
Now that we have reviewed the foundations of measure theory, let us now put it to work to set up the basic theory of one of the fundamental families of function spaces in analysis, namely the 
Just as scalar quantities live in the space of real or complex numbers, and vector quantities live in vector spaces, functions 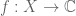

- Vector space structure. One can often add two functions
in a function space
in that space
in
and get another function
in
- Algebra structure. Sometimes (though not always), we also wish to multiply two functions
in
in
- Norm structure. We often want to distinguish “large” functions in
to each function that measures its size. Unlike the situation with scalars, where there is basically a single notion of magnitude, functions have a wide variety of useful notions of size, each measuring a different aspect (or combination of aspects) of the function, such as height, width, oscillation, regularity, decay, and so forth. Typically, each such norm gives rise to a separate function space (although sometimes it is useful to consider a single function space with multiple norms on it). We usually require the norm to be compatible with the vector space structure (and algebra structure, if present), for instance by demanding that the triangle inequality hold.
- Metric structure. We also want to tell whether two functions f, g in a function space V are “near together” or “far apart”. A typical way to do this is to impose a metric
on the space
and a vector space structure are available, there is an obvious way to do this: define the distance between two functions
. (This will be the only type of metric on function spaces encountered in this course. But there are some nonlinear function spaces of importance in nonlinear analysis (e.g. spaces of maps from one manifold to another) which have no vector space structure or norm, but still have a metric.) It is often important to know if the vector space is complete with respect to the given metric; this allows one to take limits of Cauchy sequences, and (with a norm and vector space structure) sum absolutely convergent series, as well as use some useful results from point set topology such as the Baire category theorem. All of these operations are of course vital in analysis. [Compactness would be an even better property than completeness to have, but function spaces unfortunately tend be non-compact in various rather nasty ways, although there are useful partial substitutes for compactness that are available, see e.g. this blog post of mine.]
- Topological structure. It is often important to know when a sequence (or, occasionally, nets) of functions
in
of more general functions that contain
- Functional structures. Since numbers are easier to understand and deal with than functions, it is not surprising that we often study functions f in a function space V by first applying some functional
to V to identify some key numerical quantity
associated to f. Norms
are of course one important example of a functional; integration
provides another; and evaluation
at a point x provides a third important class. (Note, though, that while evaluation is the fundamental feature of a function in set theory, it is often a quite minor operation in analysis; indeed, in many function spaces, evaluation is not even defined at all, for instance because the functions in the space are only defined almost everywhere!) An inner product
on
of useful functionals. It is of particular interest to study functionals that are compatible with the vector space structure (i.e. are linear) and with the topological structure (i.e. are continuous); this will give rise to the important notion of duality on function spaces.
- Inner product structure. One often would like to pair a function f in a function space V with another object g (which is often, though not always, another function in the same function space V) and obtain a number
, that typically measures the amount of “interaction” or “correlation” between f and g. Typical examples include inner products arising from integration, such as
; integration itself can also be viewed as a pairing,
. Of course, we usually require such inner products to be compatible with the other structures present on the space (e.g., to be compatible with the vector space structure, we usually require the inner product to be bilinear or sesquilinear). Inner products, when available, are incredibly useful in understanding the metric and norm geometry of a space, due to such fundamental facts as the Cauchy-Schwarz inequality and the parallelogram law. They also give rise to the important notion of orthogonality between functions.
- Group actions. We often expect our function spaces to enjoy various symmetries; we might wish to rotate, reflect, translate, modulate, or dilate our functions and expect to preserve most of the structure of the space when doing so. In modern mathematics, symmetries are usually encoded by group actions (or actions of other group-like objects, such as semigroups or groupoids; one also often upgrades groups to more structured objects such as Lie groups). As usual, we typically require the group action to preserve the other structures present on the space, e.g. one often restricts attention to group actions that are linear (to preserve the vector space structure), continuous (to preserve topological structure), unitary (to preserve inner product structure), isometric (to preserve metric structure), and so forth. Besides giving us useful symmetries to spend, the presence of such group actions allows one to apply the powerful techniques of representation theory, Fourier analysis, and ergodic theory. However, as this is a foundational real analysis class, we will not discuss these important topics much here (and in fact will not deal with group actions much at all).
- Order structure. In some cases, we want to utilise the notion of a function f being “non-negative”, or “dominating” another function g. One might also want to take the “max” or “supremum” of two or more functions in a function space V, or split a function into “positive” and “negative” components. Such order structures interact with the other structures on a space in many useful ways (e.g. via the Stone-Weierstrass theorem). Much like convexity, order structure is specific to the real line and is another reason why much of real analysis breaks down over other fields. (The complex plane is of course an extension of the real line and so is able to exploit the order structure of that line, usually by treating the real and imaginary components separately.)
There are of course many ways to combine various flavours of these structures together, and there are entire subfields of mathematics that are devoted to studying particularly common and useful categories of such combinations (e.g. topological vector spaces, normed vector spaces, Banach spaces, Banach algebras, von Neumann algebras, C^* algebras, Frechet spaces, Hilbert spaces, group algebras, etc.). The study of these sorts of spaces is known collectively as functional analysis. We will study some (but certainly not all) of these combinations in an abstract and general setting later in this course, but to begin with we will focus on the
—
In this post, 
For sake of concreteness, we shall select the field of scalars to be the complex numbers 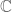
We already have the notion of an absolutely integrable function on X, which is a function 
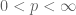
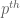

