
You are currently browsing the tag archive for the ‘correspondence principle’ tag.
Joni Teräväinen and I have just uploaded to the arXiv our paper “The structure of logarithmically averaged correlations of multiplicative functions, with applications to the Chowla and Elliott conjectures“, submitted to Duke Mathematical Journal. This paper builds upon my previous paper in which I introduced an “entropy decrement method” to prove the two-point (logarithmically averaged) cases of the Chowla and Elliott conjectures. A bit more specifically, I showed that

whenever 
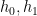
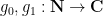

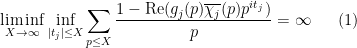
for all Dirichlet characters 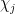
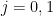

for fixed any non-zero 

One would certainly like to extend these results to higher order correlations than the two-point correlations. This looks to be difficult (though perhaps not completely impossible if one allows for logarithmic averaging): in a previous paper I showed that achieving this in the context of the Liouville function would be equivalent to resolving the logarithmically averaged Sarnak conjecture, as well as establishing logarithmically averaged local Gowers uniformity of the Liouville function. However, in this paper we are able to avoid having to resolve these difficult conjectures to obtain partial results towards the (logarithmically averaged) Chowla and Elliott conjecture. For the Chowla conjecture, we can obtain all odd order correlations, in that

for all odd 
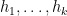

For the more general Elliott conjecture, we can show that

for any 
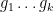

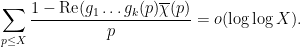
This can be seen to imply (2) as a special case. Even when
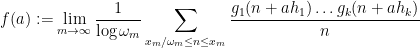
exist for each 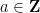


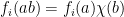




Among other things, this allows us to show that all 
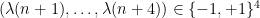

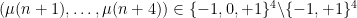
To describe the argument, let us focus for simplicity on the case of the Liouville correlations
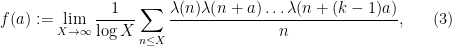
assuming for sake of discussion that all limits exist. (In the paper, we instead use the device of generalised limits, as discussed in this previous post.) The idea is to combine together two rather different ways to control this function 



Making the change of variables 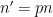
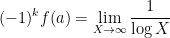

The difference between 
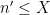
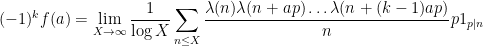
and thus by (3) we have

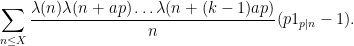
The entropy decrement argument can be used to show that the latter limit is small for most 

for most
On the other hand, by the Furstenberg correspondence principle (as discussed in these previous posts), it is possible to express
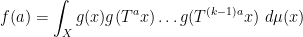
for some probability space 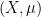
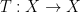
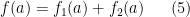
where 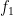


Ignoring the small error 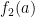
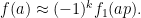
Using the equidistribution theory of nilsequences (as developed in this previous paper of Ben Green and myself), one can break up 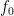
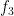
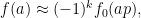
which already shows (heuristically, at least) the claim that
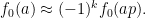
But if
The same sort of argument works to give the more general bounds on correlations of bounded multiplicative functions. But for the specific task of proving (2), we initially used a slightly different argument that avoids using the ergodic theory machinery of Bergelson-Host-Kra, Leibman, and Le, but replaces it instead with the Gowers uniformity norm theory used to count linear equations in primes. Basically, by averaging (4) in 
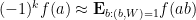
where 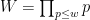

for most semiprimes 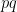

For 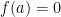
Given a function 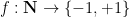



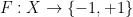
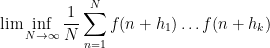


for any integers

whenever the limit on the right-hand side exists. We will refer to the system 




The correspondence principle is discussed in these previous blog posts. One way to establish the principle is by introducing a Banach limit 
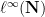

for all 

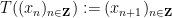
with the function
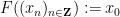
(so in particular 




for any distinct integers 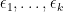
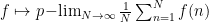
One can obtain a slightly tighter correspondence by using a smoother average than the Césaro average. For instance, one can use the logarithmic Césaro averages 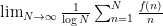
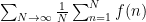


Whenever the Césaro average of a bounded sequence 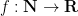

whenever the limit of the right-hand side exists.
In a recent paper of Frantizinakis, the Furstenberg limits of the Liouville function

