
You are currently browsing the tag archive for the ‘Vaughan identity’ tag.
A fundamental and recurring problem in analytic number theory is to demonstrate the presence of cancellation in an oscillating sum, a typical example of which might be a correlation
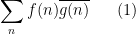
between two arithmetic functions 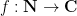



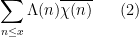
that measures the correlation between the primes and a Dirichlet character 
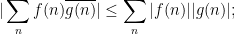
for instance, from the triangle inequality and the prime number theorem we have

as 
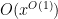
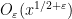

It has proven surprisingly difficult, however, to establish significant cancellation in many of the sums of interest in analytic number theory, particularly if the sums do not have a strong amount of algebraic structure (e.g. multiplicative structure) which allow for the deployment of specialised techniques (such as multiplicative number theory techniques). In fact, we are forced to rely (to an embarrassingly large extent) on (many variations of) a single basic tool to capture at least some cancellation, namely the Cauchy-Schwarz inequality. In fact, in many cases the classical case

considered by Cauchy, where at least one of 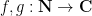



There is however some skill required to decide exactly how to deploy the Cauchy-Schwarz inequality (and in particular, how to select 
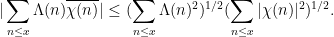
The right-hand side may be bounded by 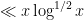
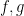
While the Cauchy-Schwarz inequality can be poor at estimating a single correlation such as (1), its power improves when considering an average (or sum, or square sum) of multiple correlations. In this set of notes, we will focus on one such situation of this type, namely that of trying to estimate a square sum
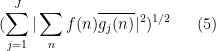
that measures the correlations of a single function 
Lemma 1 (Bessel inequality) Let
be finitely supported functions obeying the orthonormality relationship
for all
. Then for any function

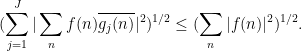
For sake of comparison, if one were to apply the Cauchy-Schwarz inequality (4) separately to each summand in (5), one would obtain the bound of 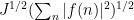

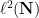
In analytic number theory applications, it is useful to generalise the Bessel inequality to the situation in which the
Proposition 2 (Generalised Bessel inequality) Let
be a non-negative function. Let
vanishes, we have
for some sequence
of complex numbers with
, with the convention that
vanishes whenever
both vanish.


Note by relabeling that we may replace the domain 

Proof: We use the method of duality to replace the role of the function
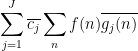
for some complex numbers 


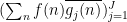
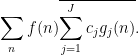
Applying Cauchy-Schwarz (dividing the first factor by 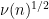
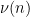

and the claim follows by expanding out the second factor.

Observe that Lemma 1 is a special case of Proposition 2 when 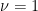
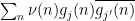
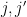
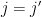
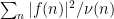
Remark 3 In harmonic analysis, the use of tools such as Proposition 2 is known as the method of almost orthogonality, or the
method. The explanation for the latter name is as follows. For sake of exposition, suppose that
defined by the formula
This is a bounded linear operator, and the left-hand side of (6) is nothing other than the
norm of
. Without any further information on the function
norm
, the best estimate one can obtain on (6) here is clearly
where
denotes the operator norm of
.
The adjoint
is easily computed to be
The composition
of
From the spectral theorem (or singular value decomposition), one sees that the operator norms of
and as
is also the supremum of the quantity
where
ranges over unit vectors in
For further discussion of almost orthogonality methods from a harmonic analysis perspective, see Chapter VII of this text of Stein.
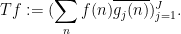



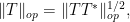
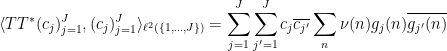
Exercise 4 Under the same hypotheses as Proposition 2, show that
as well as the variant inequality
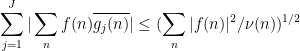


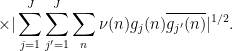
Proposition 2 has many applications in analytic number theory; for instance, we will use it in later notes to control the large value of Dirichlet series such as the Riemann zeta function. One of the key benefits is that it largely eliminates the need to consider further correlations of the function 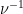

In this set of notes, we will use Proposition 2 to prove some versions of the large sieve inequality, which controls a square-sum of correlations

of an arbitrary finitely supported function 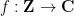
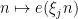
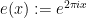

of 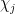
There is however one additional important trick, beyond the large sieve, which we will need in order to establish the Bombieri-Vinogradov theorem. As it turns out, after some basic manipulations (and the deployment of some multiplicative number theory, and specifically the Siegel-Walfisz theorem), the task of proving the Bombieri-Vinogradov theorem is reduced to that of getting a good estimate on sums that are roughly of the form
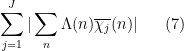
for some primitive Dirichlet characters 

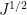

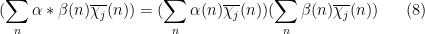
for any finitely supported sequences 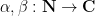
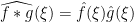
As we have seen in Notes 1, the von Mangoldt function 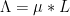


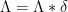
For further reading on these topics, including a significantly larger number of examples of the large sieve inequality, see Chapters 7 and 17 of Iwaniec and Kowalski.
Remark 5 We caution that the presentation given in this set of notes is highly ahistorical; we are using modern streamlined proofs of results that were first obtained by more complicated arguments.
Analytic number theory is often concerned with the asymptotic behaviour of various arithmetic functions: functions 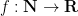