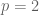

Remark 1. One can also extend these notions to functions that take values in the extended complex plane 

Following the “Lebesgue philosophy” that one should ignore whatever is going on on a set of measure zero, let us declare two measurable functions to be equivalent if they agree almost everywhere. This is easily checked to be an equivalence relation, which does not affect the property of being 
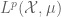

Exercise 0. If 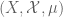

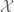


Remark 2. Depending on which of the three structures 
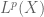

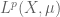



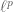
At present, the Lebesgue spaces
We begin with vector space structure. Fix 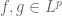
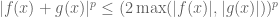

we see that the sum of two
Next, we set up the norm structure. If 


this is a finite non-negative number by definition of

for all 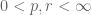
The
Lemma 1. Let
- (Non-degeneracy)
if and only if f = 0.
- (Homogeneity)
for all complex numbers c.
- ((Quasi-)triangle inequality) We have
for some constant C depending on p. If
, then we can take C=1 (this fact is also known as Minkowski’s inequality).
Proof. The claims 1, 2 are obvious. (Note how important it is that we equate functions that vanish almost everywhere in order to get 1.) The quasi-triangle inequality follows from a variant of the estimates in (1) and is left as an exercise. For the triangle inequality, we have to be more efficient than the crude estimate (1). By the non-degeneracy property we may take 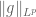



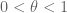
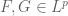

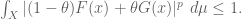
But observe that for 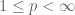


(If one wishes, one can use the complex triangle inequality to first reduce to the case when F, G are non-negative, in which case one only needs convexity on 

Exercise 1. Let 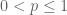
- Establish the variant
of the triangle inequality.
- If furthermore f and g are non-negative (almost everywhere), establish also the reverse triangle inequality
.
- Show that the best constant C in the quasi-triangle inequal
- ity is
. In particular, the triangle inequality is false for
.
- Now suppose instead that
or
. If
, show that one of the functions f, g is a non-negative scalar multiple of the other (up to equivalence, of course). What happens when p=1?
A vector space V with a function 



Exercise 2. Let 

Exercise 3. If 

We now are able to define 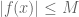

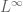
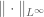


Now we explain why we call this norm the
Example 1. Let f be a (generalised) step function, thus 
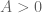

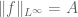

Exercise 4.
- If
for some
, show that
as
. (Hint: use the monotone convergence theorem.)
- If
, show that
as
Once one has a vector space structure and a (quasi-)norm structure, we immediately get a (quasi-)metric structure:
Exercise 5. Let 
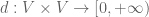




One can check (exercise!) that the quasi-metric balls 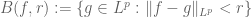


Recall that any series 

Exercise 6. Let
- V is a complete metric space (i.e. every Cauchy sequence converges).
- Every sequence
which is absolutely convergent (i.e.
), is also conditionally convergent (i.e.
converges to a limit as
.
Remark 3. The situation is more complicated for complete quasi-normed vector spaces; not every absolutely convergent series is conditionally convergent. On the other hand, if 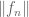
Remark 4. Let X be a topological space, and let BC(X) be the space of bounded continuous functions on X; this is a vector space. We can place the uniform norm 
A space obeying the properties in Exercise 4 (i.e. a complete normed vector space) is known as a Banach space. We will study Banach spaces in more detail later in this course. For now, we give one of the fundamental examples of Banach spaces.
Proposition 1.
.
Proof. By Exercise 6, it suffices to show that any series 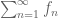




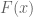

An important fact is that functions in
Proposition 2. If
(The concept of a non-trivial dense subspace is one which only comes up in infinite dimensions, and is hard to visualise directly. Very roughly speaking, the infinite number of degrees of freedom in an infinite dimensional space gives a subspace an infinite number of “opportunities” to come as close as one desires to any given point in that space, which is what allows such spaces to be dense.)
Proof. The only non-trivial thing to show is the density. An application of the monotone convergence theorem shows that the space of bounded
Remark 5. Since not every function in
Exercise 7. Show that the space of simple functions (not necessarily with finite measure support) is a dense subspace of
Exercise 7a. Suppose that
Next, we turn to algebra properties of
Proposition 3. (Hölder’s inequality) Let
for some
. Then
and
, where the exponent r is defined by the formula
.
Proof. This will be a variant of the proof of the triangle inequality in Lemma 1, again relying ultimately on convexity. The claim is easy when 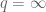


