
You are currently browsing the category archive for the ‘math.CT’ category.
As someone who had a relatively light graduate education in algebra, the import of Yoneda’s lemma in category theory has always eluded me somewhat; the statement and proof are simple enough, but definitely have the “abstract nonsense” flavor that one often ascribes to this part of mathematics, and I struggled to connect it to the more grounded forms of intuition, such as those based on concrete examples, that I was more comfortable with. There is a popular MathOverflow post devoted to this question, with many answers that were helpful to me, but I still felt vaguely dissatisfied. However, recently when pondering the very concrete concept of a polynomial, I managed to accidentally stumble upon a special case of Yoneda’s lemma in action, which clarified this lemma conceptually for me. In the end it was a very simple observation (and would be extremely pedestrian to anyone who works in an algebraic field of mathematics), but as I found this helpful to a non-algebraist such as myself, and I thought I would share it here in case others similarly find it helpful.
In algebra we see a distinction between a polynomial form (also known as a formal polynomial), and a polynomial function, although this distinction is often elided in more concrete applications. A polynomial form in, say, one variable with integer coefficients, is a formal expression 
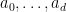


![{{\bf Z}[{\mathrm n}]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+Z%7D%5B%7B%5Cmathrm+n%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

A polynomial form 

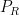
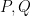




- (i) The linear forms
are distinct as polynomial forms, but agree when interpreted in the ring
, since
for all
.
- (ii) Similarly, if
is a prime, then the degree one form
are distinct as polynomial forms (and in particular have distinct degrees), but agree when interpreted in the ring
, thanks to Fermat’s little theorem.
- (iii) The polynomial form
has no roots when interpreted in the reals
, but has roots when interpreted in the complex numbers
. Similarly, the linear form
has no roots when interpreted in the integers
, but has roots when interpreted in the rationals
.
The above examples show that if one only interprets polynomial forms in a specific ring
If 
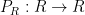
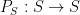

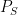


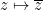
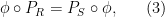

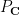 on the complex numbers, and any complex number .
on the complex numbers, and any complex number .
What was surprising to me (as someone who had not internalized the Yoneda lemma) was that the converse statement was true: if one had a function 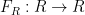
![{P \in {\bf Z}[\mathrm{n}]}](https://s0.wp.com/latex.php?latex=%7BP+%5Cin+%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


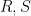
![{{\bf Z}[\mathrm{n}]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{\phi_{R,n}: {\bf Z}[\mathrm{n}] \rightarrow R}](https://s0.wp.com/latex.php?latex=%7B%5Cphi_%7BR%2Cn%7D%3A+%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D+%5Crightarrow+R%7D&bg=ffffff&fg=000000&s=0&c=20201002)

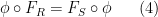
 . Applying (4) to this ring homomorphism, and specializing to the element of , we conclude that
. Applying (4) to this ring homomorphism, and specializing to the element of , we conclude that ![\displaystyle \phi_{R,n}( F_{{\bf Z}[\mathrm{n}]}(\mathrm{n}) ) = F_R( n )](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cphi_%7BR%2Cn%7D%28+F_%7B%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%7D%28%5Cmathrm%7Bn%7D%29+%29+%3D+F_R%28+n+%29&bg=ffffff&fg=000000&s=0&c=20201002) and any . If we then define to be the formal polynomial
and any . If we then define to be the formal polynomial ![\displaystyle P := F_{{\bf Z}[\mathrm{n}]}(\mathrm{n}),](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++P+%3A%3D+F_%7B%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%7D%28%5Cmathrm%7Bn%7D%29%2C&bg=ffffff&fg=000000&s=0&c=20201002)

 arises from a polynomial form . Conversely, from the identity
arises from a polynomial form . Conversely, from the identity ![\displaystyle P = P_{{\bf Z}[\mathrm{n}]}(\mathrm{n})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++P+%3D+P_%7B%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%7D%28%5Cmathrm%7Bn%7D%29&bg=ffffff&fg=000000&s=0&c=20201002) , we see that two polynomial forms
, we see that two polynomial forms 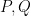 can only generate the same polynomial functions
can only generate the same polynomial functions  for all rings if they are identical as polynomial forms. So the polynomial form associated to the family is unique.
for all rings if they are identical as polynomial forms. So the polynomial form associated to the family is unique.
We have thus created an identification of form and function: polynomial forms 
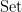

