
You are currently browsing the tag archive for the ‘eigenvectors’ tag.
Marcel Filoche, Svitlana Mayboroda, and I have just uploaded to the arXiv our preprint “The effective potential of an 


Suppose one has an eigenfunction

 , where
, where  is the Laplacian on
is the Laplacian on  ,
,  is a potential, and
is a potential, and  is an energy. Where would one expect the eigenfunction
is an energy. Where would one expect the eigenfunction  to be concentrated? If the potential
to be concentrated? If the potential  is smooth and slowly varying, the correspondence principle suggests that the eigenfunction should be mostly concentrated in the potential energy wells
is smooth and slowly varying, the correspondence principle suggests that the eigenfunction should be mostly concentrated in the potential energy wells 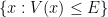 , with an exponentially decaying amount of tunnelling between the wells. One way to rigorously establish such an exponential decay is through an argument of Agmon, which we will sketch later in this post, which gives an exponentially decaying upper bound (in an
, with an exponentially decaying amount of tunnelling between the wells. One way to rigorously establish such an exponential decay is through an argument of Agmon, which we will sketch later in this post, which gives an exponentially decaying upper bound (in an  sense) of eigenfunctions in terms of the distance to the wells
sense) of eigenfunctions in terms of the distance to the wells 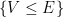 in terms of a certain “Agmon metric” on determined by the potential and energy level (or any upper bound
in terms of a certain “Agmon metric” on determined by the potential and energy level (or any upper bound 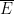 on this energy). Similar exponential decay results can also be obtained for discrete Schrödinger matrix models, in which the domain is replaced with a discrete set such as the lattice
on this energy). Similar exponential decay results can also be obtained for discrete Schrödinger matrix models, in which the domain is replaced with a discrete set such as the lattice 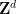 , and the Laplacian is replaced by a discrete analogue such as a graph Laplacian.
, and the Laplacian is replaced by a discrete analogue such as a graph Laplacian.
When the potential 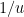


There are now several explanations for why this particular choice 
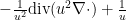

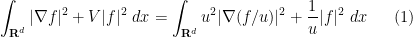
These particular explanations seem rather specific to the Schrödinger equation (continuous or discrete); we have for instance not been able to find similar identities to explain an effective potential for the bi-Schrödinger operator 
In this paper, we demonstrate the (perhaps surprising) fact that effective potentials continue to exist for operators that bear very little resemblance to Schrödinger operators. Our chosen model is that of an 



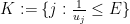
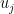
 is normalised in
is normalised in  , where the connectivity
, where the connectivity  is the maximum number of non-zero entries of in any row or column,
is the maximum number of non-zero entries of in any row or column,  are the coefficients of , and
are the coefficients of , and  is a certain moderately complicated but explicit metric function on the spatial domain. Informally, this inequality asserts that the eigenfunction
is a certain moderately complicated but explicit metric function on the spatial domain. Informally, this inequality asserts that the eigenfunction 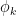 should decay like
should decay like  or faster. Indeed, our numerics show a very strong log-linear relationship between and
or faster. Indeed, our numerics show a very strong log-linear relationship between and  , although it appears that our exponent
, although it appears that our exponent 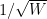 is not quite optimal. We also provide an associated localisation result which is technical to state but very roughly asserts that a given eigenvector will in fact be localised to a single connected component of
is not quite optimal. We also provide an associated localisation result which is technical to state but very roughly asserts that a given eigenvector will in fact be localised to a single connected component of  unless there is a resonance between two wells (by which we mean that an eigenvalue for a localisation of associated to one well is extremely close to an eigenvalue for a localisation of associated to another well); such localisation is also strongly supported by numerics. (Analogous results for Schrödinger operators had been previously obtained by the previously mentioned paper of Arnold, David, Jerison, and my two coauthors, and to quantum graphs in a very recent paper of Harrell and Maltsev.)
unless there is a resonance between two wells (by which we mean that an eigenvalue for a localisation of associated to one well is extremely close to an eigenvalue for a localisation of associated to another well); such localisation is also strongly supported by numerics. (Analogous results for Schrödinger operators had been previously obtained by the previously mentioned paper of Arnold, David, Jerison, and my two coauthors, and to quantum graphs in a very recent paper of Harrell and Maltsev.)
Our approach is based on Agmon’s methods, which we interpret as a double commutator method, and in particular relying on exploiting the negative definiteness of certain double commutator operators. In the case of Schrödinger operators 

