
This month I am at MSRI, for the programs of Ergodic Theory and Additive Combinatorics, and Analysis on Singular Spaces, that are currently ongoing here. This week I am giving three lectures on the correspondence principle, and on finitary versions of ergodic theory, for the introductory workshop in the former program. The article here is broadly describing the content of these talks (which are slightly different in theme from that announced in the abstract, due to some recent developments). [These lectures were also recorded on video and should be available from the MSRI web site within a few months.]
My lectures are devoted to the correspondence principle between finite dynamical systems and infinite dynamical systems, that allows one to convert certain statements about the former to logically equivalent statements about the latter. (I will be vague here about what “dynamical system” means; very broadly, just about anything with a group action could qualify here.) A little more specifically, the correspondence principle equates four types of results, which we informally describe as follows:
- Local quantitative results for concrete finite systems.
- Local qualitative results for concrete infinite systems.
- Continuous quantitative results for abstract finite systems.
- Continuous qualitative results for abstract infinite systems.
(The meaning of these terms should become clearer once we give some specific examples.)
There are many contexts in which this principle shows up (e.g. in Ramsey theory, recurrence theory, graph theory, group theory, etc.) but the basic ingredients are always the same. Namely, the correspondence between Type 1 and Type 2 (or Type 3 and Type 4) arises from a weak sequential compactness property, which, roughly speaking asserts that given any sequence of (increasingly large) finite systems, there exists a subsequence of such systems which converges (in a suitably “weak” sense) to an infinite system. [We will define these terms more precisely in concrete situations later.] More informally, any “sufficiently large” finite system can be “approximated” in some weak sense by an infinite system. (One can make this informal statement more rigorous using nonstandard analysis and/or ultrafilters, but we will not take such an approach here.) Because of this, we obtain a correspondence principle: any qualitative statement about infinite systems (e.g. that a certain quantity is always strictly positive) is equivalent to a quantitative statement about sufficiently large finite systems (e.g. a certain quantity is always uniformly bounded from below). This principle forms a crucial bridge between finitary (or quantitative) mathematics and infinitary (or qualitative) mathematics; in particular, by taking advantage of this principle, tools from one type of mathematics can be used to prove results in the other. (See my previous post on soft analysis and hard analysis for further discussion.)
In addition to the use of compactness, the other key pillar of the correspondence principle is that of abstraction – the ability to generalise from a concrete system (on a very explicit space, e.g. the infinite cube 
We now turn to several specific examples of this principle in various contexts. We begin with the more “combinatorial” or “non-ergodic theoretical” instances of this principle, in which there is no underlying probability measure involved; these situations are simpler than the ergodic-theoretic ones, but already illustrate many of the key features of this principle in action.
1. The correspondence principle in Ramsey theory
We begin with the classical correspondence principle that connects Ramsey results about finite colourings, to Ramsey results about infinite colourings, or (equivalently) about the topological dynamics of covers of open sets. We illustrate this by demonstrating the equivalence of three statements. The first two are as follows:
Theorem 1. (van der Waerden theorem, Type 2 formulation) Suppose the integers are coloured by finitely many colours. Then there exist arbitrarily long monochromatic arithmetic progressions.
Theorem 2. (van der Waerden theorem, Type 1 formulation) For every c and k there exists N such that whenever
is coloured by c colours, there exists a monochromatic arithmetic progression of length k.
It is easy to see that Theorem 2 implies Theorem 1. Conversely, to deduce Theorem 2 from Theorem 1 we use the correspondence principle as follows. Assume for contradiction that Theorem 1 was true, but Theorem 2 was false. Untangling the quantifiers, this means that there exist positive integers k, c, a sequence 


By shifting the sets 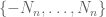
The above argument has all the basic ingredients of the correspondence principle in action: a proof by contradiction, use of weak compactness to extract an infinite limiting object, application of the infinitary result to that object, and checking that the conclusion of that result is sufficiently “finitary”, “local”, or “continuous” that it extends back to some of the finitary sequence, leading to the desired contradiction. [It is essential that one manages to reduce to purely local properties before passing from the converging sequence to the limit, or vice versa, since non-local properties are usually not preserved by the limit. For instance, consider the colouring of 
A key disadvantage of the use of the correspondence principle, though, is that it is quite difficult to extract specific quantitative bounds from any argument that uses this principle; for instance, while one can eventually “proof mine” the above argument (combined with some standard proof of Theorem 1) to eventually get a bound on N in terms of k and d, such a bound is extremely poor (of Ackermann function type).
Theorem 1 can be reformulated in a more abstract form:
Theorem 3. (van der Waerden theorem, Type 4 version) Let X be a compact space, let
be a homeomorphism, and let
be an open cover of X. Then for any k there exists a positive integer n and an open set
in the cover such that
is non-empty.
The deduction of Theorem 3 from Theorem 1 is easy, after using the compactness to refine the open cover to a finite subcover, picking a point 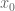

