
This is the final continuation of the online reading seminar of Zhang’s paper for the polymath8 project. (There are two other continuations; this previous post, which deals with the combinatorial aspects of the second part of Zhang’s paper, and this previous post, that covers the Type I and Type II sums.) The main purpose of this post is to present (and hopefully, to improve upon) the treatment of the final and most innovative of the key estimates in Zhang’s paper, namely the Type III estimate.
The main estimate was already stated as Theorem 17 in the previous post, but we quickly recall the relevant definitions here. As in other posts, we always take 
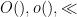
Definition 1 (Coefficient sequences) A coefficient sequence is a finitely supported sequence
that obeys the bounds
for all
, where
is the divisor function.
- (i) If
is a coefficient sequence and
is a primitive residue class, the (signed) discrepancy
of
- (ii) A coefficient sequence
for some
if it is supported on an interval of the form
.
- (iii) A coefficient sequence
for some smooth function
supported on
obeying the derivative bounds
for all fixed
(note that the implied constant in the
notation may depend on
).



For any 
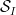

Theorem 2 (Type III estimate) Let
be fixed quantities, and let
be quantities such that
and
and
for some fixed
. Let
be coefficient sequences at scale
respectively with
smooth. Then for any
we have
In fact we have the stronger “pointwise” estimate
for all
with
and all
, and some fixed
.





(This is very slightly stronger than previously claimed, in that the condition 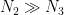
It turns out that Zhang does not exploit any averaging of the
Theorem 3 (Type III estimate without
be fixed, and let
be quantities such that
and
and
for some fixed
respectively. Then we have
for all
and some fixed

![\displaystyle d \in {\mathcal S}_{[1,x^\delta]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+d+%5Cin+%7B%5Cmathcal+S%7D_%7B%5B1%2Cx%5E%5Cdelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


Let us quickly see how Theorem 3 implies Theorem 2. To show (4), it suffices to establish the bound

for all 



From Theorem 3 we have

where the quantity 


It remains to establish Theorem 3. This is done by a set of tools similar to that used to control the Type I and Type II sums:
- (i) completion of sums;
- (ii) the Weil conjectures and bounds on Ramanujan sums;
- (iii) factorisation of smooth moduli
- (iv) the Cauchy-Schwarz and triangle inequalities (Weyl differencing).
The specifics are slightly different though. For the Type I and Type II sums, it was the classical Weil bound on Kloosterman sums that were the key source of power saving; Ramanujan sums only played a minor role, controlling a secondary error term. For the Type III sums, one needs a significantly deeper consequence of the Weil conjectures, namely the estimate of Bombieri and Birch on a three-dimensional variant of a Kloosterman sum. Furthermore, the Ramanujan sums – which are a rare example of sums that actually exhibit better than square root cancellation, thus going beyond even what the Weil conjectures can offer – make a crucial appearance, when combined with the factorisation of the smooth modulus 
— 1. A three-dimensional exponential sum —
The power savings in Zhang’s Type III argument come from good estimates on the three-dimensional exponential sum
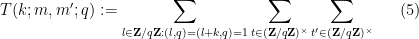

defined for positive integer 
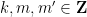
Theorem 4 (Bombieri-Birch bound) Let
where
is the greatest common divisor of
(and we adopt the convention that
). (Here, the
denotes a quantity that goes to zero as
, rather than as
.)

Note that the square root cancellation heuristic predicts 
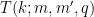

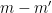
Proof: Suppose that 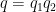
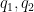
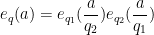
(see Lemma 7 of this previous post). From this and the Chinese remainder theorem we see that 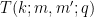
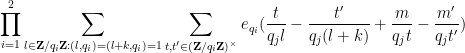
where 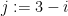
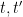
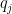

Iterating this law, we see that to prove Theorem 4 it suffices to do so in the case when

We first consider the case when 

In this case we can write 

Making the change of variables 



Performing the 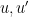

where 

Basic Fourier analysis tells us that 

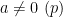
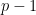
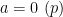
Next, suppose that 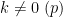
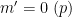
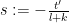


Performing the 

For each 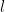



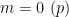
The only remaining case is when 

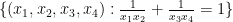

To deal with factors such as 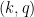
Lemma 5 For any
we have
in particular
As in the previous theorem,


Note that it is important that the 
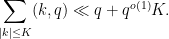
Proof: Estimating

we can bound

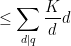


— 2. Cauchy-Schwarz —
We now prove Theorem 3. The reader may wish to track the exponents involved in the model regime

where 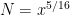

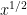
Let 

where
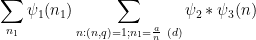
and then apply completion of sums (Lemma 6 from this previous post) to rewrite this expression as the sum of the main term

plus the error terms

and

where 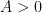
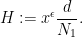
The first term does not depend on

It will be convenient to reduce to the case when 
Proposition 6 Let
be fixed, and let
be such that
for some fixed
be smooth coefficient sequences at scale
respectively. Then
for some fixed
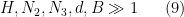
![\displaystyle d \in {\mathcal S}_{[1,x^\delta]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++d+%5Cin+%7B%5Cmathcal+S%7D_%7B%5B1%2Cx%5E%5Cdelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



Let us now see why the above proposition implies (8). To prove (8), we may of course assume 

for any function 

which we expand as

In order to apply Proposition (6) we need to modify the 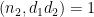


for any function 
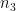

where



We may discard those values of 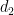




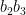

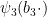

which by the divisor bound is 
It remains to prove Proposition 6. Continuing (7), the reader may wish to keep in mind the model case


Expanding out the 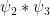
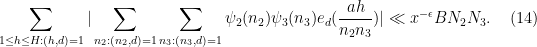
As before, our aim is to obtain a power savings better than 

The next step is Weyl differencing. We will need a step size 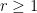

we will make the hypothesis that

and save this condition to be verified later.
By shifting 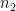
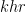

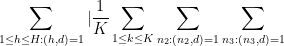
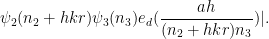
By the triangle inequality, it thus suffices to show that

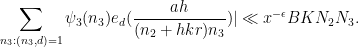
Next, we combine the 

for any fixed 



where 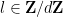


Thus we can estimate the left-hand side of (17) by
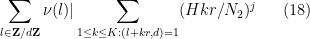

where
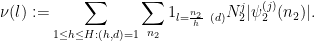
Here we have bounded 

We will eliminate the 


and thus

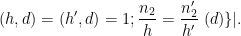
Note that 
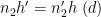

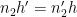

From the divisor bound, we see that for each fixed 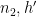
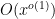
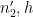

From this, (18), and Cauchy-Schwarz, we see that to prove (17) it will suffice to show that

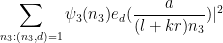
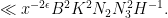
Comparing with the trivial bound of 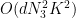
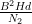
We square out (19) as
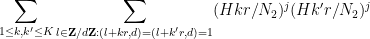

If we shift 



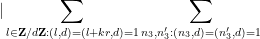
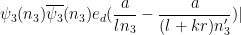
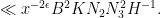
Next we perform another completion of sums, this time in the 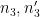
by

 , where
, where 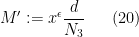
(the prime is there to distinguish this quantity from 


Making the change of variables 


Applying Theorem 4 (and recalling that
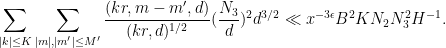
We now choose 

for some
Lemma 7 We have


Proof: We first consider the contribution of the diagonal case 

The 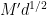
For the non-diagonal case 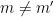

since 
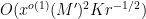
From this lemma, we see that we are done if we can find

as well as the previously recorded condition (16). We can split the condition (21) into three subconditions:
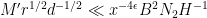