![\displaystyle \langle [[-\Delta+V,g],g] u, u \rangle = -2\int_{{\bf R}^d} |\nabla g|^2 |u|^2\ dx \leq 0 \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clangle+%5B%5B-%5CDelta%2BV%2Cg%5D%2Cg%5D+u%2C+u+%5Crangle+%3D+-2%5Cint_%7B%7B%5Cbf+R%7D%5Ed%7D+%7C%5Cnabla+g%7C%5E2+%7Cu%7C%5E2%5C+dx+%5Cleq+0+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \langle g [\psi, -\Delta+V] u, g \psi u \rangle = \frac{1}{2} \langle [[-\Delta+V, g \psi],g\psi] u, u \rangle](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clangle+g+%5B%5Cpsi%2C+-%5CDelta%2BV%5D+u%2C+g+%5Cpsi+u+%5Crangle+%3D+%5Cfrac%7B1%7D%7B2%7D+%5Clangle+%5B%5B-%5CDelta%2BV%2C+g+%5Cpsi%5D%2Cg%5Cpsi%5D+u%2C+u+%5Crangle+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle -\frac{1}{2} \langle [[-\Delta+V, g],g] \psi u, \psi u \rangle](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+-%5Cfrac%7B1%7D%7B2%7D+%5Clangle+%5B%5B-%5CDelta%2BV%2C+g%5D%2Cg%5D+%5Cpsi+u%2C+%5Cpsi+u+%5Crangle+&bg=ffffff&fg=000000&s=0&c=20201002)
 after a brief calculation. The double commutator identity then tells us that
after a brief calculation. The double commutator identity then tells us that ![\displaystyle \langle g [\psi, -\Delta+V] u, g \psi u \rangle \leq \int_{{\bf R}^d} |\nabla g|^2 |\psi u|^2\ dx.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clangle+g+%5B%5Cpsi%2C+-%5CDelta%2BV%5D+u%2C+g+%5Cpsi+u+%5Crangle+%5Cleq+%5Cint_%7B%7B%5Cbf+R%7D%5Ed%7D+%7C%5Cnabla+g%7C%5E2+%7C%5Cpsi+u%7C%5E2%5C+dx.&bg=ffffff&fg=000000&s=0&c=20201002) to be a non-negative weight and let
to be a non-negative weight and let 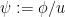 for an eigenfunction , then we can write
for an eigenfunction , then we can write ![\displaystyle [\psi, -\Delta+V] u = [\psi, -\Delta+V - E] u = \psi (-\Delta+V - E) u](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B%5Cpsi%2C+-%5CDelta%2BV%5D+u+%3D+%5B%5Cpsi%2C+-%5CDelta%2BV+-+E%5D+u+%3D+%5Cpsi+%28-%5CDelta%2BV+-+E%29+u&bg=ffffff&fg=000000&s=0&c=20201002)

