
You are currently browsing the tag archive for the ‘Paul Erdos’ tag.
This post contains two unrelated announcements. Firstly, I would like to promote a useful list of resources for AI in Mathematics, that was initiated by Talia Ringer (with the crowdsourced assistance of many others) during the National Academies workshop on “AI in mathematical reasoning” last year. This list is now accepting new contributions, updates, or corrections; please feel free to submit them directly to the list (which I am helping Talia to edit). Incidentally, next week there will be a second followup webinar to the aforementioned workshop, building on the topics covered there. (The first webinar may be found here.)
Secondly, I would like to advertise the erdosproblems.com website, launched recently by Thomas Bloom. This is intended to be a living repository of the many mathematical problems proposed in various venues by Paul Erdős, who was particularly noted for his influential posing of such problems. For a tour of the site and an explanation of its purpose, I can recommend Thomas’s recent talk on this topic at a conference last week in honor of Timothy Gowers.
Thomas is currently issuing a call for help to develop the erdosproblems.com website in a number of ways (quoting directly from that page):
- You know Github and could set a suitable project up to allow people to contribute new problems (and corrections to old ones) to the database, and could help me maintain the Github project;
- You know things about web design and have suggestions for how this website could look or perform better;
- You know things about Python/Flask/HTML/SQL/whatever and want to help me code cool new features on the website;
- You know about accessibility and have an idea how I can make this website more accessible (to any group of people);
- You are a mathematician who has thought about some of the problems here and wants to write an expanded commentary for one of them, with lots of references, comparisons to other problems, and other miscellaneous insights (mathematician here is interpreted broadly, in that if you have thought about the problems on this site and are willing to write such a commentary you qualify);
- You knew Erdős and have any memories or personal correspondence concerning a particular problem;
- You have solved an Erdős problem and I’ll update the website accordingly (and apologies if you solved this problem some time ago);
- You have spotted a mistake, typo, or duplicate problem, or anything else that has confused you and I’ll correct things;
- You are a human being with an internet connection and want to volunteer a particular Erdős paper or problem list to go through and add new problems from (please let me know before you start, to avoid duplicate efforts);
- You have any other ideas or suggestions – there are probably lots of things I haven’t thought of, both in ways this site can be made better, and also what else could be done from this project. Please get in touch with any ideas!
I for instance contributed a problem to the site (#587) that Erdős himself gave to me personally (this was the topic of a somewhat well known photo of Paul and myself, and which he communicated again to be shortly afterwards on a postcard; links to both images can be found by following the above link). As it turns out, this particular problem was essentially solved in 2010 by Nguyen and Vu.
(Incidentally, I also spoke at the same conference that Thomas spoke at, on my recent work with Gowers, Green, and Manners; here is the video of my talk, and here are my slides.)
I have just uploaded to the arXiv my paper “The convergence of an alternating series of Erdős, assuming the Hardy–Littlewood prime tuples conjecture“. This paper concerns an old problem of Erdős concerning whether the alternating series 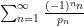

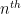
The alternating series test does not apply here because the ratios 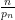
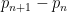

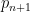
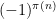
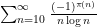
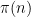
The prime tuples conjecture does not directly say much about the value of 
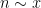
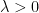




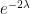


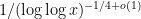
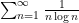
To get around this obstacle, we take advantage of the random sifted model 
![{[n, n+\lambda \log x]}](https://s0.wp.com/latex.php?latex=%7B%5Bn%2C+n%2B%5Clambda+%5Clog+x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[x,2x]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%2C2x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
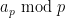

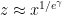

For this problem, the main advantage of working with the random sifted model, rather than with the primes or the singular series arising from the prime tuples conjecture, is that the sifted model can be studied iteratively from the partially sifted sets 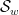
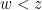


![{[n,n+\lambda \log x]}](https://s0.wp.com/latex.php?latex=%7B%5Bn%2Cn%2B%5Clambda+%5Clog+x%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


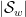
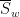


