
You are currently browsing the category archive for the ‘245B – Real analysis’ category.
Suppose one has a bounded sequence 
Of course, we have the usual notion of limit 




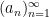
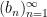


and similarly for any scalar 
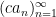

It is also an algebra homomorphism: 

We also have shift invariance: if 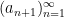

and more generally in fact for any injection 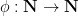
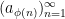

The classical limit of a sequence is unchanged if one modifies any finite number of elements of the sequence. Finally, we have boundedness: for any classically convergent sequence

One can in fact show without much difficulty that these laws uniquely determine the classical limit functional on convergent sequences.
One would like to extend the classical limit notion to more general bounded sequences; however, when doing so one must give up one or more of the desirable limit laws that were listed above. Consider for instance the sequence 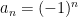

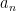



Nevertheless there are a number of useful generalisations and variants of the classical limit concept for non-convergent sequences that obey a significant portion of the above limit laws. For instance, we have the limit superior
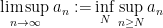
and limit inferior

which are well-defined real numbers for any bounded sequence
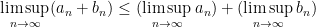
for the limit superior, and the superadditivity property

for the limit inferior. The homogeneity property (2) is only obeyed by the limits superior and inferior for non-negative

The limit superior and limit inferior are examples of limit points of the sequence, which can for instance be defined as points that are limits of at least one subsequence of the original sequence. Indeed, the limit superior is always the largest limit point of the sequence, and the limit inferior is always the smallest limit point. However, limit points can be highly non-unique (indeed they are unique if and only if the sequence is classically convergent), and so it is difficult to sensibly interpret most of the usual limit laws in this setting, with the exception of the homogeneity property (2) and the boundedness property (6) that are easy to state for limit points.
Another notion of limit are the Césaro limits
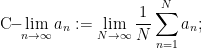
if this limit exists, we say that the sequence is Césaro convergent. If the sequence 

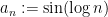
Using the Hahn-Banach theorem, one can extend the classical limit functional to generalised limit functionals 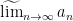
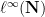


![{[\liminf_{n \rightarrow \infty} a_n, \limsup_{n \rightarrow \infty} a_n]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Climinf_%7Bn+%5Crightarrow+%5Cinfty%7D+a_n%2C+%5Climsup_%7Bn+%5Crightarrow+%5Cinfty%7D+a_n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


![{[-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Because of the reliance on the Hahn-Banach theorem, the existence of generalised limits requires the axiom of choice (or some weakened version thereof); there are models of set theory without the axiom of choice in which no generalised limits exist. For instance, consider a Solovay model in which all subsets of the real numbers are measurable. If one lets 
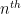
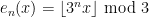



Generalised limits can obey the shift-invariance property (4) or the algebra homomorphism property (3), but as the above analysis of the sequence 
Generalised limits that obey the algebra homomorphism property (3) are known as ultrafilter limits. If one is given a generalised limit functional 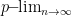



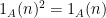



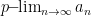

We have previously noted that generalised limits of a sequence can converge to any point between the limit inferior and limit superior. The same is not true if one restricts to Banach limits or ultrafilter limits. For instance, by the arguments already given, the only possible Banach limit for the sequence
There is no generalisation of the classical limit functional to any space that includes non-classically convergent sequences that obeys the subsequence property (5), since any non-classically-convergent sequence will have one subsequence that converges to the limit superior, and another subsequence that converges to the limit inferior, and one of these will have to violate (5) since the limit superior and limit inferior are distinct. So the above limit notions come close to the best generalisations of limit that one can use in practice.
(Added after comments) If 


We summarise (some of) the above discussion in the following table:
| Limit | Always defined | Linear | Shift-invariant | Homomorphism | Constructive |
| Classical | No | Yes | Yes | Yes | Yes |
| Superior | Yes | No | Yes | No | Yes |
| Inferior | Yes | No | Yes | No | Yes |
| Césaro | No | Yes | Yes | No | Yes |
| Generalised | Yes | Yes | Depends | Depends | No |
| Banach | Yes | Yes | Yes | No | No |
| Ultrafilter | Yes | Yes | No | Yes | No |
In functional analysis, it is common to endow various (infinite-dimensional) vector spaces with a variety of topologies. For instance, a normed vector space can be given the strong topology as well as the weak topology; if the vector space has a predual, it also has a weak-* topology. Similarly, spaces of operators have a number of useful topologies on them, including the operator norm topology, strong operator topology, and the weak operator topology. For function spaces, one can use topologies associated to various modes of convergence, such as uniform convergence, pointwise convergence, locally uniform convergence, or convergence in the sense of distributions. (A small minority of such modes are not topologisable, though, the most common of which is pointwise almost everywhere convergence; see Exercise 8 of this previous post).
Some of these topologies are much stronger than others (in that they contain many more open sets, or equivalently that they have many fewer convergent sequences and nets). However, even the weakest topologies used in analysis (e.g. convergence in distributions) tend to be Hausdorff, since this at least ensures the uniqueness of limits of sequences and nets, which is a fundamentally useful feature for analysis. On the other hand, some Hausdorff topologies used are “better” than others in that many more analysis tools are available for those topologies. In particular, topologies that come from Banach space norms are particularly valued, as such topologies (and their attendant norm and metric structures) grant access to many convenient additional results such as the Baire category theorem, the uniform boundedness principle, the open mapping theorem, and the closed graph theorem.
Of course, most topologies placed on a vector space will not come from Banach space norms. For instance, if one takes the space 
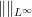
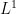
I recently realised (while teaching a graduate class in real analysis) that the closed graph theorem provides a quick explanation for why Banach space topologies are so rare:
Proposition 1 Let
be a Hausdorff topological vector space. Then, up to equivalence of norms, there is at most one norm
one can place on
so that
is a Banach space whose topology is at least as strong as
. In particular, there is at most one topology stronger than
Proof: Suppose one had two norms 