In terms of Furstenberg limits of the Liouville function, this assertion is equivalent to the assertion that
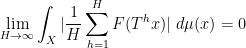
for all Furstenberg limits 



for all distinct integers 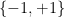

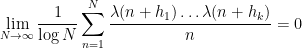
is equivalent to the assertion that all the Furstenberg limits of Liouville with logarithmic averaging are equivalent to the Bernoulli system. Recently, I was able to prove the two-point version

of the logarithmically averaged Chowla conjecture, for any non-zero integer

for any Furstenberg limit of Liouville with logarithmic averaging, and any 
The situation is more delicate with regards to the Sarnak conjecture, which is equivalent to the assertion that

for any zero-entropy sequence

as I was able to show that this conjecture was equivalent to the logarithmically averaged Chowla conjecture, and hence to all Furstenberg limits of Liouville with logarithmic averaging being Bernoulli; I also showed the conjecture was equivalent to local Gowers uniformity of the Liouville function, which is in turn equivalent to the function
Actually, the logarithmically averaged Furstenberg limits have more structure than just a 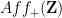

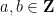
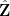
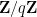
Proposition 1 (Enriched logarithmically averaged Furstenberg limit of Liouville) Let
be a Banach limit. Then there exists a probability space
of the affine semigroup
, with the following properties:
- (i) (Affine Furstenberg limit) For any
, and any congruence class
, one has
- (ii) (Equivariance of
) For any
, one has
for
.
- (iii) (Multiplicativity at fixed primes) For any prime
for
is the dilation map
.
- (iv) (Measure pushforward) If
and
is the set
, then the pushforward
of
is equal to
, that is to say one has
for every measurable
.





