
You are currently browsing the category archive for the ‘admin’ category.
[This post is collectively authored by the ICM structure committee, whom I am currently chairing – T.]
The ICM structure committee is responsible for the preparation of the Scientific Program of the International Congress of Mathematicians (ICM). It decides the structure of the Scientific Program, in particular,
- the number of plenary lectures,
- the sections and their precise definition,
- the target number of talks in each section,
- other kind of lectures, and
- the arrangement of sections.
(The actual selection of speakers and the local organization of the ICM are handled separately by the Program Committee and Organizing Comittee respectively.)
Our committee can also propose more radical changes to the format of the congress, although certain components of the congress, such as the prize lectures and satellite events, are outside the jurisdiction of this committee. For instance, in 2019 we proposed the addition of two new categories of lectures, “special sectional lectures” and “special plenary lectures”, which are broad and experimental categories of lectures that do not fall under the traditional format of a mathematician presenting their recent advances in a given section, but can instead highlight (for instance) emerging connections between two areas of mathematics, or present a “big picture” talk on a “hot topic” from an expert with the appropriate perspective. These new categories made their debut at the recently concluded virtual ICM, held on July 6-14, 2022.
Over the next year or so, our committee will conduct our deliberations on proposed changes to the structure of the congress for the next ICM (to be held in-person in Philadelphia in 2026) and beyond. As part of the preparation for these deliberations, we are soliciting feedback from the general mathematics community (on this blog and elsewhere) on the current state of the ICM, and any proposals to improve that state for the subsequent congresses; we had issued a similar call on this blog back in 2019. This time around, of course, the situation is complicated by the extraordinary and exceptional circumstances that led to the 2022 ICM being moved to a virtual platform on short notice, and so it is difficult for many reasons to hold the 2022 virtual ICM as a model for subsequent congresses. On the other hand, the scientific program had already been selected by the 2022 ICM Program Committee prior to the invasion of Ukraine, and feedback on the content of that program will be of great value to our committee.
Among the specific questions (in no particular order) for which we seek comments are the following:
- Are there suggestions to change the format of the ICM that would increase its value to the mathematical community?
- Are there suggestions to change the format of the ICM that would encourage greater participation and interest in attending, particularly with regards to junior researchers and mathematicians from developing countries?
- The special sectional and special plenary lectures were introduced in part to increase the emphasis on the quality of exposition at ICM lectures. Has this in fact resulted in a notable improvement in exposition, and should any alternations be made to the special lecture component of the ICM?
- Is the balance between plenary talks, sectional talks, special plenary and sectional talks, and public talks at an optimal level? There is only a finite amount of space in the calendar, so any increase in the number or length of one of these types of talks will come at the expense of another.
- The ICM is generally perceived to be more important to pure mathematics than to applied mathematics. In what ways can the ICM be made more relevant and attractive to applied mathematicians, or should one not try to do so?
- Are there structural barriers that cause certain areas or styles of mathematics (such as applied or interdisciplinary mathematics) or certain groups of mathematicians to be under-represented at the ICM? What, if anything, can be done to mitigate these barriers?
- The recently concluded virtual ICM had a sui generis format, in which the core virtual program was supplemented by a number of physical “overlay” satellite events. Are there any positive features of that format which could potentially be usefully adapted to such congresses? For instance, should there be any virtual or hybrid components at the next ICM?
Of course, we do not expect these complex and difficult questions to be resolved within this blog post, and debating these and other issues would likely be a major component of our internal committee discussions. Nevertheless, we would value constructive comments towards the above questions (or on other topics within the scope of our committee) to help inform these subsequent discussions. We therefore welcome and invite such commentary, either as responses to this blog post, or sent privately to one of the members of our committee. We would also be interested in having readers share their personal experiences at past congresses, and how it compares with other major conferences of this type. (But in order to keep the discussion focused and constructive, we request that comments here refrain from discussing topics that are out of the scope of this committee, such as suggesting specific potential speakers for the next congress, which is a task instead for the 2022 ICM Program Committee. Comments that are specific to the recently concluded virtual ICM can be made instead at this blog post.)
