
In preparation for my upcoming course on random matrices, I am briefly reviewing some relevant foundational aspects of probability theory, as well as setting up basic probabilistic notation that we will be using in later posts. This is quite basic material for a graduate course, and somewhat pedantic in nature, but given how heavily we will be relying on probability theory in this course, it seemed appropriate to take some time to go through these issues carefully.
We will certainly not attempt to cover all aspects of probability theory in this review. Aside from the utter foundations, we will be focusing primarily on those probabilistic concepts and operations that are useful for bounding the distribution of random variables, and on ensuring convergence of such variables as one sends a parameter 
We will assume familiarity with the foundations of measure theory; see for instance these earlier lecture notes of mine for a quick review of that topic. This is also not intended to be a first introduction to probability theory, but is instead a revisiting of these topics from a graduate-level perspective (and in particular, after one has understood the foundations of measure theory). Indeed, I suspect it will be almost impossible to follow this course without already having a firm grasp of undergraduate probability theory.
— 1. Foundations —
At a purely formal level, one could call probability theory the study of measure spaces with total measure one, but that would be like calling number theory the study of strings of digits which terminate. At a practical level, the opposite is true: just as number theorists study concepts (e.g. primality) that have the same meaning in every numeral system that models the natural numbers, we shall see that probability theorists study concepts (e.g. independence) that have the same meaning in every measure space that models a family of events or random variables. And indeed, just as the natural numbers can be defined abstractly without reference to any numeral system (e.g. by the Peano axioms), core concepts of probability theory, such as random variables, can also be defined abstractly, without explicit mention of a measure space; we will return to this point when we discuss free probability later in this course.
For now, though, we shall stick to the standard measure-theoretic approach to probability theory. In this approach, we assume the presence of an ambient sample space 
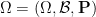


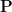
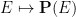
![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


Elements of the sample space 
If we were studying just a single random process, e.g. rolling a single die, then one could choose a very simple sample space – in this case, one could choose the finite set 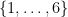
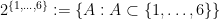

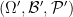


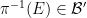
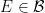
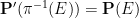

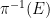
Example 1 As mentioned earlier, the sample space
being given by
.
Another example of an extension map is that of a permutation – for instance, replacing the sample space
by mapping
to
In order to have the freedom to perform extensions every time we need to introduce a new source of randomness, we will try to adhere to the following important dogma: probability theory is only “allowed” to study concepts and perform operations which are preserved with respect to extension of the underlying sample space. (This is analogous to how differential geometry is only “allowed” to study concepts and perform operations that are preserved with respect to coordinate change, or how graph theory is only “allowed” to study concepts and perform operations that are preserved with respect to relabeling of the vertices, etc..) As long as one is adhering strictly to this dogma, one can insert as many new sources of randomness (or reorganise existing sources of randomness) as one pleases; but if one deviates from this dogma and uses specific properties of a single sample space, then one has left the category of probability theory and must now take care when doing any subsequent operation that could alter that sample space. This dogma is an important aspect of the probabilistic way of thinking, much as the insistence on studying concepts and performing operations that are invariant with respect to coordinate changes or other symmetries is an important aspect of the modern geometric way of thinking. With this probabilistic viewpoint, we shall soon see the sample space essentially disappear from view altogether, after a few foundational issues are dispensed with.
Let’s give some simple examples of what is and what is not a probabilistic concept or operation. The probability 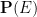
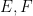


Indeed, once one is no longer working at the foundational level, it is best to try to suppress the fact that events are being modeled as sets altogether. To assist in this, we will choose notation that avoids explicit use of set theoretic notation. For instance, the union of two events 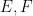
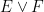
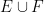

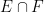
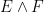
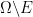
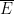

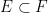
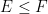
We record the trivial but fundamental union bound
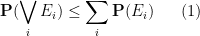
for any finite or countably infinite collection of events 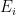
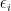
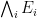
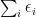