Note that 
The observable 

(This is an extended blog post version of my talk “Ultraproducts as a Bridge Between Discrete and Continuous Analysis” that I gave at the Simons institute for the theory of computing at the workshop “Neo-Classical methods in discrete analysis“. Some of the material here is drawn from previous blog posts, notably “Ultraproducts as a bridge between hard analysis and soft analysis” and “Ultralimit analysis and quantitative algebraic geometry“‘. The text here has substantially more details than the talk; one may wish to skip all of the proofs given here to obtain a closer approximation to the original talk.)
Discrete analysis, of course, is primarily interested in the study of discrete (or “finitary”) mathematical objects: integers, rational numbers (which can be viewed as ratios of integers), finite sets, finite graphs, finite or discrete metric spaces, and so forth. However, many powerful tools in mathematics (e.g. ergodic theory, measure theory, topological group theory, algebraic geometry, spectral theory, etc.) work best when applied to continuous (or “infinitary”) mathematical objects: real or complex numbers, manifolds, algebraic varieties, continuous topological or metric spaces, etc. In order to apply results and ideas from continuous mathematics to discrete settings, there are basically two approaches. One is to directly discretise the arguments used in continuous mathematics, which often requires one to keep careful track of all the bounds on various quantities of interest, particularly with regard to various error terms arising from discretisation which would otherwise have been negligible in the continuous setting. The other is to construct continuous objects as limits of sequences of discrete objects of interest, so that results from continuous mathematics may be applied (often as a “black box”) to the continuous limit, which then can be used to deduce consequences for the original discrete objects which are quantitative (though often ineffectively so). The latter approach is the focus of this current talk.
The following table gives some examples of a discrete theory and its continuous counterpart, together with a limiting procedure that might be used to pass from the former to the latter:
| (Discrete) | (Continuous) | (Limit method) |
| Ramsey theory | Topological dynamics | Compactness |
| Density Ramsey theory | Ergodic theory | Furstenberg correspondence principle |
| Graph/hypergraph regularity | Measure theory | Graph limits |
| Polynomial regularity | Linear algebra | Ultralimits |
| Structural decompositions | Hilbert space geometry | Ultralimits |
| Fourier analysis | Spectral theory | Direct and inverse limits |
| Quantitative algebraic geometry | Algebraic geometry | Schemes |
| Discrete metric spaces | Continuous metric spaces | Gromov-Hausdorff limits |
| Approximate group theory | Topological group theory | Model theory |
As the above table illustrates, there are a variety of different ways to form a limiting continuous object. Roughly speaking, one can divide limits into three categories:
- Topological and metric limits. These notions of limits are commonly used by analysts. Here, one starts with a sequence (or perhaps a net) of objects
in a common space
, which remains in the same space, and is “close” to many of the original objects
- Categorical limits. These notions of limits are commonly used by algebraists. Here, one starts with a sequence (or more generally, a diagram) of objects
or the inverse limit
of these objects, which is another object in the same category
- Logical limits. These notions of limits are commonly used by model theorists. Here, one starts with a sequence of objects
or of spaces
, each of which is (a component of) a model for given (first-order) mathematical language (e.g. if one is working in the language of groups,
or a new space
, which is still a model of the same language (e.g. if the spaces
.)
The purpose of this talk is to highlight the third type of limit, and specifically the ultraproduct construction, as being a “universal” limiting procedure that can be used to replace most of the limits previously mentioned. Unlike the topological or metric limits, one does not need the original objects
With so few requirements on the objects
Ultraproducts are not the only logical limit in the model theorist’s toolbox, but they are one of the simplest to set up and use, and already suffice for many of the applications of logical limits outside of model theory. In this post, I will set out the basic theory of these ultraproducts, and illustrate how they can be used to pass between discrete and continuous theories in each of the examples listed in the above table.
Apart from the initial “one-time cost” of setting up the ultraproduct machinery, the main loss one incurs when using ultraproduct methods is that it becomes very difficult to extract explicit quantitative bounds from results that are proven by transferring qualitative continuous results to the discrete setting via ultraproducts. However, in many cases (particularly those involving regularity-type lemmas) the bounds are already of tower-exponential type or worse, and there is arguably not much to be lost by abandoning the explicit quantitative bounds altogether.
Tamar Ziegler and I have just uploaded to the arXiv our joint paper “A multi-dimensional Szemerédi theorem for the primes via a correspondence principle“. This paper is related to an earlier result of Ben Green and mine in which we established that the primes contain arbitrarily long arithmetic progressions. Actually, in that paper we proved a more general result:
Theorem 1 (Szemerédi’s theorem in the primes) Let
be a subset of the primes
of positive relative density, thus
. Then
This result was based in part on an earlier paper of Green that handled the case of progressions of length three. With the primes replaced by the integers, this is of course the famous theorem of Szemerédi.
Szemerédi’s theorem has now been generalised in many different directions. One of these is the multidimensional Szemerédi theorem of Furstenberg and Katznelson, who used ergodic-theoretic techniques to show that any dense subset of 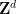
Theorem 2 (Multidimensional Szemerédi theorem in the primes) Let
, and let
Cartesian power
of the primes of positive relative density, thus
Then for any
,
with
and
a positive integer.
![\displaystyle \limsup_{N \rightarrow \infty} \frac{|A \cap [N]^d|}{|{\mathcal P}^d \cap [N]^d|} > 0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Climsup_%7BN+%5Crightarrow+%5Cinfty%7D+%5Cfrac%7B%7CA+%5Ccap+%5BN%5D%5Ed%7C%7D%7B%7C%7B%5Cmathcal+P%7D%5Ed+%5Ccap+%5BN%5D%5Ed%7C%7D+%3E+0.&bg=ffffff&fg=000000&s=0&c=20201002)
In the case when
The result is reminiscent of an earlier result of mine on finding constellations in the Gaussian primes (or dense subsets thereof). That paper followed closely the arguments of my original paper with Ben Green, namely it first enclosed (a W-tricked version of) the primes or Gaussian primes (in a sieve theoretic-sense) by a slightly larger set (or more precisely, a weight function 
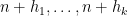
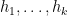
However, when one tries to adapt these arguments to sets such as 
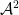
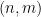
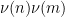
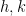
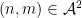
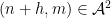