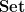
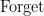
![{{\bf Z}[\mathbf{n}]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+Z%7D%5B%5Cmathbf%7Bn%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathrm{Forget}({\bf Z}[\mathbf{n}]) \equiv \mathrm{Hom}( \mathrm{Forget}, \mathrm{Forget} ). \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathrm%7BForget%7D%28%7B%5Cbf+Z%7D%5B%5Cmathbf%7Bn%7D%5D%29+%5Cequiv+%5Cmathrm%7BHom%7D%28+%5Cmathrm%7BForget%7D%2C+%5Cmathrm%7BForget%7D+%29.+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
What does this have to do with Yoneda’s lemma? Well, remember that every element 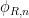
![{\mathrm{Hom}({\bf Z}[\mathrm{n}], R)}](https://s0.wp.com/latex.php?latex=%7B%5Cmathrm%7BHom%7D%28%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%2C+R%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathrm{Forget} \equiv \mathrm{Hom}({\bf Z}[\mathrm{n}], -).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathrm%7BForget%7D+%5Cequiv+%5Cmathrm%7BHom%7D%28%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%2C+-%29.&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathrm{Forget}({\bf Z}[\mathbf{n}]) \equiv \mathrm{Hom}( \mathrm{Hom}({\bf Z}[\mathrm{n}], -), \mathrm{Forget} )](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathrm%7BForget%7D%28%7B%5Cbf+Z%7D%5B%5Cmathbf%7Bn%7D%5D%29+%5Cequiv+%5Cmathrm%7BHom%7D%28+%5Cmathrm%7BHom%7D%28%7B%5Cbf+Z%7D%5B%5Cmathrm%7Bn%7D%5D%2C+-%29%2C+%5Cmathrm%7BForget%7D+%29&bg=ffffff&fg=000000&s=0&c=20201002)
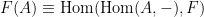
 from a (locally small) category
from a (locally small) category 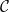 and any object
and any object  in . And indeed if one inspects the standard proof of this lemma, it is essentially the same argument as the argument we used above to establish the identification (5). More generally, it seems to me that the Yoneda lemma is often used to identify “formal” objects with their “functional” interpretations, as long as one simultaneously considers interpretations across an entire category (such as the category of rings), as opposed to just a single interpretation in a single object of the category in which there may be some loss of information due to the peculiarities of that specific object. Grothendieck’s “functor of points” interpretation of a scheme, discussed in this previous blog post, is one typical example of this.
in . And indeed if one inspects the standard proof of this lemma, it is essentially the same argument as the argument we used above to establish the identification (5). More generally, it seems to me that the Yoneda lemma is often used to identify “formal” objects with their “functional” interpretations, as long as one simultaneously considers interpretations across an entire category (such as the category of rings), as opposed to just a single interpretation in a single object of the category in which there may be some loss of information due to the peculiarities of that specific object. Grothendieck’s “functor of points” interpretation of a scheme, discussed in this previous blog post, is one typical example of this.
A popular way to visualise relationships between some finite number of sets is via Venn diagrams, or more generally Euler diagrams. In these diagrams, a set is depicted as a two-dimensional shape such as a disk or a rectangle, and the various Boolean relationships between these sets (e.g., that one set is contained in another, or that the intersection of two of the sets is equal to a third) is represented by the Boolean algebra of these shapes; Venn diagrams correspond to the case where the sets are in “general position” in the sense that all non-trivial Boolean combinations of the sets are non-empty. For instance to depict the general situation of two sets 

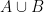

(where we have given each region depicted a different color, and moved the edges of each region a little away from each other in order to make them all visible separately), but if one wanted to instead depict a situation in which the intersection

One can use the area of various regions in a Venn or Euler diagram as a heuristic proxy for the cardinality 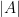
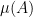
 , while the above Euler diagram similarly justifies the special case
, while the above Euler diagram similarly justifies the special case 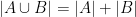 .
.
While Venn and Euler diagrams are traditionally two-dimensional in nature, there is nothing preventing one from using one-dimensional diagrams such as

or even three-dimensional diagrams such as this one from Wikipedia:

Of course, in such cases one would use length or volume as a heuristic proxy for cardinality or measure, rather than area.
With the addition of arrows, Venn and Euler diagrams can also accommodate (to some extent) functions between sets. Here for instance is a depiction of a function 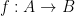




Here one can illustrate surjectivity of 


Cartesian product operations can be incorporated into these diagrams by appropriate combinations of one-dimensional and two-dimensional diagrams. Here for instance is a diagram that illustrates the identity 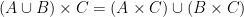

In this blog post I would like to propose a similar family of diagrams to illustrate relationships between vector spaces (over a fixed base field 
Let 
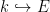
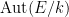
![{[E:k]}](https://s0.wp.com/latex.php?latex=%7B%5BE%3Ak%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
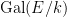
Theorem 1 (Fundamental theorem of Galois theory) Let
- (i) If
is an intermediate field betwen
is a subgroup of
- (ii) Conversely, if
is a subgroup of
; namely
- (iii) If
and
, then
if and only if
is a subgroup of
.
- (iv) If
is isomorphic to the quotient group
.
Example 2 Let
, and let
be the degree
Galois extension formed by adjoining a primitive
root of unity (that is to say,
(the invertible elements of the ring
). Amongst the intermediate fields, one has the cyclotomic fields of the form
where
divides
and
of
modulo
Example 3 Let
be the field of rational functions of one indeterminate
be the field formed by adjoining an
to
. Then
corresponding to the field automorphism of
to
). The intermediate fields are of the form
where
and
There is an analogous Galois correspondence in the covering theory of manifolds. For simplicity we restrict attention to finite covers. If 
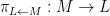

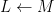
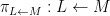
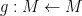
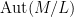
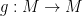

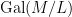
Suppose 

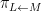
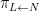
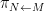

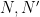
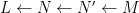
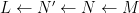
Theorem 4 (Fundamental theorem of covering spaces) Let
- (i) If
is a subgroup of
- (ii) Conversely, if
.
- (iii) If
and
, then
if and only if
is a subgroup of
.
- (iv) If
is isomorphic to the quotient group
.
Example 5 Let
, and let
be the
. Then
with covering map
where
Given the strong similarity between the two theorems, it is natural to ask if there is some more concrete connection between Galois theory and the theory of finite covers.
In one direction, if the manifolds 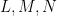
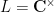
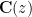
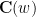
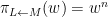
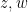
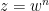
Exercise 6 What happens if one uses meromorphic functions in place of rational functions in the above example? (To answer this question, I found it convenient to use a discrete Fourier transform associated to the multiplicative action of the
of the coordinate
.)
I was curious however about the reverse direction. Starting with some field extensions 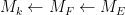
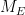
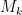
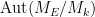
The standard answer from modern algebraic geometry (as articulated for instance in this nice MathOverflow answer by Minhyong Kim) is to set 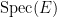
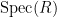
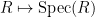

![{{\bf C}[z, z^{-1}]}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+C%7D%5Bz%2C+z%5E%7B-1%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
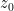
![{\{ f \in {\bf C}[z, z^{-1}]: f(z_0)=0\}}](https://s0.wp.com/latex.php?latex=%7B%5C%7B+f+%5Cin+%7B%5Cbf+C%7D%5Bz%2C+z%5E%7B-1%7D%5D%3A+f%28z_0%29%3D0%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{\mathrm{Spec}( {\bf C}[z,z^{-1}] )}](https://s0.wp.com/latex.php?latex=%7B%5Cmathrm%7BSpec%7D%28+%7B%5Cbf+C%7D%5Bz%2Cz%5E%7B-1%7D%5D+%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Of course, the spectrum of a field such as 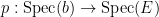

As an exercise, I set myself the task of trying to interpret Galois theory as an analogue of covering space theory in a more classical fashion, without explicit reference to more modern concepts such as schemes, spectra, or étale topology. After some experimentation, I found a reasonably satisfactory way to do so as follows. The space 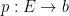






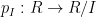
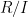
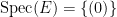
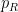