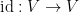
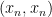
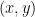
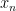

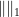

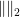


By using various generalisations of the closed graph theorem, one can generalise the above proposition to Fréchet spaces, or even to F-spaces. The proposition can fail if one drops the requirement that the norms be stronger than a specified Hausdorff topology; indeed, if
One can interpret Proposition 1 as follows: once one equips a vector space with some “weak” (but still Hausdorff) topology, there is a canonical choice of “strong” topology one can place on that space that is stronger than the “weak” topology but arises from a Banach space structure (or at least a Fréchet or F-space structure), provided that at least one such structure exists. In the case of function spaces, one can usually use the topology of convergence in distribution as the “weak” Hausdorff topology for this purpose, since this topology is weaker than almost all of the other topologies used in analysis. This helps justify the common practice of describing a Banach or Fréchet function space just by giving the set of functions that belong to that space (e.g. 

Of course, there are still some topological vector spaces which have no “strong topology” arising from a Banach space at all. Consider for instance the space 

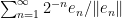

One way to study a general class of mathematical objects is to embed them into a more structured class of mathematical objects; for instance, one could study manifolds by embedding them into Euclidean spaces. In these (optional) notes we study two (related) embedding theorems for topological spaces:
- The Stone-Čech compactification, which embeds locally compact Hausdorff spaces into compact Hausdorff spaces in a “universal” fashion; and
- The Urysohn metrization theorem, that shows that every second-countable normal Hausdorff space is metrizable.
The 245B final can be found here. I am not posting solutions, but readers (both students and non-students) are welcome to discuss the final questions in the comments below.
The continuation to this course, 245C, will begin on Monday, March 29. The topics for this course are still somewhat fluid – but I tentatively plan to cover the following topics, roughly in order:
spaces and interpolation; fractional integration
- The Fourier transform on
(a very quick review; this is of course covered more fully in 247A)
- Schwartz functions, and the theory of distributions
- Hausdorff measure
- The spectral theorem (introduction only; the topic is covered in depth in 255A)
I am open to further suggestions for topics that would build upon the 245AB material, which would be of interest to students, and which would not overlap too substantially with other graduate courses offered at UCLA.
A key theme in real analysis is that of studying general functions 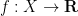

In order to approximate rough functions by more continuous ones, one of course needs tools that can generate continuous functions with some specified behaviour. The two basic tools for this are Urysohn’s lemma, which approximates indicator functions by continuous functions, and the Tietze extension theorem, which extends continuous functions on a subdomain to continuous functions on a larger domain. An important consequence of these theorems is the Riesz representation theorem for linear functionals on the space of compactly supported continuous functions, which describes such functionals in terms of Radon measures.
Sometimes, approximation by continuous functions is not enough; one must approximate continuous functions in turn by an even smoother class of functions. A useful tool in this regard is the Stone-Weierstrass theorem, that generalises the classical Weierstrass approximation theorem to more general algebras of functions.
As an application of this theory (and of many of the results accumulated in previous lecture notes), we will present (in an optional section) the commutative Gelfand-Neimark theorem classifying all commutative unital 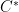
Today I’d like to discuss (in the Tricks Wiki format) a fundamental trick in “soft” analysis, sometimes known as the “limiting argument” or “epsilon regularisation argument”.
Title: Give yourself an epsilon of room.
Quick description: You want to prove some statement 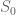
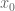



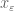

One can of course play a similar game when proving a statement 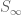
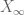