Substituting the definitions (15), (20) of 

while the other three conditions rearrange to

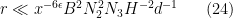
and

We can combine (23), (24) into a single condition

Also, from (9), (13) we see that this new condition also implies (22). Thus we are done as soon as we find a factor
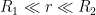
where
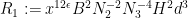
and

From (11) one has

if

and 
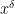

83 comments
Comments feed for this article
14 June, 2013 at 9:38 am
Terence Tao
While writing up the argument I found that the factorisation of the Bombieri-Birch exponential sum for a mdulus d=qr into a modulus q component (which is still of Bombieri-Birch type) and a modulus r component (which is of Ramanujan type) could be more cleanly performed by noting a multiplicativity property of the Bombieri-Birch sum (see the third display in the proof of Theorem 4). This in particular leads to a refinement of Lemma 12 of Zhang that “bakes in” the Ramanujan sum decay more efficiently. This ended up cleaning up the proof (as did application of completion of sums as a black box estimate, without any further need to track Fourier coefficients) but unfortunately did not lead to improved bounds.
As before, we can record the numerics of the critical case:
14 June, 2013 at 2:13 pm
bengreen
This multiplicativity property is a nice observation. It reduces some of the mystery.
16 June, 2013 at 3:01 am
v08ltu
There is something wrong in the above. I get that is less than 1. Its exponent is
is less than 1. Its exponent is  .
.
16 June, 2013 at 3:02 am
v08ltu
Oh, duh I mixed N and x, sorry!
14 June, 2013 at 10:03 am
Terence Tao
Three thoughts:
1. The triple exponential sum in Theorem 4 has the unusual property that certain degenerate cases of this sum are smaller than the non-degenerate cases (in particular, beating square root cancellation) – usually the degenerate cases are much larger. This leads to certain “diagonal” terms in the Cauchy-Schwarz analysis being significantly smaller than what one would naively expect them to be. The rarity of this phenomenon (degenerate sums being better behaved than non-degenerate sums) may limit the applicability of this very nice trick of Zhang.
2. Zhang’s trick should improve the numerical values of the recent preprint of Fouvry, Kowalski, and Iwaniec http://arxiv.org/abs/1304.3199 on the level of distribution of , at least when restricted to smooth moduli. But this is outside the scope of the polymath project and I would presume that FKM are already in the process of working out the details, so I propose that we avoid pursuing this direction here. (But it might be worth leafing through FKM to see if there are any tricks that can also be applied to the Type III sums here.)
, at least when restricted to smooth moduli. But this is outside the scope of the polymath project and I would presume that FKM are already in the process of working out the details, so I propose that we avoid pursuing this direction here. (But it might be worth leafing through FKM to see if there are any tricks that can also be applied to the Type III sums here.)
3. The discarding of the convolution to reduce Theorem 2 to Theorem 3 looks lossy. In particular it seems to me that Theorem 2 only requires an averaged version of Theorem 3 in which the
convolution to reduce Theorem 2 to Theorem 3 looks lossy. In particular it seems to me that Theorem 2 only requires an averaged version of Theorem 3 in which the  parameter is averaged over a set of length M (the inverse of an arithmetic progression in
parameter is averaged over a set of length M (the inverse of an arithmetic progression in  ). I have a suspicion that completion of sums is less lossy when there is such an averaging, in principle one might gain an additional factor of something like
). I have a suspicion that completion of sums is less lossy when there is such an averaging, in principle one might gain an additional factor of something like 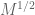 . This could lead to some noticeable numerical improvements in the exponents. However, I have not yet worked out the details of this.
. This could lead to some noticeable numerical improvements in the exponents. However, I have not yet worked out the details of this.
14 June, 2013 at 2:27 pm
v08ltu
Regarding #1, I too thought this mysterious. I mean, so you Weyl shift by multiples of – why doesn’t that just give you something like
– why doesn’t that just give you something like  (and thus no cancellation) rather than a Ramanujan sum (with residue-class differences as an argument)? This is still a philosophy disparity for me.
(and thus no cancellation) rather than a Ramanujan sum (with residue-class differences as an argument)? This is still a philosophy disparity for me.
14 June, 2013 at 9:24 pm
Terence Tao
Actually, now that I think about it, I know another context in which partly degenerate exponential sums have better cancellation than non-degenerate sums. Consider a quadratic exponential sum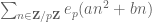 for some odd prime
for some odd prime  . When
. When  is non-zero this is a Gauss sum and has square root cancellation – the magnitude is exactly
is non-zero this is a Gauss sum and has square root cancellation – the magnitude is exactly 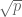 . But when
. But when  degenerates to zero while
degenerates to zero while  stays non-zero, we get perfect cancellation – the magnitude is now zero! Of course, when
stays non-zero, we get perfect cancellation – the magnitude is now zero! Of course, when  and
and  both degenerate, there is no cancellation whatsoever and the sum jumps up to
both degenerate, there is no cancellation whatsoever and the sum jumps up to  .
.
With the Birch-Bombieri sum there is a qualitatively similar phenomenon: square root cancellation in the fully non-degenerate case, better than square root cancellation in the partially degenerate case (
there is a qualitatively similar phenomenon: square root cancellation in the fully non-degenerate case, better than square root cancellation in the partially degenerate case ( has a common factor with
has a common factor with  but
but 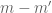 does not), and huge in the completely degenerate case.
does not), and huge in the completely degenerate case.
17 June, 2013 at 12:13 am
Emmanuel Kowalski
FKI should be FKM…. (Fouvry-K.-Michel)
[Corrected, thanks – T.]
18 June, 2013 at 6:08 am
Ph.M
Regarding # 2.
In fact, when an averaging over conveniently factorable moduli is available (as in this case here) we checked is it possible to get a quite high exponent of distribution (up to 4/7). The argument is simpler than Zhang’s treatment and in fact should improve Zhang type III sums quite a bit. See one of Emmanuel’s forth coming blog.
19 June, 2013 at 1:15 am
v08ltu
If I take this comment in the most direct sense, we have when
when 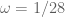 . With no
. With no  or
or  this would give
this would give  , but perhaps other aspects will break.
, but perhaps other aspects will break.
19 June, 2013 at 4:49 am
Andrew Sutherland
We would then have H(110)=628 (from Engelsma’s tables).
19 June, 2013 at 6:47 am
Terence Tao
If the Type III sums became that good then the bottleneck then comes from the Type I/II sums (which currently has a constraint of the form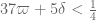 ) and also the combinatorial analysis (which has a constraint
) and also the combinatorial analysis (which has a constraint  , which when combined with the constraint
, which when combined with the constraint  coming from the Type I analysis gives that
coming from the Type I analysis gives that  ). The second barrier is a bit stronger, so there is a barrier to
). The second barrier is a bit stronger, so there is a barrier to  getting past
getting past  at present, but we have basically made no efforts to attack these barriers yet as they have not come close to the battlefront thus far, and presumably they can be knocked back a bit. But in any event I foresee that the Type III sums will cease to become critical in the near future, and we will have to turn our attention elsewhere to get gains.
at present, but we have basically made no efforts to attack these barriers yet as they have not come close to the battlefront thus far, and presumably they can be knocked back a bit. But in any event I foresee that the Type III sums will cease to become critical in the near future, and we will have to turn our attention elsewhere to get gains.
19 June, 2013 at 7:18 am
Ph.M
Actually, the exponent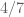 is for the distribution of
is for the distribution of  which is “smoother” than the actual type III which includes some small non smooth factor ( the variable