Starting on Oct 2, I will be teaching Math 246A, the first course in the three-quarter graduate complex analysis sequence at the math department here at UCLA. This first course covers much of the same ground as an honours undergraduate complex analysis course, in particular focusing on the basic properties of holomorphic functions such as the Cauchy and residue theorems, the classification of singularities, and the maximum principle, but there will be more of an emphasis on rigour, generalisation and abstraction, and connections with other parts of mathematics. The main text I will be using for this course is Stein-Shakarchi (with Ahlfors as a secondary text), but I will also be using the blog lecture notes I wrote the last time I taught this course in 2016. At this time I do not expect to significantly deviate from my past lecture notes, though I do not know at present how different the pace will be this quarter when the course is taught remotely. As with my 247B course last spring, the lectures will be open to the public, though other coursework components will be restricted to enrolled students.
Now that Google Plus is closing, the brief announcements that I used to post over there will now be migrated over to this blog. (Some people have suggested other platforms for this also, such as Twitter, but I think for now I can use my existing blog to accommodate these sorts of short posts.)
- The NSF-CBMS regional research conferences are now requesting proposals for the 2020 conference series. (I was the principal lecturer for one of these conferences back in 2005; it was a very intensive experience, but quite enjoyable, and I am quite pleased with the book that resulted from it.)
- The awardees for the Sloan Fellowships for 2019 have now been announced. (I was on the committee for the mathematics awards. For the usual reasons involving the confidentiality of letters of reference and other sensitive information, I will be unfortunately be unable to answer any specific questions about our committee deliberations.)
Next week, I will be teaching Math 246A, the first course in the three-quarter graduate complex analysis sequence. This first course covers much of the same ground as an honours undergraduate complex analysis course, in particular focusing on the basic properties of holomorphic functions such as the Cauchy and residue theorems, the classification of singularities, and the maximum principle, but there will be more of an emphasis on rigour, generalisation and abstraction, and connections with other parts of mathematics. If time permits I may also cover topics such as factorisation theorems, harmonic functions, conformal mapping, and/or applications to analytic number theory. The main text I will be using for this course is Stein-Shakarchi (with Ahlfors as a secondary text), but as usual I will also be writing notes for the course on this blog.
Chantal David, Andrew Granville, Emmanuel Kowalski, Phillipe Michel, Kannan Soundararajan, and I are running a program at MSRI in the Spring of 2017 (more precisely, from Jan 17, 2017 to May 26, 2017) in the area of analytic number theory, with the intention to bringing together many of the leading experts in all aspects of the subject and to present recent work on the many active areas of the subject (e.g. the distribution of the prime numbers, refinements of the circle method, a deeper understanding of the asymptotics of bounded multiplicative functions (and applications to Erdos discrepancy type problems!) and of the “pretentious” approach to analytic number theory, more “analysis-friendly” formulations of the theorems of Deligne and others involving trace functions over fields, and new subconvexity theorems for automorphic forms, to name a few). Like any other semester MSRI program, there will be a number of workshops, seminars, and similar activities taking place while the members are in residence. I’m personally looking forward to the program, which should be occurring in the midst of a particularly productive time for the subject. Needless to say, I (and the rest of the organising committee) plan to be present for most of the program.
Applications for Postdoctoral Fellowships and Research Memberships for this program (and for other MSRI programs in this time period, namely the companion program in Harmonic Analysis and the Fall program in Geometric Group Theory, as well as the complementary program in all other areas of mathematics) remain open until Dec 1. Applications are open to everyone, but require supporting documentation, such as a CV, statement of purpose, and letters of recommendation from other mathematicians; see the application page for more details.
In the winter quarter (starting January 5) I will be teaching a graduate topics course entitled “An introduction to analytic prime number theory“. As the name suggests, this is a course covering many of the analytic number theory techniques used to study the distribution of the prime numbers 
The type of results about primes that one aspires to prove here is well captured by Landau’s classical list of problems:
- Even Goldbach conjecture: every even number
greater than two is expressible as the sum of two primes.
- Twin prime conjecture: there are infinitely many pairs
which are simultaneously prime.
- Legendre’s conjecture: for every natural number
and
.
- There are infinitely many primes of the form
.
All four of Landau’s problems remain open, but we have convincing heuristic evidence that they are all true, and in each of the four cases we have some highly non-trivial partial results, some of which will be covered in this course. We also now have some understanding of the barriers we are facing to fully resolving each of these problems, such as the parity problem; this will also be discussed in the course.
One of the main reasons that the prime numbers 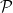