Below the fold I would like to record this interpretation of Galois theory, by first revisiting the theory of covering spaces using paths as the basic building block, and then adapting that theory to the theory of field extensions using the spaces indicated above. This is not too far from the usual scheme-theoretic way of phrasing the connection between the two topics (basically I have replaced étale-type points
In the traditional foundations of probability theory, one selects a probability space 
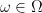
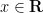



Actually, for our purposes we will adopt the philosophy of identifying stochastic objects that agree almost surely, so if one was to be completely precise, we should define a stochastic real number to be an equivalence class ![{[x]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

More generally, given any measurable space 
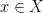




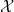
Remark 1 In my previous post on the foundations of probability theory, I emphasised the freedom to extend the sample space
Any (measurable) 

![{[x]+[y]}](https://s0.wp.com/latex.php?latex=%7B%5Bx%5D%2B%5By%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

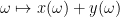


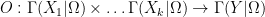
There is a similar story for 
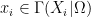
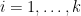
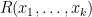









Any universal identity for deterministic operations (or universal implication between identities) extends to their stochastic counterparts: for instance, addition is commutative, associative, and cancellative on the space of deterministic reals 
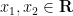
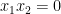
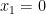

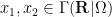
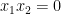



and then make all sets stochastic to obtain the true statement

thus we have to allow the index 

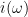


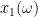

Similarly, the law of the excluded middle fails when interpreted deterministically, but remains true when interpreted stochastically: if
To avoid having to keep pointing out which operations are interpreted stochastically and which ones are interpreted deterministically, we will use the following convention: if we assert that a mathematical sentence 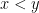
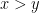
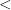
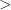
In the above discussion, the stochastic objects 



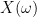

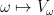
Of course, in any reasonable application one can avoid the set theoretic issues at least by various ad hoc means, for instance by restricting the dimension of all spaces involved to some fixed cardinal such as 
In this post I would like to describe a different way to formalise stochastic spaces, and stochastic elements of these spaces, by viewing the spaces as measure-theoretic analogue of a sheaf, but being over the probability space 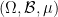

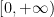
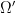


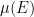
The approach taken in this post is “topos-theoretic” in nature (although we will not use the language of topoi explicitly here), and is well suited to a “pointless” or “point-free” approach to probability theory, in which the role of the stochastic state
Definition 1 (Stochastic set) Unless otherwise specified, we assume that we are given a fixed finite measure space
(which we refer to as the base space). A stochastic set (relative to
consisting of the following objects:
- A set
assigned to each event
; and
- A restriction map
from
to
of nested events
. (Strictly speaking, one should indicate the dependence on
instead of
We refer to elements of
, localised to the event
Furthermore, we impose the following axioms:
- (Category) The map
are events in
for all
.
- (Null events trivial) If
is always a singleton set; this is analogous to the convention that
for any number
- (Countable gluing) Suppose that for each natural number
and an element
such that
for all
. Then there exists a unique
such that
for all
If
of the stochastic set
relative to

The following fact is useful for actually verifying that a given object indeed has the structure of a stochastic set:
Exercise 1 Show that to verify the countable gluing axiom of a stochastic set, it suffices to do so under the additional hypothesis that the events
are disjoint. (Note that this is quite different from the situation with sheaves over a topological space, in which the analogous gluing axiom is often trivial in the disjoint case but has non-trivial content in the overlapping case. This is ultimately because a
Let us illustrate the concept of a stochastic set with some examples.
Example 1 (Discrete case) A simple case arises when
to each
. One then sets
, with the obvious restriction maps, giving rise to a stochastic set
on
.) Conversely, it is not difficult to see that any stochastic set over an at most countable discrete probability space
Example 2 (Measurable spaces as stochastic sets) Returning now to a general base space
, together with the quotienting by almost sure equivalence, means that
of fibres, but this still serves as a useful first approximation to what
Example 3 (Extended Hilbert modules) This example is the one that motivated this post for me. Suppose that one has an extension
of the base space
, thus we have a measurable factor map
such that the pushforward of the measure
by
. Then we have a conditional expectation operator
, defined as the adjoint of the pullback map
. As is well known, the conditional expectation operator also extends to a contraction
; by monotone convergence we may also extend
to a map from measurable functions from
to the extended non-negative reals
, to measurable functions from
to be the space of functions
with
finite almost everywhere. This is an extended version of the Hilbert module
, which is defined similarly except that
; this is a Hilbert module over
which is of particular importance in the Furstenberg-Zimmer structure theory of measure-preserving systems. We can then define the stochastic set
by setting
with the obvious restriction maps. In the case that
are standard Borel spaces, one can disintegrate
as an integral
of probability measures
(supported in the fibre
), in which case this stochastic set can be viewed as having fibres
(though if