which is “smoother” than the actual type III which includes some small non smooth factor ( the variable 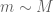 ) so the
) so the 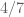 exponent is relative to
exponent is relative to  rather than
rather than  . We will write this up.
. We will write this up.
19 June, 2013 at 7:56 am
Terence Tao
Naively, if one assumes a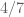 level of distribution for the
level of distribution for the  component of the type III sums, one expects a condition of the form
component of the type III sums, one expects a condition of the form
(ignoring epsilons) which on plugging in the critical case from the combinatorial analysis gives
from the combinatorial analysis gives
thus
From Type I analysis (and ignoring and infinitesimals) we can take
and infinitesimals) we can take  so this gives a constraint
so this gives a constraint  , but this is unfortunately occluded by the existing constraint
, but this is unfortunately occluded by the existing constraint 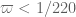 coming from the requirement
coming from the requirement  . It may well be that one can also exploit the
. It may well be that one can also exploit the  averaging as we are currently doing but this will only serve to weaken the
averaging as we are currently doing but this will only serve to weaken the  threshold and not the
threshold and not the 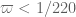 one. So my prediction is that the Type III improvement will be strong enough that it no longer provides the dominant obstruction to bounds, with the combinatorial constraint
one. So my prediction is that the Type III improvement will be strong enough that it no longer provides the dominant obstruction to bounds, with the combinatorial constraint  (combined with the constraint
(combined with the constraint 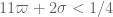 from the Type I analysis) dominating instead, and basically placing
from the Type I analysis) dominating instead, and basically placing  close to
close to  .
.
14 June, 2013 at 12:51 pm
Pace Nielsen
“Chiense” should be “Chinese”
In equation (8) there is an extra left-hand absolute value sign. [It might be more readable to make some of the absolute value signs bigger, so it is clear they encompass some of the sums.]
In the third offset equation above (8), it appears that a right-hand absolute value sign is missing.
Sorry for not having any useful things to say about the mathematics. I am enjoying reading these posts.
[Corrected, thanks – T.]
14 June, 2013 at 1:40 pm
Pace Nielsen
I did have one question, about the definition of “coefficient sequence”. Isn’t every finitely supported sequence a coefficient sequence? From the finite support, we know that the image of the sequence is bounded. But for sufficiently large x, log(x) then dominates. (Or is x not independent of n and somehow?)
somehow?)
14 June, 2013 at 2:42 pm
v08ltu
I had the same fret, reading this definition before. It’s finitely supported, but has some asymptotic bounds? I guess this needs to be interpreted, as saying that the constants in the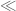 have been picked before hand?
have been picked before hand?
14 June, 2013 at 5:55 pm
Terence Tao
Every fixed (i.e. independent of x) finitely supported sequence is a coefficient sequence, but a finitely supported sequence that depends on x need not be a coefficient sequence. (The distinction between quantities that depend on the asymptotic parameter , and quantities independent of that parameter (which are called “fixed”) here, forms the basis of what I call “cheap nonstandard analysis“, which allows one to work rigorously with asymptotic notation without having to deploy the full machinery of nonstandard analysis. It is briefly introduced in the earliest of this series of posts, back at https://terrytao.wordpress.com/2013/06/03/the-prime-tuples-conjecture-sieve-theory-and-the-work-of-goldston-pintz-yildirim-motohashi-pintz-and-zhang/ .
, and quantities independent of that parameter (which are called “fixed”) here, forms the basis of what I call “cheap nonstandard analysis“, which allows one to work rigorously with asymptotic notation without having to deploy the full machinery of nonstandard analysis. It is briefly introduced in the earliest of this series of posts, back at https://terrytao.wordpress.com/2013/06/03/the-prime-tuples-conjecture-sieve-theory-and-the-work-of-goldston-pintz-yildirim-motohashi-pintz-and-zhang/ .
15 June, 2013 at 12:07 pm
Gaston Rachlou
In my humble opinion, this terminology is not a very happy innovation, and could be replaced with no harm by its definition, accessible to any mathematician. One has to understand that your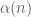 is in fact a
is in fact a  . Moreover, it is not immediately clear if the support of this sequence (supposed to be finite for
. Moreover, it is not immediately clear if the support of this sequence (supposed to be finite for  fixed) depends on
fixed) depends on  or not.
or not.
15 June, 2013 at 12:51 pm
Terence Tao
To quote from the first post in this series where this notation is introduced:
The alternative would be to explicitly subscript almost every quantity (other than the fixed ones) in these posts by , which would be quite distracting, since this dependence occurs for most of the objects introduced in the post and thus is better suited to be the default assumption in one’s notation as specified above, rather than the other way around. (For instance, in the above post, the objects
, which would be quite distracting, since this dependence occurs for most of the objects introduced in the post and thus is better suited to be the default assumption in one’s notation as specified above, rather than the other way around. (For instance, in the above post, the objects  ,
, 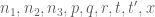 ,
,  ,
,  ,
,  and associated structures (e.g. the support of
and associated structures (e.g. the support of  ) are allowed to depend on
) are allowed to depend on  or to be bound to a range depending on
or to be bound to a range depending on  (as indicated by the default convention that is in force throughout these posts), with only
(as indicated by the default convention that is in force throughout these posts), with only  declared as fixed.)
declared as fixed.)
15 June, 2013 at 8:39 am
meditationatae
The Bombieri-Birch bound in Theorem 4 is given in long outline form above, although presumably this wasn’t re-argued in Zhang’s paper, am I right? In expression (6), it seems that is the same thing as the
is the same thing as the  assumed prime about four lines above, in the “case when
assumed prime about four lines above, in the “case when  is prime” . It seems Zhang’s proof of Theorem 3 involves invoking the Bombieri-Birch triple exponential sum bound of Theorem 4, and all that lies in Section 2 of the post, starting at expression (7) till the end of Section 2; is that about right? Finally, my intuition is that Theorem 2 is not so hard, given Theorem 3, and the “hard theorem” would be Theorem 3, Zhang’s Type III estimate without
is prime” . It seems Zhang’s proof of Theorem 3 involves invoking the Bombieri-Birch triple exponential sum bound of Theorem 4, and all that lies in Section 2 of the post, starting at expression (7) till the end of Section 2; is that about right? Finally, my intuition is that Theorem 2 is not so hard, given Theorem 3, and the “hard theorem” would be Theorem 3, Zhang’s Type III estimate without  …
…
15 June, 2013 at 9:22 am
Terence Tao
Yes, this is basically correct. Theorem 4 above corresponds to Lemma 11 in Zhang, although Theorem 4 is also recording an additional cancellation in the degenerate case when k has a shared factor with q but not m-m’; this cancellation was implicit in Section 14 but it seems simpler to place it in Theorem 4 instead.
15 June, 2013 at 1:47 pm
Terence Tao
I think I can indeed get some gain here from working with an averaged version of Theorem 3. More precisely, if one inspects the derivation of Theorem 2 from Theorem 3, we see that it actually suffices to replace the conclusion of Theorem 3 by the weaker
where for some
for some  and the coefficients
and the coefficients  are
are 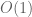 . (In the regime of interest we have
. (In the regime of interest we have  .)
.)
If we run the arguments of Section 2 carrying this new averaging in A with us, (8) becomes
and the conclusion of Proposition 6 is similarly replaced with
Continuing the argument through to (19), we see that (19) is replaced with
Squaring this out and continuing the arguments of the main post, we see that it suffices to establish the bound
note crucially that the third argument of the exponential sum now acquires a factor of a’ instead of a. Using Theorem 4, the left-hand side is essentially bounded by
