
In the winter quarter (starting January 5) I will be teaching a graduate topics course entitled “An introduction to analytic prime number theory“. As the name suggests, this is a course covering many of the analytic number theory techniques used to study the distribution of the prime numbers 
The type of results about primes that one aspires to prove here is well captured by Landau’s classical list of problems:
- Even Goldbach conjecture: every even number
greater than two is expressible as the sum of two primes.
- Twin prime conjecture: there are infinitely many pairs
which are simultaneously prime.
- Legendre’s conjecture: for every natural number
and
.
- There are infinitely many primes of the form
.
All four of Landau’s problems remain open, but we have convincing heuristic evidence that they are all true, and in each of the four cases we have some highly non-trivial partial results, some of which will be covered in this course. We also now have some understanding of the barriers we are facing to fully resolving each of these problems, such as the parity problem; this will also be discussed in the course.
One of the main reasons that the prime numbers 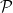


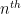

It may be in the future that some usable structure to the primes (or related objects) will eventually be located (this is for instance one of the motivations in developing a rigorous theory of the “field with one element“, although this theory is far from being fully realised at present). For now, though, analytic and combinatorial methods have proven to be the most effective way forward, as they can often be used even in the near-complete absence of structure.
In this course, we will not discuss combinatorial approaches (such as the deployment of tools from additive combinatorics) in depth, but instead focus on the analytic methods. The basic principles of this approach can be summarised as follows:
- Rather than try to isolate individual primes
in
of twin primes up to some threshold
. Similarly, one can focus on counts such as
,
, or
, which are the natural counts associated to the other three Landau problems. In all four of Landau’s problems, the basic task is now to obtain a non-trivial lower bounds on these counts.
- If one wishes to proceed analytically rather than combinatorially, one should convert all these counts into sums, using the fundamental identity
(or variants thereof) for the cardinality
of subsets
of the natural numbers
, where
is the indicator function of
or
- Once one expresses number-theoretic problems in this fashion, we are naturally led to the more general question of how to accurately estimate (or, less ambitiously, to lower bound or upper bound) sums such as
or more generally bilinear or multilinear sums such as
or
for various functions
of arithmetic interest. (Importantly, one should also generalise to include integrals as well as sums, particularly contour integrals or integrals over the unit circle or real line, but we postpone discussion of these generalisations to later in the course.) Indeed, a huge portion of modern analytic number theory is devoted to precisely this sort of question. In many cases, we can predict an expected main term for such sums, and then the task is to control the error term between the true sum and its expected main term. It is often convenient to normalise the expected main term to be zero or negligible (e.g. by subtracting a suitable constant from
exhibiting an unexpectedly large correlation with each other.
- It is often difficult to discern cancellation (or to prevent conspiracy) directly for a given sum (such as
) of interest. However, analytic number theory has developed a large number of techniques to relate one sum to another, and then the strategy is to keep transforming the sum into more and more analytically tractable expressions, until one arrives at a sum for which cancellation can be directly exhibited. (Note though that there is often a short-term tradeoff between analytic tractability and algebraic simplicity; in a typical analytic number theory argument, the sums will get expanded and decomposed into many quite messy-looking sub-sums, until at some point one applies some crude estimation to replace these messy sub-sums by tractable ones again.) There are many transformations available, ranging such basic tools as the triangle inequality, pointwise domination, or the Cauchy-Schwarz inequality to key identities such as multiplicative number theory identities (such as the Vaughan identity and the Heath-Brown identity), Fourier-analytic identities (e.g. Fourier inversion, Poisson summation, or more advanced trace formulae), or complex analytic identities (e.g. the residue theorem, Perron’s formula, or Jensen’s formula). The sheer range of transformations available can be intimidating at first; there is no shortage of transformations and identities in this subject, and if one applies them randomly then one will typically just transform a difficult sum into an even more difficult and intractable expression. However, one can make progress if one is guided by the strategy of isolating and enhancing a desired cancellation (or conspiracy) to the point where it can be easily established (or dispelled), or alternatively to reach the point where no deep cancellation is needed for the application at hand (or equivalently, that no deep conspiracy can disrupt the application).
- One particularly powerful technique (albeit one which, ironically, can be highly “ineffective” in a certain technical sense to be discussed later) is to use one potential conspiracy to defeat another, a technique I refer to as the “dueling conspiracies” method. This technique may be unable to prevent a single strong conspiracy, but it can sometimes be used to prevent two or more such conspiracies from occurring, which is particularly useful if conspiracies come in pairs (e.g. through complex conjugation symmetry, or a functional equation). A related (but more “effective”) strategy is to try to “disperse” a single conspiracy into several distinct conspiracies, which can then be used to defeat each other.
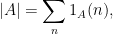