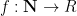

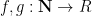


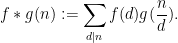
Regardless of what commutative ring
An important class of arithmetic functions in analytic number theory are the multiplicative functions, that is to say the arithmetic functions 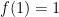
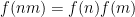
for all coprime 
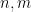
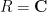
- the Kronecker delta
, defined by setting
for
and
otherwise;
- the constant function
and the linear function
(which by abuse of notation we denote by
- more generally monomials
for any fixed complex number
(in particular, the “Archimedean characters”
for any fixed
), which by abuse of notation we denote by
;
- Dirichlet characters
- the Liouville function
;
- the indicator function of the
–smooth numbers (numbers whose prime factors are all at most
- the indicator function of the
Examples of multiplicative functions that are not completely multiplicative include
- the Möbius function
- the divisor function
(also referred to as
);
- more generally, the higher order divisor functions
for
;
- the Euler totient function
;
- the number of roots
of a given polynomial
defined over
- more generally, the point counting function
of a given algebraic variety
defined over
- the function
that counts the number of representations of
- more generally, the function that maps a natural number
of absolute norm
These multiplicative functions interact well with the multiplication and convolution operations: if 
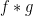


Finally, the product of completely multiplicative functions is again completely multiplicative. On the other hand, the sum of two multiplicative functions will never be multiplicative (just look at what happens at
The specific multiplicative functions listed above are also related to each other by various important identities, for instance

where
On the other hand, analytic number theory also is very interested in certain arithmetic functions that are not exactly multiplicative (and certainly not completely multiplicative). One particularly important such function is the von Mangoldt function 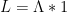
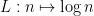
Definition 1 A derived multiplicative function
at the origin of a family
of multiplicative functions
parameterised by a formal parameter
. Equivalently,
of
such that the arithmetic function
is multiplicative, or equivalently that
is multiplicative and one has the Leibniz rule
More generally, for any
, a
-derived multiplicative function
at the origin of a family
of multiplicative functions
parameterised by formal parameters
. Equivalently,
coefficient of a multiplicative function in the extension
of
We define the notion of a
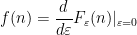
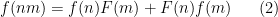

There are Leibniz rules similar to (2) but they are harder to state; for instance, a doubly derived multiplicative function 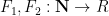
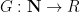
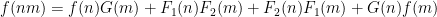
for all coprime
One can then check that the von Mangoldt function 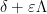
![{{\bf C}[\varepsilon]/(\varepsilon^2)}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+C%7D%5B%5Cvarepsilon%5D%2F%28%5Cvarepsilon%5E2%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)

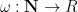
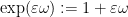
Remark 1 One can also phrase these concepts in terms of the formal Dirichlet series
associated to an arithmetic function
Using the definition of a 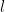
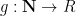
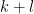

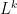
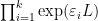
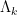
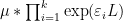
![{C[\varepsilon_1,\dots,\varepsilon_k]/(\varepsilon_1^2,\dots,\varepsilon_k^2)}](https://s0.wp.com/latex.php?latex=%7BC%5B%5Cvarepsilon_1%2C%5Cdots%2C%5Cvarepsilon_k%5D%2F%28%5Cvarepsilon_1%5E2%2C%5Cdots%2C%5Cvarepsilon_k%5E2%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
It then turns out that most (if not all) of the basic identities used by analytic number theorists concerning derived multiplicative functions, can in fact be viewed as coefficients of identities involving purely multiplicative functions, with the latter identities being provable primarily from multiplicative identities, such as (1). This phenomenon is analogous to the one in linear algebra discussed in this previous blog post, in which many of the trace identities used there are derivatives of determinant identities. For instance, the Leibniz rule
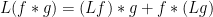
for any arithmetic functions

in the ring with one infinitesimal 

are top order terms of

and the variant formula 
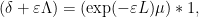
which can then be deduced from the previous identities by noting that the completely multiplicative function 


which plays a key role in the Erdös-Selberg elementary proof of the prime number theorem (as discussed in this previous blog post), is the top order term of the identity

involving the multiplicative functions 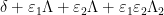




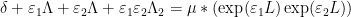
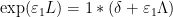

and (1). Similarly for higher identities such as
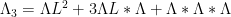
which arise from expanding out 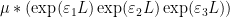
An analogous phenomenon arises for identities that are not purely multiplicative in nature due to the presence of truncations, such as the Vaughan identity

for any 
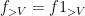
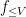

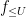
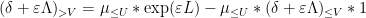

which can be easily derived from the identities 
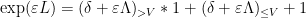

valid for natural numbers up to 
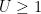
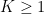



and arises by first observing that

vanishes up to 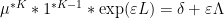
One consequence of this phenomenon is that identities involving derived multiplicative functions tend to have a dimensional consistency property: all terms in the identity have the same order of derivation in them. For instance, all the terms in the Selberg symmetry formula (3) are doubly derived functions, all the terms in the Vaughan identity (4) or the Heath-Brown identity (5) are singly derived functions, and so forth. One can then use dimensional analysis to help ensure that one has written down a key identity involving such functions correctly, much as is done in physics.
In addition to the dimensional analysis arising from the order of derivation, there is another dimensional analysis coming from the value of multiplicative functions at primes 
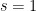
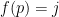







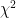
A 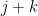
By taking top order coefficients, we then see that the convolution of a 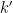


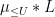

One caveat, though: this latter dimensional consistency breaks down for identities that involve infinitely many terms, such as Linnik’s identity
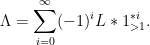
In this case, one can still rewrite things in terms of multiplicative functions as

so the former dimensional consistency is still maintained.
I thank Andrew Granville, Kannan Soundararajan, and Emmanuel Kowalski for helpful conversations on these topics.

Recent Comments