now acquires a factor of a’ instead of a. Using Theorem 4, the left-hand side is essentially bounded by
The key point here is that generic are usually coprime, making the diagonal case
are usually coprime, making the diagonal case  somewhat rarer than the diagonal case
somewhat rarer than the diagonal case  considered in Lemma 7. Writing
considered in Lemma 7. Writing  ,
,  for
for  , one can rewrite
, one can rewrite
and by using the divisor bound this is basically back to the situation in Lemma 7 but with m, m’ now ranging at scale O(MM’) rather than just O(M’). As such, the first two terms on the RHS of Lemma 7 acquire an additional factor of M^{-1} after performing the averaging in a,a’. According to my calculations, this allows one to loosen the constraint
in Proposition 6 with the pair of constraints
(the latter condition comes from (22) which is no longer so obviously dominated by (24), although it will ultimately still be redundant in the final analysis after optimising with the Type I/II analysis). This means that we can replace
in Theorem 2 with
and
The former constraint is equivalent to
Returning to the combinatorial analysis, the necessary condition
is now relaxed to the combination of
and
which, upon setting close to
close to  (and also recalling the condition
(and also recalling the condition  ) becomes (if all my calculations are correct)
) becomes (if all my calculations are correct)
and
and
The second and third conditions are weaker than the first so we are left with , which would be a significant improvement over the previous bound of
, which would be a significant improvement over the previous bound of 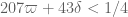 .
.
Needless to say, this should all be checked, and should be currently viewed as provisional, but I'm optimistic that we have a good gain here.
15 June, 2013 at 4:04 pm
v08ltu
I have been too busy to be PolyMathing recently, but I think that the work of Ping Xi on Burgess for Kloosterman sums that I mentioned in the other thread has good hope of some improvement on the other end of things. The main technical issue is to pass from prime to composite moduli (and write the details of the proof in the first place) w/o losing too much, which is not always trivial in a Burgess setting (it is not simply CRT) vis-a-vis coprimality accounting.
I contend that the main “problem” with 13&14 was that the diagonal was so dominant (that K needed to be so big), and so your idea seems to quell it via averaging. What is the critical K with these provisional parameters?
15 June, 2013 at 10:55 pm
v08ltu
I agree that this $m$-averaging should in principle work. But to verify all the details I still need to change your notation into my notation (and compare to Zhang’s notation, particularly ensuring that “m” is not confused with “m” any where).
16 June, 2013 at 4:41 am
Michael
I think the redundant inequality near the end should have instead of
instead of 
[Corrected, thanks; also I added the additional constraint from the combinatorial analysis. Fortunately, neither of these corrections ended up affecting the headline bound. -T]
from the combinatorial analysis. Fortunately, neither of these corrections ended up affecting the headline bound. -T]
15 June, 2013 at 3:59 pm
Andrew Sutherland
Do we know approximately what value this would imply for ?
?
15 June, 2013 at 4:11 pm
v08ltu
I think and
and  works, but I have to run.
works, but I have to run.
15 June, 2013 at 6:25 pm
Terence Tao
Here’s what I get with this choice of parameters (ignoring infinitesimals):
and
which gives us about of room for
of room for  and
and 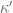 . Using Gergely’s first improved value
. Using Gergely’s first improved value
of (the derivation of which is now in the main post of https://terrytao.wordpress.com/2013/06/11/further-analysis-of-the-truncated-gpy-sieve/ ), I get
(the derivation of which is now in the main post of https://terrytao.wordpress.com/2013/06/11/further-analysis-of-the-truncated-gpy-sieve/ ), I get 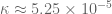 and
and  , so the bar looks like it is cleared (though I do not have an error analysis on the numerical integration I performed). With Gergely’s provisional values of
, so the bar looks like it is cleared (though I do not have an error analysis on the numerical integration I performed). With Gergely’s provisional values of  I get essentially the same result. So I am happy to confirm the
I get essentially the same result. So I am happy to confirm the  value once the
value once the 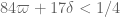 condition is confirmed.
condition is confirmed.
For the above values of , we can recalculate the critical numerology as follows:
, we can recalculate the critical numerology as follows:
So K is looking a lot smaller than it used to be (in the previous critical case, it was closer to ).
).
I have to run, but I will try to confirm Gergely’s new provisional argument for soon (and maybe sneak a look at the Ping Xi paper, though this may have to wait a bit). I’ll also have to double-check the
soon (and maybe sneak a look at the Ping Xi paper, though this may have to wait a bit). I’ll also have to double-check the 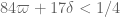 argument, though if someone else could also have a look at this, that would be great.
argument, though if someone else could also have a look at this, that would be great.
15 June, 2013 at 6:33 pm
v08ltu
I get allows
allows  .
.
15 June, 2013 at 6:37 pm
v08ltu
In fact, also allows
also allows  (just barely), not sure why I missed it the first time around, but I was in a hurry. I will try to sort through the new argument for 13&14. The condition is “87” omega, correct? In the latter comment you twice have “84”. I will work thru it in any case.
(just barely), not sure why I missed it the first time around, but I was in a hurry. I will try to sort through the new argument for 13&14. The condition is “87” omega, correct? In the latter comment you twice have “84”. I will work thru it in any case.
15 June, 2013 at 8:06 pm
Terence Tao
Oops, sorry about that, that was a typo and I have just corrected it. Yes, the correct condition (I believe) is .
.
15 June, 2013 at 6:42 pm
Gergely Harcos
Sounds great. For I get
I get 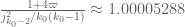 , while the provisional
, while the provisional  is a bit smaller, about
is a bit smaller, about  . BTW I am more confident about the provisional
. BTW I am more confident about the provisional  and
and 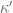 now, but I also apologize for any failures, past and future.
now, but I also apologize for any failures, past and future.
15 June, 2013 at 8:10 pm
Eytan Paldi
Note that by decreasing by 1, the change in the denominator of the LHS ratio seems to be
by 1, the change in the denominator of the LHS ratio seems to be  since the asymptotic expansion of
since the asymptotic expansion of  starts with n. Hence, small changes in
starts with n. Hence, small changes in  results in LARGER relative changes of
results in LARGER relative changes of  .
. is perhaps still not negligible, and further work on its reduction may be important for such values of
is perhaps still not negligible, and further work on its reduction may be important for such values of
 .
.
So even this small value of
16 June, 2013 at 3:21 am
v08ltu
I think the gain from the above is in some sense from the betterment of the last line of page 50 of Zhang on the diagonal estimation, replacing the crude worst-case bound of with an on-average bound, perhaps not as good as
with an on-average bound, perhaps not as good as  (I am still checking details, this is the length of the sum, so you can’t beat that) but enough to make
(I am still checking details, this is the length of the sum, so you can’t beat that) but enough to make  rather harmless.
rather harmless.
16 June, 2013 at 3:33 am
v08ltu
According to my ansatz, there are three terms, namely the Weyl shift error which is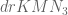 , the
, the  -diagonal error which is dominated by
-diagonal error which is dominated by  giving
giving  , and the BB-Deligne term which is
, and the BB-Deligne term which is  , the savings being from the Zhang trick. Previously the second (diagonal term) was
, the savings being from the Zhang trick. Previously the second (diagonal term) was  , so the
, so the  -average saved
-average saved 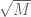 (i.e., the
(i.e., the  -diagonal now dominates the double
-diagonal now dominates the double  -sum, sqrt due to Cauchy of course). Oh, there is also the
-sum, sqrt due to Cauchy of course). Oh, there is also the  -modulus error which I think is the same as the Weyl shift, but with
-modulus error which I think is the same as the Weyl shift, but with  instead of