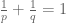
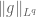


Here, we use the convexity of the exponential function 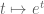

![t \in [0,1]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002)

and the claim (6) follows from the normalisations on p, q, f, g.
Remark 6. For a different proof of this inequality (based on the tensor power trick), see Example 1 of this blog post of mine.
Remark 7. One can also use Hölder’s inequality to prove the triangle inequality for 
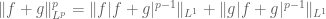
while Hölder’s inequality gives 


Remark 8. The proofs of Hölder’s inequality and Minkowski’s inequality both relied on convexity of various functions in
Example 2. It is instructive to test Hölder’s inequality (and also Exercises 8-12 below) in the special case when f, g are generalised step functions, say 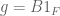

which can be easily deduced from the hypothesis 




Exercise 8. Let 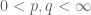
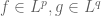

An important corollary of Hölder’s inequality is the Cauchy-Schwarz inequality

which can of course be proven by many other means.
Exercise 9. If 
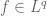
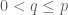

Exercise 10. If 

Exercise 11. If 

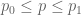


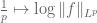
Exercise 12. If 






— Linear functionals on
Given an exponent 
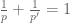

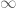



is well-defined on
A deep and important fact about
Theorem 1. Let
be a continuous linear functional. Then there exists a unique
.
This result should be compared with the Radon-Nikodym theorem (Corollary 1 from Notes 1). Both theorems start with an abstract function 
To prove Theorem 1, we first need a simple and useful lemma:
Lemma 2. (Continuity is equivalent to boundedness for linear operators) Let
be a linear transformation from one normed vector space
to another
. Then the following are equivalent:
- T is continuous.
- T is continuous at 0.
- There exists a constant C such that
for all
.
Proof. It is clear that 1 implies 2, and that 3 implies 2. Next, from linearity we have 

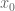
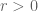

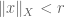
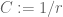
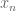



Proof of Theorem 1. The uniqueness claim is similar to the uniqueness claim in the Radon-Nikodym theorem (Exercise 2 from Notes 1) and is left as an exercise to the reader; the hard part is establishing existence.
Let us first consider the case when 

Since 

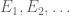





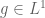
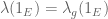
for all measurable E. By linearity, this implies that 

To finish the theorem in this case, we need to establish that g lies in 
We already know that 


Suppose first that 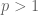




We can’t quite make that argument work, because it is circular: it assumes 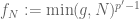


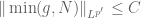
In the p=1 case, we instead use 
This handles the case when 



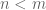

Remark 9. When 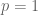
Remark 10. We have seen how the Lebesgue-Radon-Nikodym theorem can be used to establish Theorem 1. The converse is also true: Theorem 1 can be used to deduce the Lebesgue-Radon-Nikodym theorem (a fact essentially observed by von Neumann). For simplicity, let us restrict attention to the unsigned finite case, thus 



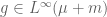

for all 

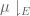

and one then easily verifies that 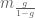
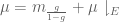
Remark 11. The argument used in Remark 10 also shows that the Radon-Nikodym theorem implies the Lebesgue-Radon-Nikodym theorem.
In a later set of notes, we will give an alternate proof of Theorem 1, which relies on the geometry of