We will sometimes refer to use of the union bound to bound probabilities as the zeroth moment method, to contrast it with the first moment method, second moment method, exponential moment method, and Fourier moment methods for bounding probabilities that we will encounter later in this course.
Let us formalise some specific cases of the union bound that we will use frequently in the course. In most of this course, there will be an integer parameter 
Definition 1 (Asymptotic notation) We use
,
,
, or
to denote the estimate
for some
independent of
. If we need
, we will indicate this by subscripts, e.g.
. We write
if
for some
that goes to zero as
. We write
or
if
.
Given an event 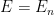
- An event
- An event
.
- An event
, it holds with probability
(i.e. one has
for some
independent of
- An event
for some
independent of
for some
- An event
, thus the probability of success goes to
Of course, all of these notions are probabilistic notions.
Given a family of events 

From the union bound (1) we immediately have
- If
holds surely.
- If
- If
) which hold with uniformly overwhelming probability, the
- If
) which hold with uniformly high probability, the
.)
- If
) which each hold asymptotically almost surely, then
Note how as the certainty of an event gets stronger, the number of times one can apply the union bound increases. In particular, holding with overwhelming probability is practically as good as holding surely or almost surely in many of our applications (except when one has to deal with the entropy of an
— 2. Random variables —
An event
Definition 3 (Random variable) Let
be a measurable space (i.e. a set
, equipped with a
). A random variable taking values in
from the sample space to
such that
is an event for every
.
As the notion of a random variable involves the sample space, one has to pause to check that it invariant under extensions before one can assert that it is a probabilistic concept. But this is clear: if 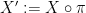

At this point let us make the convenient convention (which we have in fact been implicitly using already) that an event is identified with the predicate which is true on the event set and false outside of the event set. Thus for instance the event 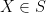

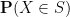
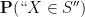
Remark 1 On occasion, we will have to deal with almost surely defined random variables, which are only defined on a subset
of
) whenever it would otherwise be undefined.
We observe a few key subclasses and examples of random variables:
- Discrete random variables, in which
is the discrete
, we say that the random variable is Boolean, while if
we say that the random variable is deterministic, and (by abuse of notation) we identify this random variable with
of an event
- Real-valued random variables, in which
, we have the events “
“. In particular, we have the upper tail event “
” and lower tail event “
” for any threshold
. (We also consider the events “
” and “
” to be tail events; in practice, there is very little distinction between the two.)
- Complex random variables, whose range is the complex plane with the Borel
” for some complex number
and some (small) radius
. We refer to real and complex random variables collectively as scalar random variables.
- Given a
, the
-valued random variable
is indeed a random variable, and the operation of converting
holds for all
.
- Given two random variables
and
taking values in
respectively, one can form the joint random variable
with range
with the product
for every
. One easily verifies that this is indeed a random variable, and that the operation of taking a joint random variable is a probabilistic operation. This variable can also be defined without reference to the sample space as the unique random variable for which one has
and
, where
and
are the usual projection maps from
for any family of random variables
in various ranges
(note here that the set
of labels can be infinite or even uncountable).
- Combining the previous two constructions, given any measurable binary operation
and random variables
taking values in
, and this is a probabilistic operation. Thus for instance one can add or multiply together scalar random variables, and similarly for the matrix-valued random variables that we will consider shortly. Similarly for ternary and higher order operations. A technical issue: if one wants to perform an operation (such as division of two scalar random variables) which is not defined everywhere (e.g. division when the denominator is zero). In such cases, one has to adjoin an additional “undefined” symbol
to the output range
- Vector-valued random variables, which take values in a finite-dimensional vector space such as
or
with the Borel
as the joint random variable of its scalar component random variables
.
- Matrix-valued random variables or random matrices, which take values in a space
or
of
real or complex-valued matrices, again with the Borel
are integers (usually we will focus on the square case
). Note here that the shape
as the joint random variable of its scalar components
. One can apply all the usual matrix operations (e.g. sum, product, determinant, trace, inverse, etc.) on random matrices to get a random variable with the appropriate range, though in some cases (e.g with inverse) one has to adjoin the undefined symbol
- Point processes, which take values in the space
of subsets
for all precompact measurable sets
. Thus, if
is a discrete random variable in
. For us, the key example of a point process comes from taking the spectrum
of eigenvalues (counting multiplicity) of a random
. I discuss point processes further in this previous blog post. We will return to point processes (and define them more formally) later in this course.
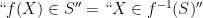
Remark 2 A pedantic point: strictly speaking, one has to include the range
rather than
to any coextension
of that random variable to a larger range space
(assuming of course that the
Given a random variable 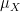
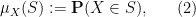
thus 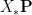
We write 
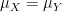
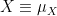
We have seen that every random variable generates a probability distribution
Lemma 4 (Creating a random variable with a specified distribution) Let
be a probability measure on a measurable space
Proof: Extend 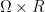
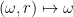
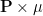
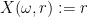

