
You are currently browsing the tag archive for the ‘almost orthogonality’ tag.
In contrast to previous notes, in this set of notes we shall focus exclusively on Fourier analysis in the one-dimensional setting 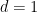

In previous notes we have often performed various localisations in either physical space or Fourier space 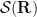
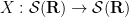
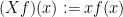
and the momentum operator 
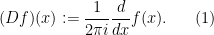
(The terminology comes from quantum mechanics, where it is customary to also insert a small constant 

for any 
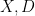
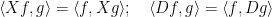
for all 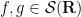
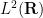
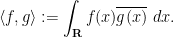
Clearly, for any polynomial 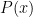

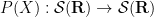

and similarly the operator 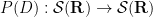
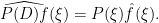
Inspired by this, if 
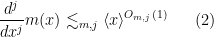
for all 
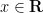

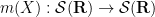

one can easily verify from several applications of the Leibniz rule that 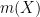
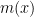
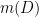
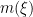
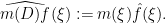
For instance, any constant coefficient linear differential operators 
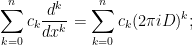
however there are many Fourier multiplier operators that are not of this form, such as fractional derivative operators 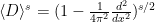

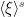

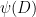

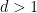
We observe that the maps 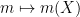
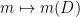
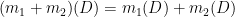
and

for any 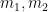


for 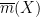
In the field of PDE and ODE, it is also very common to study variable coefficient linear differential operators
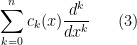
where the 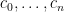
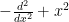
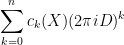
and so it is natural to interpret this operator as a combination 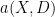



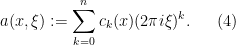
Indeed, from the Fourier inversion formula
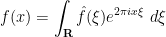
for any
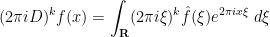
and hence on multiplying by 
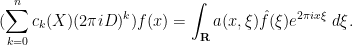
Inspired by this, we can introduce the Kohn-Nirenberg quantisation by defining the operator 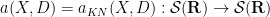
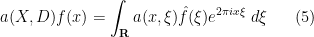
whenever
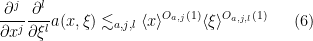
for all 
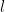


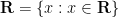


 are two functions obeying
are two functions obeying  for all
for all 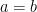 . (Hint: apply
. (Hint: apply  to a suitable truncation of a plane wave
to a suitable truncation of a plane wave 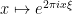 and then take limits.)
and then take limits.)
In principle, the quantisations 
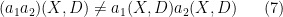
in general. Fundamentally, this is due to the fact that pointwise multiplication of symbols is a commutative operation, whereas the composition of operators such as
![\displaystyle [A,B] := AB - BA](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5BA%2CB%5D+%3A%3D+AB+-+BA&bg=ffffff&fg=000000&s=0&c=20201002)
of two operators 
![\displaystyle [X,D] = -\frac{1}{2\pi i} \neq 0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5BX%2CD%5D+%3D+-%5Cfrac%7B1%7D%7B2%5Cpi+i%7D+%5Cneq+0.&bg=ffffff&fg=000000&s=0&c=20201002)
(In the language of Lie groups and Lie algebras, this tells us that
Exercise 2 (Heisenberg uncertainty principle) For any
and
, show that
(Hint: evaluate the expression
in two different ways and apply the Cauchy-Schwarz inequality.) Informally, this exercise asserts that the spatial uncertainty
and the frequency uncertainty
of a function obey the Heisenberg uncertainty relation
.
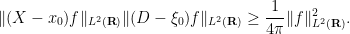
Nevertheless, one still has the correspondence principle, which asserts that in certain regimes (which, with our choice of normalisations, corresponds to the high-frequency regime), quantum mechanics continues to behave like a commutative theory, and one can sometimes proceed as if the operators
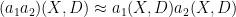
where the error between the left and right-hand sides is of “lower order” and can in fact enjoys a useful asymptotic expansion. As a first approximation to this calculus, one can think of functions 
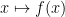


Unfortunately the uncertainty principle (or the non-commutativity of 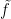

To complement the pseudodifferential calculus we have the basic Calderón-Vaillancourt theorem, which asserts that pseudodifferential operators of order zero are Calderón-Zygmund operators and thus bounded on 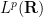
Pseudodifferential operators (especially when generalised to higher dimensions 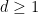
This set of notes is only the briefest introduction to the theory of pseudodifferential operators. Many texts are available that cover the theory in more detail, for instance this text of Taylor.
A fundamental and recurring problem in analytic number theory is to demonstrate the presence of cancellation in an oscillating sum, a typical example of which might be a correlation
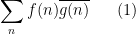
between two arithmetic functions 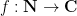