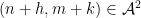
do not behave independently (as they would if 
There are now two ways known to get around this problem and establish Theorem 2 in full generality. The approach of Cook, Magyar, and Titichetrakun proceeds by starting with one of the known proofs of the multidimensional Szemerédi theorem – namely, the proof that proceeds through hypergraph regularity and hypergraph removal – and attach pseudorandom weights directly within the proof itself, rather than trying to add the weights to the result of that proof through a transference argument. (A key technical issue is that weights have to be added to all the levels of the hypergraph – not just the vertices and top-order edges – in order to circumvent the failure of naive pseudorandomness.) As one has to modify the entire proof of the multidimensional Szemerédi theorem, rather than use that theorem as a black box, the Cook-Magyar-Titichetrakun argument is lengthier than ours; on the other hand, it is more general and does not rely on some difficult theorems about primes that are used in our paper.
In our approach, we continue to use the multidimensional Szemerédi theorem (or more precisely, the equivalent theorem of Furstenberg and Katznelson concerning multiple recurrence for commuting shifts) as a black box. The difference is that instead of using a transference principle to connect the relative multidimensional Szemerédi theorem we need to the multiple recurrence theorem, we instead proceed by a version of the Furstenberg correspondence principle, similar to the one that connects the absolute multidimensional Szemerédi theorem to the multiple recurrence theorem. I had discovered this approach many years ago in an unpublished note, but had abandoned it because it required an infinite number of linear forms conditions (in contrast to the transference technique, which only needed a finite number of linear forms conditions and (until the recent work of Conlon-Fox-Zhao) a correlation condition). The reason for this infinite number of conditions is that the correspondence principle has to build a probability measure on an entire 

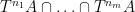

With the sieve weights 
One of the basic objects of study in combinatorics are finite strings 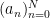
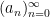
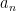
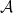
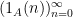

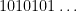

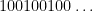
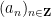
On the other hand, the basic object of study in dynamics (and in related fields, such as ergodic theory) is that of a dynamical system 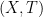

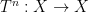
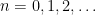

There is a fundamental correspondence principle connecting the study of strings (or subsets of natural numbers or integers) with the study of dynamical systems. In one direction, given a dynamical system 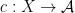
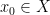
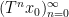


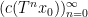
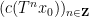
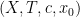
Example 1 If
with the shift map
,
is the observable that takes the value
and zero at the other two classes, and one starts with the initial datum
, then the observed string
In the converse direction, every infinite string 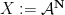
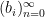
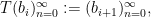
let

and let

Then one easily sees that the observed string 

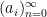
In the case when the alphabet 
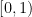
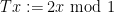

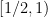
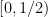
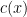
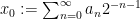
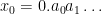
The above universal construction is very easy to describe, and is well suited for “generic” strings 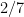
A related aesthetic objection to the universal construction is that of the four components 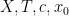
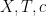
One step in this direction can be made by restricting 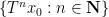
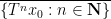

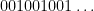
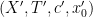
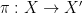

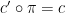

For general sequences
Lars Hörmander, who made fundamental contributions to all areas of partial differential equations, but particularly in developing the analysis of variable-coefficient linear PDE, died last Sunday, aged 81.
I unfortunately never met Hörmander personally, but of course I encountered his work all the time while working in PDE. One of his major contributions to the subject was to systematically develop the calculus of Fourier integral operators (FIOs), which are a substantial generalisation of pseudodifferential operators and which can be used to (approximately) solve linear partial differential equations, or to transform such equations into a more convenient form. Roughly speaking, Fourier integral operators are to linear PDE as canonical transformations are to Hamiltonian mechanics (and one can in fact view FIOs as a quantisation of a canonical transformation). They are a large class of transformations, for instance the Fourier transform, pseudodifferential operators, and smooth changes of the spatial variable are all examples of FIOs, and (as long as certain singular situations are avoided) the composition of two FIOs is again an FIO.
The full theory of FIOs is quite extensive, occupying the entire final volume of Hormander’s famous four-volume series “The Analysis of Linear Partial Differential Operators”. I am certainly not going to try to attempt to summarise it here, but I thought I would try to motivate how these operators arise when trying to transform functions. For simplicity we will work with functions 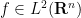

A function 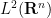
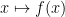


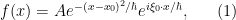
where 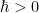
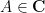
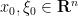
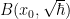
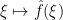


For instance, for the gaussian wave packet (1), one has
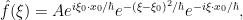
and so we see that 
However, there is a third (but less rigorous) way to view a function 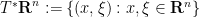
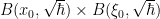



If functions in 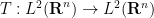
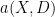

Now we turn to operators that alter the support of a phase space distribution, rather than the amplitude; we will focus on unitary operators to emphasise the amplitude preservation aspect. These will eventually be key examples of Fourier integral operators. A physical translation 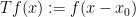


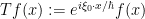
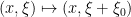


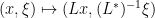

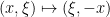
Based on these examples, one may hope that given any diffeomorphism 
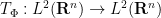
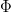
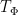
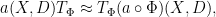
and thus 