124 comments
Comments feed for this article
10 March, 2017 at 1:42 pm
Anonymous
In 247a notes 1 Problem 5.3 “Show that the triangle inequality is sharp if and only if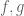 ” are parallel, thus either
” are parallel, thus either  ,
,  or
or  for some real positive $c$. ”
for some real positive $c$. ”
Must here be a constant? (What does “parallel” mean here?)
here be a constant? (What does “parallel” mean here?)
Suppose . Isn’t it true that
. Isn’t it true that
[Problem 5.3 in those notes should have the additional constraint . Parallel here is in the sense of parallel vectors in a vector space. -T.]
. Parallel here is in the sense of parallel vectors in a vector space. -T.]
26 March, 2017 at 11:31 am
Anonymous
For Exercise 4(1), I can only show that
since a.e.
a.e.
How should I do the other direction?
—–
Would you elaborate how is one supposed to use the monotone convergence theorem?
15 November, 2017 at 6:44 pm
Anonymous
Do you have a hint for Exercise 1(4)? I have no idea how to get information out of
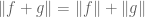
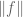 and
and 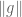 are both positive.
are both positive.
when
I have worked on the triangle inequality in the Euclidean spaces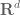 (corresponding to counting measure on the space with finite cardinality I think). I find that the cases
(corresponding to counting measure on the space with finite cardinality I think). I find that the cases  have been difficult for me: one cannot make a geometric argument…
have been difficult for me: one cannot make a geometric argument…
[Hint: review your solution to Exercise 1(2). -T]
16 November, 2017 at 1:23 pm
Anonymous
Since for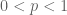 , the function
, the function 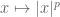 is concave, one has the reverse inequality in (4) and (5) in the proof of lemma 1 so that one can conclude the reverse inequality for
is concave, one has the reverse inequality in (4) and (5) in the proof of lemma 1 so that one can conclude the reverse inequality for  (
(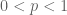 ) for all
) for all  , which is obviously not true. What goes wrong?
, which is obviously not true. What goes wrong?
16 November, 2017 at 1:27 pm
Anonymous
“reverse inequality” should be “reverse triangle inequality” above.
17 November, 2017 at 10:52 am
Terence Tao
The function is not concave at zero. However, as long as one avoids zero, one does get a reverse triangle inequality: see part 2 of Exercise 1.
is not concave at zero. However, as long as one avoids zero, one does get a reverse triangle inequality: see part 2 of Exercise 1.
22 April, 2023 at 2:12 am
Vi
Dear Prof. Tao, is sharp iff
is sharp iff  . Is there an elementary way to prove this equality condition? Can you please give a hint (Does holders inequality help?) thanks
. Is there an elementary way to prove this equality condition? Can you please give a hint (Does holders inequality help?) thanks
Taking your hint for Exercise 1(4), I see that proving the proportionality boils down to proving that the inequality
[This is equivalent to the strict convexity of the function – T.]
– T.]
16 November, 2017 at 2:05 pm
Anonymous
For Exercise 1(3), one can exploit to get the constant
to get the constant  . But how can one show that this the “best” constant?
. But how can one show that this the “best” constant?
[Hint: think about when equality occurs in the inequality you mentioned. -T]
18 November, 2017 at 1:00 pm
Anonymous
Do you have a hint for Exercise 10? I tried the “simplest” case first but I don’t see how to go on after writing down the definition: ?
?
how to get
26 November, 2017 at 10:29 am
Terence Tao
You might find the general problem solving strategies in https://terrytao.wordpress.com/2010/10/21/245a-problem-solving-strategies/ to be of assistance. In particular, strategy 3 may help: try first the situation of an indicator function, then a simple function, to get an idea of how to solve the general case.
19 November, 2017 at 12:31 pm
Anonymous
Suppose . In your 274a notes, it is said that if
. In your 274a notes, it is said that if  is bounded above by a constant
is bounded above by a constant  , then
, then
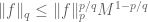
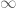 exponent, while if
exponent, while if  is bounded below by
is bounded below by  on its support, then one has the reverse inequality
on its support, then one has the reverse inequality

