
You are currently browsing the tag archive for the ‘large deviation inequality’ tag.
I have uploaded to the arXiv my paper “Exploring the toolkit of Jean Bourgain“. This is one of a collection of papers to be published in the Bulletin of the American Mathematical Society describing aspects of the work of Jean Bourgain; other contributors to this collection include Keith Ball, Ciprian Demeter, and Carlos Kenig. Because the other contributors will be covering specific areas of Jean’s work in some detail, I decided to take a non-overlapping tack, and focus instead on some basic tools of Jean that he frequently used across many of the fields he contributed to. Jean had a surprising number of these “basic tools” that he wielded with great dexterity, and in this paper I focus on just a few of them:
- Reducing qualitative analysis results (e.g., convergence theorems or dimension bounds) to quantitative analysis estimates (e.g., variational inequalities or maximal function estimates).
- Using dyadic pigeonholing to locate good scales to work in or to apply truncations.
- Using random translations to amplify small sets (low density) into large sets (positive density).
- Combining large deviation inequalities with metric entropy bounds to control suprema of various random processes.
Each of these techniques is individually not too difficult to explain, and were certainly employed on occasion by various mathematicians prior to Bourgain’s work; but Jean had internalized them to the point where he would instinctively use them as soon as they became relevant to a given problem at hand. I illustrate this at the end of the paper with an exposition of one particular result of Jean, on the Erdős similarity problem, in which his main result (that any sum 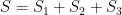

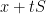

I had initially intended to also cover some other basic tools in Jean’s toolkit, such as the uncertainty principle and the use of probabilistic decoupling, but was having trouble keeping the paper coherent with such a broad focus (certainly I could not identify a single paper of Jean’s that employed all of these tools at once). I hope though that the examples given in the paper gives some reasonable impression of Jean’s research style.
In the previous set of notes we established the central limit theorem, which we formulate here as follows:
Theorem 1 (Central limit theorem) Let
be iid copies of a real random variable
of mean
and variance
, and write
. Then, for any fixed
, we have

 .
.This is however not the end of the matter; there are many variants, refinements, and generalisations of the central limit theorem, and the purpose of this set of notes is to present a small sample of these variants.
First of all, the above theorem does not quantify the rate of convergence in (1). We have already addressed this issue to some extent with the Berry-Esséen theorem, which roughly speaking gives a convergence rate of 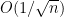

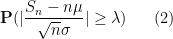
in the setting where 

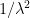
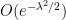
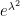
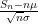
In the other direction, we can also look at the fine scale behaviour of the sums 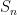

where 


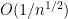
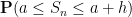


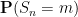
We also discuss other limit theorems in which the limiting distribution is something other than the normal distribution. Perhaps the most common example of these theorems is the Poisson limit theorems, in which one sums a large number of indicator variables (or approximate indicator variables), each of which is rarely non-zero, but which collectively add up to a random variable of medium-sized mean. In this case, it turns out that the limiting distribution should be a Poisson random variable; this again is an easy application of the Fourier method. Finally, we briefly discuss limit theorems for other stable laws than the normal distribution, which are suitable for summing random variables of infinite variance, such as the Cauchy distribution.
Finally, we mention a very important class of generalisations to the CLT (and to the variants of the CLT discussed in this post), in which the hypothesis of joint independence between the variables 
In the theory of discrete random matrices (e.g. matrices whose entries are random signs 
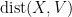
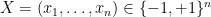
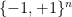



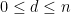
It is not hard to compute the second moment of this random variable. Indeed, if 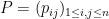
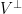

and so upon taking expectations we see that

since 

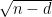
In fact, one has sharp concentration around this value, in the sense that 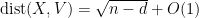
Proposition 1 (Large deviation inequality) For any
, one has
for some absolute constants
.
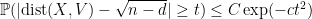
In fact the constants 

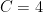
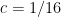
Proposition 1 is an easy consequence of the second moment computation and Talagrand’s inequality, which among other things provides a sharp concentration result for convex Lipschitz functions on the cube 

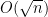
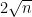


Remark 1 If one makes the coordinates of
rather than random signs, then Proposition 1 is much easier to prove; the probability distribution of a Gaussian vector is rotation-invariant, so one can rotate
, at which point
is clearly the sum of

Recent Comments