instead of 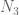 . Now to check the final numbers…
. Now to check the final numbers…
16 June, 2013 at 4:02 am
v08ltu
Noting that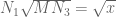 in the
in the 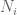 equal case, I get
equal case, I get  , then
, then  , and plugging in for
, and plugging in for  gives me
gives me 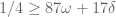 . Check.
. Check.
16 June, 2013 at 4:10 am
v08ltu
So I can be clear, I did not check every detail about how much the -average saved (computing all the gcd’s that is), just did enough to convince my self the main
-average saved (computing all the gcd’s that is), just did enough to convince my self the main  term “should” dominate and compute its effect.
term “should” dominate and compute its effect.
16 June, 2013 at 7:29 am
Terence Tao
Thanks for this! The fact that you used a slightly different approach lends more confidence to the confirmation.
It looks like the main condition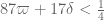 is still much stronger than all the other necessary conditions that are needed in the analysis, so it should be safe to list this condition as confirmed, as well as the corollary that
is still much stronger than all the other necessary conditions that are needed in the analysis, so it should be safe to list this condition as confirmed, as well as the corollary that  (and hence
(and hence  ) are confirmed as well.
) are confirmed as well.
15 June, 2013 at 6:03 pm
Gergely Harcos
With the provisional improved values for and
and 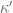 (see https://terrytao.wordpress.com/2013/06/11/further-analysis-of-the-truncated-gpy-sieve/#comment-234683) I get that
(see https://terrytao.wordpress.com/2013/06/11/further-analysis-of-the-truncated-gpy-sieve/#comment-234683) I get that  and
and  is best.
is best.
15 June, 2013 at 6:02 pm
Andrew Sutherland
Thanks. We then have . But I’m sure this bound will improve.
. But I’m sure this bound will improve.
15 June, 2013 at 9:47 pm
Terence Tao
Looks like Polymath8 has made three orders of magnitude of improvement then! (But we’ve cleaned out almost all the low hanging fruit… I’d be surprised if we get more than one more order of magnitude from the rest of the project.)
16 June, 2013 at 4:48 am
v08ltu
If we could make the (sieve) estimates be “ -free” and “
-free” and “ -free, via some impossible sieving, that would leave
-free, via some impossible sieving, that would leave  into the
into the 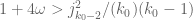 , which I find permits
, which I find permits  . So any gains there might appear slight.
. So any gains there might appear slight.
I should probably directly compute how much a prospective Burgess-Kloosterman bound would achieve, but I instead will speculate it could be an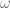 or two in
or two in  . Each
. Each 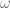 reduces the “87” by 10, and one such reduction yields the above 5446 down to 4518, and two reductions to 3651. Even still, that is not a halving from currently 6329.
reduces the “87” by 10, and one such reduction yields the above 5446 down to 4518, and two reductions to 3651. Even still, that is not a halving from currently 6329.
16 June, 2013 at 5:08 am
Andrew Sutherland
For reference, I get ,
, 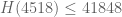 , and
, and  (I expect these can all be improved, but they should be reasonably close to the optimal values).
(I expect these can all be improved, but they should be reasonably close to the optimal values).
16 June, 2013 at 5:17 am
Andrew Sutherland
I notice that 3651 is in the range considered by Engelsma (see http://www.opertech.com/primes/summary.txt), and his results imply an upper bound of 33076 (which I suspect involved a lot of computation), whereas the bound 33070 I gave above took less than 5 minutes to find. This suggests that the polymath8 techniques for computing upper bounds on H(k0) are getting pretty good.
16 June, 2013 at 7:24 am
Terence Tao
Thanks for this – it’s good to get some benchmarks for best-case scenarios, even if they don’t project fantastic new gains.
Incidentally, as we work with larger and larger values of and
and  (and smaller values of
(and smaller values of  ), other obstacles begin to appear (a bit like how rocks submerged far beneath the ocean surface do not pose a problem for navigation until the ocean level drops too low); for instance the combinatorial analysis has a condition
), other obstacles begin to appear (a bit like how rocks submerged far beneath the ocean surface do not pose a problem for navigation until the ocean level drops too low); for instance the combinatorial analysis has a condition  which previously has not been any difficulty whatsoever but will for instance block
which previously has not been any difficulty whatsoever but will for instance block  from exceeding
from exceeding  even in the absence of
even in the absence of  unless the Type I analysis improves or if we can somehow improve the combinatorics.
unless the Type I analysis improves or if we can somehow improve the combinatorics.
Still, we are not completely out of things to try yet, even if I do agree that further progress is going to require increasing effort and we are not going to see the dramatic order-of-magnitude improvements that we had once or twice in the past. At some point the progress will reach a natural plateau, at which point it will be time to turn to the writing up stage of the project.
16 June, 2013 at 9:22 am
Terence Tao
I haven’t checked any details yet, but there may be a way to do the Weyl differencing more efficiently. Right now we shift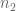 to
to  for
for  ; this limits the size of
; this limits the size of  to roughly
to roughly  . The presence of the
. The presence of the  allows one to achieve the cancellation
allows one to achieve the cancellation
where . But what if we don’t bother putting
. But what if we don’t bother putting  in the shift, i.e. only shifting
in the shift, i.e. only shifting 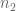 to
to  ? This enlarges K significantly, to about
? This enlarges K significantly, to about  , which should help attenuate the diagonal contributions
, which should help attenuate the diagonal contributions  even further. The cost is that the cancellation now looks slightly worse,
even further. The cost is that the cancellation now looks slightly worse,
but I think the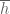 factor attached to
factor attached to  , being coprime to
, being coprime to  , is ultimately harmless in the rest of the argument (at least as far as a quick glance at Theorem 4 suggests), though this certainly needs to be checked. But this may lead to a further noticeable gain in the numerology. (I think someone pointed out in one of the earlier threads that there was potentially more slack in the Type III estimates than the Type I/II estimates, as the latter have already been optimised quite a bit by BFI and other very strong previous authors, whereas the Type III argument is original to Zhang and thus not nearly as optimised.)
, is ultimately harmless in the rest of the argument (at least as far as a quick glance at Theorem 4 suggests), though this certainly needs to be checked. But this may lead to a further noticeable gain in the numerology. (I think someone pointed out in one of the earlier threads that there was potentially more slack in the Type III estimates than the Type I/II estimates, as the latter have already been optimised quite a bit by BFI and other very strong previous authors, whereas the Type III argument is original to Zhang and thus not nearly as optimised.)
16 June, 2013 at 9:57 am
Terence Tao
A quick calculation of the numerology:
With the previous improvement to the arguments, the conditions to verify for Theorem 2 take the shape (ignoring epsilon factors)
and
(the extra factors of improving over Lemma 7 is the gain coming from exploiting the averaging from the
improving over Lemma 7 is the gain coming from exploiting the averaging from the  factor). With the new idea,
factor). With the new idea,  gets increased from
gets increased from  to
to  . The conditions on
. The conditions on  now become
now become
The new gain here is in the third inequality which has lost one power of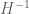 on the RHS. (The second inequality is likely to still be redundant as before.) So we end up with the conditions
on the RHS. (The second inequality is likely to still be redundant as before.) So we end up with the conditions
for the analogue of Proposition 6; I think the main inequality is still the last one, in which one power of H has now been saved over before. The analogue of Theorem 2 then acquires the conditions
or equivalently
The first is majorised by the third and can be deleted. This leads to the constraints
