
You are currently browsing the tag archive for the ‘Vitaly Bergelson’ tag.
Vitaly Bergelson, Tamar Ziegler, and I have just uploaded to the arXiv our joint paper “Multiple recurrence and convergence results associated to 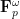
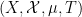

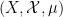
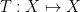
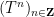
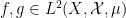

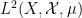

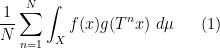
converges as 

see e.g. this previous blog post. Informally, one can interpret this limit formula as an equidistribution result: if 


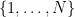



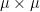
If we allow 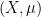
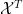
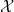
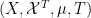
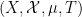



where 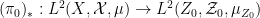
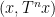



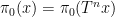
Limit formulae are known for multiple ergodic averages as well, although the statement becomes more complicated. For instance, consider the expression

for three functions 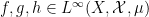
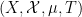

which would roughly speaking correspond to an assertion that the triplet 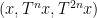


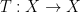


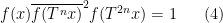
tying together 
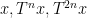

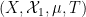
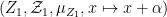
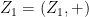
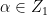
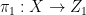
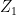
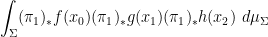
where 
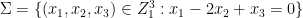
and 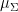

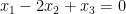
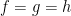
If one considers a quadruple average
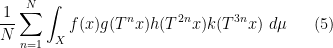
(analogous to counting length four progressions) then the situation becomes more complicated still, even in the ergodic case. In addition to the (linear) eigenfunctions that already showed up in the computation of the triple average (3), a new type of constraint also arises from quadratic eigenfunctions 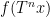
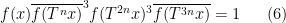
between 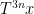
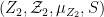
The above discussion was concerned with 
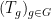
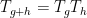

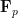
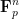
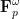
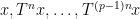
As a consequence, we can recover finite field analogues of most of the results of Bergelson-Host-Kra, though interestingly some of the counterexamples demonstrating sharpness of their results for 


for a syndetic set of 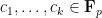





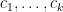
I’ve just uploaded to the arXiv my joint paper with Vitaly Bergelson, “Multiple recurrence in quasirandom groups“, which is submitted to Geom. Func. Anal.. This paper builds upon a paper of Gowers in which he introduced the concept of a quasirandom group, and established some mixing (or recurrence) properties of such groups. A 
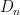
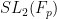


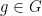

where 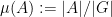




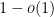

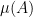
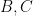

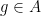
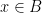
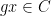



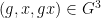

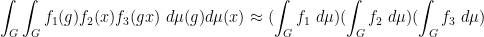
for any bounded functions 
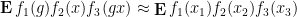
where 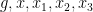
As observed in Gowers’ paper, one can iterate this observation to find “parallelopipeds” of any given dimension in dense subsets of 



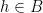
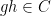
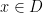
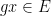
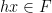
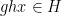

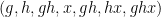

However, there are other tuples for which the above iteration argument does not seem to apply. One of the simplest tuples in this vein is the tuple 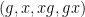

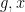
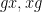


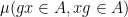

Theorem 1 Let
, we have
where
,
are drawn uniformly and independently at random from
is drawn uniformly at random from the conjugates of
for each fixed choice of
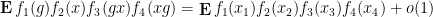
This is the probabilistic formulation of the above theorem; one can also phrase the theorem in other formulations (such as an integral formulation), and this is detailed in the paper. This theorem leads to a number of recurrence results; for instance, as a corollary of this result, we have

for almost all 
To me, the more interesting thing here is not the result itself, but how it is proven. Vitaly and I were not able to find a purely finitary way to establish this mixing theorem. Instead, we had to first use the machinery of ultraproducts (as discussed in this previous post) to convert the finitary statement about a quasirandom group to an infinitary statement about a type of infinite group which we call an ultra quasirandom group (basically, an ultraproduct of increasingly quasirandom finite groups). This is analogous to how the Furstenberg correspondence principle is used to convert a finitary combinatorial problem into an infinitary ergodic theory problem.
Ultra quasirandom groups come equipped with a finite, countably additive measure known as Loeb measure 


for “almost all” 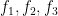
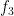
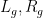

To establish this mixing theorem, we use the machinery of idempotent ultrafilters, which is a particularly useful tool for understanding the ergodic theory of actions of countable groups 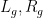
Idempotent ultrafilters are an extremely infinitary type of mathematical object (one has to use Zorn’s lemma no fewer than three times just to construct one of these objects!). So it is quite remarkable that they can be used to establish a finitary theorem such as Theorem 1, though as is often the case with such infinitary arguments, one gets absolutely no quantitative control whatsoever on the error terms 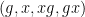
We also have some miscellaneous other results in the paper. It turns out that by using the triangle removal lemma from graph theory, one can obtain a recurrence result that asserts that whenever 



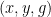
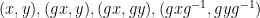
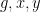
We also give some properties of a model example of an ultra quasirandom group, namely the ultraproduct 
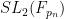

Vitaly Bergelson, Tamar Ziegler, and I have just uploaded to the arXiv our paper “An inverse theorem for the uniformity seminorms associated with the action of 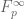
Theorem. Let
be a finite field of characteristic p. Suppose that
is a probability space with an ergodic measure-preserving action
of
. Let
be such that the Gowers-Host-Kra seminorm
(defined in a previous post) is non-zero.
- In the high-characteristic case
, there exists a phase polynomial g of degree <k (as defined in the previous post) such that
.
- In general characteristic, there exists a phase polynomial of degree <C(k) for some C(k) depending only on k such that
This theorem is closely analogous to a similar theorem of Host and Kra on ergodic actions of 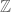
The paper is rather technical (60+ pages!) and difficult to describe in detail here, but I will try to sketch out (in very broad brush strokes) what the key steps in the proof of part 2 of the theorem are. (Part 1 is similar but requires a more delicate analysis at various stages, keeping more careful track of the degrees of various polynomials.)
Let 



- (Global definition)
for some coefficients
.
- (Local definition)
.
From single variable calculus we know that if P is a polynomial in the global sense, then it is a polynomial in the local sense; conversely, if P is a polynomial in the local sense, then from the Taylor series expansion
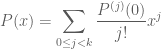
we see that P is a polynomial in the global sense. We make the trivial remark that we have no difficulty dividing by 

The above equivalence carries over to higher dimensions:
- (Global definition)
is a polynomial of degree
for some coefficients
.
- (Local definition)
for all
.
Again, it is not difficult to use several variable calculus to show that these two definitions of a polynomial are equivalent.
The purpose of this (somewhat technical) post here is to record some basic analogues of the above facts in finite characteristic, in which the underlying domain of the polynomial P is F or 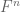

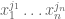
(The results here are derived from forthcoming work with Vitaly Bergelson and Tamar Ziegler.)

Recent Comments