
You are currently browsing the tag archive for the ‘Schur complement’ tag.
Suppose we have an 


where 
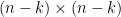





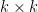


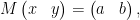
where 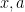
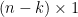




Using the invertibility of
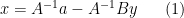
and substituting this into the second equation yields
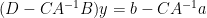
and thus (assuming that 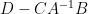

and then inserting this back into (1) gives

Comparing this with
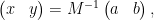
we have managed to express the inverse of

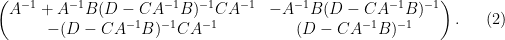
One can consider the inverse problem: given the inverse 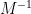
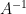


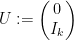
(with 


Then for any scalar 

and hence by (2)
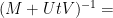

noting that the inverses here will exist for 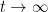
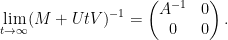
On the other hand, by the Woodbury matrix identity (discussed in this previous blog post), we have
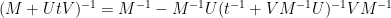
and hence on taking limits and comparing with the preceding identity, one has

This achieves the aim of expressing the inverse

In the 

where 
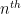
We can apply this identity to understand how the spectrum of an 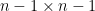

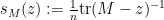

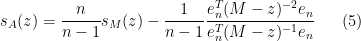
At this point we begin to proceed informally. Assume for sake of argument that the random matrix 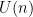


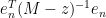
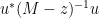

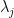
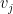

One can think of 



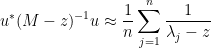
and thus

(that is to say, the diagonal entries of 
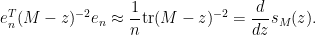
Inserting this into (5) and discarding terms of size 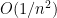

This can be viewed as a difference equation for the Stieltjes transform of top left minors of 

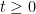

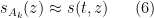
where 

with initial data 
Example 1 If
of the identity, then
. One checks that
is a steady state solution to (7), which is unsurprising given that all minors of
times the identity.
Example 2 If
, then by the semi-circular law (see previous notes) one has
(using an appropriate branch of the square root). One can then verify the self-similar solution
to (7), which is consistent with the fact that a top
when
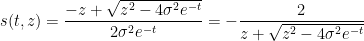
One can justify the approximation (6) given a sufficiently good well-posedness theory for the equation (7). We will not do so here, but will note that (as with the classical inviscid Burgers equation) the equation can be solved exactly (formally, at least) by the method of characteristics. For any initial position 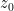

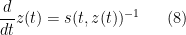
with initial data 

and thus 

and thus (7) may be solved implicitly via the equation
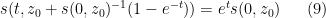
for all
Remark 3 In practice, the equation (9) may stop working when
crosses the real axis, as (7) does not necessarily hold in this region. It is a cute exercise (ultimately coming from the Cauchy-Schwarz inequality) to show that this crossing always happens, for instance if
necessarily has negative or zero imaginary part.
Example 4 Suppose we have
as in Example 1. Then (9) becomes
for any
, which after making the change of variables
becomes
as in Example 1.
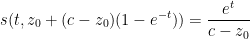
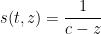
Example 5 Suppose we have
as in Example 2. Then (9) becomes
If we write
one can calculate that
and hence
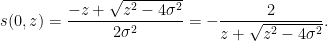
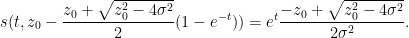

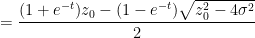
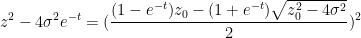
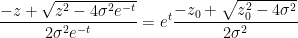

One can recover the spectral measure 

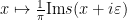


In this informal notation, we have for instance that

which can be interpreted as the fact that the Cauchy distributions 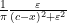
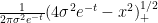
If we let 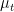


![{(0,1]}](https://s0.wp.com/latex.php?latex=%7B%280%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

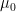
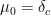



thus at height 
![{[-2\sigma \sqrt{\alpha}, 2\sigma \sqrt{\alpha}]}](https://s0.wp.com/latex.php?latex=%7B%5B-2%5Csigma+%5Csqrt%7B%5Calpha%7D%2C+2%5Csigma+%5Csqrt%7B%5Calpha%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
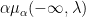


An interesting example of such a limiting Gelfand-Tsetlin pattern occurs when 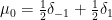
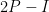


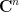
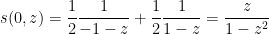
and so (9) in this case becomes
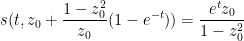
A tedious calculation then gives the solution
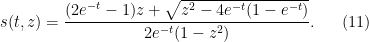
For 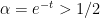

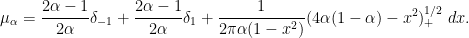
This reflects the interlacing property, which forces 
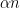



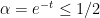
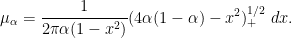
For 

There is presumably a direct geometric explanation of this fact (basically describing the singular values of the product of two random orthogonal projections to half-dimensional subspaces of
The evolution of 



for all 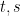
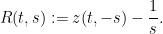
The equation (9) may be rewritten as
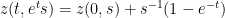
and hence


See these previous notes for a discussion of free probability topics such as the
Example 6 If
.
Example 7 If
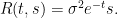
Example 8 If