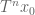


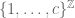

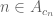
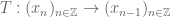
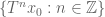


2. The correspondence principle for finitely generated groups
The combinatorial correspondence used above for colourings can also be applied to other situations, such as that of finitely generated groups. Recall that if G is a group generated by a finite set S, we say that G has polynomial growth if there exists constants K, d such that the ball 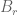
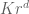
Theorem 4. (Gromov’s theorem on polynomial growth, Type 4 version) Let G be a finitely generated group of polynomial growth. Then G is virtually nilpotent (i.e. it has a finite index subgroup that is nilpotent).
As observed in Gromov’s original paper, this result is equivalent to a finitary version:
Theorem 5. (Gromov’s theorem on polynomial growth, Type 3) For every integers s, K, d, there exists R such that any finitely generated group with s generators, such that
, is virtually nilpotent.
It is clear that Theorem 5 implies Theorem 4; for the converse implication, we use the correspondence principle. We sketch the details as follows. First, we make things more concrete (i.e. move from Type 3 and Type 4 to Type 1 and Type 2 respectively) by observing that every group G on s generators can be viewed as a quotient 
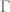
Suppose for contradiction that Theorem 5 failed in this concrete setting; then there exists s, K, d, a sequence 
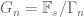



The next step, as before, is to exploit weak sequential compactness and extract a subsequence of groups 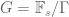

As volume growth is a local condition (involving only words of bounded length for any fixed r), we then easily conclude that G is of polynomial growth, and thus by Theorem 4 is virtually nilpotent. Some nilpotent algebra reveals that every virtually nilpotent group is finitely presented, so in particular there are a finite list of relations among the generators which guarantee this virtual nilpotency property. Such properties are local enough that they must then persist to groups
A slight modification of the above argument also reveals that the step and index of the nilpotent subgroup of G can be bounded by some constant depending only on K, d, s; this gives Theorem 5 meaningful content even when G is finite (in contrast to Theorem 4, which is trivial for finite groups). On the other hand, no explicit bound for this constant (or for R) in terms of s, K, d is currently known, though presumably some such bound can eventually be extracted from the above argument and the existing proofs of Gromov’s theorem by proof mining techniques.
3. The correspondence principle for dense sets of integers
Now we turn to the more “ergodic” variants of the correspondence principle, starting with the fundamental Furstenberg correspondence principle connecting combinatorial number theory with ergodic theory. We will illustrate this with the classic example of Szemerédi’s theorem.
There are many finitary versions of Szemerédi’s theorem. Here is one:
Theorem 6. (Szemerédi’s theorem, Type 1 version) Let
and
. Then there exists a positive integer
such that every subset A of
contains at least one k-term arithmetic progression.
The standard “Type 2” formulation of this theorem is the assertion that any subset of the integers of positive upper density has arbitrarily long arithmetic progressions. While this statement is indeed easily shown to be equivalent to Theorem 6, the Furstenberg correspondence principle instead connects this formulation to a rather different one, in which the deterministic infinite set is replaced by a random one. Recall that a random subset of integers 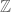
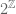

that involve only finitely many of the elements of A, are well-defined as numbers between 0 and 1. The Carathéodory extension theorem (combined with some topological properties of
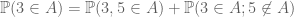
can be shown to give rise to a well-defined random set A.
We say that a random set A of integers is stationary if for every integer h, the shifted set A+h has the same probability distribution as A. In terms of cylinder events, this is equivalent to a collection of assertions such as

and so forth. One can then equate Theorem 6 with
Theorem 7. (Szemerédi’s theorem, Type 2 version) Let A be a stationary random infinite set of integers such that
(which, by stationarity, implies that
for all n), and let
It is not difficult to show that Theorem 6 implies Theorem 7. We briefly sketch the converse implication, which goes through the usual compactness-and-contradiction method. Suppose for contradiction that Theorem 7 is true, but Theorem 6 fails. Then we can find k and 