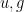 . If we select
. If we select  , we obtain the clean inequality
, we obtain the clean inequality 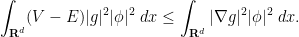 to be a function which equals on the wells but increases exponentially away from these wells, in such a way that
to be a function which equals on the wells but increases exponentially away from these wells, in such a way that 
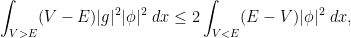 away from the wells. This is basically the classic exponential decay estimate of Agmon; one can basically take to be the distance to the wells with respect to the Euclidean metric conformally weighted by a suitably normalised version of
away from the wells. This is basically the classic exponential decay estimate of Agmon; one can basically take to be the distance to the wells with respect to the Euclidean metric conformally weighted by a suitably normalised version of 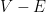 . If we instead select to be the landscape function
. If we instead select to be the landscape function 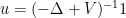 , (3) then gives
, (3) then gives 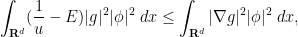 appropriately this gives an exponential decay estimate away from the effective wells
appropriately this gives an exponential decay estimate away from the effective wells  , using a metric weighted by
, using a metric weighted by  .
.
It turns out that this argument extends without much difficulty to the
![\displaystyle \langle [[A,D],D] u, u \rangle = \sum_{i \neq j} a_{ij} u_i u_j (d_{ii} - d_{jj})^2 \leq 0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clangle+%5B%5BA%2CD%5D%2CD%5D+u%2C+u+%5Crangle%09%3D+%5Csum_%7Bi+%5Cneq+j%7D+a_%7Bij%7D+u_i+u_j+%28d_%7Bii%7D+-+d_%7Bjj%7D%29%5E2+%5Cleq+0&bg=ffffff&fg=000000&s=0&c=20201002)
 . The remainder of the Agmon type arguments go through after making the natural modifications.
. The remainder of the Agmon type arguments go through after making the natural modifications.
Numerically we have also found some aspects of the landscape theory to persist beyond the
Peter Denton, Stephen Parke, Xining Zhang, and I have just uploaded to the arXiv a completely rewritten version of our previous paper, now titled “Eigenvectors from Eigenvalues: a survey of a basic identity in linear algebra“. This paper is now a survey of the various literature surrounding the following basic identity in linear algebra, which we propose to call the eigenvector-eigenvalue identity:
Theorem 1 (Eigenvector-eigenvalue identity) Let
Hermitian matrix, with eigenvalues
. Let
be a unit eigenvector corresponding to the eigenvalue
, and let
be the
component of
where
is the
Hermitian matrix formed by deleting the
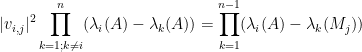
When we posted the first version of this paper, we were unaware of previous appearances of this identity in the literature; a related identity had been used by Erdos-Schlein-Yau and by myself and Van Vu for applications to random matrix theory, but to our knowledge this specific identity appeared to be new. Even two months after our preprint first appeared on the arXiv in August, we had only learned of one other place in the literature where the identity showed up (by Forrester and Zhang, who also cite an earlier paper of Baryshnikov).
The situation changed rather dramatically with the publication of a popular science article in Quanta on this identity in November, which gave this result significantly more exposure. Within a few weeks we became informed (through private communication, online discussion, and exploration of the citation tree around the references we were alerted to) of over three dozen places where the identity, or some other closely related identity, had previously appeared in the literature, in such areas as numerical linear algebra, various aspects of graph theory (graph reconstruction, chemical graph theory, and walks on graphs), inverse eigenvalue problems, random matrix theory, and neutrino physics. As a consequence, we have decided to completely rewrite our article in order to collate this crowdsourced information, and survey the history of this identity, all the known proofs (we collect seven distinct ways to prove the identity (or generalisations thereof)), and all the applications of it that we are currently aware of. The citation graph of the literature that this ad hoc crowdsourcing effort produced is only very weakly connected, which we found surprising:

The earliest explicit appearance of the eigenvector-eigenvalue identity we are now aware of is in a 1966 paper of Thompson, although this paper is only cited (directly or indirectly) by a fraction of the known literature, and also there is a precursor identity of Löwner from 1934 that can be shown to imply the identity as a limiting case. At the end of the paper we speculate on some possible reasons why this identity only achieved a modest amount of recognition and dissemination prior to the November 2019 Quanta article.
Peter Denton, Stephen Parke, Xining Zhang, and I have just uploaded to the arXiv the short unpublished note “Eigenvectors from eigenvalues“. This note gives two proofs of a general eigenvector identity observed recently by Denton, Parke and Zhang in the course of some quantum mechanical calculations. The identity is as follows:
Theorem 1 Let
where
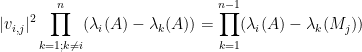
For instance, if we have
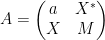
for some real number 


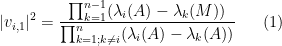
assuming that the denominator is non-zero.
Once one is aware of the identity, it is not so difficult to prove it; we give two proofs, each about half a page long, one of which is based on a variant of the Cauchy-Binet formula, and the other based on properties of the adjugate matrix. But perhaps it is surprising that such a formula exists at all; one does not normally expect to learn much information about eigenvectors purely from knowledge of eigenvalues. In the random matrix theory literature, for instance in this paper of Erdos, Schlein, and Yau, or this later paper of Van Vu and myself, a related identity has been used, namely
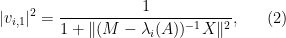
but it is not immediately obvious that one can derive the former identity from the latter. (I do so below the fold; we ended up not putting this proof in the note as it was longer than the two other proofs we found. I also give two other proofs below the fold, one from a more geometric perspective and one proceeding via Cramer’s rule.) It was certainly something of a surprise to me that there is no explicit appearance of the 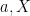
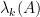

One can get some feeling of the identity (1) by considering some special cases. Suppose for instance that 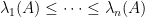
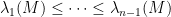
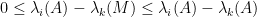
for 
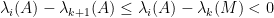
for 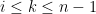

