgain, Gamburd, and Sarnak conjectured:
(or equivalently yet again, a group whose limit set consists of more than one point). In this situation, Bourgain, Gamburd, and Sarnak conjectured:
Conjecture 2. Let be a non-elementary subgroup of , and let b be a primitive element of 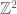 . Suppose that there are no local obstructions at infinity or at finite places q. Then
. Suppose that there are no local obstructions at infinity or at finite places q. Then  is Zariski dense in the plane (in particular, is infinite).
is Zariski dense in the plane (in particular, is infinite).
This conjecture remains open. However, as in the linear situation, one can make progress if one replaces primes with almost primes – products of at most r primes for some bounded r. (There are certainly prior results for nonlinear patterns in the almost primes; for instance, it is a famous result of Iwaniec that there are infinitely many numbers of the form that are the product of at most two primes.) In particular, Bourgain, Gamburd, and Sarnak were able to show
Theorem. Let  be as in Conjecture 2. Then there exists an r such that
be as in Conjecture 2. Then there exists an r such that  is Zariski dense in the plane, where
is Zariski dense in the plane, where  is the set of numbers that are the product of at most r primes.
is the set of numbers that are the product of at most r primes.
Several further generalisations and extensions of this result, with a similar flavour, are known, but will not be discussed here. There are a number of amusing special cases of these results, for instance one can show that there exist infinitely many Appollonian circle packings of the unit circle by four other mutually tangent circles, all of whose radii is the reciprocal of an almost prime, or infinitely many Pythagorean triples whose area is an almost prime (for a sufficiently large r in the definition of “almost prime”).
Let me now discuss some of the key ideas in the proof of this theorem. One begins by rephrasing the question in a more quantitative (or finitary) manner. In the linear case, this would be done by counting the number of points in that lie inside some large Euclidean ball, thus using the Euclidean (or Archimedean) notion of distance to localise the problem. This can also be done here, but it turns out to be more convenient to instead use the word metric induced by the finite generating set S of (which we can take to be symmetric for convenience, thus  ). One thus looks at sets of the form
). One thus looks at sets of the form  , where
, where  consists of all words formed by products of at most R elements of S. A major new difficulty here compared to the linear theory is the exponential growth of
consists of all words formed by products of at most R elements of S. A major new difficulty here compared to the linear theory is the exponential growth of  (a consequence of the non-elementary nature of ). (Though it is not immediately apparent, the same problem also arises if one uses Euclidean balls instead of word metric balls, due to the multiplicative rather than additive nature of the group .)
(a consequence of the non-elementary nature of ). (Though it is not immediately apparent, the same problem also arises if one uses Euclidean balls instead of word metric balls, due to the multiplicative rather than additive nature of the group .)
The next step is to use sieve theory. Recall the sieve of Eratosthenes, which expresses the set of all (large) primes as the integers, minus the multiples of two, minus the multiples of three, and so forth. Using the inclusion-exclusion principle, we can thus view the indicator function  of the primes, when restricted to an interval such as
of the primes, when restricted to an interval such as ![{}[N,2N]](https://s0.wp.com/latex.php?latex=%7B%7D%5BN%2C2N%5D&bg=ffffff&fg=545454&s=0&c=20201002) , as equal to 1, minus the indicator function
, as equal to 1, minus the indicator function  of the even numbers, minus the indicator function
of the even numbers, minus the indicator function  of the multiples of three, plus the indicator function
of the multiples of three, plus the indicator function  of the multiples of six, and so forth. This leads to the Legendre sieve
of the multiples of six, and so forth. This leads to the Legendre sieve
 , (1)
, (1)
valid in an interval as long as one restricts d to those integers which are products of primes less than N. Here 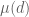 is the Möbius function.
is the Möbius function.
The basic idea of sieve theory is to replace the indicator function of the primes (or almost primes) by a more general divisor sum
 ,
,
where the sieve weights 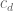 are chosen in order to optimise the final bounds in the sieve (they typically resemble “smoothed out” versions of the Möbius functionin order that these sieves be large on the almost primes and small elsewhere). In order for the sieve to be practical, one wants to restrict d in this sum to be relatively small, for instance
are chosen in order to optimise the final bounds in the sieve (they typically resemble “smoothed out” versions of the Möbius functionin order that these sieves be large on the almost primes and small elsewhere). In order for the sieve to be practical, one wants to restrict d in this sum to be relatively small, for instance  for some absolute constant
for some absolute constant 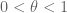 (values such as
(values such as  are fairly typical). The selection of the sieve weights is now a well-developed science (see also my earlier post, and Kowalski’s guest post, on this topic), and Bourgain, Gamburd and Sarnak basically use off-the-shelf sieves (in particular, combinatorial sieves and the Selberg sieve) in their work. Inserting these standard sieves into the problem at hand, the task of counting almost primes in the finite set
are fairly typical). The selection of the sieve weights is now a well-developed science (see also my earlier post, and Kowalski’s guest post, on this topic), and Bourgain, Gamburd and Sarnak basically use off-the-shelf sieves (in particular, combinatorial sieves and the Selberg sieve) in their work. Inserting these standard sieves into the problem at hand, the task of counting almost primes in the finite set  then quickly reduces to the question of getting good estimates on sets such as
then quickly reduces to the question of getting good estimates on sets such as  for various q. This amounts to much the same thing as asking for good equidistribution bounds for modulo q, thus we project the generating set S, and the ball it produces, from to
for various q. This amounts to much the same thing as asking for good equidistribution bounds for modulo q, thus we project the generating set S, and the ball it produces, from to  . For sieving purposes it turns out to be necessary to consider all squarefree moduli q, but for simplicity we shall only discuss the (massively easier) case when q is prime.
. For sieving purposes it turns out to be necessary to consider all squarefree moduli q, but for simplicity we shall only discuss the (massively easier) case when q is prime.
The reduction to an equidistribution problem converts the original sieving problem to a more combinatorial one, involving the Cayley graph G on induced by the set S, thus two vertices  are connected by an edge in G if
are connected by an edge in G if  lie in S (modulo q). The image of the ball in is then the set of points one can reach in the graph G from the origin by walking on a path of length at most R. The desired equidistribution result one needs can then be viewed as a mixing result for the random walk along the graph G.
lie in S (modulo q). The image of the ball in is then the set of points one can reach in the graph G from the origin by walking on a path of length at most R. The desired equidistribution result one needs can then be viewed as a mixing result for the random walk along the graph G.
Standard graph theory then tells us that the task reduces to showing that the graphs G form a family of expander graphs as  (recall we are restricting q to be prime for simplicity). There are many equivalent definitions of what an expander graph is, but let us give a spectral definition that is specialised to Cayley graphs. The symmetric generating set S induces a natural measure
(recall we are restricting q to be prime for simplicity). There are many equivalent definitions of what an expander graph is, but let us give a spectral definition that is specialised to Cayley graphs. The symmetric generating set S induces a natural measure

