
You are currently browsing the tag archive for the ‘Cramer’s random model’ tag.
William Banks, Kevin Ford, and I have just uploaded to the arXiv our paper “Large prime gaps and probabilistic models“. In this paper we introduce a random model to help understand the connection between two well known conjectures regarding the primes 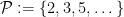
Conjecture 1 (Cramér conjecture) If
is a large number, then the largest prime gap
in
is of size
. (Granville refines this conjecture to
, where
. Here we use the asymptotic notation
for
,
for
,
for
, and
for
.)
Conjecture 2 (Hardy-Littlewood conjecture) If
are fixed distinct integers, then the number of numbers
with
all prime is
as
, where the singular series
is defined by the formula

(One can view these conjectures as modern versions of two of the classical Landau problems, namely Legendre’s conjecture and the twin prime conjecture respectively.)
A well known connection between the Hardy-Littlewood conjecture and prime gaps was made by Gallagher. Among other things, Gallagher showed that if the Hardy-Littlewood conjecture was true, then the prime gaps 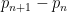
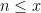
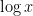
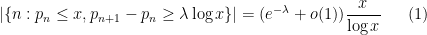
as 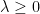
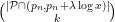
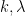

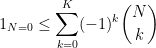
when 
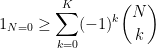
when 

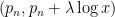
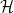

![{[0, \lambda \log x]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C+%5Clambda+%5Clog+x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Heuristically, if one extrapolates the asymptotic (1) to the regime 


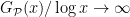


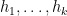
Theorem 3 (Large gaps from Hardy-Littlewood, rough statement)
- If the Hardy-Littlewood conjecture is uniformly true for
, and with shifts
, with a power savings in the error term, then
.
- If the Hardy-Littlewood conjecture is “true on average” for
and shifts
for all
, with a power savings in the error term, then
.
In particular, we can recover Cramer’s conjecture given a sufficiently powerful version of the Hardy-Littlewood conjecture “on the average”.
Our proof of this theorem proceeds more or less along the same lines as Gallagher’s calculation, but now with 

of the singular series, for a suitable cutoff 


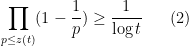
(this is well defined for 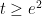
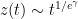
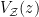

where 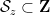
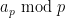
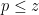
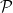
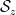
The proof of Theorem 3 ended up not using any properties of the set of primes
This line of inquiry was started by Cramér, who introduced what we now call the Cramér random model 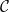
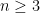
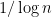
![\displaystyle | {\mathcal C} \cap [1,x] | = \int_2^x \frac{dt}{\log t} + O( x^{1/2+o(1)})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%7C+%7B%5Cmathcal+C%7D+%5Ccap+%5B1%2Cx%5D+%7C+%3D+%5Cint_2%5Ex+%5Cfrac%7Bdt%7D%7B%5Clog+t%7D+%2B+O%28+x%5E%7B1%2F2%2Bo%281%29%7D%29&bg=ffffff&fg=000000&s=0&c=20201002)
and Cramér also showed that the largest gap 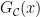


Granville proposed a refinement 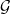
![{[x,2x]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2C2x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
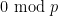

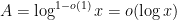

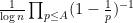
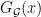

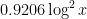
However, Granville’s model does not produce a power savings in the error term of the Hardy-Littlewood conjectures, mostly due to the need to truncate the singular series at the logarithmic cutoff 
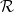
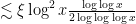


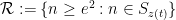
with
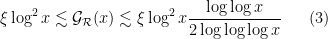
and that the Hardy-Littlewood conjectures hold with power savings for 