We now need to extract a stationary random infinite set A of integers as a limit of the deterministic finite sets 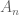
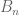






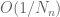

By using the same type of Arzelà-Ascoli argument as before, we can show that some subsequence of the random variables 

(To get from the cylinder probabilities back to a random variable, one uses the Carathéodory extension theorem. Weak convergence (or more precisely, weak-* convergence) of measures is also known as vague convergence, or convergence in distribution.)
Since the 


Much as Theorem 1 is equivalent to Theorem 4, Theorem 7 can be reformulated in a more abstract manner, known as the Furstenberg recurrence theorem:
Theorem 8. (Szemerédi’s theorem, Type 4 version) Let
be a probability space with a measure-preserving bimeasurable map
are measurable and measure-preserving), and let
have positive measure
. Then there exists
such that
.
We leave the equivalence of Theorem 8 with Theorems 6,7 as an exercise.
4. The correspondence principle for dense sets of integers II.
The deduction of Theorem 6 from Theorem 7, gives that the set A appearing in Theorem 6 has at least one k-term arithmetic progression, but if one inspects the argument more carefully, one sees that in fact one has a stronger statement that if N is large enough, there exists some 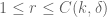


It is possible however to find even more progressions in the set A:
Theorem 8′. (Szemerédi’s theorem, Varnavides-type version) Let
and
such that for every
and every subset A of
k-term arithmetic progressions.
This can be obtained from Theorem 7 by repeating the derivation of Theorem 6 with two additional twists. Firstly, it is not difficult to modify the 



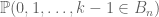

This type of argument was implicitly first introduced by Varnavides. Basically, this argument exploits the affine invariance (i.e. 
One can rephrase Theorem 8 in a quantitative ergodic formulation, essentially due to Bergelson, Host, McCutcheon, and Parreau:
Theorem 9. (Szemerédi’s theorem, Type 3 version) Let
such that for every measure-preserving system
and any measurable set A with
, we have
.
5. The correspondence principle for sparse sets of integers
It is possible to squeeze even more finitary results out of Theorem 7 than was done in the previous two sections. In particular, one has the following relative version of Szemerédi’s theorem:
Theorem 10. (Relative Szemerédi theorem) Let
contains one k-term arithmetic progression.
I did not define above what “sufficiently pseudorandom” meant as it is somewhat technical, but very roughly speaking it is a package of approximate independence conditions which include things like
![{\Bbb E}_{n,h,k \in [N]} \nu(n) \nu(n+h) \nu(n+k) \nu(n+h+k)=1+o(1)](https://s0.wp.com/latex.php?latex=%7B%5CBbb+E%7D_%7Bn%2Ch%2Ck+%5Cin+%5BN%5D%7D+%5Cnu%28n%29+%5Cnu%28n%2Bh%29+%5Cnu%28n%2Bk%29+%5Cnu%28n%2Bh%2Bk%29%3D1%2Bo%281%29&bg=ffffff&fg=545454&s=0&c=20201002)
where 
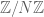
The point of Theorem 10 is that it allows one to detect arithmetic progressions inside quite sparse sets of integers (typically, R will have size about 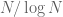
The derivation of Theorem 10 from Theorem 7 is discussed in this unpublished note of mine. We sketch the main ideas here. Once again, we argue by contradiction. If Theorem 10 failed, then one can find k and 

As before, it is not difficult to ensure 
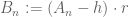


In the previous two sections, we looked at the (Borel) probability measure
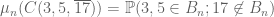
where 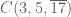


and also
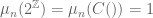
Conversely, any set of non-negative numbers obeying these properties will give a Borel probability measure, thanks to the Carathéodory extension theorem.
In the sparse case, this approach does not work, because 

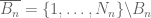



and similarly for other cylinder sets. Perhaps more suggestively, we have

where 

This gives us a non-negative number assigned to every cylinder set, but unfortunately these numbers do not obey the compatibility conditions required to make these numbers arise from a probability measure. However, if one assumes enough pseudorandomness conditions such as (1), one can show that the compatibility conditions are satisfied approximately, thus for instance

or equivalently

These conditions can be checked using a large number of applications of the Cauchy-Schwarz inequality, which we omit here. Thus,
6. The correspondence principle for graphs
In the previous three sections we considered the correspondence principle in the integers 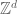


