
You are currently browsing the tag archive for the ‘Hausdorff-Young inequality’ tag.
As many readers may already know, my good friend and fellow mathematical blogger Tim Gowers, having wrapped up work on the Princeton Companion to Mathematics (which I believe is now in press), has begun another mathematical initiative, namely a “Tricks Wiki” to act as a repository for mathematical tricks and techniques. Tim has already started the ball rolling with several seed articles on his own blog, and asked me to also contribute some articles. (As I understand it, these articles will be migrated to the Wiki in a few months, once it is fully set up, and then they will evolve with edits and contributions by anyone who wishes to pitch in, in the spirit of Wikipedia; in particular, articles are not intended to be permanently authored or signed by any single contributor.)
So today I’d like to start by extracting some material from an old post of mine on “Amplification, arbitrage, and the tensor power trick” (as well as from some of the comments), and converting it to the Tricks Wiki format, while also taking the opportunity to add a few more examples.
Title: The tensor power trick
Quick description: If one wants to prove an inequality 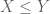
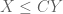
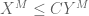
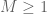
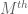
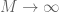
It occurred to me recently that the mathematical blog medium may be a good venue not just for expository “short stories” on mathematical concepts or results, but also for more technical discussions of individual mathematical “tricks”, which would otherwise not be significant enough to warrant a publication-length (and publication-quality) article. So I thought today that I would discuss the amplification trick in harmonic analysis and combinatorics (and in particular, in the study of estimates); this trick takes an established estimate involving an arbitrary object (such as a function f), and obtains a stronger (or amplified) estimate by transforming the object in a well-chosen manner (often involving some new parameters) into a new object, applying the estimate to that new object, and seeing what that estimate says about the original object (after optimising the parameters or taking a limit). The amplification trick works particularly well for estimates which enjoy some sort of symmetry on one side of the estimate that is not represented on the other side; indeed, it can be viewed as a way to “arbitrage” differing amounts of symmetry between the left- and right-hand sides of an estimate. It can also be used in the contrapositive, amplifying a weak counterexample to an estimate into a strong counterexample. This trick also sheds some light as to why dimensional analysis works; an estimate which is not dimensionally consistent can often be amplified into a stronger estimate which is dimensionally consistent; in many cases, this new estimate is so strong that it cannot in fact be true, and thus dimensionally inconsistent inequalities tend to be either false or inefficient, which is why we rarely see them. (More generally, any inequality on which a group acts on either the left or right-hand side can often be “decomposed” into the “isotypic components” of the group action, either by the amplification trick or by other related tools, such as Fourier analysis.)
The amplification trick is a deceptively simple one, but it can become particularly powerful when one is arbitraging an unintuitive symmetry, such as symmetry under tensor powers. Indeed, the “tensor power trick”, which can eliminate constants and even logarithms in an almost magical manner, can lead to some interesting proofs of sharp inequalities, which are difficult to establish by more direct means.
The most familiar example of the amplification trick in action is probably the textbook proof of the Cauchy-Schwarz inequality

for vectors v, w in a complex Hilbert space. To prove this inequality, one might start by exploiting the obvious inequality
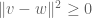
but after expanding everything out, one only gets the weaker inequality
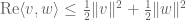
Now (3) is weaker than (1) for two reasons; the left-hand side is smaller, and the right-hand side is larger (thanks to the arithmetic mean-geometric mean inequality). However, we can amplify (3) by arbitraging some symmetry imbalances. Firstly, observe that the phase rotation symmetry 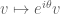
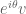

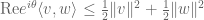
Now we are free to choose 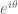
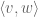
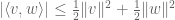
This is closer to (1); we have fixed the left-hand side, but the right-hand side is still too weak. But we can amplify further, by exploiting an imbalance in a different symmetry, namely the homogenisation symmetry 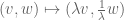
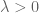
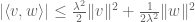
where 




Recent Comments