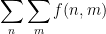

As stated before, the above strategy has not been able to establish any of the four Landau problems as stated. However, they can come close to such problems (and we now have some understanding as to why these problems remain out of reach of current methods). For instance, by using these techniques (and a lot of additional effort) one can obtain the following sample partial results in the Landau problems:
- Chen’s theorem: every sufficiently large even number
, where
is the set of almost primes.
- Zhang’s theorem: There exist infinitely many pairs
of consecutive primes with
. The proof proceeds by giving a non-negative lower bound on the quantity
for large
between
and
. (The bound
.)
- The Baker-Harman-Pintz theorem: for sufficiently large
. Proven by finding a nontrivial lower bound on
.
- The Friedlander-Iwaniec theorem: There are infinitely many primes of the form
. Proven by finding a nontrivial lower bound on
.
We will discuss (simpler versions of) several of these results in this course.
Of course, for the above general strategy to have any chance of succeeding, one must at some point use some information about the set
- (Sieve theory description) The primes
- (Multiplicative number theory description) The primes
The sieve-theoretic description and its variants lead one to a good understanding of the almost primes, which turn out to be excellent tools for controlling the primes themselves, although there are known limitations as to how much information on the primes one can extract from sieve-theoretic methods alone, which we will discuss later in this course. The multiplicative number theory methods lead one (after some complex or Fourier analysis) to the Riemann zeta function (and other L-functions, particularly the Dirichlet L-functions), with the distribution of zeroes (and poles) of these functions playing a particularly decisive role in the multiplicative methods.
Many of our strongest results in analytic prime number theory are ultimately obtained by incorporating some combination of the above two fundamental descriptions of 
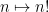
To give a simple illustration of these two basic approaches to the primes, let us first give two variants of the usual proof of Euclid’s theorem:
Theorem 1 (Euclid’s theorem) There are infinitely many primes.
Proof: (Multiplicative number theory proof) Suppose for contradiction that there were only finitely many primes 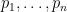
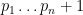
(Sieve-theoretic proof) Suppose for contradiction that there were only finitely many primes 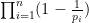

In particular, 

Remark 1 One can also phrase the proof of Euclid’s theorem in a fashion that largely avoids the use of contradiction; see this previous blog post for more discussion.
Both proofs in fact extend to give a stronger result:
Proof: (Multiplicative number theory proof) By the fundamental theorem of arithmetic, every natural number is expressible uniquely as the product 

(both sides make sense in ![{[0,+\infty]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C%2B%5Cinfty%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

and 
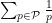
(Sieve-theoretic proof) Suppose for contradiction that the sum 



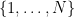


Since 
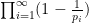

Remark 2 We have seen how easy it is to prove Euler’s theorem by analytic methods. In contrast, there does not seem to be any known proof of this theorem that proceeds by using any sort of prime-generating formula or a primality test, which is further evidence that such tools are not the most effective way to make progress on problems such as Landau’s problems. (But the weaker theorem of Euclid, Theorem 1, can sometimes be proven by such devices.)
The two proofs of Theorem 2 given above are essentially the same proof, as is hinted at by the geometric series identity

