
In a recent paper, Yitang Zhang has proven the following theorem:
Theorem 1 (Bounded gaps between primes) There exists a natural number
such that there are infinitely many pairs of distinct primes
with
.
Zhang obtained the explicit value of 

Zhang’s argument naturally divides into three steps, which we describe in reverse order. The last step, which is the most elementary, is to deduce the above theorem from the following weak version of the Dickson-Hardy-Littlewood (DHL) conjecture for some 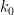
Theorem 2 (
) Let
be an admissible
for every prime
Zhang obtained 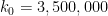
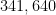
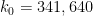
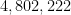

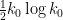
The second step in Zhang’s argument, which is somewhat less elementary (relying primarily on the sieve theory of Goldston, Yildirim, Pintz, and Motohashi), is to deduce ![{MPZ[\varpi,\delta]}](https://s0.wp.com/latex.php?latex=%7BMPZ%5B%5Cvarpi%2C%5Cdelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
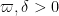
Conjecture 3 (
be an element of
be a large parameter, and define
for any natural number
, and
for any function
. Let
equal
when
is a prime
otherwise. Then one has
for any fixed
.
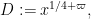

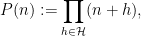

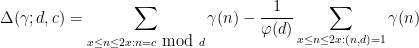
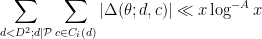
Note that this is slightly different from the formulation of ![{MPZ[\varpi]}](https://s0.wp.com/latex.php?latex=%7BMPZ%5B%5Cvarpi%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
In the previous post, I described how one can deduce 
![{g: [0,1] \rightarrow {\bf R}}](https://s0.wp.com/latex.php?latex=%7Bg%3A+%5B0%2C1%5D+%5Crightarrow+%7B%5Cbf+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

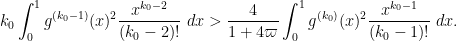
By selecting 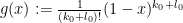


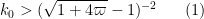
It may be possible to do better than this by choosing smarter choices for 
The final, and deepest, part of Zhang’s work is the following theorem (Theorem 2 from Zhang’s paper, whose proof occupies Sections 6-13 of that paper, and is about 32 pages long):
![{MPZ[\varpi,\varpi]}](https://s0.wp.com/latex.php?latex=%7BMPZ%5B%5Cvarpi%2C%5Cvarpi%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is true for all
is true for all 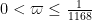 .
.
The significance of the fraction 
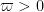

(see page 53 of Zhang) which is equivalent to 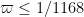
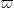
Improving the value of
- Going through Zhang’s argument in order to improve the value of
- Gaining a more holistic understanding of Zhang’s argument (and perhaps to find some more “global” improvements to that argument), as well as related arguments such as the prior work of Bombieri, Fouvry, Friedlander, and Iwaniec that Zhang’s work is based on.
In addition to reading through Zhang’s paper, the following material is likely to be relevant:
- A recent blog post of Emmanuel Kowalski on the technical details of Zhang’s argument.
- Scanned notes from a talk related to the above blog post.
- A recent expository note by Fouvry, Kowalski, and Michel on a Friedlander-Iwaniec character sum relevant to this argument.
- This 1981 paper of Fouvry and Iwaniec which is the first result in the literature which is roughly of the type
and
, if I read it correctly; I don’t yet understand what prevents this result or modifications thereof from being used in place of Theorem 4.)
I envisage a loose, unstructured format for the reading seminar. In the comments below, I am going to post my own impressions, questions, and remarks as I start going through the material, and I encourage other participants to do the same. The most obvious thing to do is to go through Zhang’s Sections 6-13 in linear order, but it may make sense for some participants to follow a different path. One obvious near-term goal is to carefully go through Zhang’s arguments for ![{MPZ[1/1168,1/1168]}](https://s0.wp.com/latex.php?latex=%7BMPZ%5B1%2F1168%2C1%2F1168%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Everyone is welcome to participate in this project (as per the usual polymath rules); however I would request that “meta” comments about the project that are not directly related to the task of reading Zhang’s paper and related works be placed instead on the polymath proposal page. (Similarly, comments regarding the optimisation of