In the case of discrete random variables,
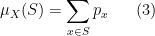
where 
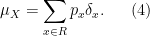
We list some important examples of discrete distributions:
- Dirac distributions
, in which
for
and
otherwise;
- discrete uniform distributions, in which
for all
;
- (Unsigned) Bernoulli distributions, in which
, and
for some parameter
;
- The signed Bernoulli distribution, in which
and
;
- Lazy signed Bernoulli distributions, in which
,
, and
for some parameter
;
- Geometric distributions, in which
and
for all natural numbers
and some parameter
- Poisson distributions, in which
for all natural numbers
Now we turn to non-discrete random variables 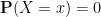
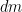
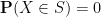
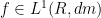
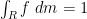
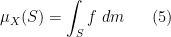
for all measurable sets 

We call 
In the case of real-valued random variables
![\displaystyle F_X(x) := {\bf P}(X \leq x) = \mu_X( (-\infty,x] ). \ \ \ \ \ (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F_X%28x%29+%3A%3D+%7B%5Cbf+P%7D%28X+%5Cleq+x%29+%3D+%5Cmu_X%28+%28-%5Cinfty%2Cx%5D+%29.+%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=0&c=20201002)
Indeed, 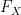
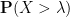
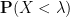
We give some basic examples of absolutely continuous scalar distributions:
- uniform distributions, in which
for some subset
in the real line, or a disk in the complex plane.
- The real normal distribution
of mean
and variance
, given by the density function
for
. We isolate in particular the standard (real) normal distribution
. Random variables with normal distributions are known as gaussian random variables.
- The complex normal distribution
of mean
and variance
. Again, we isolate the standard complex normal distribution
.
Later on, we will encounter several more scalar distributions of relevance to random matrix theory, such as the semicircular law or Marcenko-Pastur law. We will also of course encounter many matrix distributions (also known as matrix ensembles) as well as point processes.
Given an unsigned random variable ![{[0,+\infty]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C%2B%5Cinfty%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


which by the Fubini-Tonelli theorem can also be rewritten as

The expectation of an unsigned variable lies in also 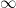
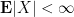
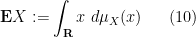
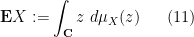
in the complex case. Similarly for vector-valued random variables (note that in finite dimensions, all norms are equivalent, so the precise choice of norm used to define 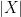


A deterministic scalar random variable 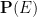


![{[a,b] \subset {\bf R}}](https://s0.wp.com/latex.php?latex=%7B%5Ba%2Cb%5D+%5Csubset+%7B%5Cbf+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

A fundamentally important property of expectation is that it is linear: if 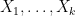
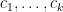
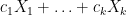

By the Fubini-Tonelli theorem, the same result also applies to infinite sums 
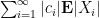
We will use linearity of expectation so frequently in the sequel that we will often omit an explicit reference to it when it is being used. It is important to note that linearity of expectation requires no assumptions of independence or dependence amongst the individual random variables
In the unsigned (or real absolutely integrable) case, expectation is also monotone: if 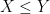
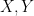
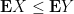
For an unsigned random variable, we have the obvious but very useful Markov inequality
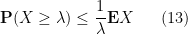
for any 
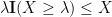
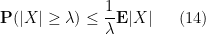
Another fact related to Markov’s inequality is that if 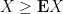