One can also see the Riemann zeta function begin to make an appearance in both proofs. Once one goes beyond Euler’s theorem, though, the sieve-theoretic and multiplicative methods begin to diverge significantly. On one hand, sieve theory can still handle to some extent sets such as twin primes, despite the lack of multiplicative structure (one simply has to sieve out two residue classes per prime, rather than one); on the other, multiplicative number theory can attain results such as the prime number theorem for which purely sieve theoretic techniques have not been able to establish. The deepest results in analytic number theory will typically require a combination of both sieve-theoretic methods and multiplicative methods in conjunction with the many transforms discussed earlier (and, in many cases, additional inputs from other fields of mathematics such as arithmetic geometry, ergodic theory, or additive combinatorics).
— 1. Topics covered —
Analytic prime number theory is a vast subject (the 615-page text of Iwaniec and Kowalski, for instance, gives a good indication as to its scope). I will therefore have to be somewhat selective in deciding what subset of this field to cover. I have chosen the following “core” topics to focus on:
- Elementary multiplicative number theory.
- Heuristic random models for the primes.
- The basic theory of the Riemann zeta function and Dirichlet L-functions, and their relationship with the primes.
- Zero-free regions for the zeta function and the Dirichet L-function, including Siegel’s theorem.
- The prime number theorem, the Siegel-Walfisz theorem, and the Bombieri-Vinogradov theorem.
- Sieve theory, small and large gaps between the primes, and the parity problem.
- Exponential sum estimates over the integers, and the Vinogradov-Korobov zero-free region.
- Zero density estimates, Hohiesel’s theorem, and Linnik’s theorem.
- Exponential sum estimates over finite fields, and improved distribution estimates for the primes.
- (If time permits) Exponential sum estimates over the primes, the circle method, and Vinogradov’s three-primes theorem.
In order to cover all this material, I will focus on more qualitative results, as opposed to the strongest quantitative results, in particular I will not attempt to optimise many of the numerical constants and exponents appearing in various estimates. This also allows me to downplay the role of some key components of the field which are not essential for establishing the core results of this course at such a qualitative level:
- I will minimise the use of algebraic number theory tools (such as the class number formula).
- I will avoid deploying the functional equation (or related identities, such as Poisson summation) if they are unnecessary at a qualitative level (though I will note when the functional equation can be used to improve the quantitative results). As it turns out, all of the core results mentioned above can in fact be derived without ever invoking the functional equation, although one usually gets poorer numerical exponents as a consequence.
- Somewhat related to this, I will reduce the reliance on complex analytic methods as compared to more traditional presentations of the material, relying in some places instead on Fourier-analytic substitutes, or on results about harmonic functions. (But I will not go as far as deploying the primarily real-variable “pretentious” approach to analytic number theory currently in development by Granville and Soundararajan, although my approach here does align in spirit with that approach.)
- The discussion on sieve methods will be somewhat abridged, focusing primarily on the Selberg sieve, which is a good general-purpose sieve for qualitative applications at least.
- I will almost certainly avoid any discussion of automorphic forms methods.
- Similarly, I will not cover methods that rely on additive combinatorics or ergodic theory.
Of course, many of these additional topics are well covered in existing textbooks, such as the above-mentioned text of Iwaniec and Kowalski (or, for the finer points of sieve theory, the text of Friedlander and Iwaniec). Other good texts that can be used for supplementary reading are Davenport’s “Multiplicative number theory” and Montgomery-Vaughan’s “Multiplicative number theory I.”. As for prerequisites: some exposure to complex analysis, Fourier analysis, and real analysis will be particularly helpful, although we will review some of this material as needed (particularly with regard to complex analysis and the theory of harmonic functions). Experience with other quantitative areas of mathematics in which lower bounds, upper bounds, and other forms of estimation are emphasised (e.g. asymptotic combinatorics or theoretical computer science) will also be useful. Knowledge of algebraic number theory or arithmetic geometry will add a valuable additional perspective to the course, but will not be necessary to follow most of the material.
— 2. Notation —
In this course, all sums will be understood to be over the natural numbers unless otherwise specified, with the exception of sums over the variable 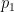
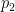
We will use asymptotic notation in two contexts, one in which there is no asymptotic parameter present, and one in which there is an asymptotic parameter (such as 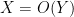
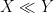
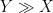
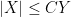

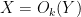
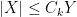

In some cases it will instead be convenient to work in an asymptotic setting, in which there is an explicitly designated asymptotic parameter (such as 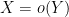


Remark 3 In later posts we will make a distinction between implied constants
We use 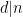