Theorem 11. (Triangle removal lemma, Type 3 version) For every
there exists
and
such that for any
be a graph on N vertices for some
triangles, one can remove at most
edges from the graph to make the graph triangle free.
We will not discuss why this theorem is of interest, other than to mention in passing that it actually implies the k=3 case of Szemerédi’s theorem. (See also my previous blog posts on related topics.) It turns out that this result can be deduced from some infinitary versions of this lemma. Here is one instance:
Theorem 12. (Triangle removal lemma, Type 2 version) Let G be a random graph on the integers
. Then there exists a continuous function F from the space
of graphs on
of graphs on
, which is equivariant with respect to permutations of
is surely (not just almost surely) a subgraph of G which is triangle free, and such that
.
Theorem 13. (Triangle removal lemma, Type 3 version) Let
be a probability space with a measure-preserving action of
be three measurable sets which are invariant under the stabiliser of
,
, and
respectively. Suppose that
has measure zero. Then one can find subsets
respectively of
is empty (and not just measure zero).
The proofs that Theorem 12 and Theorem 13 imply Theorem 11 are somewhat technical, but in the same spirit as the previous applications of the correspondence principle; see this paper (or these blog posts) and this paper respectively for details. In fact they prove slightly stronger statements than Theorem 11, in that they give a bit more information as to how the triangle-free graph G’ is obtained from the nearly triangle-free graph G. The same methods also apply to hypergraphs without much further difficulty, as is done in the above papers, but we will not discuss the details here.
7. The correspondence principle over finite fields
The correspondence principle can also be applied quite effectively to the finite field setting, which is a dyadic model for the integer setting. In particular, Tamar Ziegler and I have very recently shown the equivalence of the following two results:
Theorem 14. (Inverse Gowers conjecture for finite fields, Type 1 version) Let F be a finite field, let
be a function on some vector space
bounded in magnitude by 1, and such that the Gowers norm
is larger than
. Then there exists a function
which is a phase polynomial of degree at most k in the sense that
for all
(or equivalently, that
), such that we have the correlation
for some
independent of n.
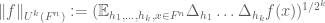
Theorem 15. (Inverse Gowers conjecture for finite fields, Type 4 version) Let
be a probability space, let F be a finite field, and let
be a measure-preserving action of the infinite group
. Let
be such that the Gowers-Host-Kra seminorm
is positive, where
. Then there exists
which is a phase polynomial in the sense that
a.e., and which correlates with f in the sense that
.

In a forthcoming paper of Bergelson, Ziegler, and myself (which I hope to discuss here on this blog in the near future), Theorem 15 was established, which by the correspondence principle alluded to above, implies Theorem 14. (See my previous blog post for some discussion of Theorem 14, which had been conjectured for a few years. Interestingly, this result also holds in the low characteristic case, for which (as discussed in that post) the conjecture was believed to fail. The issue here is a little subtle: counterexamples are known if the phase polynomial 
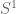
I will try to discuss these things in more detail in a later post, but very roughly speaking the reason why the correspondence principle is more effective here than on the integers is because the vector space 
8. The correspondence principle for convergence of ergodic averages
My final instance of the correspondence principle goes in the opposite direction from previous instances. In the preceding seven instances, the interesting aspect of the principle was that one could use a qualitative result about infinite systems to deduce a quantitative result about finite systems. Here, we will do the reverse: we show how a result about infinite systems can be deduced from one from a finite system. We will illustrate this with a very simple result from ergodic theory, the mean ergodic theorem:
Theorem 16 (Mean ergodic theorem, Type 4 version) Let
. Let
be the averaging operators
. Then
is a convergent sequence in
as
.
This is of course a well-known result with many short and elegant proofs; the proof method that we sketch here (essentially due to Avigad, Gerhardy, and Towsner) is lengthier and messier than the purely infinitary proofs, but can be extended to some situations in which it had been difficult to proceed in an infinitary manner (in particular on my result on convergence for multiple commuting transformations, as discussed in this post of mine).
The basic problem with finitising this theorem is that there is no uniform rate of convergence in the mean ergodic theorem: given any 
The resolution is in fact very similar to that discussed in the above-mentioned post. Observe that if 
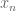
For every 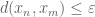
which is in turn equivalent to
For every 
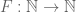