that is the uniform distribution on S, which controls the random walk along G; note that if  is a function, then the convolution
is a function, then the convolution  is another function, whose value at any vertex x is the average value of f at all the neighbours of x. The operation
is another function, whose value at any vertex x is the average value of f at all the neighbours of x. The operation  is then a self-adjoint contraction on
is then a self-adjoint contraction on  which leaves the function 1 invariant, so its largest eigenvalue
which leaves the function 1 invariant, so its largest eigenvalue 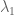 is equal to 1. The expander graph condition is then equivalent to the existence of a spectral gap
is equal to 1. The expander graph condition is then equivalent to the existence of a spectral gap  for the second largest eigenvalue, where
for the second largest eigenvalue, where 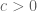 is a constant independent of q.
is a constant independent of q.
Of course, to have a spectral gap, one necessary condition is that  be strictly less than 1. This can be easily seen to be equivalent to the statement that G is connected, which in turn is equivalent to the statement that the projection of S to generates all of . This statement can be verified to be true, either by direct consideration of all possible subgroups of , or by the strong approximation property. However, mere connectedness is not enough to ensure that a Cayley graph is an expander family (which can be viewed as a sort of “robust” version of connectedness, which can survive the deletion of large numbers of edges). For instance, the Cayley graph of the generating set
be strictly less than 1. This can be easily seen to be equivalent to the statement that G is connected, which in turn is equivalent to the statement that the projection of S to generates all of . This statement can be verified to be true, either by direct consideration of all possible subgroups of , or by the strong approximation property. However, mere connectedness is not enough to ensure that a Cayley graph is an expander family (which can be viewed as a sort of “robust” version of connectedness, which can survive the deletion of large numbers of edges). For instance, the Cayley graph of the generating set 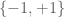 in
in 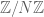 is connected, but does not form an expander family as
is connected, but does not form an expander family as  ; the second largest eigenvalue is about
; the second largest eigenvalue is about  only. (One can also see that the random walk on this Cayley graph takes a long time (about O(N^2) steps) before it mixes to be close to the uniform distribution; with expander graphs on a set of N vertices, mixing instead occurs in time
only. (One can also see that the random walk on this Cayley graph takes a long time (about O(N^2) steps) before it mixes to be close to the uniform distribution; with expander graphs on a set of N vertices, mixing instead occurs in time  , thanks to the spectral gap.)
, thanks to the spectral gap.)
Obtaining the spectral gap property requires more work. When the original subgroup of is as large as a finite index subgroup (in particular, if it is a congruence subgroup), this gap follows from a celebrated theorem of Selberg providing a similar spectral gap for arithmetic quotients of the upper half-plane. Smaller examples (in which the index is now infinite) were first constructed by Shalom and by Gamburd, with the latter following the method of Sarnak and Xue. Then (in the case of prime q), Bourgain and Gamburd extended the method using additional tools from additive combinatorics to handle all non-elementary subgroups.
Let us now describe the method of proof. As mentioned briefly earlier, the existence of a spectral gap implies a strong mixing property: the iterated convolutions  of the probability measure
of the probability measure  (which can be interpreted as the probability distribution of a random walk on n steps) converges exponentially fast to the constant distribution on . Since the latter distribution has an l^2 norm of
(which can be interpreted as the probability distribution of a random walk on n steps) converges exponentially fast to the constant distribution on . Since the latter distribution has an l^2 norm of  , we see in particular that for any fixed
, we see in particular that for any fixed  , we will have
, we will have
 (2)
(2)
once n is a sufficiently large multiple of  . This can also be seen explicitly from the trace formula
. This can also be seen explicitly from the trace formula
 . (3)
. (3)
In general, this implication between spectral gap and rapid mixing (2) cannot be reversed; the problem is that only directly influences one term in the summation on the right-hand side of (3), and so upper bounds on the left-hand side do not translate efficiently to upper bounds on . However, there is an algebraic miracle that happens in the case of groups such as that allows one to reverse the implication:
Lemma (Frobenius) Let q be prime. Then every non-trivial finite-dimensional unitary representation of has dimension at least (q-1)/2.
Proof. Observe that can be generated by parabolic elements, so given a non-trivial representation  , there exists a parabolic element a whose representation
, there exists a parabolic element a whose representation  is non-trivial. By a change of basis we may take
is non-trivial. By a change of basis we may take

