
You are currently browsing the tag archive for the ‘prime tuples conjecture’ tag.
Tamar Ziegler and I have just uploaded to the arXiv our paper “Infinite partial sumsets in the primes“. This is a short paper inspired by a recent result of Kra, Moreira, Richter, and Robertson (discussed for instance in this Quanta article from last December) showing that for any set 
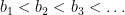


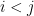
Theorem 1
- (i) If the Hardy-Littlewood prime tuples conjecture (or the weaker conjecture of Dickson) is true, then there exists an increasing sequence
is prime for all
.
- (ii) Unconditionally, there exist increasing sequences
and
of natural numbers such that
is prime for all
- (iii) These conclusions fail if “prime” is replaced by “positive (relative) density subset of the primes” (even if the density is equal to 1).
We remark that it was shown by Balog that there (unconditionally) exist arbitrarily long but finite sequences 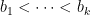

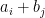

The conclusion of (i) is stronger than that of (ii) (which is of course consistent with the former being conditional and the latter unconditional). The conclusion (ii) also implies the well-known theorem of Maynard that for any given 
Our proof of (i) was initially inspired by the topological dynamics methods used by Kra, Moreira, Richter, and Robertson, but we managed to condense it to a purely elementary argument (taking up only half a page) that makes no reference to topological dynamics and builds up the sequence
The proof of (ii) takes up the majority of the paper. It is easiest to phrase the argument in terms of “prime-producing tuples” – tuples 


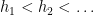
Lemma 2 (Bergelson intersectivity lemma) Letbe subsets of a probability space
of measure uniformly bounded away from zero, thus
. Then there exists a subsequence
such that
for all

This lemma has a short proof, though not an entirely obvious one. Firstly, by deleting a null set from 
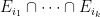
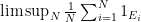

It turns out that one cannot quite combine the standard Maynard sieve with the intersectivity lemma because the events 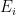
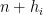
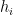
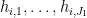

Joni Teräväinen and I have just uploaded to the arXiv our preprint “The Hardy–Littlewood–Chowla conjecture in the presence of a Siegel zero“. This paper is a development of the theme that certain conjectures in analytic number theory become easier if one makes the hypothesis that Siegel zeroes exist; this places one in a presumably “illusory” universe, since the widely believed Generalised Riemann Hypothesis (GRH) precludes the existence of such zeroes, yet this illusory universe seems remarkably self-consistent and notoriously impossible to eliminate from one’s analysis.
For the purposes of this paper, a Siegel zero is a zero 

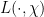

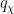

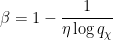
 (which we will call the quality) of the Siegel zero. The significance of these zeroes is that they force the Möbius function
(which we will call the quality) of the Siegel zero. The significance of these zeroes is that they force the Möbius function  and the Liouville function
and the Liouville function  to “pretend” to be like the exceptional character for primes of magnitude comparable to . Indeed, if we define an exceptional prime to be a prime
to “pretend” to be like the exceptional character for primes of magnitude comparable to . Indeed, if we define an exceptional prime to be a prime 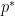 in which
in which  , then very few primes near will be exceptional; in our paper we use some elementary arguments to establish the bounds
, then very few primes near will be exceptional; in our paper we use some elementary arguments to establish the bounds 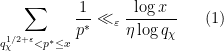
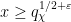 and
and  , where the sum is over exceptional primes in the indicated range
, where the sum is over exceptional primes in the indicated range 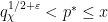 ; this bound is non-trivial for
; this bound is non-trivial for  as large as
as large as 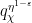 . (See Section 1 of this blog post for some variants of this argument, which were inspired by work of Heath-Brown.) There is also a companion bound (somewhat weaker) that covers a range of a little bit below
. (See Section 1 of this blog post for some variants of this argument, which were inspired by work of Heath-Brown.) There is also a companion bound (somewhat weaker) that covers a range of a little bit below 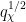 .
.
One of the early influential results in this area was the following result of Heath-Brown, which I previously blogged about here:
Theorem 1 (Hardy-Littlewood assuming Siegel zero) Letbe a fixed natural number. Suppose one has a Siegel zero
for all
, where
is the von Mangoldt function and
is the singular series
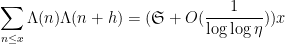
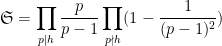
In particular, Heath-Brown showed that if there are infinitely many Siegel zeroes, then there are also infinitely many twin primes, with the correct asymptotic predicted by the Hardy-Littlewood prime tuple conjecture at infinitely many scales.
Very recently, Chinis established an analogous result for the Chowla conjecture (building upon earlier work of Germán and Katai):
Theorem 2 (Chowla assuming Siegel zero) Letbe distinct fixed natural numbers. Suppose one has a Siegel zero
in the range
, where
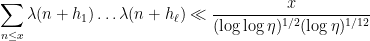
In our paper we unify these results and also improve the quantitative estimates and range of
Theorem 3 (Hardy-Littlewood-Chowla assuming Siegel zero) Letbe distinct fixed natural numbers with
. Suppose one has a Siegel zero
for
for any fixed


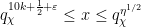
Our argument proceeds by a series of steps in which we replace
- (i) Replace the Liouville function
, which is a completely multiplicative function that agrees with
- (ii) Replace the von Mangoldt function
, which is the Dirichlet convolution
multiplied by a Selberg sieve weight
to essentially restrict that convolution to almost primes.
- (iii) Replace
which has the structure of a “Type I sum”, and which agrees with
- (iv) Replace the approximant
which has the structure of a “Type I sum”.
- (v) Now that all terms in the correlation have been replaced with tractable Type I sums, use standard Euler product calculations and Fourier analysis, similar in spirit to the proof of the pseudorandomness of the Selberg sieve majorant for the primes in this paper of Ben Green and myself, to evaluate the correlation to high accuracy.
Steps (i), (ii) proceed mainly through estimates such as (1) and standard sieve theory bounds. Step (iii) is based primarily on estimates on the number of smooth numbers of a certain size.
The restriction 
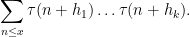
 this sum can be easily controlled by the Dirichlet hyperbola method. For
this sum can be easily controlled by the Dirichlet hyperbola method. For  one needs the fact that has a level of distribution greater than
one needs the fact that has a level of distribution greater than  ; in fact Kloosterman sum bounds give a level of distribution of
; in fact Kloosterman sum bounds give a level of distribution of  , a folklore fact that seems to have first been observed by Linnik and Selberg. We use a (notationally more complicated) version of this argument to treat the sums arising in (iv) for . Unfortunately for
, a folklore fact that seems to have first been observed by Linnik and Selberg. We use a (notationally more complicated) version of this argument to treat the sums arising in (iv) for . Unfortunately for 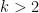 there are no known techniques to unconditionally obtain asymptotics, even for the model sum
there are no known techniques to unconditionally obtain asymptotics, even for the model sum 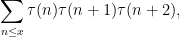 hypothesis in our main theorem at our current level of understanding of analytic number theory.
hypothesis in our main theorem at our current level of understanding of analytic number theory.
Step (v) is a tedious but straightforward sieve theoretic computation, similar in many ways to the correlation estimates of Goldston and Yildirim used in their work on small gaps between primes (as discussed for instance here), and then also used by Ben Green and myself to locate arithmetic progressions in primes.

Recent Comments