which could be done by the log-convexity at the
How do you prove the second one?
20 November, 2017 at 12:51 pm
Anonymous
I have just asked a stupid question. Found that the second one follows from the pointwise estimate:
 .
.
26 December, 2018 at 9:32 am
245A: Problem solving strategies | What's new
[…] to achieve a normalisation , which can be convenient for some proofs of this inequality (see this previous blog post for more […]
8 April, 2020 at 12:02 pm
Anonymous
Can one prove that (
(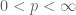 ) is separable without invoking Exercise 7a?
) is separable without invoking Exercise 7a?
What can one say about separability in general for arbitrary (
(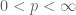 ) spaces?
) spaces?
8 April, 2020 at 12:42 pm
Terence Tao
Separability of Lebesgue spaces is closely related to separability of the underlying sigma-algebra.
9 April, 2020 at 6:12 am
Anonymous
In your PCM article of harmonic analysis:
…
So the “control of two ‘extreme’ norms automatically implies further control on ‘intermediate’ norms… ”
Why in the log convexity inequality
one needs the “extra” constraint that
instead of just for all and
and  with
with  ?
?
9 April, 2020 at 7:55 am
Terence Tao
The constraint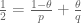 can be viewed as determining the exact exponent of
can be viewed as determining the exact exponent of  that makes the inequality true; it is mandated for instance by dimensional analysis or scale invariance considerations (as discussed for instance in my recent lecture notes https://terrytao.wordpress.com/2020/03/29/247b-notes-1-restriction-theory/ ).
that makes the inequality true; it is mandated for instance by dimensional analysis or scale invariance considerations (as discussed for instance in my recent lecture notes https://terrytao.wordpress.com/2020/03/29/247b-notes-1-restriction-theory/ ).
18 April, 2020 at 7:41 am
Anonymous
So the norm of a function says something about the “width” and “height” of the function. What is the intuition of the weak
norm of a function says something about the “width” and “height” of the function. What is the intuition of the weak  norm? In other words, intuitively, what “information” one gains if one can control the weak
norm? In other words, intuitively, what “information” one gains if one can control the weak  norm of a function
norm of a function  :
:
18 April, 2020 at 8:27 am
Terence Tao
For a function which mostly exists at a single scale, with a single width and height, the strong and weak norms are basically equivalent (as are all the other Lorentz norms
norms are basically equivalent (as are all the other Lorentz norms 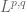 at this exponent). The distinction between the strong and weak norms only becomes apparent when considering functions that exist at multiple scales. For instance consider the function
at this exponent). The distinction between the strong and weak norms only becomes apparent when considering functions that exist at multiple scales. For instance consider the function
on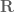 , where
, where  are widely separated scales (the exact choice is not important for this example so long as
are widely separated scales (the exact choice is not important for this example so long as  for each
for each 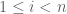 ). Each individual term
). Each individual term ![N_i^{-1/p} 1_{[N_i,2N_i]}](https://s0.wp.com/latex.php?latex=N_i%5E%7B-1%2Fp%7D+1_%7B%5BN_i%2C2N_i%5D%7D&bg=ffffff&fg=545454&s=0&c=20201002) in this expression has both strong and weak
in this expression has both strong and weak  norm equal to 1, as befits a function of height
norm equal to 1, as befits a function of height  and width
and width 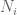 ; but the sum
; but the sum  has a strong
has a strong  norm of
norm of  and a weak
and a weak  norm comparable to 1. (More generally, the
norm comparable to 1. (More generally, the 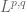 norm is comparable to
norm is comparable to 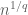 in this example.)
in this example.)
To put it another way: up to logarithmic corrections, all the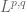 norms can be thought of as “
norms can be thought of as “ ''. If one wishes to take logarithmic corrections into account (but are possibly willing to ignore double logarithmic corrections), one can think of the
''. If one wishes to take logarithmic corrections into account (but are possibly willing to ignore double logarithmic corrections), one can think of the 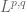 norm as basically being the worst value of “
norm as basically being the worst value of “ '' present in the function, times the number of scales where this worst value is attained raised to the power
'' present in the function, times the number of scales where this worst value is attained raised to the power 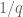 .
.
18 April, 2020 at 11:19 am
Anonymous
I have seen the term “scales” (of a function) mentioned quite a few times in some of your articles. But I don’t really follow what it means. It seems to be a loose term, but it was used in various rigorous arguments. (For instance, it is the theme of this article: https://terrytao.wordpress.com/2019/06/14/abstracting-induction-on-scales-arguments/) Would you elaborate on what it really means? For instance, is the function![f=100\cdot 1_{[0,1]}](https://s0.wp.com/latex.php?latex=f%3D100%5Ccdot+1_%7B%5B0%2C1%5D%7D&bg=ffffff&fg=545454&s=0&c=20201002) considered as “large scale while
considered as “large scale while ![f=0.001\cdot 1_{[0,1]}](https://s0.wp.com/latex.php?latex=f%3D0.001%5Ccdot+1_%7B%5B0%2C1%5D%7D&bg=ffffff&fg=545454&s=0&c=20201002) as “small scale”? Does it also have anything to do with the (size) support of the function?
as “small scale”? Does it also have anything to do with the (size) support of the function?
Going back to the example you gave in the comment, besides “small” and “big” scales, you also seem to tell the difference between “single” scale vs “multiple” scales. What does that mean? (Can such terms be defined in a mathematical way?)
19 April, 2020 at 10:49 am
Terence Tao
Informally, a scale is an order of magnitude of length (or some other physically or geometrically meaningful quantity). For instance, the Earth is essentially flat at human scales (~1m), essentially a ball at global scales (~10^7 m), and essentially a point at astronomical scales (e.g., 1AU or larger); at the opposite extreme, the Earth becomes a discrete lattice-like object at molecular scales (~1 Å) and a very weird sea of quantum foam at the Planck scale. All of these scales are meaningful, but if one wants to study the Earth as a whole, it is the global scale (~10^7 m) that is the most relevant.
A step function![f = A 1_{[0,N]}](https://s0.wp.com/latex.php?latex=f+%3D+A+1_%7B%5B0%2CN%5D%7D&bg=ffffff&fg=545454&s=0&c=20201002) would have a significant presence at one amplitude scale
would have a significant presence at one amplitude scale  and one length scale