Perhaps the most important structural result about general large dense graphs is the Szemerédi regularity lemma. Here is a standard formulation of that lemma:
Lemma 1 (Szemerédi regularity lemma) Let
be a graph on
vertices, and let
. Then there exists a partition
for some
with the property that for all but at most
of the pairs
, the pair
is
-regular in the sense that
whenever
are such that
and
, and
is the edge density between
. Furthermore, the partition is equitable in the sense that
for all

There are many proofs of this lemma, which is actually not that difficult to establish; see for instance these previous blog posts for some examples. In this post I would like to record one further proof, based on the spectral decomposition of the adjacency matrix of 
For reasons of exposition, it is convenient to first establish a slightly weaker form of the lemma, in which one drops the hypothesis of equitability (but then has to weight the cells 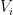
Lemma 2 (Szemerédi regularity lemma, weakened variant) . Let
outside of an exceptional set
, one has
whenever
, where
is the number of edges between
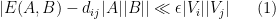

Let us now prove Lemma 2. We enumerate 


for some orthonormal basis 
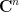
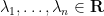

We can compute the trace of 

 , so
, so 
Among other things, this implies that

for all 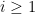
Let 
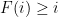

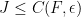
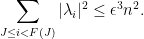
(Indeed, the bound on 



where 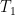
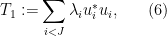
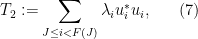
and 
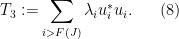
We now design a vertex partition to make 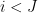




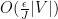

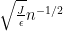
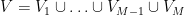

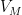
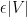



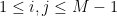
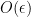
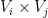

for any 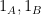
Next, we observe from (3) and (7) that 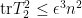
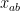
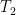
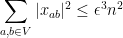
and hence by Markov’s inequality we have

for all pairs 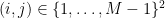
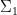
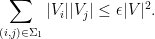

for any
Finally, to control 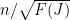
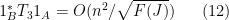
for any 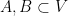
Let 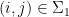
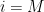

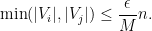
One easily verifies that (2) holds. If

for all 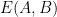
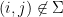
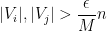
and so (since
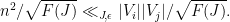
If we let
To prove Lemma 1, one argues similarly (after modifying 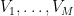
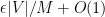
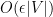
Remark 1 It is easy to verify that
essentially gives the weak regularity lemma of Frieze and Kannan.
Remark 2 If we specialise to a Cayley graph, in which
is a finite abelian group and
for some (symmetric) subset
of
Remark 3 The use of spectral theory here is parallel to the use of Fourier analysis to establish results such as Roth’s theorem on arithmetic progressions of length three. In analogy with this, one could view hypergraph regularity as being a sort of “higher order spectral theory”, although this spectral perspective is not as convenient as it is in the graph case.
Van Vu and I have just uploaded to the arXiv our paper “Random matrices: Universality of eigenvectors“, submitted to Random Matrices: Theory and Applications. This paper concerns an extension of our four moment theorem for eigenvalues. Roughly speaking, that four moment theorem asserts (under mild decay conditions on the coefficients of the random matrix) that the fine-scale structure of individual eigenvalues of a Wigner random matrix depend only on the first four moments of each of the entries.
In this paper, we extend this result from eigenvalues to eigenvectors, and specifically to the coefficients of, say, the 


(A technical point here: strictly speaking, the eigenvectors 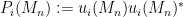
This theorem strengthens a four moment theorem for eigenvectors recently established by Knowles and Yin (by a somewhat different method), in that the hypotheses are weaker (no level repulsion assumption is required, and the matrix entries only need to obey a finite moment condition rather than an exponential decay condition), and a slightly stronger conclusion (less regularity is needed on the test function, and one can handle the joint distribution of polynomially many coefficients, rather than boundedly many coefficients). On the other hand, the Knowles-Yin paper can also handle generalised Wigner ensembles in which the variances of the entries are allowed to fluctuate somewhat.
The method used here is a variation of that in our original paper (incorporating the subsequent improvements to extend the four moment theorem from the bulk to the edge, and to replace exponential decay by a finite moment condition). That method was ultimately based on the observation that if one swapped a single entry (and its adjoint) in a Wigner random matrix, then an individual eigenvalue 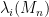

As an application of the eigenvalue four moment theorem, we establish a four moment theorem for the coefficients of resolvent matrices 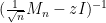




Recent Comments