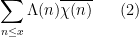
that measures the correlation between the primes and a Dirichlet character 
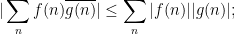
for instance, from the triangle inequality and the prime number theorem we have

as 
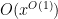
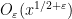

It has proven surprisingly difficult, however, to establish significant cancellation in many of the sums of interest in analytic number theory, particularly if the sums do not have a strong amount of algebraic structure (e.g. multiplicative structure) which allow for the deployment of specialised techniques (such as multiplicative number theory techniques). In fact, we are forced to rely (to an embarrassingly large extent) on (many variations of) a single basic tool to capture at least some cancellation, namely the Cauchy-Schwarz inequality. In fact, in many cases the classical case

considered by Cauchy, where at least one of 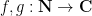


There is however some skill required to decide exactly how to deploy the Cauchy-Schwarz inequality (and in particular, how to select 
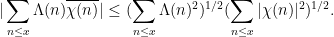
The right-hand side may be bounded by 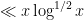
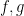
While the Cauchy-Schwarz inequality can be poor at estimating a single correlation such as (1), its power improves when considering an average (or sum, or square sum) of multiple correlations. In this set of notes, we will focus on one such situation of this type, namely that of trying to estimate a square sum
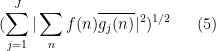
that measures the correlations of a single function 
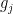
Lemma 1 (Bessel inequality) Let
be finitely supported functions obeying the orthonormality relationship
for all
. Then for any function

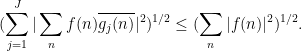
For sake of comparison, if one were to apply the Cauchy-Schwarz inequality (4) separately to each summand in (5), one would obtain the bound of 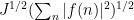

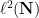
In analytic number theory applications, it is useful to generalise the Bessel inequality to the situation in which the
Proposition 2 (Generalised Bessel inequality) Let
be a non-negative function. Let
vanishes, we have
for some sequence
of complex numbers with
, with the convention that
vanishes whenever
both vanish.


Note by relabeling that we may replace the domain 

Proof: We use the method of duality to replace the role of the function
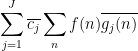
for some complex numbers 


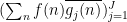
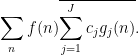
Applying Cauchy-Schwarz (dividing the first factor by 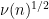
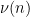

and the claim follows by expanding out the second factor.

Observe that Lemma 1 is a special case of Proposition 2 when 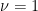
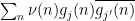
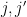
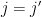
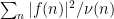
Remark 3 In harmonic analysis, the use of tools such as Proposition 2 is known as the method of almost orthogonality, or the
method. The explanation for the latter name is as follows. For sake of exposition, suppose that
defined by the formula
This is a bounded linear operator, and the left-hand side of (6) is nothing other than the
norm of
. Without any further information on the function
norm
, the best estimate one can obtain on (6) here is clearly
where
denotes the operator norm of
.
The adjoint
is easily computed to be
The composition
of
From the spectral theorem (or singular value decomposition), one sees that the operator norms of
and as
is also the supremum of the quantity
where
ranges over unit vectors in
For further discussion of almost orthogonality methods from a harmonic analysis perspective, see Chapter VII of this text of Stein.
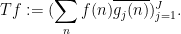



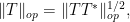
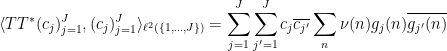
Exercise 4 Under the same hypotheses as Proposition 2, show that
as well as the variant inequality
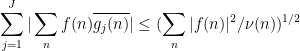


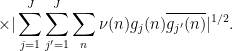
Proposition 2 has many applications in analytic number theory; for instance, we will use it in later notes to control the large value of Dirichlet series such as the Riemann zeta function. One of the key benefits is that it largely eliminates the need to consider further correlations of the function 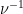

In this set of notes, we will use Proposition 2 to prove some versions of the large sieve inequality, which controls a square-sum of correlations

of an arbitrary finitely supported function 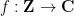
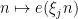
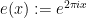

of 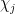
There is however one additional important trick, beyond the large sieve, which we will need in order to establish the Bombieri-Vinogradov theorem. As it turns out, after some basic manipulations (and the deployment of some multiplicative number theory, and specifically the Siegel-Walfisz theorem), the task of proving the Bombieri-Vinogradov theorem is reduced to that of getting a good estimate on sums that are roughly of the form
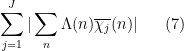
for some primitive Dirichlet characters 