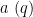


We use 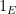


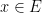




We use 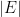

29 comments
Comments feed for this article
13 November, 2014 at 8:09 pm
Kumar Ashok
Thank you for giving me opportunity for the most precious comment!
Since 1901 in second week September every year all Mathematicians feel embarrassed and slapped not to nominated for Nobel Prize.Why?Not the story of love floated for A.Nobel.But for the reason ” Mathematician do not do the mathematics that suit mankind but do that suit to them. Most of them do not recognize good work for others, so it would be difficult to select the best” Today many problems are remain even after some people have solved them , but after due to not to co-operate nature of most of mathematicians and rubbish policies of Journals most of the problems are unsolved even after getting solved.These mathematician are printing rubbish subject material a burden to coming generation without any application to mankind. Mathematician need to think many times if they are working foe mankind or for self.Differentiation between then is difficult as they all are identical so they themselves recognize work among them.
You all have accepted 100+ page solution of FermateTheorem (real sol is 7-8 page),Goldbach problem is solved (sol- 10-12 page),Twin prime Problem is slved (sol 10+ page),Riemann problem is solved (sol 8-10 page).aaaaa……nnnn…..ddddd many more.
BUT NO NEUTRAL JOURNAL IS FOUND THIS IS MOST TEDIOUS AND DIFFICULT PROBLEM TO BE SOLVED.
First mathematicians have to solve this problem other will get solved immediately.
Thanks to every one who read and act to this problem
Kumar Ashok
16 November, 2014 at 2:30 pm
Chandan Sinha
Your comment was quite insightful sir and it really states the problems with mathematicians to considerable extent but you should also take into account the applicability of advancement. Though the role of today’s mathematical development for the welfare of humanity is not apparent but it does affect in inconspicuous ways for the betterment. Also we should see that the researches have been done since almost the beginning of civilization and it has come too far. Let’s say- Integration- it is part of mathematics and would be considered as invented by mathematician itself ( Newton or Leibnitz whomever you consider) but its finds its application as a tool in almost every area which enhances the living standard. Though it was the contributing subject but so does everything else for which Nobel prize is given. The combination of all these brings the applicable result- hope you get my point! Anyway it is said that Mathematics is the queen of science and it too would have a role in running the whole empire :)
13 November, 2014 at 9:01 pm
Bo Jacoby
“Remark 2 We have seen how easy it is to prove Euler’s theorem” read “Remark 2 We have seen how easy it is to prove Euclid’s theorem”
[Actually, my intent here is indeed to highlight the ease of proof of Euler’s theorem if one uses analytic techniques. -T.]
13 November, 2014 at 11:11 pm
mathtuition88
Reblogged this on Singapore Maths Tuition and commented:
Bookmark Terence Tao’s site if you are interested in his notes on Analytic number theory! He will be placing lecture notes online on his blog.
This is a one-in-a-lifetime chance to learn Analytic Number Theory from a Master — Fields’ Medallist Terrence Tao.
14 November, 2014 at 6:59 am
arch1@gmail.com
The referenced “Landau’s Problems” Wikipedia article reports only partial progress on Goldbach’s weak (3-primes) conjecture, while the “Goldbach’s weak conjecture” article reports a 2013 solution. Perhaps one of you who knows the real story can fix.
PS. At least the 1st article spells “D. H. J. Polymath” correctly:-)
14 November, 2014 at 9:35 am
arch1
1) Holy moly. *Thanks* for these lecture notes.
2) “…using some combination…into the general strategy…”: using -> incorporating
[Corrected, thanks – T.]
14 November, 2014 at 9:36 am
vznvzn
:star: :star: :star: once again big congratulations on your $3M breakthru prize and appearing on colbert! so your blog overflows with dense impersonal math, but it would be very interesting to hear your opinion of the awards, am sure many would like/ appreciate it, a personal reaction to the ceremony, etc. eg did you get to flirt with cameron diaz or kate beckinsdale at all lol :p … as a model consider Gowers coverage of the IMU2014 meeting in korea in his blog. alas, thinking you are not gonna go for it, so as a vastly inferior substitute for your readers, see eg more coverage/ commentary etc at this link, star studded, cash overflowing 2015 breakthru awards
14 November, 2014 at 2:54 pm
Anonymous
Are there any references for the real-variable approach taken by Granville and Soundararajan?
[There is a book in preparation, until then one has to go to the original articles, such as http://arxiv.org/abs/math/0503113 – T.]
14 November, 2014 at 4:40 pm
arch1
Naive Q: Is it really the case that the proof of Chen’s theorem proceeds by lower-bounding the very same sum that one seeks to lower-bound when attacking the Goldbach conjecture itself? Or in the description of Chen’s theorem, should one of the indicator functions in the sum indicate almost-primality rather than primality?