140 comments
Comments feed for this article
9 July, 2013 at 11:23 am
The p-group fixed point theorem | Annoying Precision
[…] into bounds on the former, and this has various applications, for example the original proof of Zhang’s theorem on bounded gaps between primes (although my understanding is that this step is unnecessary just to […]
4 October, 2013 at 1:53 pm
zhang twin prime breakthru vs academic track/grind | Turing Machine
[…] 7. Online reading seminar for Zhang’s “bounded gaps between primes” | What’s new […]
19 November, 2013 at 4:13 pm
An online reading seminar from Terry Tao’s blog | The Conscious Mathematician
[…] https://terrytao.wordpress.com/2013/06/04/online-reading-seminar-for-zhangs-bounded-gaps-between-prim… […]
25 June, 2014 at 9:52 pm
大数学家张益唐的唐诗舒怀 | Chinoiseries 《汉瀚》
[…] https://terrytao.wordpress.com/2013/06/04/online-reading-seminar-for-zhangs-bounded-gaps-between-prim… […]
17 December, 2014 at 5:59 am
王晓明
从张益唐论文不能发表评数学批判家王晓明的批判艺术
开场白:
张益唐的论文因为王晓明的搅局,至今没有发表,这是因为王晓明在2014年3月20日写信给美国【数学年刊】编辑部,阻止了原计划在5月出版的179-3期杂志,不能按照正常时间出版。如今已经12月中旬,以后是否能够发表暂且不说,仅仅一个无名之辈就让大名鼎鼎的【数学年刊】改变计划,足以证明王晓明出手不凡。王晓明是怎么样的批评,能够让世界上数一数二的杂志接受批评呢?
也有人说张益唐是遭到嫉妒,木秀于林风必摧之,如果张益唐文章没有致命错误,什么妖风可以摧毁呢?
如果王晓明是一个平庸之人,他的意见都是无稽之谈,没有思想的利器,他给【数学年刊】的信件只会成为笑柄。这是因为在所有学科中,数学的证明最严格,可以做到没有任何歧义,可以做到让全世界数学家都可以接受的严密程度。
是什么原因让王晓明去挑战全世界最权威的数学家已经认可的理论?王晓明难道就是一个数学无赖存心与科学界捣蛋吗?这样做王晓明可以得到什么呢?
一定是这个命题的魅力,永不凋谢的青春产生神秘的诱惑,在她的入口处,正向在地狱的入口处一样。张益唐没有通过凯旋门,而是走到了地狱。
第一刀:
王晓明杀入张益唐的第一刀是什么?
数学批判一般有三个批判点,第一是论(命)题批判,第二的论据批判,第三是论证方法批判。
对张益唐结论的杀伤力无疑最强烈,这是因为,否定了结论就彻底否定了整个工作。
张益唐公式:
一开始就让人感觉丑陋,不等式左边表明一种性质,下确界是针对一组数据,极限针对函数和序列,而右边70000000是说左边的素数对,好了,破绽就在这里。小于70000000的素数对是一个“集合概念”。集合概念反映的是集合体,集合体有什么不对吗?
概念的种类:
1,单独概念和普遍概念
a,单独概念反映独一无二的概念,例如,上海,孙中山,,,。它们反映的概念都是独一无二的。
b,普遍概念,普遍概念反映的是一个对象以上的概念,反映的是一个“类”,例如:工人,无论“石油工人”,“钢铁工人”,还是“中国工人”,“德国工人”,它们必然地具有“工人”的基本属性。
2,集合概念和非集合概念。
a,集合概念反映的是集合体,例如“中国工人阶级”,集合体的每一个个体不是必然具备集合体的基本属性,例如某一个“中国工人”,不是必然具有“中国工人阶级”的基本属性。
b,非集合概念(省略)。
大家明白了吗?张益唐如果要说不超过70000000的素数对具有无穷性质,必须对所有小于70000000的素数对逐一证明,就是要使用完全归纳法:
1)相差2的素数对(这是一个类)无穷。
2)相差4的素数对(类)无穷。
3)相差6的素数对(类)无穷。
…….
35000000)相差7000000的素数对(类)无穷。
张益唐没有确定相差不超过70000000的素数对都是无穷的。张益唐等于什么也没有说。
第二刀
什么是判断?判断就是对思维对象有所断定的形式。
判断的基本性质:
1,有所肯定或者有所否定。
2,判断有真假。
张益唐没有确定任何一个类是无穷或者有限,张益唐什么也没有说。就是说,张益唐的证明违背了一个判断的基本要求,暂且不说对与错。就连一个明确的判断都没有。
数学证明就是要求对数学对象给予一个明确的判断。
第三刀
就算张益唐想说:“相差不超过70000000的素数对至少有一对是无穷的”。这个也没有做到一个定理的要求啊?张益唐是说“有些A是B”,这是一种“特称判断”这样的说法不能作为数学定理,因为数学定理要求明确的“全称判断”,就是“一切都A是B”。特称判断在日常生活中使用没有问题,甚至在其它学科也没有问题,例如物理学。唯独在数学证明中特称判断无效。
第四刀
一个定理陈述一个给定类的所有数学元素不变的关系,适用于无限大的类,在任何时候都无区别成立。张益唐公式左边的变量部分输入一个值,得出结果是需要区别的,就不是定理了,这些结果,人们无法知道,张益唐自己也无法知道:“无穷还是有限”。或者说右边70000000以内的任何一个值对应左边是什么?是无法知道的。
第五刀
特称判断为什么不能作为定理?因为特称判断暗含“假定存在”的非逻辑前提,数学证明是严禁使用非逻辑前提,在逻辑学也不允许引入非逻辑前提。这是我们数学中常常发现一个显然的事实却不能成为定理的困难。如果可以引入非逻辑前提,那么数学难题就不会有这么多了。
小节
浪漫情怀不能代替严肃的证明,迷信和伪科学让人们不动脑筋就可以欢欣鼓舞,迷信迎合人们懒得思考的需求。而科学是在逐一消除错误的基础之上发展起来的。张益唐的错误工作被否定,私人感情当然受到伤害,但是这种否证公认为科学的核心。
26 November, 2015 at 7:17 pm
tomcircle
Reblogged this on Math Online Tom Circle.
29 March, 2016 at 10:18 am
Quora
What math problem has never been solved?
If you’re referring to the twin primes hypothesis, the hypothesis is just that there are infinite primes that satisfy the condition (only one integer apart from another prime). The hypothesis is *not* that all primes are twin primes. A very, very weak…