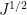

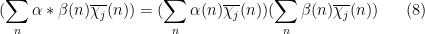
for any finitely supported sequences 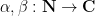
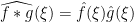
As we have seen in Notes 1, the von Mangoldt function 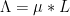


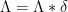
For further reading on these topics, including a significantly larger number of examples of the large sieve inequality, see Chapters 7 and 17 of Iwaniec and Kowalski.
Remark 5 We caution that the presentation given in this set of notes is highly ahistorical; we are using modern streamlined proofs of results that were first obtained by more complicated arguments.
One of the basic problems in analytic number theory is to estimate sums of the form
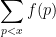
as 
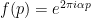

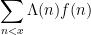
where 

but often (when

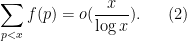
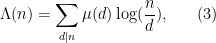
where
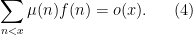
Unfortunately, the connection between (1) and (4) is not particularly tight; roughly speaking, one needs to improve the bounds in (4) (and variants thereof) by about two factors of 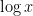
When

the Type I sum
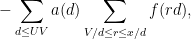
the Type II sum
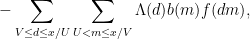
and the error term 

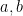
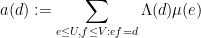
and

Similarly one can express (4) as the Type I sum

the Type II sum
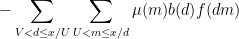
and the error term 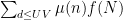
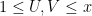
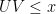


After eliminating troublesome sequences such as 

or Type II sums such as

for various 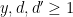
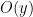
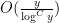

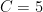
However, in a recent paper of Bourgain, Sarnak, and Ziegler, it was observed that as long as one is only seeking the Mobius orthogonality (4) rather than the von Mangoldt orthogonality (1), one can avoid losing any logarithmic factors, and rely purely on qualitative equidistribution properties of
Proposition 1 (Orthogonality criterion) Let
for any distinct primes
(where the decay rate of the error term
may depend on
). Then

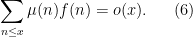
Actually, the Bourgain-Sarnak-Ziegler paper establishes a more quantitative version of this proposition, in which 

As a sample application, Proposition 1 easily gives a proof of the asymptotic
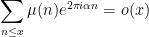
for any irrational
Informally, the connection between (5) and (6) comes from the multiplicative nature of the Möbius function. If (6) failed, then 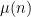

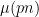
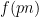
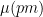
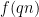
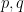

I will give a proof of Proposition 1 below the fold (which is not quite based on the argument in the above mentioned paper, but on a variant of that argument communicated to me by Tamar Ziegler, and also independently discovered by Adam Harper). The main idea is to exploit the following observation: if 
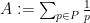
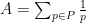

A more precise formalisation of this heuristic is provided by the Turan-Kubilius inequality, which is proven by a simple application of the second moment method.
In particular, one can sum (7) against 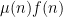

that approximates a sum of
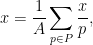
we see (heuristically, at least) that in order to establish (4), it would suffice to establish the sparser estimates
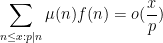
for all 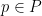
Now we make the change of variables 
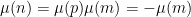


for most 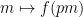
A basic problem in harmonic analysis (as well as in linear algebra, random matrix theory, and high-dimensional geometry) is to estimate the operator norm 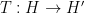

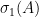
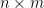

In general, this operator norm is hard to compute precisely, except in special cases. One such special case is that of a diagonal operator, such as that associated to an 


A variant of (1) is Schur’s test, which for simplicity we will phrase in the setting of finite-dimensional operators 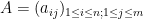
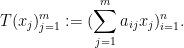
A simple version of this test is as follows: if all the absolute row sums and columns sums of 
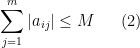
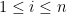 and
and 
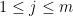 , then
, then 
(note that this generalises (the upper bound in) (1).) Indeed, to see (4), it suffices by duality and homogeneity to show that

whenever 



Schur’s test (4) (and its many generalisations to weighted situations, or to Lebesgue or Lorentz spaces) is particularly useful for controlling operators in which the role of oscillation (as reflected in the phase of the coefficients 
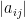

To illustrate the basic flavour of the result, let us return to the bound (1), and now consider instead a block-diagonal matrix
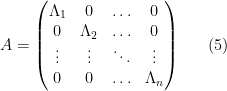
where each 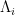
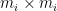
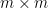
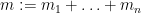