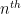

It may be in the future that some usable structure to the primes (or related objects) will eventually be located (this is for instance one of the motivations in developing a rigorous theory of the “field with one element“, although this theory is far from being fully realised at present). For now, though, analytic and combinatorial methods have proven to be the most effective way forward, as they can often be used even in the near-complete absence of structure.
In this course, we will not discuss combinatorial approaches (such as the deployment of tools from additive combinatorics) in depth, but instead focus on the analytic methods. The basic principles of this approach can be summarised as follows:
- Rather than try to isolate individual primes
in
of twin primes up to some threshold
. Similarly, one can focus on counts such as
,
, or
, which are the natural counts associated to the other three Landau problems. In all four of Landau’s problems, the basic task is now to obtain a non-trivial lower bounds on these counts.
- If one wishes to proceed analytically rather than combinatorially, one should convert all these counts into sums, using the fundamental identity
(or variants thereof) for the cardinality
of subsets
of the natural numbers
, where
is the indicator function of
or
- Once one expresses number-theoretic problems in this fashion, we are naturally led to the more general question of how to accurately estimate (or, less ambitiously, to lower bound or upper bound) sums such as
or more generally bilinear or multilinear sums such as
or
for various functions
of arithmetic interest. (Importantly, one should also generalise to include integrals as well as sums, particularly contour integrals or integrals over the unit circle or real line, but we postpone discussion of these generalisations to later in the course.) Indeed, a huge portion of modern analytic number theory is devoted to precisely this sort of question. In many cases, we can predict an expected main term for such sums, and then the task is to control the error term between the true sum and its expected main term. It is often convenient to normalise the expected main term to be zero or negligible (e.g. by subtracting a suitable constant from
exhibiting an unexpectedly large correlation with each other.
- It is often difficult to discern cancellation (or to prevent conspiracy) directly for a given sum (such as
) of interest. However, analytic number theory has developed a large number of techniques to relate one sum to another, and then the strategy is to keep transforming the sum into more and more analytically tractable expressions, until one arrives at a sum for which cancellation can be directly exhibited. (Note though that there is often a short-term tradeoff between analytic tractability and algebraic simplicity; in a typical analytic number theory argument, the sums will get expanded and decomposed into many quite messy-looking sub-sums, until at some point one applies some crude estimation to replace these messy sub-sums by tractable ones again.) There are many transformations available, ranging such basic tools as the triangle inequality, pointwise domination, or the Cauchy-Schwarz inequality to key identities such as multiplicative number theory identities (such as the Vaughan identity and the Heath-Brown identity), Fourier-analytic identities (e.g. Fourier inversion, Poisson summation, or more advanced trace formulae), or complex analytic identities (e.g. the residue theorem, Perron’s formula, or Jensen’s formula). The sheer range of transformations available can be intimidating at first; there is no shortage of transformations and identities in this subject, and if one applies them randomly then one will typically just transform a difficult sum into an even more difficult and intractable expression. However, one can make progress if one is guided by the strategy of isolating and enhancing a desired cancellation (or conspiracy) to the point where it can be easily established (or dispelled), or alternatively to reach the point where no deep cancellation is needed for the application at hand (or equivalently, that no deep conspiracy can disrupt the application).
- One particularly powerful technique (albeit one which, ironically, can be highly “ineffective” in a certain technical sense to be discussed later) is to use one potential conspiracy to defeat another, a technique I refer to as the “dueling conspiracies” method. This technique may be unable to prevent a single strong conspiracy, but it can sometimes be used to prevent two or more such conspiracies from occurring, which is particularly useful if conspiracies come in pairs (e.g. through complex conjugation symmetry, or a functional equation). A related (but more “effective”) strategy is to try to “disperse” a single conspiracy into several distinct conspiracies, which can then be used to defeat each other.
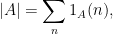