On the one hand, we have  and hence
and hence  ; thus all eigenvalues of are
; thus all eigenvalues of are  roots of unity. On another hand, is non-trivial, so at least one of the eigenvalues of differs from 1. Thirdly, conjugating a by diagonal matrices in , we see that a is conjugate to
roots of unity. On another hand, is non-trivial, so at least one of the eigenvalues of differs from 1. Thirdly, conjugating a by diagonal matrices in , we see that a is conjugate to  whenever m is a quadratic residue mod q, and so the eigenvalues of must be stable under the operation of taking
whenever m is a quadratic residue mod q, and so the eigenvalues of must be stable under the operation of taking 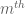 powers. On the other hand, there are (q-1)/2 quadratic residues. Putting all this together we see that must take at least (q-1)/2 distinct eigenvalues, and the claim follows.
powers. On the other hand, there are (q-1)/2 quadratic residues. Putting all this together we see that must take at least (q-1)/2 distinct eigenvalues, and the claim follows. 
Remark. For our purposes, the exact value of  is irrelevant; any multiplicity which grows like a power of q would suffice.
is irrelevant; any multiplicity which grows like a power of q would suffice. 
Applying this lemma to the eigenspace of , we obtain
Corollary. The second eigenvalue of the operation appears with multiplicity at least .
Combining this corollary with (3), one can now reverse the previous implication and obtain a spectral gap as soon as one gets a mixing estimate (2) for some  and some sufficiently small
and some sufficiently small  .
.
The task is now to obtain the mixing estimate (2). The quantity  starts at 1 when
starts at 1 when  and decreases with n. If we assume (as we may) that S generates a free group, then it is not hard to see that
and decreases with n. If we assume (as we may) that S generates a free group, then it is not hard to see that  expands rapidly for
expands rapidly for  (because all the words generated by S will be distinct until one encounters the “wrap-around” effect of taking residues modulo q). Using this one can get a preliminary mixing bound
(because all the words generated by S will be distinct until one encounters the “wrap-around” effect of taking residues modulo q). Using this one can get a preliminary mixing bound

for some absolute constant 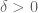 and some . Also, since S modulo q generates all of , we know that the probability measure is not trapped inside any proper subgroup H of ; indeed, using the classification of subgroups of (or some general “escape from subvarieties” machinery of Eskin, Moses, and Oh) one can show that
and some . Also, since S modulo q generates all of , we know that the probability measure is not trapped inside any proper subgroup H of ; indeed, using the classification of subgroups of (or some general “escape from subvarieties” machinery of Eskin, Moses, and Oh) one can show that

for any such subgroup, and some . The result now follows from iterating the following lemma, which is the heart of the argument:
 flattening lemma. Let
flattening lemma. Let  be a symmetric probability measure on which is a little bit dispersed in the sense that
be a symmetric probability measure on which is a little bit dispersed in the sense that

for some , and is not concentrated in a subvariety in the sense that  for any proper subgroup H of . Suppose also that is not entirely flat in the sense that
for any proper subgroup H of . Suppose also that is not entirely flat in the sense that