The point here is that once the function F is selected, one only has to verify the closeness of a single pair of elements in the sequence, rather than infinitely many. This makes it easier to finitise the convergence statement effectively. Indeed, Theorem 16 is easily seen (by another compactness and contradiction argument) to be equivalent to
Theorem 17 (Mean ergodic theorem, Type 3 version) For every
, we have
for some
.
Note that this theorem is quantitative in the sense that N depends only on 

33 comments
Comments feed for this article
31 August, 2008 at 9:25 am
gowers
Terry, that’s great news and I look forward to hearing more about it. For now, let me say congratulations and also make the stupid remark that you seem to have forgotten a “latex” in your statement of Theorem 15.
There’s a sort of intermediate reformulation of Szemeredi’s theorem that I like (and that you of course know well), which serves a bridge between the finitary statement and the ergodic one. It’s that if is a function on
is a function on 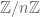 that takes values in
that takes values in ![{}[0,1]](https://s0.wp.com/latex.php?latex=%7B%7D%5B0%2C1%5D&bg=ffffff&fg=545454&s=0&c=20201002) and has average
and has average 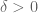 then there’s a constant
then there’s a constant  that depends on
that depends on  only such that the average value of
only such that the average value of  is bounded below by
is bounded below by  . It’s easily seen to be equivalent to the Varnavides version and I find it the most natural one to think about from an analytic-but-finite point of view.
. It’s easily seen to be equivalent to the Varnavides version and I find it the most natural one to think about from an analytic-but-finite point of view.
31 August, 2008 at 8:56 pm
Anthony Quas
Theorem 12 should include something about the triangle-freeness of the graph, right?
31 August, 2008 at 9:44 pm
Terence Tao
Dear Tim and Anthony: thanks for the corrections! Tim, you are of course right that the finitary versions of Szemeredi’s theorem are best phrased using functions instead of sets (and the infinitary versions can be formulated that way also), but the correspondence principle is a little bit trickier to pull off in that setting (though not by too much) so I avoided it in my lectures.
1 September, 2008 at 2:55 am
Sean
Here are some possible typos: is not typesetting.
is not typesetting.
– In the ‘approximate independence conditions’ stated after Theorem 10, the definition of
– Should the G’ in Theorem 12 equal F(G)?
1 September, 2008 at 8:29 am
Terence Tao
Dear Sean: thanks for the corrections!
1 September, 2008 at 9:36 am
Indian
REQUEST
Dear Prof Terence Tao, I was waiting for a reply to this query , I surmise you might have overlooked this query, it’s an important query that plays a pivotal role in solving intricate problems.
QUERY
Hello Mr Tao, I would like to know if imagination plays a comprehensive role in solving intricate problems, if so do you possess vivid powers of imagination? How do you approach a convoluted problem? Do you apply “Imagination” , other “tricks” ,etc, in arriving at a solution, please answer this query, I thank you in advance.
Prof Terence Tao, I humbly request you to answer this query, I am requesting you, please, I will be grateful to you, i apologize for posting this query over here, I thank you.
2 September, 2008 at 9:30 am
Terence Tao
Dear Indian,
I think each mathematician has his or her own way to make progress, but I personally do not think of myself as particularly imaginative, and in fact imagination does not play much of a role in my own mathematics; to me, other attributes, such as having insight, intuition, knowledge, clarity of thought, concentration, appreciation of the “big picture”, and immersion in a problem, are significantly more important. While one does of course have to come up with new ideas (as well as applying, refining, clarifying, or modifying existing technology, of course) when solving any genuinely non-trivial problem, I find that such ideas tend to be found naturally – without the need for any wildly creative or imaginative leap of faith – after one has thought about the problem long enough, isolated the main difficulties, found the key test cases or model problems, understood the key counterexamples, grasped the strengths and weaknesses of existing methods, and so forth. Such new ideas may appear to come “out of the blue” to outside observers who have not spent quite as much time being immersed in the problem, but they are usually in fact closely connected to the context that one is working in.
It does happen from time to time that a truly original idea causes an important breakthrough in a field, but in the majority of cases (particularly in mature fields), mathematical progress is usually based primarily on existing technology, and to organic refinements and modifications to that technology, as these are, after all, tried and tested ideas that are proven to work. Most new ideas in fact end up not being particularly effective, especially if they are not guided by the existing body of results, intuition, heuristics, etc., although often the reason for the failure of these ideas tends to be rather instructive.