and one length scale  ; a sum of two functions
; a sum of two functions ![f= A_1 1_{[0,N_1]} + A_2 1_{[1,N_2]}](https://s0.wp.com/latex.php?latex=f%3D+A_1+1_%7B%5B0%2CN_1%5D%7D+%2B+A_2+1_%7B%5B1%2CN_2%5D%7D&bg=ffffff&fg=545454&s=0&c=20201002) with two very different amplitudes
with two very different amplitudes  and two different widths
and two different widths 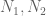 would exist at two amplitude scales and two length scales. For functions that are normalised to be of roughly unit size in
would exist at two amplitude scales and two length scales. For functions that are normalised to be of roughly unit size in  or weak
or weak  , the amplitude
, the amplitude  and width
and width  become constrained to each other by the relation
become constrained to each other by the relation  (at least for the “dominant” scale components of the function), so there is really only one degree of freedom in scale in this context. (For more complicated norms, such as mixed norms or Sobolev norms, there can be multiple independent notions of scale, for instance there can be a frequency scale in addition to a spatial scale that are partially connected to each other by the uncertainty principle but which can otherwise vary independently.) Whether one considers
(at least for the “dominant” scale components of the function), so there is really only one degree of freedom in scale in this context. (For more complicated norms, such as mixed norms or Sobolev norms, there can be multiple independent notions of scale, for instance there can be a frequency scale in addition to a spatial scale that are partially connected to each other by the uncertainty principle but which can otherwise vary independently.) Whether one considers 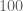 ,
,  , and
, and  to be distinct scales depends on your point of view; for real world applications a change of two or three orders of magnitude can make a lot of difference, but in many problems in analysis we ignore the effect of absolute constants and all such scales would be considered equivalent in the asymptotic regime.
to be distinct scales depends on your point of view; for real world applications a change of two or three orders of magnitude can make a lot of difference, but in many problems in analysis we ignore the effect of absolute constants and all such scales would be considered equivalent in the asymptotic regime.
It’s possible to make the notion of scale more rigorous if one works in the formalism of nonstandard analysis (which among other things allows one to mathematically define the concept of “order of magnitude” in a completely rigorous fashion), but at your current level of understanding I recommend keeping these notions of scale as informal concepts rather than attempt to assign precise rigorous meaning to them.
25 October, 2020 at 8:33 am
Ruijun Lin
I also have no idea about how to use the Monotone convergence theorem to deduce the result? Should we construct a sequence of functions monotone in p, or use another method? Would you elaborate how is one supposed to use the monotone convergence theorem?
Thanks very much!
25 October, 2020 at 8:36 am
Ruijun Lin
Sorry I forgot to refer to the exercise. It is Exercise 4.
25 October, 2020 at 4:27 pm
Terence Tao
You can use the monotone convergence theorem to approximate by a bounded function with finite measure support, and reduce to verifying the claim for the latter classes of function; a further application of monotone convergence (or rounding arguments) can then be used to reduce to the case of simple functions with finite measure support, which can be checked by direct calculation. (It is also possible for this particular exercise to skip some of these steps and obtain a shorter ad hoc proof that avoids explicit mention of monotone convergence, but this technique of using convergence theorems to reduce to simpler classes of functions is broadly applicable.)
by a bounded function with finite measure support, and reduce to verifying the claim for the latter classes of function; a further application of monotone convergence (or rounding arguments) can then be used to reduce to the case of simple functions with finite measure support, which can be checked by direct calculation. (It is also possible for this particular exercise to skip some of these steps and obtain a shorter ad hoc proof that avoids explicit mention of monotone convergence, but this technique of using convergence theorems to reduce to simpler classes of functions is broadly applicable.)
25 October, 2020 at 7:01 pm
Ruijun Lin
Thank you! I succeed to verify the claim when is a simple function by direct calculation. Then I followed the simple approximation lemma which express a measurable function as a limit of a sequence of increasing simple functions
is a simple function by direct calculation. Then I followed the simple approximation lemma which express a measurable function as a limit of a sequence of increasing simple functions  , then I tried to use the monotone convergence theorem. But there is still a gap which I cannot fill it, and I think it is the key step: How to verify the two limits are interchangeable?
, then I tried to use the monotone convergence theorem. But there is still a gap which I cannot fill it, and I think it is the key step: How to verify the two limits are interchangeable?
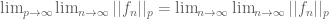
[As indicated in the preceding reply, this is easiest to establish in the special case when (and hence
(and hence 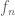 ) are bounded and have finite measure support, as Holder’s inequality will give enough quantitative continuity to interchange limits. A further approximation argument is then needed to recover the general case. -T]
) are bounded and have finite measure support, as Holder’s inequality will give enough quantitative continuity to interchange limits. A further approximation argument is then needed to recover the general case. -T]
25 October, 2020 at 7:03 pm
Ruijun Lin
Sorry, again one typo: the first “n” in the right-hand side should be “p”.
22 March, 2022 at 3:41 pm
Anonymous
as Holder’s inequality will give enough quantitative continuity to interchange limits.
I don’t understand why Holder’s inequality is needed or how it may be useful anywhere. Can you please elaborate?
If one has already established for a class of function so that
so that
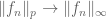 as
as  , and this class of function is such that it approximates
, and this class of function is such that it approximates  in
in  and also
and also 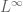 , then to pass to the limit to establish the result for
, then to pass to the limit to establish the result for  , one can use (can one?)
, one can use (can one?)
where the first and third terms are estimated by the approximation property of the class and the second term is controlled by the established result for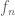 .
.
22 March, 2022 at 3:43 pm
J
It seems that the inequality above is too long to parse:

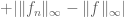
6 May, 2023 at 3:17 am
Vi
Dear Prof. Tao, where
where  necessarily have finite measure support (otherwise
necessarily have finite measure support (otherwise  would blow up?). Can you please clarify?
would blow up?). Can you please clarify?
Why do we need the special case of “finite measure support”. Shouldn’t any simple function
7 May, 2023 at 11:38 am
Anonymous
15 May, 2023 at 2:38 pm
Anonymous
Is the explanation above wrong?
27 October, 2020 at 6:39 am
Ruijun Lin
This problem is interesting and impressive to me.
Using Holder inequality for continuity (in which sense?) and interchanging limits seems novel to me, I tried again and again and still cannot figure it out. Any more hints or comments?
27 October, 2020 at 7:10 am
Ruijun Lin
Really eager to know the rigorous process dealing with the interchange of the limit ~
27 October, 2020 at 7:37 am
Ruijun Lin
It is very kind of you to spend no effort replying our doubts. Also, I think the changing of limits should use the condition . I think I may be exhausted, and discussed on this problem (Exercise 4) with many of my classmates but they still did not figure it out the key step of the feasibility of interchanging the limits.
. I think I may be exhausted, and discussed on this problem (Exercise 4) with many of my classmates but they still did not figure it out the key step of the feasibility of interchanging the limits.
Wish Mr. Tao to give a reply.
27 October, 2020 at 7:40 am
Ruijun Lin
Sorry, I mean “ “
“
22 March, 2022 at 3:34 pm
J
I am confused by the comment:
You can use the monotone convergence theorem to approximate f by a bounded function with finite measure support, and reduce to verifying the claim for the latter classes of function; a further application of monotone convergence (or rounding arguments) can then be used to reduce to the case of simple functions with finite measure support, which can be checked by direct calculation.
How can one first show that for all
for all  or sufficiently large
or sufficiently large  so that it makes sense to talk about the limit of
so that it makes sense to talk about the limit of
 as
as  ? Or one need not show this at all?
? Or one need not show this at all?
22 March, 2022 at 3:45 pm
J
Is this argument also applied to Part 2 of Exercise 4?
1 December, 2020 at 6:50 pm
Ruijun Lin
In the proof of Proposition 2, I think we should use the dominated convergence theorem instead of the monotone convergence theorem, since the monotone convergence does not guarantee the passing of the limit in the absolute function.
[One can use either, if one first works with non-negative functions – T.]
functions – T.]
16 April, 2021 at 12:10 am
How to show that $|f|_{L^p} to |f|_{L^infty}$ as $p to infty$ if $f in L^infty cap L^{p_0}$ for some $0 < p_0 < infty$? ~ Mathematics ~ mathubs.com
[…] This problem is from Terrence Tao’s blog: Exercise 4 […]
3 October, 2021 at 2:47 pm
How to understand "It takes a little bit of getting used to the idea..."? - English Vision
[…] The following sentence is from a mathematical lecture note here: […]
17 March, 2022 at 12:03 pm
J
Different structures are listed for the spaces at the beginning of the post.
spaces at the beginning of the post.
When you use the word “subspace” in various places of the post, e.g., Proposition 2, Exercise 7, are you assuming all the sub-structures in the list? Or just some of them, for instance, a “linear” subspace in the category of vector spaces?
17 March, 2022 at 1:07 pm
Terence Tao
By default, subspaces here refer to linear subspaces, and most of the structures listed (e.g., metric, topology, norm, inner product) are inherited by such linear subspaces in the usual fashion.
17 March, 2022 at 1:03 pm
J
In Exercise 4.2, which strategies in https://terrytao.wordpress.com/2010/10/21/245a-problem-solving-strategies/ can one use?
A density argument seems not possible due to the form of the statement. If one tries the contrapositive, and assume
 , then one wants to show that
, then one wants to show that  . This is easy for simple functions. How can one upgrade this to functions with finite measure support? In order to apply a density, one ends up with the need of assuming that
. This is easy for simple functions. How can one upgrade this to functions with finite measure support? In order to apply a density, one ends up with the need of assuming that  is finite if one wants to proceed with an estimate that works for Exercise 4.1 when "passing to the limit":
is finite if one wants to proceed with an estimate that works for Exercise 4.1 when "passing to the limit":