Exercise 1 (Borel-Cantelli lemma) Let
be a sequence of events such that
. Show that almost surely, at most finitely many of the events
If


when 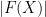
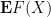
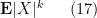
for various 
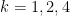

for real 


for complex or vector-valued 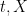

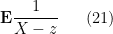
for complex 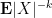

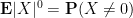


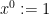
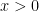
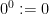

for any scalar random variables 
It will be important to know if a scalar random variable
such that
surely.
such that
for all
such that
for all
moment for some
.
almost surely.
Exercise 2 Show that these properties genuinely are in decreasing order of strength, i.e. that each property on the list implies the next.
Exercise 3 Show that each of these properties are closed under vector space operations, thus for instance if
and
also have sub-exponential tail for any scalar
The various species of Bernoulli random variable are surely bounded, and any random variable which is uniformly distributed in a bounded set is almost surely bounded. Gaussians are of course subgaussian, while the Poisson and geometric distributions merely have sub-exponential tail. Cauchy distributions are typical examples of heavy-tailed distributions which are almost surely finite, but do not have all moments finite (indeed, the Cauchy distribution does not even have finite first moment).
If we have a family of scalar random variables 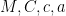
Fix
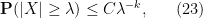
thus we see that the higher the moments that we control, the faster the tail decay is. From the dominated convergence theorem we also have the variant
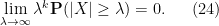
However, this result is qualitative or ineffective rather than quantitative because it provides no rate of convergence of 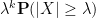

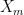

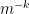
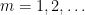
We observe some consequences of (23):
Lemma 5 Let
be a scalar random variable depending on a parameter
- If
has uniformly bounded expectation, then for any
independent of
with high probability.
- If
has uniformly bounded
, we have
with probability
.
- If
with overwhelming probability.
Exercise 4 Show that a real-valued random variable
such that
for all real
such that
for all
Exercise 5 Show that a real-valued random variable
for all positive integers
Once the second moment of a scalar random variable is finite, one can define the variance
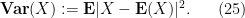
From Markov’s inequality we thus have Chebyshev’s inequality
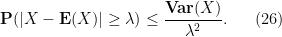
Upper bounds on 
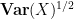
Exercise 6 (Scaling of mean and variance) If
are scalars, show that
and
. In particular, if
such that
has mean zero and variance one.
Exercise 7 We say that a real number
is a median of a real-valued random variable
.
- Show that a median always exists, and if
- If
for any median
If 
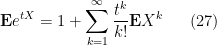
for any real or complex
— 3. Independence —
When studying the behaviour of a single random variable
Exercise 8 Let
be random variables (on sample spaces
respectively) taking values in a range
. Show that after extending the spaces
, the two random variables
are isomorphic, in the sense that there exists a probability space isomorphism
(i.e. an invertible extension map whose inverse is also an extension map) such that
.
However, once one studies families 
Example 2 Let
be drawn uniformly at random from the set
. Then the random variables
all individually have the same distribution, namely the signed Bernoulli distribution. However the pairs
, and
all have different joint distributions: the first pair, by definition, is uniformly distributed in
, and the third pair is uniformly distributed in
. Thus, for instance, if one is told that
, there is insufficient information to solve the problem; if
were distributed as
, while if
There is however an important special class of families of random variables in which the joint distribution is determined by the individual distributions.
Definition 6 (Joint independence) A family
A family
are jointly independent for all distinct
. More generally,
are jointly independent for all
and all distinct
.
We also say that
if
A family of events
is said to be jointly independent if their indicators
are jointly independent. Similarly for pairwise independence and
From the theory of product measure, we have the following equivalent formulation of joint independence:
Exercise 9 Let
- Show that the
of
for
, one has
- Show that the necessary and sufficient condition
is constrained to be at most
In particular, a finite family
of random variables
taking values in measurable spaces
are jointly independent if and only if
for all measurable
.
If the
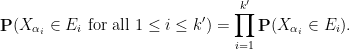
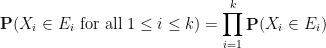
From the above exercise we see that joint independence implies
Example 3 Let
be the field of two elements, let
be the subspace of triples
with
, and let
be drawn uniformly at random from
. Then
is independent of each of
separately, but is not independent of
Exercise 10 This exercise generalises the above example. Let
be a finite field, and let
for some finite
be drawn uniformly at random from
- Show that each
is uniformly distributed in
- Show that for any
, that
- Show that
.
Informally, we thus see that imposing constraints between
Exercise 11 Let
, and let
and
separately), but
Exercise 12 We say that one random variable
) is determined by another random variable
) if there exists a (deterministic) function
such that
is surely true (i.e.
for all
is a family such that each
is determined by some subfamily
of the
disjoint as
varies, then the
Exercise 13 (Determinism vs. independence) Let
Exercise 14 Show that a complex random variable
are independent real gaussian random variables with the same variance. In particular, the variance of
and
will be half of variance of
One key advantage of working with jointly independent random variables and events is that one can compute various probabilistic quantities quite easily. We give some key examples below.
Exercise 15 If
are jointly independent events, show that
Show that the converse statement (i.e. that (28) and (29) imply joint independence) is true for
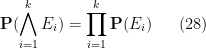