We make the remark that if 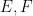
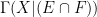
As a corollary of the above observation, we see that if the base space 
Exercise 2 If
for
One can now start take many of the fundamental objects, operations, and results in set theory (and, hence, in most other categories of mathematics) and establish analogues relative to a finite measure space. Implicitly, what we will be doing in the next few paragraphs is endowing the category of stochastic sets with the structure of an elementary topos. However, to keep things reasonably concrete, we will not explicitly emphasise the topos-theoretic formalism here, although it is certainly lurking in the background.
Firstly, we define a stochastic function 

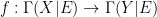


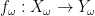
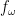

Thus (in the discrete, at most countable setting, at least) stochastic functions do not mix together information from different states 
One can now form the stochastic set 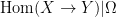
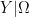




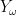
In a similar spirit, we say that one stochastic set 


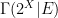
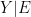
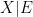

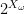
Note that if 








In a similar spirit, if 



Remark 2 One should caution that in the definition of the subset relation
.
Now we discuss Boolean operations on stochastic subsets of a given stochastic set 



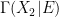
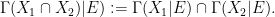
This is easily verified to again be a stochastic subset of 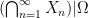

Stochastic unions are a bit more subtle. The set 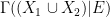













One can also consider a stochastic finite union 

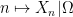

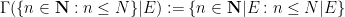


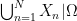







The Cartesian product 


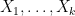



Remark 3 In the degenerate case when
), and any two deterministic objects
.
The following simple observation is crucial to subsequent discussion. If 
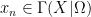


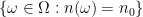
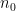
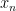



We now specialise from the extremely broad discipline of set theory to the more focused discipline of real analysis. There are two fundamental axioms that underlie real analysis (and in particular distinguishes it from real algebra). The first is the Archimedean property, which we phrase in the “no infinitesimal” formulation as follows:
Proposition 2 (Archimedean property) Let
for all positive natural numbers
.
The other is the least upper bound axiom:
Proposition 3 (Least upper bound axiom) Let
, thus
for all
. Then there exists a unique real number
with the following properties:
for all
- For any real
, there exists
.
.
Furthermore,
does not depend on the choice of
The Archimedean property extends easily to the stochastic setting:
Proposition 4 (Stochastic Archimedean property) Let
be such that
Remark 4 Here, incidentally, is one place in which this stochastic formalism deviates from the nonstandard analysis formalism, as the latter certainly permits the existence of infinitesimal elements. On the other hand, we caution that stochastic real numbers are permitted to be unbounded, so that formulation of Archimedean property is not valid in the stochastic setting.
The proof is easy and is left to the reader. The least upper bound axiom also extends nicely to the stochastic setting, but the proof requires more work (in particular, our argument uses the monotone convergence theorem):
Theorem 5 (Stochastic least upper bound axiom) Let
be a stochastic subset of
which has a global upper bound
, thus
, and is globally non-empty in the sense that there is at least one global element
with the following properties:
- For any stochastic real
Furthermore,
For future reference, we note that the same result holds with 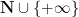

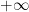
Proof: Uniqueness is clear (using the Archimedean property), as well as the independence on 



We observe that 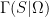

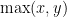




Let 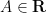

then (by Proposition 3!) 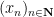

Using the lattice property, we may assume that the 
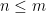