This simple relationship (12) is essentially due to Nica and Speicher (thanks to Dima Shylakhtenko for this reference). It has the remarkable consequence that when 



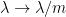
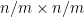

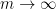

In a similar vein, if one defines the function
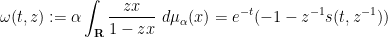
and inverts it to obtain a function 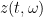
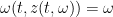
for all 
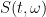
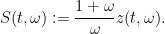
Writing

for any

and so (9) becomes
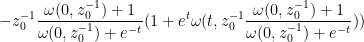

which simplifies to
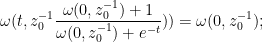
replacing 

and thus
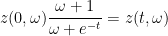
and hence
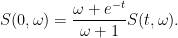
One can compute 
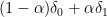



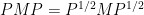
The determinant 


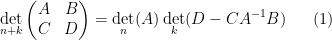
whenever 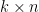
I only recently discovered that this identity in turn immediately implies what I always found to be a somewhat curious identity, namely the Dodgson condensation identity (also known as the Desnanot-Jacobi identity)


for any 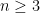





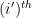

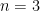


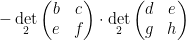
for any scalars 
The derivation is not new; it is for instance noted explicitly in this paper of Brualdi and Schneider, though I do not know if this is the earliest place in the literature where it can be found. (EDIT: Apoorva Khare has pointed out to me that the original arguments of Dodgson can be interpreted as implicitly following this derivation.) I thought it is worth presenting the short derivation here, though.
Firstly, by swapping the first and 


Now write

where 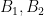
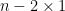

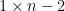


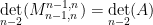
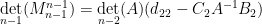


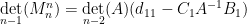
and the claim (2) then follows by a brief calculation (and the explicit form 
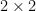
The same argument gives the more general determinant identity of Sylvester
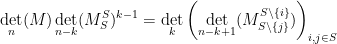
whenever 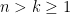

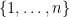

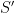

A closely related proof of (2) proceeds by elementary row and column operations. Observe that if one adds some multiple of one of the first 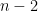
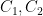

The latter approach can also prove the cute identity

for any 


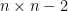
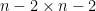

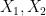
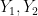






The determinant 
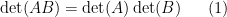
whenever 





This identity, which converts an 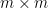
Another identity generated from (1) arises when trying to compute the determinant of a 
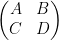
where
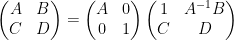

and on taking determinants using (1) we obtain the Schur determinant identity
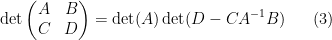
relating the determinant of a block-diagonal matrix with the determinant of the Schur complement 

It is also possible to use determinant identities to deduce other matrix identities that do not involve the determinant, by the technique of matrix differentiation (or equivalently, matrix linearisation). The key observation is that near the identity, the determinant behaves like the trace, or more precisely one has
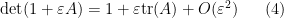
for any bounded square matrix 
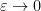

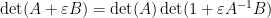
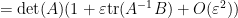
for infinitesimal 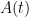
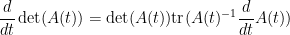
whenever
Let us see some examples of this differentiation method. If we take the Weinstein-Aronszajn identity (2) and multiply one of the rectangular matrices
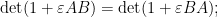
applying (4) and extracting the linear term in 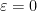
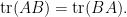
To manipulate derivatives and inverses, we begin with the Neumann series approximation
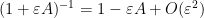
for bounded square
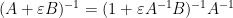
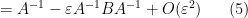
for square matrices 

whenever
We can then differentiate (or linearise) the Schur identity (3) in a number of ways. For instance, if we replace the lower block 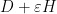


while the right-hand side becomes

extracting the linear term in
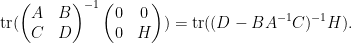
As 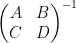
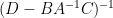

One can also compute the other components of this inverse in terms of the Schur complement 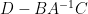
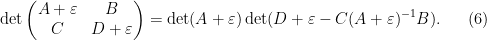
By (4), the left-hand side is
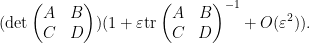
From (5), we have

and so from (4) the right-hand side of (6) is
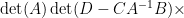
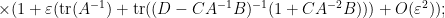
extracting the linear component in
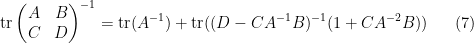
which relates the trace of the inverse of a block matrix, with the trace of the inverse of one of its blocks. This particular identity turns out to be useful in random matrix theory; I hope to elaborate on this in a later post.
As a final example of this method, we can analyse low rank perturbations 
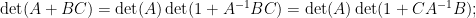
if one then perturbs 

Extracting the linear component in

assuming that
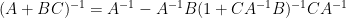
for the inverse of a low rank perturbation
Exercise 1 Use the “determinant first” approach to derive the Woodbury matrix identity (also known as the binomial inverse theorem)
where
are all invertible.

Exercise 2 Let
and differentiate this in
(assuming that all inverses exist) and thence
Rotating
then gives
which is useful for inverting a matrix
that has been split into a self-adjoint component
.


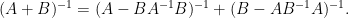
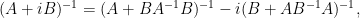

Recent Comments