
You are currently browsing the tag archive for the ‘almost everywhere convergence’ tag.
This set of notes discusses aspects of one of the oldest questions in Fourier analysis, namely the nature of convergence of Fourier series.
If 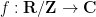
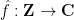
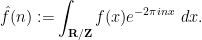
 is smooth, then the Fourier coefficients
is smooth, then the Fourier coefficients 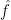 are absolutely summable, and we have the Fourier inversion formula
are absolutely summable, and we have the Fourier inversion formula 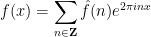
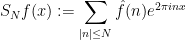
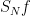 converges uniformly to when is smooth.
converges uniformly to when is smooth.
What if 
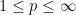

Exercise 1
- (i) If
and
, show that
.)
- (ii) If
or
, show that there exists
The question of pointwise almost everywhere convergence turned out to be a significantly harder problem:
Theorem 2 (Pointwise almost everywhere convergence)
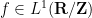 such that
such that  is unbounded in
is unbounded in  ,
,  for almost every
for almost every  and
and
Note from Hölder’s inequality that 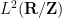
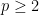
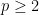
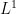
Carleson’s theorem in particular was a surprisingly difficult result, lying just out of reach of classical methods (as we shall see later, the result is much easier if we smooth either the function
Suppose one has a measure space 

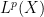
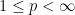



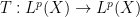

One standard way to proceed here is to study the maximal operator

and aim to establish a weak-type maximal inequality
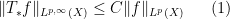
for all 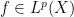

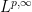


A standard approximation argument using (1) then shows that 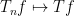
In the case of norm convergence (in which one asks for

for some 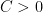
Returning to pointwise almost everywhere convergence, the answer in general is “yes”. Consider for instance the rank one operators
![\displaystyle T_n f(x) := 1_{[n,n+1]} \int_0^1 f(y)\ dy](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+T_n+f%28x%29+%3A%3D+1_%7B%5Bn%2Cn%2B1%5D%7D+%5Cint_0%5E1+f%28y%29%5C+dy&bg=ffffff&fg=000000&s=0&c=20201002)
from 

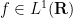
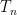
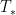
In spite of this, a remarkable observation of Stein, now known as Stein’s maximal principle, asserts that the maximal inequality is necessary to prove pointwise almost everywhere convergence, if one is working on a compact group and the operators 

Theorem 1 (Stein maximal principle) Let
be a compact group, let
, let
, and let
This is not quite the most general vesion of the principle; some additional variants and generalisations are given in the original paper of Stein. For instance, one can replace the discrete sequence 
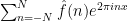

And unsurprisingly, most of the proofs of this (difficult) theorem have proceeded by first establishing (3), and Stein’s maximal principle strongly suggests that this is the optimal way to try to prove this theorem.
On the other hand, the theorem does fail for 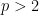
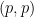
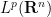



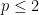
Stein’s principle is restricted to compact groups (such as the torus 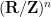
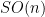
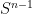

![{T_n f := f * 1_{[n,n+1]}}](https://s0.wp.com/latex.php?latex=%7BT_n+f+%3A%3D+f+%2A+1_%7B%5Bn%2Cn%2B1%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
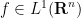
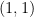
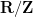
Stein’s argument from his 1961 paper can be viewed nowadays as an application of the probabilistic method; starting with a sequence of increasingly bad counterexamples to the maximal inequality (1), one randomly combines them together to create a single “infinitely bad” counterexample. To make this idea work, Stein employs two basic ideas:
- The random rotations (or random translations) trick. Given a subset
of
translates
of
- The random sums trick Given a collection
of signed functions that may possibly cancel each other in a deterministic sum
, one can perform a random sum
instead to obtain a random function whose magnitude will usually be comparable to the square function
; this can be made rigorous by concentration of measure results, such as Khintchine’s inequality.
These ideas have since been used repeatedly in harmonic analysis. For instance, I used the random rotations trick in a recent paper with Jordan Ellenberg and Richard Oberlin on Kakeya-type estimates in finite fields. The random sums trick is by now a standard tool to build various counterexamples to estimates (or to convergence results) in harmonic analysis, for instance being used by Fefferman in his famous paper disproving the boundedness of the ball multiplier on 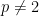

Another use of the random rotations trick, closely related to Theorem 1, is the Nikishin-Stein factorisation theorem. Here is Stein’s formulation of this theorem:
Theorem 2 (Stein factorisation theorem) Let
, and let
be a bounded linear operator commuting with translations and obeying the estimate
for all
. Then
, with
for all
depending only on
.