If 

From this and (1) we conclude that

From monotone convergence, we conclude that

and so
Now let 



Remark 5 One can abstract away the role of the measure
Using Proposition 4 and Theorem 5, one can then revisit many of the other foundational results of deterministic real analysis, and develop stochastic analogues; we give some examples of this below the fold (focusing on the Heine-Borel theorem and a case of the spectral theorem). As an application of this formalism, we revisit some of the Furstenberg-Zimmer structural theory of measure-preserving systems, particularly that of relatively compact and relatively weakly mixing systems, and interpret them in this framework, basically as stochastic versions of compact and weakly mixing systems (though with the caveat that the shift map is allowed to act non-trivially on the underlying probability space). As this formalism is “point-free”, in that it avoids explicit use of fibres and disintegrations, it will be well suited for generalising this structure theory to settings in which the underlying probability spaces are not standard Borel, and the underlying groups are uncountable; I hope to discuss such generalisations in future blog posts.
Remark 6 Roughly speaking, stochastic real analysis can be viewed as a restricted subset of classical real analysis in which all operations have to be “measurable” with respect to the base space. In particular, indiscriminate application of the axiom of choice is not permitted, and one should largely restrict oneself to performing countable unions and intersections rather than arbitrary unions or intersections. Presumably one can formalise this intuition with a suitable “countable transfer principle”, but I was not able to formulate a clean and general principle of this sort, instead verifying various assertions about stochastic objects by hand rather than by direct transfer from the deterministic setting. However, it would be desirable to have such a principle, since otherwise one is faced with the tedious task of redoing all the foundations of real analysis (or whatever other base theory of mathematics one is going to be working in) in the stochastic setting by carefully repeating all the arguments.
More generally, topos theory is a good formalism for capturing precisely the informal idea of performing mathematics with certain operations, such as the axiom of choice, the law of the excluded middle, or arbitrary unions and intersections, being somehow “prohibited” or otherwise “restricted”.
As laid out in the foundational work of Kolmogorov, a classical probability space (or probability space for short) is a triplet 
![{\mu: {\mathcal X} \rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7B%5Cmu%3A+%7B%5Cmathcal+X%7D+%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
- the (real) Hilbert space
of square-integrable functions
, modulo
; and
- the unital commutative Banach algebra
of essentially bounded functions
defined as the essential supremum of
.
There is also a trace 

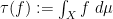
One can form the category 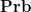

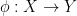

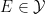
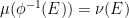
Let us now abstract the algebraic features of these spaces as follows; for want of a better name, I will refer to this abstraction as an algebraic probability space, and is very similar to the non-commutative probability spaces studied in this previous post, except that these spaces are now commutative (and real).
Definition 1 An algebraic probability space is a pair
where
is a unital commutative real algebra;
is a homomorphism such that
and
for all
;
- Every element
. (Technically, this isn’t an algebraic property, but I need it for technical reasons.)
A morphism
is a homomorphism
which is trace-preserving, in the sense that
for all
.
For want of a better name, I’ll denote the category of algebraic probability spaces as 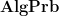
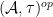
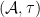

By the previous discussion, we have a covariant functor 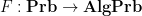
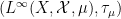
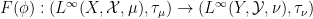
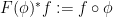
for 
In this post I would like to describe a functor 

Let us describe how to construct the functor
- Starting with an algebraic probability space
, and also form the spectral radius
.
- The inner product is clearly positive semi-definite. Quotienting out the null vectors and taking completions, we arrive at a real Hilbert space
, to which the trace
may be extended.
- Somewhat less obviously, the spectral radius is well-defined and gives a norm on
limits of sequences in
of
- The idempotents
of the Banach algebra
- The Boolean algebra homomorphisms
(or equivalently, the real algebra homomorphisms
) may be indexed by elements
- Let
for every
- Let
be the
, where
.
- One verifies that
. Using this isomorphism, the trace
, and the abstract spaces
may now be identified with their concrete counterparts
- Every algebraic probability space morphism
generates a classical probability morphism
via the formula
using a pullback operation
on the abstract
that can be defined by density.
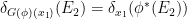
Remark 1 The classical probability space
The partial inversion relationship between the functors
- There is a natural transformation from
to the identity functor
.
More informally: if one starts with an algebraic probability space 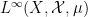
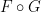

Remark 2 The opposite composition
is a little odd: it takes an arbitrary probability space
, with
being the space of homomorphisms
. while there is “morally” an embedding of
,
, then these algebras become naturally isomorphic after quotienting out by null sets.
Remark 3 An algebraic probability space captures a bit more structure than a classical probability space, because
(with the usual Haar measure and the usual trace
), any unital subalgebra
that is dense in
will generate the same classical probability space
of homomorphisms from
, the Wiener algebra
or the full space
of continuous functions on a topological space. I hope to discuss one such example of extra structure (coming from the Gowers-Host-Kra theory of uniformity seminorms) in a later blog post (this generalises the example of the Wiener algebra given previously, which is encoding “Fourier structure”).
A small example of how one could use the functors 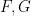