3 September, 2008 at 6:12 am
philipp
dear prof. tao,
right at the end of 1. it should be “Theorem 3 implies Theorem 1” and not vice versa.
best regards,
philipp
5 September, 2008 at 7:49 pm
Terence Tao
Dear philipp: thanks for the correction.
5 September, 2008 at 8:53 pm
Anonymous
Dr. Tao,
I’m a bit confused about how your new result on the inverse Gower’s conjecture reconciles with the previously discussed “counterexample.” Did the formulation of the statement change in low characteristic, or is the counterexample, in fact, not a counterexample?
8 September, 2008 at 9:40 am
Terence Tao
Dear anonymous:
It turns out that there are two formulations of the Gowers inverse conjecture in finite fields, one in which polynomials are constrained to lie in p^th roots of unity, and the other in which polynomials are allowed to range freely in the unit circle. For high characteristic (p >= k) some simple algebra shows that the two formulations are equivalent. But in low characteristic, there exist polynomials that do not take values in p^th roots of unity (even after multiplying by constants). For instance, the function that maps 0 to 1 and 1 to i is a quadratic phase polynomial from F_2 to S^1 which does not take values in the second roots of unity {-1,1}.
The first formulation of the Gowers inverse conjecture fails in low characteristic, but our result (which we are still checking and polishing, but should be ready for uploading soon) shows that the second formulation continues to hold in this case.
1 November, 2008 at 11:05 am
The inverse conjecture for the Gowers norm over finite fields via the correspondence principle « What’s new
[…] principle“, submitted to Analysis & PDE. As announced a few months ago in this blog post, this paper establishes (most of) the inverse conjecture for the Gowers norm from an ergodic theory […]
7 March, 2009 at 9:34 am
Infinite fields, finite fields, and the Ax-Grothendieck theorem « What’s new
[…] correspondence Serre discusses is slightly different from the one I discuss for instance in here or here, although there seems to be a common theme of “compactness” (or of model theory) tying […]
10 April, 2009 at 9:24 pm
The completeness and compactness theorems of first-order logic « What’s new
[…] as the elementary limits of sequences of finite fields. I recently discovered that other several correspondence principles between finitary and infinitary objects, such as the Furstenberg correspondence principle between […]
8 May, 2009 at 8:14 pm
Szemeredi’s regularity lemma via the correspondence principle « What’s new
[…] through a graph-theoretic version of the Furstenberg correspondence principle (mentioned briefly in this earlier post of mine). While this approach superficially looks quite different from the combinatorial approach, it in […]
22 August, 2009 at 11:50 am
GILA 1: van der Waerden and all that « Portrait of the Mathematician
[…] be seen to be equivalent to the infinitary version stated earlier in the post, by what Terry Tao calls the Arzela-Ascoli trick. The key is to proceed by induction on k; fix some k and assume the theorem […]
23 October, 2009 at 11:46 am
A finitary version of Gromov’s polynomial growth theorem « What’s new
[…] subgroup of , and the step of that subgroup). However, a compactness argument (sketched in this previous blog post) shows that some such relationship must exist; indeed, if one has (1) for all for some […]
14 December, 2009 at 3:38 pm
Approximate bases, sunflowers, and nonstandard analysis « What’s new
[…] theorems to each other without a significant increase in effort. (This is closely related to various correspondence principles between combinatorics and parts of infinitary mathematics, such as ergodic theory; see also my post […]
30 January, 2010 at 7:07 pm
Ultralimit analysis, and quantitative algebraic geometry « What’s new
[…] analysis, ultrafilters, ultralimit analysis | by Terence Tao I have blogged a number of times in the past about the relationship between finitary (or “hard”, or […]
10 February, 2010 at 10:56 pm
245A, Notes 5: Free probability « What’s new
[…] up in the application of ergodic theory to combinatorics via the correspondence principle; see this previous blog post for further […]
19 March, 2010 at 9:53 pm
A computational perspective on set theory « What’s new
[…] only finitely many points or numbers, etc.); I have explored this theme in a number of previous blog posts. So, one may ask: what is the finitary analogue of statements such as Cantor’s theorem […]
27 November, 2010 at 12:07 am
Nonstandard analysis as a completion of standard analysis « What’s new
[…] theorem for ultrapowers to establish various versions of the correspondence principle, as discussed previously on this blog. A simple example occurs when demonstrating the equivalence of colouring theorems, […]