(note that the minimal norm for a probability measure is comparable to  , attained for the uniform distribution). Then
, attained for the uniform distribution). Then  is “flatter” than in the sense that
is “flatter” than in the sense that

for some depending on  .
.
In the special case when is the uniform distribution on some set A, the flattening lemma is very close to the following theorem of Helfgott:
Product theorem. Let q be a prime. Let A be a subset of which is not too big in the sense that  for some , and which is not contained in any proper subgroup H of . Then
for some , and which is not contained in any proper subgroup H of . Then  for some depending on .
for some depending on .
Indeed, by using some standard additive combinatorics, in particular a (non-commutative version of) the Balog-Szemerédi-Gowers lemma (which can be found for instance in my book with Van Vu), which connects “statistical” multiplication, such as that provided by convolution  , with “combinatorial” multiplication, coming from the product set operation
, with “combinatorial” multiplication, coming from the product set operation  , one can show that these two statements are in fact equivalent to each other.
, one can show that these two statements are in fact equivalent to each other.
The product theorem is a manifestation of certain “nonlinear” or “noncommutative” behaviour in the group  ; see my Milliman lecture for a bit more discussion on this. For now, let me just say that Helfgott’s proof on this uses a variety of algebraic and combinatorial computations exploiting the special structure of (especially how commutativity or non-commutativity of various elements in this group interact with the trace of various combinations of these elements), as well as the following sum-product estimate of Bourgain-Katz-Tao and Bourgain-Glibichuk-Konyagin:
; see my Milliman lecture for a bit more discussion on this. For now, let me just say that Helfgott’s proof on this uses a variety of algebraic and combinatorial computations exploiting the special structure of (especially how commutativity or non-commutativity of various elements in this group interact with the trace of various combinations of these elements), as well as the following sum-product estimate of Bourgain-Katz-Tao and Bourgain-Glibichuk-Konyagin:
Sum-product theorem. Let q be prime. Let A be a subset of  which is not too big in the sense that
which is not too big in the sense that  for some . Then
for some . Then  for some depending only on .
for some depending only on .
There are now some quite elementary proofs of this theorem, but I will not discuss them here (see e.g. my earlier blog post on this topic). I should note, though, that the bulk of the Bourgain-Gamburd-Sarnak work is preoccupied with establishing a suitable extension of this sum-product theorem to the case when q is not prime, in a manner which is uniform in the number of prime factors; this turns out to be a surprisingly difficult task.


7 comments
Comments feed for this article
20 November, 2008 at 6:46 pm
Martin Mazur
Great lecture at Penn State today, Prof. Tao. I’m an acoustics researcher at PSU with a background in applied mathematics (MA, UCLA 1986). Still, I followed your talk.
21 November, 2008 at 12:42 pm
luca
Hi Terry, thanks for making this beautiful material so accessible. A small correction: in the example of the Cayley graph of with generators
with generators  , the second eigenvalue is about
, the second eigenvalue is about  (it is something like
(it is something like  ), and the random walk takes about
), and the random walk takes about 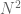 time to mix (because after
time to mix (because after  steps you are likely to be within distance
steps you are likely to be within distance  of your starting point).
of your starting point).
21 November, 2008 at 3:03 pm
Student
Could you give a reference to the elementary proofs of the sum-product theorem?
21 November, 2008 at 8:17 pm
Terence Tao
Dear Luca: thanks for the correction!
Dear Student: Some references can be found at my earlier post
25 November, 2008 at 1:47 pm
bob schmieder
Are any of your lectures available on podcasts? Unfortunately I missed your visit to Penn State.
26 November, 2008 at 9:35 am
Terence Tao
Dear Bob,
My Penn State lectures were not recorded, but my Milliman lectures at U. Washington (which were on related topics to my Marker lectures) can be found online at
http://www.math.washington.edu/Seminars/milliman_0708.php
26 November, 2008 at 6:19 pm
Jonathan Vos Post
Trivial typo: In the boxed theorem text for Sum-product theorem: “somem” should be “some” [Fixed – T.]
I love this thread. Cool results!