This result is trivial with 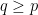
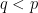
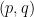


Stein’s factorisation theorem (or more precisely, a variant of it) is useful in the theory of Kakeya and restriction theorems in Euclidean space, as first observed by Bourgain.
In 1970, Nikishin obtained the following generalisation of Stein’s factorisation theorem in which the translation-invariance hypothesis can be dropped, at the cost of excluding a set of small measure:
Theorem 3 (Nikishin-Stein factorisation theorem) Let
for all
, there exists a subset
such that

 depending only on
depending only on  .
.One can recover Theorem 2 from Theorem 3 by an averaging argument to eliminate the exceptional set; we omit the details.
If one has a sequence 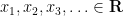
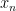
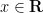

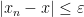
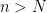
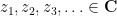
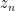
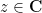
More generally, if one has a sequence 

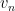

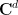

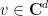

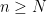
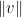



If however one has a sequence 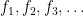
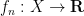



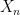
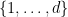
What different types of convergence are there? As an undergraduate, one learns of the following two basic modes of convergence:
- We say that
,
converges to
. In other words, for every
and
) such that
whenever
- We say that
for every
Uniform convergence implies pointwise convergence, but not conversely. A typical example: the functions 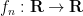

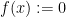
However, pointwise and uniform convergence are only two of dozens of many other modes of convergence that are of importance in analysis. We will not attempt to exhaustively enumerate these modes here (but see this Wikipedia page, and see also these 245B notes on strong and weak convergence). We will, however, discuss some of the modes of convergence that arise from measure theory, when the domain 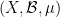
- We say that
- We say that
norm if, for every
- We say that
of measure
such that
- We say that
converges to
as
- We say that
converge to zero as
Observe that each of these five modes of convergence is unaffected if one modifies
Remark 1 In the context of probability theory, in which
Exercise 2 (Linearity of convergence) Let
be sequences of measurable functions, and let
be measurable functions.
- Show that
converges to
- If
converges to
along the same mode, show that
converges to
along the same mode, and that
converges to
along the same mode for any
.
- (Squeeze test) If
pointwise for each
We have some easy implications between modes:
Exercise 3 (Easy implications) Let
- If
- If
of
of
- If
- If
- If
- If
- If
The reader is encouraged to draw a diagram that summarises the logical implications between the seven modes of convergence that the above exercise describes.
We give four key examples that distinguish between these modes, in the case when
Example 4 (Escape to horizontal infinity) Let
. Then
Example 5 (Escape to width infinity) Let
. Then
Example 6 (Escape to vertical infinity) Let
. Then
Example 7 (Typewriter sequence) Let
whenever
and
. This is a sequence of indicator functions of intervals of decreasing length, marching across the unit interval
over and over again. Then
![\displaystyle f_n := 1_{[\frac{n-2^k}{2^k}, \frac{n-2^k+1}{2^k}]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++f_n+%3A%3D+1_%7B%5B%5Cfrac%7Bn-2%5Ek%7D%7B2%5Ek%7D%2C+%5Cfrac%7Bn-2%5Ek%2B1%7D%7B2%5Ek%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Remark 8 The
of a measurable function
that are essential upper bounds for
for almost every
as
One particular advantage of

as one sees from the triangle inequality. Unfortunately, none of the other modes of convergence automatically imply this convergence of the integral, as the above examples show.
The purpose of these notes is to compare these modes of convergence with each other. Unfortunately, the relationship between these modes is not particularly simple; unlike the situation with pointwise and uniform convergence, one cannot simply rank these modes in a linear order from strongest to weakest. This is ultimately because the different modes react in different ways to the three “escape to infinity” scenarios described above, as well as to the “typewriter” behaviour when a single set is “overwritten” many times. On the other hand, if one imposes some additional assumptions to shut down one or more of these escape to infinity scenarios, such as a finite measure hypothesis 

Recent Comments