23 January, 2011 at 7:13 am
The Peter-Weyl theorem, and non-abelian Fourier analysis on compact groups « What’s new
[…] a crucial role in Gromov’s proof of his theorem on groups of polynomial growth (discussed previously on this blog), and in a more recent paper of Hrushovski on approximate groups (also discussed […]
30 January, 2011 at 8:59 pm
A topological proof of Van der Waerden’s Theorem | YAMB
[…] 2. We now present a standard compactness argument, explored in great detail by Terence Tao in his blog, to derive the other […]
8 July, 2012 at 8:48 am
Rex
In the statement of Theorem 8′, I assume you want to add that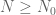
[Corrected, thanks – T.]
27 March, 2013 at 7:33 pm
An informal version of the Furstenberg correspondence principle | What's new
[…] the string , and leads to the Furstenberg correspondence principle, discussed for instance in these previous blog posts. Such principles allow one to rigorously pass back and forth between the combinatorics […]
5 March, 2017 at 10:38 am
Furstenberg limits of the Liouville function | What's new
[…] correspondence principle is discussed in these previous blog posts. One way to establish the principle is by introducing a Banach limit that extends the usual limit […]
9 May, 2018 at 12:51 pm
ahartel
I have a question regarding the proof that Theorem 1 implies Theorem 2. I’m not sure if anybody will read my question at all given the fact that this post is almost 10 years old, but I’ll try anyway.
But let me first express my gratitude to you for writing this blog and for exposing so much of your mathematical thinking. I think you serve the discipline invaluably in writing this blog and being so open with your ideas.
But back to my question: While thinking about the proof that the infinitary vdW impies the finitary vdW (Theorem 2) I was wondering if the diagonalization trick is even necessary. After all, we’re interested in a finite section of the “limit coloring” of all integers, a finite section that only just contains our k-term AP. Now we want to make sure that there also exist finite colorings with the same colors in that section in order to complete the contradiction.
So in order to construct the “pre-infinite” coloring with the k-term AP we might start by picking a subsequence along one position (say 17). We then proceed along all positions of our finite section and get “thinner and thinner” subsequences for the other positions. Since we only “thin out” finitely often we should be fine and end up with stable colors (for some N) all along the section. Contradiction complete, proof complete. So I don’t understand why we need to add finitely many elements to each sub-sub-sequence by picking the diagonalized subsequence globally. I would be very thankfull if someone could help me improve my understanding.
10 May, 2018 at 5:00 pm
Terence Tao
I’m not sure I follow your argument – it would help if you would give names to all the colorings etc. you are discussing – but one can’t apply the infinitary van der Waerden theorem unless one has an infinite coloring; merely being able to color a finite portion of the integers doesn’t immediately yield any conclusion. (One could add dummy colors to all the integers outside this finite portion, but then the monochromatic AP provided by the infinitary van der Waerden theorem might reside partially or fully in the dummy region, and again one does not obtain any useful conclusion.)
13 May, 2018 at 11:27 am
ahartel
Thank you for taking the time to read and answer my question. Your reply was very helpful indeed. Of course you can only apply Thm. 1 once you’ve obtained a coloring of all the integers.
And also, next time I’ll try to be more precise in naming my objects.
14 May, 2018 at 12:52 pm
Finitary versions of theorems – Write down what you’ve done
[…] https://terrytao.wordpress.com/2008/08/30/the-correspondence-principle-and-finitary-ergodic-theory/ […]
14 June, 2019 at 2:34 pm
Abstracting induction on scales arguments | What's new
[…] In this post I would like to observe that one can clean up and made more systematic this final step (iii) by passing to upper exponents (12) to eliminate the role of the parameter (and also “tropicalising” all the estimates), and then taking similar limit superiors to eliminate some other less important parameters, until one is left with a simple linear programming problem (which, among other things, could be amenable to computer-assisted proving techniques). This method is analogous to that of passing to a simpler asymptotic limit object in many other areas of mathematics (for instance using the Furstenberg correspondence principle to pass from a combinatorial problem to an ergodic theory problem, as discussed in this previous post). […]
3 June, 2020 at 4:07 pm
247B, Notes 4: almost everywhere convergence of Fourier series | What's new
[…] correspondence Serre discusses is slightly different from the one I discuss for instance in here or here, although there seems to be a common theme of “compactness” (or of model theory) tying […]