Indeed, the lower bound is trivial (as can be seen by testing 

to decompose an arbitrary vector 

with 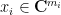
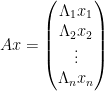
and the upper bound in (6) then follows from a simple computation.
The operator 
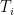
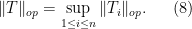
When

The reason for this gain can ultimately be traced back to the “orthogonality” of the


whenever 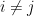

The Cotlar-Stein lemma is an extension of this observation to the case where the
Lemma 1 (Cotlar-Stein lemma) Let
be a finite sequence of bounded linear operators from one Hilbert space
to another
, obeying the bounds
for all
and some
(compare with (2), (3)). Then one has
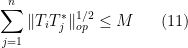
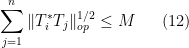


that the hypothesis (11) (or (12)) already gives the bound
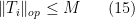
on each component
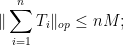
the point of the Cotlar-Stein lemma is that the dependence on 
The Cotlar-Stein lemma was first established by Cotlar in the special case of commuting self-adjoint operators, and then independently by Cotlar and Stein in full generality, with the proof appearing in a subsequent paper of Knapp and Stein.
The Cotlar-Stein lemma is often useful in controlling operators such as singular integral operators or pseudo-differential operators 

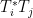
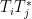



Once one is in the almost orthogonal setting, as opposed to the genuinely orthogonal setting, the previous arguments based on orthogonal projection seem to fail completely. Instead, the proof of the Cotlar-Stein lemma proceeds via an elegant application of the tensor power trick (or perhaps more accurately, the power method), in which the operator norm of 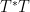

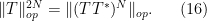
To estimate the right-hand side, we expand out the right-hand side and apply the triangle inequality to bound it by

Recall that when we applied the triangle inequality directly to
To bound (17), we use the basic inequality 


On the other hand, we can group the product by pairs in another way, to obtain the bound of

We bound 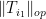


If we then sum this series first in 

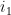

for (16). Taking 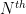

Sending 
Remark 1 As observed in a number of places (see e.g. page 318 of Stein’s book, or this paper of Comech, the Cotlar-Stein lemma can be extended to infinite sums
(with the obvious changes to the hypotheses (11), (12)). Indeed, one can show that for any
, the sum
is unconditionally convergent in
-variation), and the resulting operator
Remark 2 If we specialise to the case where all the
Remark 3 One can prove Schur’s test by a similar method. Indeed, starting from the inequality
(which follows easily from the singular value decomposition), we can bound
by
Estimating the other two terms in the summand by
and the claim follows from the tensor power trick as before. On the other hand, in the converse direction, I do not know of any way to prove the Cotlar-Stein lemma that does not basically go through the tensor power argument.


The first Distinguished Lecture Series at UCLA for this academic year is given by Elias Stein (who, incidentally, was my graduate student advisor), who is lecturing on “Singular Integrals and Several Complex Variables: Some New Perspectives“. The first lecture was a historical (and non-technical) survey of modern harmonic analysis (which, amazingly, was compressed into half an hour), followed by an introduction as to how this theory is currently in the process of being adapted to handle the basic analytical issues in several complex variables, a topic which in many ways is still only now being developed. The second and third lectures will focus on these issues in greater depth.
As usual, any errors here are due to my transcription and interpretation of the lecture.
[Update, Oct 27: The slides from the talk are now available here.]
As many readers may already know, my good friend and fellow mathematical blogger Tim Gowers, having wrapped up work on the Princeton Companion to Mathematics (which I believe is now in press), has begun another mathematical initiative, namely a “Tricks Wiki” to act as a repository for mathematical tricks and techniques. Tim has already started the ball rolling with several seed articles on his own blog, and asked me to also contribute some articles. (As I understand it, these articles will be migrated to the Wiki in a few months, once it is fully set up, and then they will evolve with edits and contributions by anyone who wishes to pitch in, in the spirit of Wikipedia; in particular, articles are not intended to be permanently authored or signed by any single contributor.)
So today I’d like to start by extracting some material from an old post of mine on “Amplification, arbitrage, and the tensor power trick” (as well as from some of the comments), and converting it to the Tricks Wiki format, while also taking the opportunity to add a few more examples.
Title: The tensor power trick
Quick description: If one wants to prove an inequality 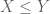
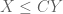
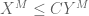
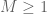
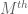

Recent Comments