The formalisation of this fact in the theory of Fourier integral operators is known as Egorov’s theorem, due to Yu Egorov (and not to be confused with the more widely known theorem of Dmitri Egorov in measure theory).
Applying commutators, we conclude the approximate conjugacy relationship
![\displaystyle \frac{1}{i\hbar} [(a \circ \Phi)(X,D), (b \circ \Phi)(X,D)] \approx T_\Phi^{-1} \frac{1}{i\hbar} [a(X,D), b(X,D)] T_\Phi.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cfrac%7B1%7D%7Bi%5Chbar%7D+%5B%28a+%5Ccirc+%5CPhi%29%28X%2CD%29%2C+%28b+%5Ccirc+%5CPhi%29%28X%2CD%29%5D+%5Capprox+T_%5CPhi%5E%7B-1%7D+%5Cfrac%7B1%7D%7Bi%5Chbar%7D+%5Ba%28X%2CD%29%2C+b%28X%2CD%29%5D+T_%5CPhi.&bg=ffffff&fg=000000&s=0&c=20201002)
Now, the pseudodifferential calculus (as discussed in this previous post) tells us (heuristically, at least) that
![\displaystyle \frac{1}{i\hbar} [a(X,D), b(X,D)] \approx \{ a, b \}(X,D)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cfrac%7B1%7D%7Bi%5Chbar%7D+%5Ba%28X%2CD%29%2C+b%28X%2CD%29%5D+%5Capprox+%5C%7B+a%2C+b+%5C%7D%28X%2CD%29&bg=ffffff&fg=000000&s=0&c=20201002)
and
![\displaystyle \frac{1}{i\hbar} [(a \circ \Phi)(X,D), (b \circ \Phi)(X,D)] \approx \{ a \circ \Phi, b \circ \Phi \}(X,D)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cfrac%7B1%7D%7Bi%5Chbar%7D+%5B%28a+%5Ccirc+%5CPhi%29%28X%2CD%29%2C+%28b+%5Ccirc+%5CPhi%29%28X%2CD%29%5D+%5Capprox+%5C%7B+a+%5Ccirc+%5CPhi%2C+b+%5Ccirc+%5CPhi+%5C%7D%28X%2CD%29&bg=ffffff&fg=000000&s=0&c=20201002)
where 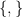
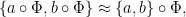
thus
Now suppose that 
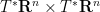
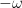

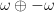
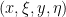

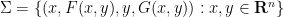
for some smooth functions 

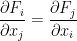

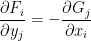
for 
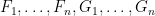
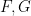
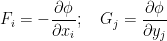
for some smooth potential function 

so that 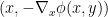

A reasonable candidate for an operator associated to
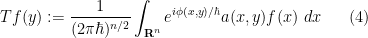
for some smooth amplitude function 

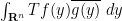
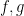
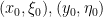
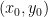

Of course, it may be the case that 
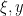
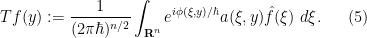
This class of FIOs covers many important cases; for instance, the translation, modulation, and dilation operators considered earlier can be written in this form after some Fourier analysis. Another typical example is the half-wave propagator 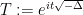

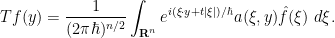
This corresponds to the phase space transformation 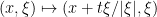
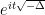

In some cases, the canonical relation
Many structures in mathematics are incomplete in one or more ways. For instance, the field of rationals 


Similarly, the rationals 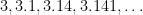

A third type of incompleteness is that of logical incompleteness, which applies now to formal theories rather than to fields or metric spaces. For instance, Zermelo-Frankel-Choice (ZFC) set theory is logically incomplete, because there exist statements (such as the consistency of ZFC) which could potentially be provable by the theory (because it does not lead to a contradiction, or at least so we believe, just from the axioms and deductive rules of the theory), but is not actually provable in this theory.
A fourth type of incompleteness, which is slightly less well known than the above three, is what I will call elementary incompleteness (and which model theorists call the failure of the countable saturation property). It applies to any structure that is describable by a first-order language, such as a field, a metric space, or a universe of sets. For instance, in the language of ordered real fields, the real line 

In each of these cases, though, it is possible to start with an incomplete structure and complete it to a much larger structure to eliminate the incompleteness. For instance, starting with an arbitrary field 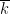
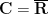
Similarly, starting with an arbitrary metric space 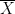

In a similar vein, we have the Gödel completeness theorem, which implies (among other things) that for any consistent first-order theory 