which on substituting gives (if my arithmetic is correct)
gives (if my arithmetic is correct)
The second condition is redundant, so we end up with
The condition coming from combinatorics is now also relevant and gives an additional constraint
condition coming from combinatorics is now also relevant and gives an additional constraint
This is extremely rough though and there may be errors, I need to double check this.
16 June, 2013 at 10:18 am
Terence Tao
One interesting new phenomenon: if one tries to move past 1/10 (i.e. to go past (2)) then we will have to contend with a new type of sum – a “Type IV sum” if you will – a model case of which is
past 1/10 (i.e. to go past (2)) then we will have to contend with a new type of sum – a “Type IV sum” if you will – a model case of which is 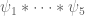 where all
where all  are smooth and at scale about
are smooth and at scale about  .
.
Gotta run, more later…
16 June, 2013 at 10:34 am
Andrew Sutherland
@v08ltu, Harcos: any estimates of what this would yield for ?
?
16 June, 2013 at 2:17 pm
v08ltu
I get for
for  , but this breaks condition (2). From that I get
, but this breaks condition (2). From that I get  and
and  .
.
16 June, 2013 at 1:08 pm
Terence Tao
Rechecked the numerology. For the analogue of Prop 6, there are actually a few more constraints coming from the requirements , which take the form
, which take the form
but these look very mild; they transform to
which become the extremely weak
but this is still majorised by . So the conditions (1), (2) are still the only necessary conditions in this analysis, representing the need to control the Type I/III and a new Type I/IV border. But if we improve things much more, we may have to fight battles on many fronts at once, including the Type I/II border…
. So the conditions (1), (2) are still the only necessary conditions in this analysis, representing the need to control the Type I/III and a new Type I/IV border. But if we improve things much more, we may have to fight battles on many fronts at once, including the Type I/II border…
I will probably write a new blog post on the latest Type III estimate since it now has two major alterations from what is posted above. But this may take a day or two.
16 June, 2013 at 2:53 pm
Hannes
155 varpi + 31 delta < 1 (is this what you call (1)?) is dominated by 11 varpi + 3 delta < 1/20
16 June, 2013 at 2:03 pm
v08ltu
I considered forgetting the from the Weyl shift awhile back, but (after looking at FI) somehow convinced myself that it should not work. Maybe in our context it turns out Ok for some reason.
from the Weyl shift awhile back, but (after looking at FI) somehow convinced myself that it should not work. Maybe in our context it turns out Ok for some reason.
16 June, 2013 at 3:41 pm
v08ltu
In the notation of Zhang S14, I think the issue is that you don’t have modulo
modulo  anymore in the
anymore in the 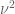 of the Cauchy, but now just
of the Cauchy, but now just  . Thus the contribution is not
. Thus the contribution is not  , but
, but  . At least that’s what I think happens, when comparing to what I determined about FI.
. At least that’s what I think happens, when comparing to what I determined about FI.
16 June, 2013 at 4:39 pm
Terence Tao
Hmm, but it seems to me that changing the shift doesn’t change the relation
shift doesn’t change the relation  because one is still canceling by
because one is still canceling by  in the first display of S14.
in the first display of S14.
In the notation of Zhang S14, one is starting with a phase of the form
if one shifts by kr instead of hkr. We can rewrite this as
where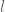 is exactly the same as before, i.e.
is exactly the same as before, i.e.  . So when one does the Cauchy-Schwarz in
. So when one does the Cauchy-Schwarz in 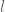 using
using  , I don’t think any of the multiplicity analysis changes; instead, the only thing that is affected (other than the larger value of
, I don’t think any of the multiplicity analysis changes; instead, the only thing that is affected (other than the larger value of  ) is that all occurrences of
) is that all occurrences of  in S14 of Zhang get replaced by
in S14 of Zhang get replaced by  , which seems to change absolutely nothing (the
, which seems to change absolutely nothing (the 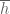 gets carried by
gets carried by  all the way to the first line of page 53 of Zhang, when it is killed by Theorem 12).
all the way to the first line of page 53 of Zhang, when it is killed by Theorem 12).
But perhaps I am missing something…
16 June, 2013 at 4:56 pm
Terence Tao
Oops, I see the problem now – we can’t have terms that depend on if we want to change variables to
if we want to change variables to 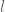 and take advantage of the Cauchy-Schwarz in
and take advantage of the Cauchy-Schwarz in 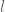 . That was silly of me. So the idea doesn’t work directly, and I’ll have to retract the claim :-(. I’ll still play around to see if something else can be salvaged though.
. That was silly of me. So the idea doesn’t work directly, and I’ll have to retract the claim :-(. I’ll still play around to see if something else can be salvaged though.
16 June, 2013 at 5:19 pm
v08ltu
Maybe the point is that the definition of is really a double sum over
is really a double sum over 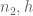 , so I don’t see how you separate the
, so I don’t see how you separate the  -variable in the Cauchy, considering that you are now carrying it also in
-variable in the Cauchy, considering that you are now carrying it also in 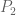 ?
?
16 June, 2013 at 5:24 pm
v08ltu
OK, so you found the same thing I did. On the “sociological” level, the reason why I disdained the idea is that FI shifted by -multiples, and I would think they were aiming for more optimisation, and this would be the first “obvious” place to manuever. On the theoretical level, it would mean that you could just pull
-multiples, and I would think they were aiming for more optimisation, and this would be the first “obvious” place to manuever. On the theoretical level, it would mean that you could just pull  out of the exponential, for instance
out of the exponential, for instance 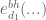 and its effect is then prevalent (you are back at
and its effect is then prevalent (you are back at 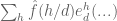 with Fourier).
with Fourier).
16 June, 2013 at 9:45 am
Thomas J Engelsma
Nice to see ‘tuples’ active again !!
Would love to read the Zhang paper, but it is hidden behind wall and I am not affiliated with an university.
Couple of quick questions, believe the proof is for an infinite number of prime pairings separated by some value less than 70 million. Can the proof be adapted for three primes in a larger interval? Can it then be generalized for ‘n’ primes in some massive interval?
—
Reading thru the above, some off my work should be clarified. The chart at http://www.opertech.com/primes/varcount.bmp shows the number of variations that are archived for each width.
There are 3 colors shown
green — variations found from true exhaustive search.
blue — variations found using targeted search routines – close to densest
red — variations generated from smaller tuples – just best found
‘Exhaustive search’ was true pruning exhaustive search.
‘Targeted search’ was recursive searching of a specific width
‘Generated’ was creating tuples using existing patterns (mostly smaller)
This was done due to the evidence that most tuples had smaller tuples embedded.
The tuples in the red zone were investigated mainly to see if k(w) stayed above pi(w) or oscillated around pi(w).
See http://www.opertech.com/primes/trophy.bmp Amazingly, k(w) is concave upward, and every improvement causes it to rise faster.
(current work implies that there is no inflection point, showing ever growing localized order amid the global chaos of the primes)
Also, the improvements of k()-pi() were not evenly scattered as w grew, but clustered (the series of red and blue dots) Whenever a series of red dots does not have a corresponding series of blue dots, those tuple widths should be able to be easily improved.
The headings of the table at http://www.opertech.com/primes/summary.txt are:
1st col — w width of interval, number of consecutive integers
2nd col — k [has value if first occurrence of a k]
3rd col — k number of admissible elements
4th col — k(w) – pi(w) [has value if first occurrence of k()-pi()]
5th col — k(w) – pi(w) over pack/under pack quantity relative to prime count
6th col — number of variations currently archived