[Corrected, thanks – T.]
15 November, 2014 at 12:47 pm
arch1
Terry, the ref you cite (and the Mathworld article *it* cites) say that P2 is the set of “2-almost-primes” (exactly 2 prime factors, counting multiplicity). Should the P2 subscript instead be P union P2?
[Corrected, thanks – T.]
14 November, 2014 at 10:31 pm
Avi Levy
There’s an extra ‘(‘ in the last sentence of the second paragraph up from Theorem 1: “with the distribution of zeroes (and poles of these functions playing a particularly decisive role in the multiplicative methods.”
[Corrected, thanks – T.]
14 November, 2014 at 11:56 pm
zr9558
Reblogged this on ZHANG RONG.
15 November, 2014 at 8:13 am
MrCactu5 (@MonsieurCactus)
I am still busy reading your other Math 254A
16 November, 2014 at 9:14 am
Frank Lesley
Perri:
This looks like a rare opportunity- an on-line course on this topic, given by a real master. IComing to a computer near you in January.
David
16 November, 2014 at 1:28 pm
Anonymous
This seems like a fantastic course, I wish I could take it. Best of luck!
16 November, 2014 at 2:32 pm
Chandan Sinha
Will you be posting the video lectures also on any site?
16 November, 2014 at 2:34 pm
Chandan Sinha
Reblogged this on Divine_Lifez and commented:
Mathematics!!!
24 November, 2014 at 7:50 pm
Mike Ross
I sort of followed the interesting article concerning Landau’s Problems. The one most obvious thing that was not said about them is they are all related to perfect squares. The third and fourth – Legendre’s conjecture and Are there infinitely many primes p such that p-1 is a perfect square? – are overtly so. The second is the Twin Prime, and the connection here is that the product of p and p+2 is (X^2)-1. (That leaves Goldbach’s conjecture, where the connection requires looking at the products of the partitions in relation to perfect squares.) That the twin primes are always the factors of (x^2)-1, actually x-1 and x+1, shows a very precise geometric relationship with square numbers that I think is easy to overlook. Reversing the logic and considering composites first and their prime factors second can bring unexpected clarity to these four problems.
25 November, 2014 at 8:58 am
Eytan Paldi
This shows that the twin prime conjecture is equivalent to the conjecture that there are infinitely many semiprimes of the form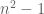 .
.
2 December, 2014 at 9:33 am
Mike Ross
An interesting property of even perfect squares minus 1 is the triviality of their smallest prime factor unless they are twin-prime composites. This makes it extremely fast to factor them and easy to determine the instances of twin primes (simply by elimination). The rule is that the smallest prime factor of a non-twin-prime X^2-1 composite cannot be greater than the square root of its square root – and usually much smaller. If such a factor is not found, the composite must be the product of twin primes. Thus the largest of these non-twin-prime factors less than 1 million is 991 for 999836006723.
28 November, 2014 at 6:44 pm
Enrique Treviño
I enjoyed reading this entry. Looking forward to following along the rest of these lecture notes.
I found two typos:
1) “One of course create…” is missing “can”.
2) “A has positive density and is thus contains….” has an extra “is”.
[Corrected, thanks – T.]
7 December, 2014 at 10:08 pm
tomcircle
Reblogged this on Math Online Tom Circle and commented:
This is excellent lecture notes. Thanks Prof. Terence Tao. 谢谢!
3 January, 2015 at 7:30 pm
Anonymous
What do you mean here? “There does not seem to be any known proof of this theorem that proceeds by using any sort of prime-generating formula or a primality test.” I think the first proof is from around 1300 or 1400. Which makes me think we are not communicating well.
7 January, 2015 at 9:14 am
Anonymous
In the Sieve-theoretic proof of Theorem 2, should the sentence instead read “As in the previous proof, each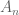 has density
has density  ” as opposed to
” as opposed to  ?
?
[Corrected, thanks – T.]
20 March, 2017 at 7:10 pm
Anonymous
How can I print this? Is there any book form?
27 December, 2018 at 1:15 pm
Chebyshev’s Almost Prime Number Theorem – Write down what you’ve learned
[…] https://terrytao.wordpress.com/2014/11/13/254a-announcement-analytic-prime-number-theory/ […]
4 September, 2019 at 1:46 pm
254A announcement: Analytic prime number theory | What's new
[…] 27) I will be teaching a graduate course on analytic prime number theory. This will be similar to a graduate course I taught in 2015, and in particular will reuse several of the lecture notes from that course, though it will also […]
10 February, 2020 at 4:45 pm
plm
Dear Terence Tao, I hope you plan to publish your notes on analytic prime number theory. I feel these are some of your deepest expository contributions. You already had notes which did not arrive to book form. Was it because you felt unsatisfied? Because the material was fluctuating too much then? Do you feel now the time is riper?
Thank you,
Paul
10 February, 2020 at 4:47 pm
plm
I meant to write this comment in your 2019 course annoucement.