Finally, if one starts with an arbitrary structure 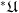
As mentioned earlier, completion tends to make a space much larger and more complicated. If one algebraically completes a finite field, for instance, one necessarily obtains an infinite field as a consequence. If one metrically completes a countable metric space with no isolated points, such as 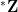
However, there are substantial benefits to working in the completed structure which can make it well worth the massive increase in size. For instance, by working in the algebraic completion of a field, one gains access to the full power of algebraic geometry. By working in the metric completion of a metric space, one gains access to powerful tools of real analysis, such as the Baire category theorem, the Heine-Borel theorem, and (in the case of Euclidean completions) the Bolzano-Weierstrass theorem. By working in a logically and elementarily completed theory (aka a saturated model) of a first-order theory, one gains access to the branch of model theory known as definability theory, which allows one to analyse the structure of definable sets in much the same way that algebraic geometry allows one to analyse the structure of algebraic sets. Finally, when working in an elementary completion of a structure, one gains a sequential compactness property, analogous to the Bolzano-Weierstrass theorem, which can be interpreted as the foundation for much of nonstandard analysis, as well as providing a unifying framework to describe various correspondence principles between finitary and infinitary mathematics.
In this post, I wish to expand upon these above points with regard to elementary completion, and to present nonstandard analysis as a completion of standard analysis in much the same way as, say, complex algebra is a completion of real algebra, or real metric geometry is a completion of rational metric geometry.
In a previous post, we discussed the Szemerédi regularity lemma, and how a given graph could be regularised by partitioning the vertex set into random neighbourhoods. More precisely, we gave a proof of
Lemma 1 (Regularity lemma via random neighbourhoods) Let
. Then there exists integers
with the following property: whenever
be a graph on finitely many vertices, if one selects one of the integers
at random from
uniformly from
at random, then the
vertex cells
(some of which can be empty) generated by the vertex neighbourhoods
for
, will obey the regularity property
with probability at least
, where the sum is over all pairs
for which
is not
-regular between
and
. [Recall that a pair
is
for any
and
with
, where
is the density of edges between
.]


The proof was a combinatorial one, based on the standard energy increment argument.
In this post I would like to discuss an alternate approach to the regularity lemma, which is an infinitary approach passing through a graph-theoretic version of the Furstenberg correspondence principle (mentioned briefly in this earlier post of mine). While this approach superficially looks quite different from the combinatorial approach, it in fact uses many of the same ingredients, most notably a reliance on random neighbourhoods to regularise the graph. This approach was introduced by myself back in 2006, and used by Austin and by Austin and myself to establish some property testing results for hypergraphs; more recently, a closely related infinitary hypergraph removal lemma developed in the 2006 paper was also used by Austin to give new proofs of the multidimensional Szemeredi theorem and of the density Hales-Jewett theorem (the latter being a spinoff of the polymath1 project).
For various technical reasons we will not be able to use the correspondence principle to recover Lemma 1 in its full strength; instead, we will establish the following slightly weaker variant.
Lemma 2 (Regularity lemma via random neighbourhoods, weak version) Let
with the following property: whenever
such that if one selects
uniformly from
vertex cells
generated by the vertex neighbourhoods
, will obey the regularity property (1) with probability at least
.
Roughly speaking, Lemma 1 asserts that one can regularise a large graph 
This month I am at MSRI, for the programs of Ergodic Theory and Additive Combinatorics, and Analysis on Singular Spaces, that are currently ongoing here. This week I am giving three lectures on the correspondence principle, and on finitary versions of ergodic theory, for the introductory workshop in the former program. The article here is broadly describing the content of these talks (which are slightly different in theme from that announced in the abstract, due to some recent developments). [These lectures were also recorded on video and should be available from the MSRI web site within a few months.]
In this lecture, we describe the simple but fundamental Furstenberg correspondence principle which connects the “soft analysis” subject of ergodic theory (in particular, recurrence theorems) with the “hard analysis” subject of combinatorial number theory (or more generally with results of “density Ramsey theory” type). Rather than try to set up the most general and abstract version of this principle, we shall instead study the canonical example of this principle in action, namely the equating of the Furstenberg multiple recurrence theorem with Szemerédi’s theorem on arithmetic progressions.
Read the rest of this entry »

Recent Comments