The number of variations gives a clue if a tuple can be improved. When tuples in the red-zone have 1000s of variations, that width should be able to be improved. When the searching was active, if an improved tuple was found, it was tested to generate 1000 variations.
—
Searching has been idle for 4 years, but could be revived.
Currently, combinatorics is being used to create a counting function F(w,k) that counts the number of unique patterns of ‘k’ primes in an interval of ‘w’ integers. With the function ‘w’ could be fixed and ‘k’ could be varied, thereby providing the ability to know the densest tuple possible without knowing a single prime location within any pattern.
16 June, 2013 at 9:55 am
andrescaicedo
Thomas, you may want to take a look at http://mathoverflow.net/questions/132731/does-zhangs-theorem-generalize-to-3-or-more-primes-in-an-interval-of-fixed-len
16 June, 2013 at 10:15 am
Terence Tao
Thanks for the info! You may also be interested in the discussion at
which is more specifically focused on finding narrow prime tuples of a given length.
16 June, 2013 at 10:07 am
Andrew Sutherland
Hi Thomas, thanks for the chart, and the explanation.
16 June, 2013 at 5:14 pm
Terence Tao
A small comment (which does not directly improve bounds, unfortunately): of the three coefficient sequences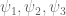 appearing in the Type III arguments, it is only
appearing in the Type III arguments, it is only  and
and 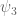 that need to have any sort of smoothness (because we apply completion of sums in these variables); in contrast, the
that need to have any sort of smoothness (because we apply completion of sums in these variables); in contrast, the  sequence is eventually eliminated by Cauchy-Schwarz. So one could in principle replace
sequence is eventually eliminated by Cauchy-Schwarz. So one could in principle replace  by other coefficient sequences, such as Dirichlet convolutions of lower scale things. This enlarges the class of combinatorial configurations
by other coefficient sequences, such as Dirichlet convolutions of lower scale things. This enlarges the class of combinatorial configurations 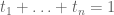 that are treated by the Type III analysis, but unfortunately does not seem to help in the most important cases (e.g. when
that are treated by the Type III analysis, but unfortunately does not seem to help in the most important cases (e.g. when 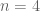 and
and  ).
).
16 June, 2013 at 5:43 pm
Terence Tao
Gah, I need to retract this also; there is actually a Taylor expansion of (which of course exploits smoothness) in the argument that I did not properly document in the blog post above before, I have fixed this now.
(which of course exploits smoothness) in the argument that I did not properly document in the blog post above before, I have fixed this now.
16 June, 2013 at 5:52 pm
v08ltu
Yes, this smoothness is exploited in estimating the error from Weyl shifts (below 13.13 in Zhang, with his variable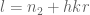 ).
).
16 June, 2013 at 8:19 pm
Derek O
Just a side comment, I’m following this thread and polymath8, and this is just amazing. I’m a math/physics major at University of Pittsburgh with a strong interest in number theory. Unfortunately, I don’t know what half this stuff means, but it’s still awesome! I was blown away when H went from 4.5 million to 400,000 then the most recent drop to 60,000; it’s just incredible to me. Anyway, keep up the great work you guys
16 June, 2013 at 10:58 pm
Anonymous
All that’s needed now is Zhang giving the thumbs up!
16 June, 2013 at 9:39 pm
Terence Tao
OK, here is another attempt to squeeze a further gain in the Type III sums. I am beginning to suspect that the treatment of the diagonal terms (or
(or 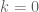 after shifting
after shifting  by
by  ) in Zhang (or in the post above) is suboptimal (in a different way from the suboptimality previously identified by not taking advantage of the
) in Zhang (or in the post above) is suboptimal (in a different way from the suboptimality previously identified by not taking advantage of the  averaging, which for simplicity I will not try to exploit here). Right now, the diagonal terms in
averaging, which for simplicity I will not try to exploit here). Right now, the diagonal terms in  are treated together with the off-diagonal terms via expansion into exponential sums, then at some point one applies an exponential sum bound for an inner sum (in the diagonal case case, one uses the bound
are treated together with the off-diagonal terms via expansion into exponential sums, then at some point one applies an exponential sum bound for an inner sum (in the diagonal case case, one uses the bound  on Ramanujan sums, see bottom of page 50 of Zhang) and then uses absolute values and the triangle inequality for the outer sum.
on Ramanujan sums, see bottom of page 50 of Zhang) and then uses absolute values and the triangle inequality for the outer sum.
However if one peels off the diagonal case earlier in the argument then one can do better than the triangle inequality, in particular Plancherel’s theorem (which, being an identity, is 100% efficient) appears to be available. Let me first describe this using Zhang’s original paper. In the bottom of page 48 a key quantity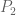 is defined, which can be expanded as a sum over pairs
is defined, which can be expanded as a sum over pairs 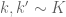 . Let us now deviate from Zhang by immediately isolating the diagonal terms
. Let us now deviate from Zhang by immediately isolating the diagonal terms  in this sum (as opposed to waiting until the bottom of page 50 to try to control these terms); this expression can be written as
in this sum (as opposed to waiting until the bottom of page 50 to try to control these terms); this expression can be written as
If we make the change of variables this becomes
this becomes
This is an expression which can be estimated almost exactly by Plancherel (the only loss coming from those with a common factor with
with a common factor with  ), giving a bound of
), giving a bound of
which surely must be more accurate than the triangle inequality-based treatment of the diagonal case as is currently present in Zhang’s paper. Since the final bound in the Type III case comes from balancing the diagonal case against the off-diagonal case, this should lead to a gain.
as is currently present in Zhang’s paper. Since the final bound in the Type III case comes from balancing the diagonal case against the off-diagonal case, this should lead to a gain.
In the language of the blog post above, one would similarly extract out the diagonal term from (19) (or the display after (19)) and evaluate it separately using Plancherel.
from (19) (or the display after (19)) and evaluate it separately using Plancherel.
Tomorrow I will try to work out the precise details of this idea and see if it actually works. Hopefully after two wrong arguments, the third time will be the charm…
17 June, 2013 at 12:06 am
v08ltu
Well, on line 4 of page 51, “it follows that the contribution from the terms with on the right side of (14.6) is
on the right side of (14.6) is 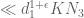 , so I don’t think you gained anything? Note that Zhang gets Ramanujan in both
, so I don’t think you gained anything? Note that Zhang gets Ramanujan in both  and
and  on the diagonal (and you improved this in the
on the diagonal (and you improved this in the  -aspect via the
-aspect via the  -average), so it might be hard to beat.
-average), so it might be hard to beat.
17 June, 2013 at 7:23 am
Terence Tao
Ah, yes, you’re right about this, both with and without the averaging. Using Plancherel basically replaces Ramanujan by a (normalised) Kronecker delta function but yes, the behaviour is basically the same. Back to the drawing board…
averaging. Using Plancherel basically replaces Ramanujan by a (normalised) Kronecker delta function but yes, the behaviour is basically the same. Back to the drawing board…
17 June, 2013 at 3:19 pm
v08ltu
The three tools of the mathematician: the paper, the pencil, and the wastebasket…
18 June, 2013 at 2:40 pm
Anonymous
Good!
17 June, 2013 at 4:28 pm
Terence Tao
Well, this isn’t any direct progress towards improving the bounds, but at least I understand Zhang’s argument a bit better.
We want to understand how the convolution is distributed in the residue class
is distributed in the residue class  , so we would like to compute the sum
, so we would like to compute the sum
with accuracy . Fourier jnversion allows one to rewrite this expression as
. Fourier jnversion allows one to rewrite this expression as
where
is essentially of size when
when  and small elsewhere.
and small elsewhere.
If we ignore all that are not coprime to