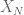

General discussion: Here are some typical examples of a target statement 
|
|
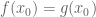 |
 |
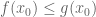 |
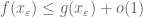 |
 |
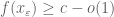 for some for some  independent of independent of |
 is finite is finite |
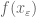 is bounded uniformly in is bounded uniformly in |
 for all for all 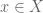 (i.e. maximises f) (i.e. maximises f) |
 for all (i.e. nearly maximises f) for all (i.e. nearly maximises f) |
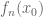 converges as converges as 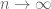 |
 fluctuates by at most o(1) for sufficiently large n fluctuates by at most o(1) for sufficiently large n |
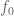 is a measurable function is a measurable function |
 is a measurable function converging pointwise to is a measurable function converging pointwise to |
| is a continuous function |
is an equicontinuous family of functions converging pointwise to OR is continuous and converges (locally) uniformly to |
The event 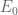 holds almost surely holds almost surely |
The event  holds with probability 1-o(1) holds with probability 1-o(1) |
The statement  holds for almost every x holds for almost every x |
The statement  holds for x outside of a set of measure o(1) holds for x outside of a set of measure o(1) |
Of course, to justify the convergence of 
It is also necessary in many cases that the control 
By giving oneself an epsilon of room, one can evade a lot of familiar issues in soft analysis. For instance, by replacing “rough”, “infinite-complexity”, “continuous”, “global”, or otherwise “infinitary” objects 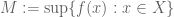
To summarise: one can view the epsilon regularisation argument as a “loan” in which one borrows an epsilon here and there in order to be able to ignore soft analysis difficulties, and can temporarily be able to utilise estimates which are non-uniform in epsilon, but at the end of the day one needs to “pay back” the loan by establishing a final “hard analysis” estimate which is uniform in epsilon (or whose error terms decay to zero as epsilon goes to zero).
A variant: It may seem that the epsilon regularisation trick is useless if one is already in “hard analysis” situations when all objects are already “finitary”, and all formal computations easily justified. However, there is an important variant of this trick which applies in this case: namely, instead of sending the epsilon parameter to zero, choose epsilon to be a sufficiently small (but not infinitesimally small) quantity, depending on other parameters in the problem, so that one can eventually neglect various error terms and to obtain a useful bound at the end of the day. (For instance, any result proven using the Szemerédi regularity lemma is likely to be of this type.) Since one is not sending epsilon to zero, not every term in the final bound needs to be uniform in epsilon, though for quantitative applications one still would like the dependencies on such parameters to be as favourable as possible.
Prerequisites: Graduate real analysis. (Actually, this isn’t so much a prerequisite as it is a corequisite: the limiting argument plays a central role in many fundamental results in real analysis.) Some examples also require some exposure to PDE.
A normed vector space 

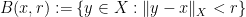
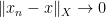

However, in some cases it is useful to work in topologies on vector spaces that are weaker than a norm topology. One reason for this is that many important modes of convergence, such as pointwise convergence, convergence in measure, smooth convergence, or convergence on compact subsets, are not captured by a norm topology, and so it is useful to have a more general theory of topological vector spaces that contains these modes. Another reason (of particular importance in PDE) is that the norm topology on infinite-dimensional spaces is so strong that very few sets are compact or pre-compact in these topologies, making it difficult to apply compactness methods in these topologies. Instead, one often first works in a weaker topology, in which compactness is easier to establish, and then somehow upgrades any weakly convergent sequences obtained via compactness to stronger modes of convergence (or alternatively, one abandons strong convergence and exploits the weak convergence directly). Two basic weak topologies for this purpose are the weak topology on a normed vector space 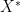
The strong and weak topologies on normed vector spaces also have analogues for the space 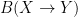

One of the most useful concepts for analysis that arise from topology and metric spaces is the concept of compactness; recall that a space
Exercise 1 (Basic properties of compact sets)
- Show that any finite set is compact.
- Show that any finite union of compact subsets of a topological space is still compact.
- Show that any image of a compact space under a continuous map is still compact.
Show that these three statements continue to hold if “compact” is replaced by “sequentially compact”.
The notion of what it means for a subset E of a space X to be “small” varies from context to context. For instance, in measure theory, when 
Lemma 1. (Pigeonhole principle for measure spaces) Let
be an at most countable sequence of measurable subsets of a measure space X. If
has positive measure, then at least one of the
has positive measure.
Now suppose that X was a Euclidean space 
Proposition 1. Let
be a measurable subset of
- E has positive measure.
- For any
.
Thus one can think of a null set as a set which is “nowhere dense” in some measure-theoretic sense.
It turns out that there are analogues of these results when the measure space 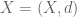

Theorem 1. (Baire category theorem). Let
Exercise 1. Show that the Baire category theorem is equivalent to the claim that in a complete metric space, the countable intersection of open dense sets remain dense.

Exercise 2. Using the Baire category theorem, show that any non-empty complete metric space without isolated points is uncountable. (In particular, this shows that Baire category theorem can fail for incomplete metric spaces such as the rationals 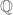
To quickly illustrate an application of the Baire category theorem, observe that it implies that one cannot cover a finite-dimensional real or complex vector space 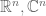
- The uniform boundedness principle, that equates the qualitative boundedness (or convergence) of a family of continuous operators with their quantitative boundedness.
- The open mapping theorem, that equates the qualitative solvability of a linear problem Lu = f with the quantitative solvability.
- The closed graph theorem, that equates the qualitative regularity of a (weakly continuous) operator T with the quantitative regularity of that operator.
Strictly speaking, these theorems are not used much directly in practice, because one usually works in the reverse direction (i.e. first proving quantitative bounds, and then deriving qualitative corollaries); but the above three theorems help explain why we usually approach qualitative problems in functional analysis via their quantitative counterparts.
To progress further in our study of function spaces, we will need to develop the standard theory of metric spaces, and of the closely related theory of topological spaces (i.e. point-set topology). I will be assuming that students in my class will already have encountered these concepts in an undergraduate topology or real analysis course, but for sake of completeness I will briefly review the basics of both spaces here.

Recent Comments