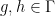
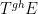

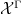
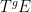
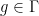
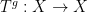



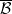
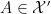
More indirectly, the functors
Given a function 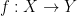
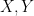

which is a subset of the Cartesian product 
There are a number of “closed graph theorems” in mathematics which relate the regularity properties of the function 
Theorem 1 (Closed graph theorem (functional analysis)) Let
is both linearly closed (i.e. it is a linear subspace of
I like to think of this theorem as linking together qualitative and quantitative notions of regularity preservation properties of an operator
The theorem is equivalent to the assertion that any continuous linear bijection 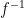
It turns out that there is a closed graph theorem (or equivalent reformulations of that theorem, such as an assertion that bijective morphisms between sufficiently “complete” objects are necessarily isomorphisms, or as an open mapping theorem) in many other categories in mathematics as well. Here are some easy ones:
Theorem 2 (Closed graph theorem (linear algebra)) Let
Theorem 3 (Closed graph theorem (group theory)) Let
Theorem 4 (Closed graph theorem (order theory)) Let
Remark 1 Similar results to the above three theorems (with similarly easy proofs) hold for other algebraic structures, such as rings (using the usual product of rings), modules, algebras, or Lie algebras, groupoids, or even categories (a map between categories is a functor iff its graph is again a category). (ADDED IN VIEW OF COMMENTS: further examples include affine spaces and
A slightly more sophisticated result in the same vein:
Theorem 5 (Closed graph theorem (point set topology)) Let
Indeed, the “only if” direction is easy, while for the “if” direction, note that if
Note that the compactness hypothesis is necessary: for instance, the function 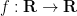
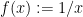


A similar result (but relying on a much deeper theorem) is available in algebraic geometry, as I learned after asking this MathOverflow question:
Theorem 6 (Closed graph theorem (algebraic geometry)) Let
Proof: (Sketch) For the only if direction, note that the map 
Conversely, if 
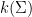
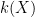
![{k[\Sigma]}](https://s0.wp.com/latex.php?latex=%7Bk%5B%5CSigma%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{k[X]}](https://s0.wp.com/latex.php?latex=%7Bk%5BX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The counterexample of the map 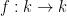