18 March, 2022 at 1:10 pm
J
In the proof of Theorem 1:
 is absolutely continuous with respect to
is absolutely continuous with respect to  .
.
… Finally, from (11) we also see that … , thus
Is the notion of “absolutely continuous” defined for “complex measures” yet somewhere in the previous sets of notes? It seems that this is where a “complex measure” is (implicitly) used the first time.
Without “complex measures”, this may be simply changed to
… *both the real and imaginary parts of* is absolutely continuous with respect to
is absolutely continuous with respect to  .
.
[Corrected, thanks – T.]
18 March, 2022 at 2:23 pm
J
In Remark 10, when Theorem 1 is used to deduce the Lebesgue-Radon-Nikodym theorem, can one consider as a functional on
as a functional on  with other values of
with other values of  ?
?
20 March, 2022 at 1:33 pm
Terence Tao
Well, since we are assuming finite measure, is a subspace of
is a subspace of  for
for 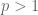 thanks to Holder’s inequality, so the answer to your question is “yes”. For instance in some texts the
thanks to Holder’s inequality, so the answer to your question is “yes”. For instance in some texts the  duality theorem of Riesz is used to establish the Radon-Nikodym theorem in this fashion (I believe Rudin does so, but this is from memory and I do not have a copy physically at hand to check this).
duality theorem of Riesz is used to establish the Radon-Nikodym theorem in this fashion (I believe Rudin does so, but this is from memory and I do not have a copy physically at hand to check this).
15 May, 2023 at 2:24 pm
YM
I think your remark 10 (which uses general $L^p$ duality?) essentially does the same thing that Rudin does (who also credits von Neumann)
21 July, 2022 at 10:58 am
Anonymous
Do all the inequalities about Lp-norms hold if one replaces big Lp by little lp-norm? It seems fine as Lp space includes lp space. But I would like to confirm.
[Yes; see Remark 2. -T]
8 January, 2023 at 6:39 am
Anonymous
You seem to use the label “Lemma 1” twice for two different theorems.
[Corrected, thanks – T.]
9 April, 2023 at 2:38 pm
Mayoorathy Vishagan
Dear Prof. Tao
I am not able to progress with part 5 of exercise . Should we show this first to simple functions and use some kind of convergence argument? Can you give a hint? thanks.
9 April, 2023 at 3:38 pm
Mayoorathy Vishagan
Sorry it is exercise1 part 4
14 May, 2023 at 4:59 am
Anonymous
For ex: 8, the statement “scalar multiple of the other” is only true when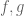 are non-negative right?
are non-negative right?
[Correction added, thanks – T.]
11 June, 2023 at 4:31 am
Anonymous
In theorem 1, to prove , I see for example how we can use the test function
, I see for example how we can use the test function  to prove the result along the same lines as you state.
to prove the result along the same lines as you state.
I am not however able to follow your line of thought “By taking real and imaginary parts we may assume without loss of generality that g is real ….”. Do you mean taking real & imaginary parts of $g$? How does that reduce it to the real and then positive case?
[One takes the real and imaginary parts of to obtain the real and imaginary parts of
to obtain the real and imaginary parts of 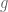 , then puts those parts back together to reconstruct the complex
, then puts those parts back together to reconstruct the complex 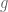 . -T]
. -T]
17 September, 2023 at 6:53 am
Anonymous
can you provide the solution to exercise 7a?
9 January, 2024 at 2:52 pm
Anonymous
In the definition of the infinity norm:
We say that a function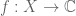 is essentially bounded if there exists an M such that
is essentially bounded if there exists an M such that 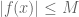 for almost every x, and define
for almost every x, and define  to be the least
to be the least  that serves as such a bound.
that serves as such a bound.
is there an example where one can only use the “infimum” (so that the “least” M does not exist) instead of the “minimum” of the ?
?
9 January, 2024 at 6:31 pm
Anonymous
By we mean the preimage of
we mean the preimage of  .
.
Every value larger than works as such a bound by assumption.
works as such a bound by assumption.  ,
,
Lastly, countable additivity implies
As easy as usual, serves as such a bound, be the least as well.
serves as such a bound, be the least as well.
10 January, 2024 at 11:02 am
Anonymous
If the least M doesn’t exist, then f is not essentially bounded.
10 January, 2024 at 6:10 pm
Anonymous
and .
.
Set .
.