- If
- If
is absolutely integrable, and
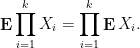
Remark 3 The above exercise combines well with Exercise 12. For instance, if
for any complex
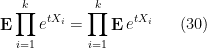
The following result is a key component of the second moment method.
Exercise 17 (Pairwise independence implies linearity of variance) If
and more generally
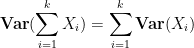

The product measure construction allows us to extend Lemma 4:
Exercise 18 (Creation of new, independent random variables) Let
be a collection (not necessarily finite) of probability measures
on measurable spaces
. Then, after extending the sample space if necessary, one can find a family
We isolate the important case when 
Corollary 7 Let
Thus, for instance, one can create arbitrarily large iid families of Bernoulli random variables, Gaussian random variables, etc., regardless of what other random variables are already in play. We thus see that the freedom to extend the underyling sample space allows us access to an unlimited source of randomness. This is in contrast to a situation studied in complexity theory and computer science, in which one does not assume that the sample space can be extended at will, and the amount of randomness one can use is therefore limited.
Remark 4 Given two probability measures
on two measurable spaces
, a joining or coupling of the these measures is a random variable
, whose individual components
— 4. Conditioning —
Random variables are inherently non-deterministic in nature, and as such one has to be careful when applying deterministic laws of reasoning to such variables. For instance, consider the law of the excluded middle: a statement 



Now, one can always eliminate these difficulties by explicitly working with points 
However, if instead one only seeks to remove a partial amount of randomness from consideration, then one can do this in a manner consistent with the probabilistic way of thinking, by introducing the machinery of conditioning. By conditioning an event to be true or false, or conditioning a random variable to be fixed, one can turn that random event or variable into a deterministic one, while preserving the random nature of other events and variables (particularly those which are independent of the event or variable being conditioned upon).
We begin by considering the simpler situation of conditioning on an event.
Definition 8 (Conditioning on an event) Let
, defined by the formula
All events
on the conditioned space, which we model set-theoretically as the set of all
All random variables
, and thus define conditional distribution
and conditional expectation
(if
One can also condition on the complementary event
By undoing this conditioning, we revert the underlying sample space and measure back to their original (or unconditional) values. Note that any random variable which has been defined both after conditioning on
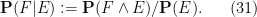
Conditioning affects the underlying probability space in a manner which is different from extension, and so the act of conditioning is not guaranteed to preserve probabilistic concepts such as distribution, probability, or expectation. Nevertheless, the conditioned version of these concepts are closely related to their unconditional counterparts:
Exercise 19 If
for any (unconditional) event
for any (unconditional) random variable
are also non-negative and absolutely integrable on their respective conditioned spaces, and that
In the degenerate case when
should be omitted. Similarly if
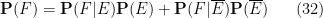
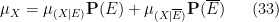
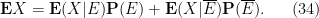
The above identities allow one to study probabilities, distributions, and expectations on the original sample space by conditioning to the two conditioned spaces.
From (32) we obtain the inequality
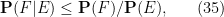
thus conditioning can magnify probabilities by a factor of at most 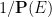
- If
- If
- If
for some
independent of
- If
for some
and some sufficiently small
independent of
- If
for some
Conditioning can distort the probability of events and the distribution of random variables. Most obviously, conditioning on 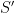
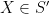
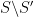
However, events and random variables that are independent of the event
Remark 5 One can view conditioning to an event
is unconditionally true if and only if it is conditionally true in both of these two cases. Similarly, in probability theory, given an event
Now we consider conditioning with respect to a discrete random variable 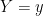