One of the basic problems in analytic number theory is to obtain bounds and asymptotics for sums of the form

in the limit 
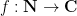
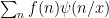
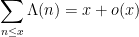
where 

It is thus of interest to develop techniques to estimate such sums 

At the easiest end of the spectrum are those functions 
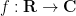

One can already get quite good bounds on this quantity by comparison with the integral 

with sharper bounds available by using tools such as the Euler-Maclaurin formula (see this blog post). Exponentiating such asymptotics, incidentally, leads to one of the standard proofs of Stirling’s formula (as discussed in this blog post).
One can also consider “non-Archimedean” notions of smoothness, such as periodicity relative to a small period 
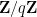

In particular, we have the fundamental estimate

This is a good estimate when 

One can also consider functions
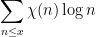
where 
Another class of functions that is reasonably well controlled are the multiplicative functions, in which 
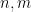

which are clearly related to the partial sums
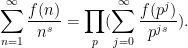
One also obtains similar types of representations for functions that are not quite multiplicative, but are closely related to multiplicative functions, such as the von Mangoldt function 
Moving another notch along the spectrum between well-controlled and ill-controlled functions, one can consider functions

for some other arithmetic function 

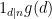

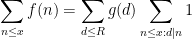
and thus by (1) one can bound this by the sum of a main term 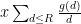
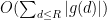

or expressions of the form

where each 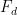

One of the simplest examples of this comes when estimating the divisor function

which counts the number of divisors up to



Here, we are (barely) able to keep the error term smaller than the main term; this is right at the edge of the divisor sum method, because the level

where 



From Dirichlet series methods, it is not difficult to establish the identities
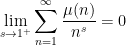
and

This suggests (but does not quite prove) that one has

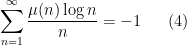
in the sense of conditionally convergent series. Assuming one can justify this (which, ultimately, requires one to exclude zeroes of the Riemann zeta function on the line 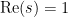
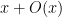
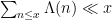

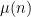
However, there are a number of tricks available to reduce the level of divisor sums. The simplest comes from exploiting the change of variables 
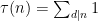


except when
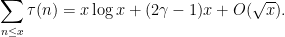
This type of argument is also known as the Dirichlet hyperbola method. A variant of this argument can also deduce the prime number theorem from (3), (4) (and with some additional effort, one can even drop the use of (4)); this is discussed at this previous blog post.
Using this square root trick, one can now also control divisor sums such as
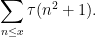
(Note that 
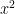

which one can rewrite as

The constraint 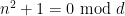

where 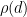
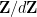
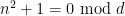

The function 

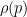



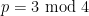

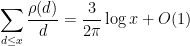
and also

and thus

Similar arguments give asymptotics for 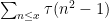



However, the square root trick is insufficient by itself to deal with higher order sums involving the divisor function, such as
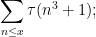
the level here is initially of order 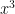

Nevertheless, there is an ingenious argument of Erdös that allows one to obtain good upper and lower bounds for these sorts of sums, in particular establishing the asymptotic
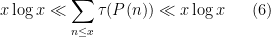
for any fixed irreducible non-constant polynomial 


for any fixed 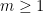

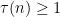

for any fixed
The lower bound in (6) is easy, since one can simply lower the level in (5) to obtain the lower bound

for any 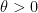

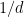
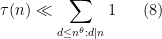
for any fixed 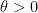

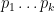
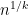

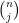
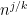


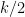
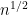
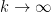
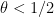
This however can be fixed in a number of ways. First of all, even when 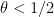

for some 

For Erdös’s upper bound (6), though, one cannot afford to lose these additional factors of 
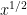

which, thanks to Mertens’ theorem
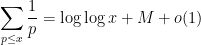
for some absolute constant 


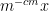
The Erdös argument is quite robust; for instance, the more general inequality

for fixed irreducible

which turn out to be enough to obtain the right asymptotics for the number of solutions to the equation 
Below the fold I will provide some more details of the arguments of Landreau and of Erdös.

Recent Comments