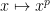
There are also a number of closed graph theorems for topological groups, of which the following is typical (see Exercise 3 of these previous blog notes):
Theorem 7 (Closed graph theorem (topological group theory)) Let
is a continuous homomorphism if and only if the graph
The hypotheses of being
In several complex variables, it is a classical theorem (see e.g. Lemma 4 of this blog post) that a holomorphic function from a domain in 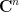
Theorem 8 (Closed graph theorem (complex manifolds)) Let
Indeed, one applies the previous observation to the projection from 
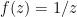
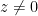
(ADDED LATER:) There is a real analogue to the above theorem:
Theorem 9 (Closed graph theorem (real manifolds)) Let
This theorem can be proven by applying invariance of domain (discussed in this previous post) to the projection of
Note though that the analogous claim for smooth real manifolds fails: the function 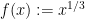
(ADDED YET LATER:) Here is an easy closed graph theorem in the symplectic category:
Theorem 10 (Closed graph theorem (symplectic geometry)) Let
and
be smooth symplectic manifolds of the same dimension. Then a smooth map
) if and only if the graph
is a Lagrangian submanifold of
.
In view of the symplectic rigidity phenomenon, it is likely that the smoothness hypotheses on 
There are presumably many further examples of closed graph theorems (or closely related theorems, such as criteria for inverting a morphism, or open mapping type theorems) throughout mathematics; I would be interested to know of further examples.
In his wonderful article “On proof and progress in mathematics“, Bill Thurston describes (among many other topics) how one’s understanding of given concept in mathematics (such as that of the derivative) can be vastly enriched by viewing it simultaneously from many subtly different perspectives; in the case of the derivative, he gives seven standard such perspectives (infinitesimal, symbolic, logical, geometric, rate, approximation, microscopic) and then mentions a much later perspective in the sequence (as describing a flat connection for a graph).
One can of course do something similar for many other fundamental notions in mathematics. For instance, the notion of a group
- (0) Motivating examples: A group is an abstraction of the operations of addition/subtraction or multiplication/division in arithmetic or linear algebra, or of composition/inversion of transformations.
- (1) Universal algebraic: A group is a set
, and a binary multiplication operation
obeying the relations (or axioms)
,
,
for all
.
- (2) Symmetric: A group is all the ways in which one can transform a space
to itself while preserving some object or structure
on this space.
- (3) Representation theoretic: A group is identifiable with a collection of transformations on a space
- (4) Presentation theoretic: A group can be generated by a collection of generators subject to some number of relations.
- (5) Topological: A group is the fundamental group
of a connected topological space
- (6) Dynamic: A group represents the passage of time (or of some other variable(s) of motion or action) on a (reversible) dynamical system.
- (7) Category theoretic: A group is a category with one object, in which all morphisms have inverses.
- (8) Quantum: A group is the classical limit
of a quantum group.
- etc.
One can view a large part of group theory (and related subjects, such as representation theory) as exploring the interconnections between various of these perspectives. As one’s understanding of the subject matures, many of these formerly distinct perspectives slowly merge into a single unified perspective.
From a recent talk by Ezra Getzler, I learned a more sophisticated perspective on a group, somewhat analogous to Thurston’s example of a sophisticated perspective on a derivative (and coincidentally, flat connections play a central role in both):
- (37) Sheaf theoretic: A group is identifiable with a (set-valued) sheaf on the category of simplicial complexes such that the morphisms associated to collapses of
-simplices are bijective for
(and merely surjective for
).
This interpretation of the group concept is apparently due to Grothendieck, though it is motivated also by homotopy theory. One of the key advantages of this interpretation is that it generalises easily to the notion of an
The connection of (37) with any of the other perspectives of a group is elementary, but not immediately obvious; I enjoyed working out exactly what the connection was, and thought it might be of interest to some readers here, so I reproduce it below the fold.
[Note: my reconstruction of Grothendieck’s perspective, and of the appropriate terminology, is likely to be somewhat inaccurate in places: corrections are of course very welcome.]
I’ve just uploaded to the arXiv my joint paper with Tim Austin, “On the testability and repair of hereditary hypergraph properties“, which has been submitted to Random Structures and Algorithms. In this paper we prove some positive and negative results for the testability (and the local repairability) of various properties of directed or undirected graphs and hypergraphs, which can be either monochromatic or multicoloured.
The negative results have already been discussed in a previous posting of mine, so today I will focus on the positive results. The property testing results here are finitary results, but it turns out to be rather convenient to use a certain correspondence principle (the hypergraph version of the Furstenberg correspondence principle) to convert the question into one about exchangeable probability measures on spaces of hypergraphs (i.e. on random hypergraphs whose probability distribution is invariant under exchange of vertices). Such objects are also closely related to the”graphons” and “hypergraphons” that emerge as graph limits, as studied by Lovasz-Szegedy, Elek-Szegedy, and others. Somewhat amusingly, once one does so, it then becomes convenient to keep track of objects indexed by vertex sets and how they are exchanged via the language of category theory, and in particular using the concept of a natural transformation to describe such objects as exchangeable measures, graph colourings, and local modification rules. I will try to sketch out some of these connections, after describing the main positive results.
Before we begin or study of dynamical systems, topological dynamical systems, and measure-preserving systems (as defined in the previous lecture), it is convenient to give these three classes the structure of a category. One of the basic insights of category theory is that a mathematical objects in a given class (such as dynamical systems) are best studied not in isolation, but in relation to each other, via morphisms. Furthermore, many other basic concepts pertaining to these objects (e.g. subobjects, factors, direct sums, irreducibility, etc.) can be defined in terms of these morphisms. One advantage of taking this perspective here is that it provides a unified way of defining these concepts for the three different categories of dynamical systems, topological dynamical systems, and measure-preserving systems that we will study in this course, thus sparing us the need to give any of our definitions (except for our first one below) in triplicate.

Recent Comments