that are not coprime to  , we may rearrange this as
, we may rearrange this as
where
and
The function has a computable
has a computable  norm, basically
norm, basically
and similarly has a computable
similarly has a computable  norm by Plancherel:
norm by Plancherel:
One could apply Cauchy-Schwarz directly to (*) to obtain an upper bound
however this gives an unusable bound (unless we are in the Bombieri-Vinogradov range ). To do better, Zhang notes that
). To do better, Zhang notes that  has some smoothness, roughly speaking
has some smoothness, roughly speaking
whenever is an integer of size
is an integer of size 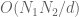 . This reflects the fact that the Farey sequence
. This reflects the fact that the Farey sequence  is more or less stable with respect to shifts by integers
is more or less stable with respect to shifts by integers  of size
of size  . This is basically all of the regularity that
. This is basically all of the regularity that  enjoys; one can compute the Fourier transform of
enjoys; one can compute the Fourier transform of  in
in  to be spread out more or less evenly across frequencies of size
to be spread out more or less evenly across frequencies of size  , save for a big concentration at the zero frequency mode of course.
, save for a big concentration at the zero frequency mode of course.
The smoothness of allows one to approximately write (*) as
allows one to approximately write (*) as
for any non-empty set of integers of size
of integers of size  , so we may replace (***) by the improved bound
, so we may replace (***) by the improved bound
where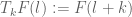 is the translate of
is the translate of  by
by  . On the other hand, Bombieri-Birch/Ramanujan and completion of sums gives us a bound on the inner product
. On the other hand, Bombieri-Birch/Ramanujan and completion of sums gives us a bound on the inner product
which is basically of the form
which is a bound which is strangely non-monotonic in : when
: when  is divisible by d (and in particular in the diagonal case
is divisible by d (and in particular in the diagonal case  ) it matches what one gets from Cauchy-Schwarz and (**) (this is basically why I got essentially no improvement by trying to treat the
) it matches what one gets from Cauchy-Schwarz and (**) (this is basically why I got essentially no improvement by trying to treat the  case directly), then decreases as
case directly), then decreases as  becomes increasingly coprime with
becomes increasingly coprime with  , until one reaches a transition and the bound worsens again as
, until one reaches a transition and the bound worsens again as  approaches 1. So to optimise in (****) one would like the differences
approaches 1. So to optimise in (****) one would like the differences  for
for  to have some common factor with
to have some common factor with  , but not too much of a factor, while also keeping
, but not too much of a factor, while also keeping  reasonably large to avoid the diagonal terms from swamping everything; and so Zhang factors
reasonably large to avoid the diagonal terms from swamping everything; and so Zhang factors 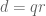 for a controlled value of
for a controlled value of  and sets
and sets  to be the multiples of
to be the multiples of  of size
of size  . I think I’ve convinced myself that this is more or less the optimal choice of
. I think I’ve convinced myself that this is more or less the optimal choice of  given the bounds available.
given the bounds available.
So it's the non-monotonicity of the bound (*****) that makes the argument slightly strange, but it appears difficult to improve upon (*****) without somehow gaining the ability to get bounds on short averages of Bombieri-Birch sums that improve upon the triangle inequality, which one can conjecture to be true (in the spirit of Hooley's conjecture) but it looks very difficult (and for this one should start with the Type I/II sums where one "only" has to deal with short averages of Kloosterman rather than short averages of Bombieri-Birch. I poked for a while on the Fourier side (replacing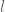 by its Fourier dual variable) to see if there was anything better than Weyl differencing available, but the only thing that seemed to suggest itself was bounds on higher moments (e.g.
by its Fourier dual variable) to see if there was anything better than Weyl differencing available, but the only thing that seemed to suggest itself was bounds on higher moments (e.g. 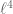 moment) of the Fourier transform of
moment) of the Fourier transform of  (or equivalently the
(or equivalently the 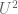 Gowers norm of
Gowers norm of  ), which didn't look very enticing. (In principle one gets more square root cancellation from increasingly higher-dimensional cases of the Weil conjectures, but this seems to be more than compensated for by the increased amount of completion of sums and Cauchy-Schwarz one has to perform.)
), which didn't look very enticing. (In principle one gets more square root cancellation from increasingly higher-dimensional cases of the Weil conjectures, but this seems to be more than compensated for by the increased amount of completion of sums and Cauchy-Schwarz one has to perform.)
So, in summary, perhaps we've cleaned up all the low hanging fruit from Type III for now, and it's time to look again at Type I. I had a little look at the Ping Xi preprint giving some power savings on short Kloosterman sums, but have not yet worked out the numerology to see if the ranges in which Xi's bound are non-trivial are relevant here (and it's more "short averages of Kloosterman sums" that we need non-trivial bounds for rather than "short Kloosterman sums" per se).
18 June, 2013 at 6:19 pm
A truncated elementary Selberg sieve of Pintz | What's new
[…] that holds for as small as , but currently we are only able to establish this result for (see this comment). However, with the new truncated sieve of Pintz described in this post, we expect to be able to […]
20 June, 2013 at 9:45 am
Oktawian
Theorem 1 (Bounded gaps between primes) There exists a natural number {H} such that there are infinitely many pairs of distinct primes {p,q} with {|p-q| \leq H}.
I want to add some small observation about this theorem. If H is different than 3 that means there is not infinitly many pairs of even numbers like (n, n+2) and this unproven statement will be proven (or denied) if we will know the smallest H.
22 June, 2013 at 7:39 am
Bounding short exponential sums on smooth moduli via Weyl differencing | What's new
[…] in (using Lemma 5 from this previous post) we see that the total contribution to the off-diagonal case […]
22 June, 2013 at 8:01 am
Terence Tao
There is a new blog post of Emmanuel Kowalski at http://blogs.ethz.ch/kowalski/2013/06/22/bounded-gaps-between-primes-the-dawn-of-some-enlightenment/ announcing an improvement in the d_3 bounds on smooth moduli (which should also lead to improvements in the Type III bounds). Interestingly, Emmanuel claims that Weyl differencing may be avoided. He also mentions an older paper of Heath-Brown http://matwbn.icm.edu.pl/ksiazki/aa/aa47/aa4713.pdf that uses some similar ideas, I think I will try to look at that paper first.
23 June, 2013 at 9:14 pm
The distribution of primes in densely divisible moduli | What's new
[…] improves upon previous constraints of (see this blog comment) and (see Theorem 13 of this previous post), albeit for instead of . Inserting Theorem 4 into the […]
23 June, 2013 at 10:23 pm
Terence Tao
This thread and the companion Type I/II thread are being rolled over to
From past experience with polymath projects, now that our understanding of the project is more mature, the pace should settle down a bit from the crazily hectic pace of the last few weeks; I think we’re getting near the finish line and perhaps in a couple more weeks we will find a good place to “declare victory” and turn to the writing part of the project.
25 June, 2013 at 8:34 am
Zhang’s theorem on bounded prime gaps | random number theory generator
[…] Crucially, if is composite then we can surpass square root cancellation just slightly. […]
7 July, 2013 at 11:17 pm
The distribution of primes in doubly densely divisible moduli | What's new
[…] by Lemma 5 of this previous post and the bound is bounded […]
11 July, 2013 at 8:15 pm
Gergely Harcos
Minor correction: in the proof of Theorem 4, “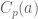 equals […]
equals […] 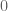 when
when 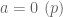 ” should be “
” should be “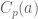 equals […]
equals […]  when
when 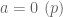 “.
“.
[Corrected, thanks – T.]