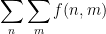

As stated before, the above strategy has not been able to establish any of the four Landau problems as stated. However, they can come close to such problems (and we now have some understanding as to why these problems remain out of reach of current methods). For instance, by using these techniques (and a lot of additional effort) one can obtain the following sample partial results in the Landau problems:
- Chen’s theorem: every sufficiently large even number
, where
is the set of almost primes.
- Zhang’s theorem: There exist infinitely many pairs
of consecutive primes with
. The proof proceeds by giving a non-negative lower bound on the quantity
for large
between
and
. (The bound
.)
- The Baker-Harman-Pintz theorem: for sufficiently large
. Proven by finding a nontrivial lower bound on
.
- The Friedlander-Iwaniec theorem: There are infinitely many primes of the form
. Proven by finding a nontrivial lower bound on
.
We will discuss (simpler versions of) several of these results in this course.
Of course, for the above general strategy to have any chance of succeeding, one must at some point use some information about the set
- (Sieve theory description) The primes
- (Multiplicative number theory description) The primes
The sieve-theoretic description and its variants lead one to a good understanding of the almost primes, which turn out to be excellent tools for controlling the primes themselves, although there are known limitations as to how much information on the primes one can extract from sieve-theoretic methods alone, which we will discuss later in this course. The multiplicative number theory methods lead one (after some complex or Fourier analysis) to the Riemann zeta function (and other L-functions, particularly the Dirichlet L-functions), with the distribution of zeroes (and poles) of these functions playing a particularly decisive role in the multiplicative methods.
Many of our strongest results in analytic prime number theory are ultimately obtained by incorporating some combination of the above two fundamental descriptions of 
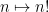
To give a simple illustration of these two basic approaches to the primes, let us first give two variants of the usual proof of Euclid’s theorem:
Theorem 1 (Euclid’s theorem) There are infinitely many primes.
Proof: (Multiplicative number theory proof) Suppose for contradiction that there were only finitely many primes 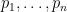
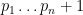
(Sieve-theoretic proof) Suppose for contradiction that there were only finitely many primes 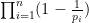

In particular, 

Remark 1 One can also phrase the proof of Euclid’s theorem in a fashion that largely avoids the use of contradiction; see this previous blog post for more discussion.
Both proofs in fact extend to give a stronger result:
Proof: (Multiplicative number theory proof) By the fundamental theorem of arithmetic, every natural number is expressible uniquely as the product 

(both sides make sense in ![{[0,+\infty]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C%2B%5Cinfty%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

and 
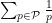
(Sieve-theoretic proof) Suppose for contradiction that the sum 



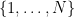


Since 
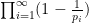

Remark 2 We have seen how easy it is to prove Euler’s theorem by analytic methods. In contrast, there does not seem to be any known proof of this theorem that proceeds by using any sort of prime-generating formula or a primality test, which is further evidence that such tools are not the most effective way to make progress on problems such as Landau’s problems. (But the weaker theorem of Euclid, Theorem 1, can sometimes be proven by such devices.)
The two proofs of Theorem 2 given above are essentially the same proof, as is hinted at by the geometric series identity