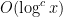
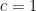
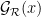
![{[0,y]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2Cy%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The probabilistic analysis of 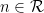
![{n \in [0,y]}](https://s0.wp.com/latex.php?latex=%7Bn+%5Cin+%5B0%2Cy%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
We now move away from the world of multiplicative prime number theory covered in Notes 1 and Notes 2, and enter the wider, and complementary, world of non-multiplicative prime number theory, in which one studies statistics related to non-multiplicative patterns, such as twins 
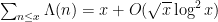
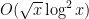
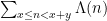
Despite this, we do have a number of extremely convincing and well supported models for the primes (and related objects) that let us predict what the answer to many prime number theory questions (both multiplicative and non-multiplicative) should be, particularly in asymptotic regimes where one can work with aggregate statistics about the primes, rather than with a small number of individual primes. These models are based on taking some statistical distribution related to the primes (e.g. the primality properties of a randomly selected
As it turns out, the models for primes that have turned out to be the most accurate in practice are random models, which involve (either explicitly or implicitly) one or more random variables. This is despite the prime numbers being obviously deterministic in nature; no coins are flipped or dice rolled to create the set of primes. The point is that while the primes have a lot of obvious multiplicative structure (for instance, the product of two primes is never another prime), they do not appear to exhibit much discernible non-multiplicative structure asymptotically, in the sense that they rarely exhibit statistical anomalies in the asymptotic limit that cannot be easily explained in terms of the multiplicative properties of the primes. As such, when considering non-multiplicative statistics of the primes, the primes appear to behave pseudorandomly, and can thus be modeled with reasonable accuracy by a random model. And even for multiplicative problems, which are in principle controlled by the zeroes of the Riemann zeta function, one can obtain good predictions by positing various pseudorandomness properties of these zeroes, so that the distribution of these zeroes can be modeled by a random model.
Of course, one cannot expect perfect accuracy when replicating a deterministic set such as the primes by a probabilistic model of that set, and each of the heuristic models we discuss below have some limitations to the range of statistics about the primes that they can expect to track with reasonable accuracy. For instance, many of the models about the primes do not fully take into account the multiplicative structure of primes, such as the connection with a zeta function with a meromorphic continuation to the entire complex plane; at the opposite extreme, we have the GUE hypothesis which appears to accurately model the zeta function, but does not capture such basic properties of the primes as the fact that the primes are all natural numbers. Nevertheless, each of the models described below, when deployed within their sphere of reasonable application, has (possibly after some fine-tuning) given predictions that are in remarkable agreement with numerical computation and with known rigorous theoretical results, as well as with other models in overlapping spheres of application; they are also broadly compatible with the general heuristic (discussed in this previous post) that in the absence of any exploitable structure, asymptotic statistics should default to the most “uniform”, “pseudorandom”, or “independent” distribution allowable.
As hinted at above, we do not have a single unified model for the prime numbers (other than the primes themselves, of course), but instead have an overlapping family of useful models that each appear to accurately describe some, but not all, aspects of the prime numbers. In this set of notes, we will discuss four such models:
- The Cramér random model and its refinements, which model the set
- The Möbius pseudorandomness principle, which predicts that the Möbius function
does not correlate with any genuinely different arithmetic sequence of reasonable “complexity”.
- The equidistribution of residues principle, which predicts that the residue classes of a large number
- The GUE hypothesis, which asserts that the zeroes of the Riemann zeta function are distributed (at microscopic and mesoscopic scales) like the zeroes of a GUE random matrix, and which generalises the pair correlation conjecture regarding pairs of such zeroes.
This is not an exhaustive list of models for the primes and related objects; for instance, there is also the model in which the major arc contribution in the Hardy-Littlewood circle method is predicted to always dominate, and with regards to various finite groups of number-theoretic importance, such as the class groups discussed in Supplement 1, there are also heuristics of Cohen-Lenstra type. Historically, the first heuristic discussion of the primes along these lines was by Sylvester, who worked informally with a model somewhat related to the equidistribution of residues principle. However, we will not discuss any of these models here.
A word of warning: the discussion of the above four models will inevitably be largely informal, and “fuzzy” in nature. While one can certainly make precise formalisations of at least some aspects of these models, one should not be inflexibly wedded to a specific such formalisation as being “the” correct way to pin down the model rigorously. (To quote the statistician George Box: “all models are wrong, but some are useful”.) Indeed, we will see some examples below the fold in which some finer structure in the prime numbers leads to a correction term being added to a “naive” implementation of one of the above models to make it more accurate, and it is perfectly conceivable that some further such fine-tuning will be applied to one or more of these models in the future. These sorts of mathematical models are in some ways closer in nature to the scientific theories used to model the physical world, than they are to the axiomatic theories one is accustomed to in rigorous mathematics, and one should approach the discussion below accordingly. In particular, and in contrast to the other notes in this course, the material here is not directly used for proving further theorems, which is why we have marked it as “optional” material. Nevertheless, the heuristics and models here are still used indirectly for such purposes, for instance by
- giving a clearer indication of what results one expects to be true, thus guiding one to fruitful conjectures;
- providing a quick way to scan for possible errors in a mathematical claim (e.g. by finding that the main term is off from what a model predicts, or an error term is too small);
- gauging the relative strength of various assertions (e.g. classifying some results as “unsurprising”, others as “potential breakthroughs” or “powerful new estimates”, others as “unexpected new phenomena”, and yet others as “way too good to be true”); or
- setting up heuristic barriers (such as the parity barrier) that one has to resolve before resolving certain key problems (e.g. the twin prime conjecture).
See also my previous essay on the distinction between “rigorous” and “post-rigorous” mathematics, or Thurston’s essay discussing, among other things, the “definition-theorem-proof” model of mathematics and its limitations.
Remark 1 The material in this set of notes presumes some prior exposure to probability theory. See for instance this previous post for a quick review of the relevant concepts.
In the third Marker lecture, I would like to discuss the recent progress, particularly by Goldston, Pintz, and Yıldırım, on finding small gaps 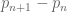

Recent Comments