One can also see the Riemann zeta function begin to make an appearance in both proofs. Once one goes beyond Euler’s theorem, though, the sieve-theoretic and multiplicative methods begin to diverge significantly. On one hand, sieve theory can still handle to some extent sets such as twin primes, despite the lack of multiplicative structure (one simply has to sieve out two residue classes per prime, rather than one); on the other, multiplicative number theory can attain results such as the prime number theorem for which purely sieve theoretic techniques have not been able to establish. The deepest results in analytic number theory will typically require a combination of both sieve-theoretic methods and multiplicative methods in conjunction with the many transforms discussed earlier (and, in many cases, additional inputs from other fields of mathematics such as arithmetic geometry, ergodic theory, or additive combinatorics).
I’m encountering a sporadic bug over the past few months with the way WordPress renders or displays its LaTeX images on this blog (and occasionally on other WordPress blogs). On most computers, it seems to work fine, but on some computers, the sizes of images are occasionally way off, leading to extremely distorted and fairly unreadable versions of the images appearing in blog posts and comments. A sample screenshot (with accompanying HTML source), supplied to me by a reader, can be found here (in which an image whose dimensions should be 321 x 59 are instead being displayed as 552 x 20). Is anyone else encountering this issue? The problem sometimes can be resolved by refreshing the page, but not always, so it is a bit unclear where the problem is coming from and how one might mitigate it. (If nothing else, I can add it to the bug collection post, once it can be reliably replicated.)
It’s time to (somewhat belatedly) roll over the previous thread on writing the first paper from the Polymath8 project, as this thread is overflowing with comments. We are getting near the end of writing this large (173 pages!) paper, establishing a bound of 4,680 on the gap between primes, with only a few sections left to thoroughly proofread (and the last section should probably be removed, with appropriate changes elsewhere, in view of the more recent progress by Maynard). As before, one can access the working copy of the paper at this subdirectory, as well as the rest of the directory, and the plan is to submit the paper to Algebra and Number theory (and the arXiv) once there is consensus to do so. Even before this paper was submitted, it already has had some impact; Andrew Granville’s exposition of the bounded gaps between primes story for the Bulletin of the AMS follows several of the Polymath8 arguments in deriving the result.
After this paper is done, there is interest in continuing onwards with other Polymath8 – related topics, and perhaps it is time to start planning for them. First of all, we have an invitation from the Newsletter of the European Mathematical Society to discuss our experiences and impressions with the project. I think it would be interesting to collect some impressions or thoughts (both positive and negative) from people who were highly active in the research and/or writing aspects of the project, as well as from more casual participants who were following the progress more quietly. This project seemed to attract a bit more attention than most other polymath projects (with the possible exception of the very first project, Polymath1). I think there are several reasons for this; the project builds upon a recent breakthrough (Zhang’s paper) that attracted an impressive amount of attention and publicity; the objective is quite easy to describe, when compared against other mathematical research objectives; and one could summarise the current state of progress by a single natural number H, which implied by infinite descent that the project was guaranteed to terminate at some point, but also made it possible to set up a “scoreboard” that could be quickly and easily updated. From the research side, another appealing feature of the project was that – in the early stages of the project, at least – it was quite easy to grab a new world record by means of making a small observation, which made it fit very well with the polymath spirit (in which the emphasis is on lots of small contributions by many people, rather than a few big contributions by a small number of people). Indeed, when the project first arose spontaneously as a blog post of Scott Morrrison over at the Secret Blogging Seminar, I was initially hesitant to get involved, but soon found the “game” of shaving a few thousands or so off of 
Then of course there is the “Polymath 8b” project in which we build upon the recent breakthroughs of James Maynard, which have simplified the route to bounded gaps between primes considerably, bypassing the need for any Elliott-Halberstam type distribution results beyond the Bombieri-Vinogradov theorem. James has kindly shown me an advance copy of the preprint, which should be available on the arXiv in a matter of days; it looks like he has made a modest improvement to the previously announced results, improving 




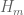
Once again it is time to roll over the previous discussion thread, which has become rather full with comments. The paper is nearly finished (see also the working copy at this subdirectory, as well as the rest of the directory), but several people are carefully proofreading various sections of the paper. Once all the people doing so have signed off on it, I think we will be ready to submit (there appears to be no objection to the plan to submit to Algebra and Number Theory).
Another thing to discuss is an invitation to Polymath8 to write a feature article (up to 8000 words or 15 pages) for the Newsletter of the European Mathematical Society on our experiences with this project. It is perhaps premature to actually start writing this article before the main research paper is finalised, but we can at least plan how to write such an article. One suggestion, proposed by Emmanuel, is to have individual participants each contribute a brief account of their interaction with the project, which we would compile together with some additional text summarising the project as a whole (and maybe some speculation for any lessons we can apply here for future polymath projects). Certainly I plan to have a separate blog post collecting feedback on this project once the main writing is done.
The main purpose of this post is to roll over the discussion from the previous Polymath8 thread, which has become rather full with comments. We are still writing the paper, but it appears to have stabilised in a near-final form (source files available here); the main remaining tasks are proofreading, checking the mathematics, and polishing the exposition. We also have a tentative consensus to submit the paper to Algebra and Number Theory when the proofreading is all complete.
The paper is quite large now (164 pages!) but it is fortunately rather modular, and thus hopefully somewhat readable (particularly regarding the first half of the paper, which does not need any of the advanced exponential sum estimates). The size should not be a major issue for the journal, so I would not seek to artificially shorten the paper at the expense of readability or content.

{kind=link}
{kind=link}
Recent Comments