Exercise 20 Let
for any (unconditional) event
for any (unconditional) random variable
In all of these identities, we adopt the convention that any term involving
is ignored when
.
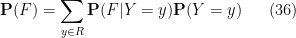

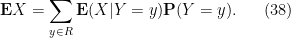
With the notation as in the above exercise, we define the conditional probability 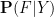
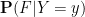
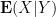
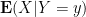
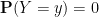
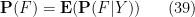
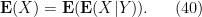
Remark 6 One can interpret conditional expectation as a type of orthogonal projection; see for instance these previous lecture notes of mine. But we will not use this perspective in this course. Just as conditioning on an event and its complement can be viewed as the probabilistic analogue of the law of the excluded middle, conditioning on a discrete random variable can be viewed as the probabilistic analogue of dividing into finitely or countably many cases. For instance, one could condition on the outcome
of a six-sided die, thus conditioning the underlying sample space into six separate subspaces. If the die is fair, then the unconditional statistics of a random variable or event would be an unweighted average of the conditional statistics of the six conditioned subspaces; if the die is weighted, one would take a weighted average instead.
Example 4 Let
, thus
(with probability
,
, but becomes the deterministic variable
when conditioned to
, and similarly becomes the deterministic variable
when conditioned to
. As a consequence, the conditional expectation
is equal to
. Similarly
; summing and using the linearity of (conditional) expectation (which follows automatically from the unconditional version) we obtain the obvious identity
.
If 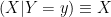


(so in this case the conditional expectation is a deterministic quantity).
Example 5 Let
where the latter equality holds since
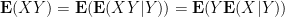
We will also need to condition with respect to continuous random variables (this is the probabilistic analogue of dividing into a potentially uncountable number of cases). To do this formally, we need to proceed a little differently from the discrete case, introducing the notion of a disintegration of the underlying sample space.
Definition 9 (Disintegration) Let
of the underlying sample space
(thus
almost surely), together with assignment of a probability measure
on the subspace
of
is measurable for every event
for all such events, where
Given such a disintegration, we can then condition to the event
by replacing
(with the induced
and random variables
on the conditioned space, giving rise to conditional probabilities
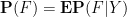
Example 6 (Discrete case) If
. For each
Example 7 (Independent case) Starting with an initial sample space
and letting
be the probability measure on
induced by the obvious isomorphism between
and
Example 8 Let
with Lebesgue measure, and let
. Then one can disintegrate
and letting
.
Exercise 21 (Almost uniqueness of disintegrations) Let
,
be two disintegrations of the same random variable
for
are defined using the disintegrations
(or vice versa) by some fixed
Similarly, for a scalar random variable
in such cases.
Remark 7 Under some mild topological assumptions on the underlying sample space (and on the measurable space
Remark 8 Strictly speaking, disintegration is not a probabilistic concept; there is no canonical way to extend a disintegration when extending the sample space;. However, due to the (almost) uniqueness and existence results alluded to earlier, this will not be a difficulty in practice. Still, we will try to use conditioning on continuous variables sparingly, in particular containing their use inside the proofs of various lemmas, rather than in their statements, due to their slight incompatibility with the “probabilistic way of thinking”.
Exercise 22 (Fubini-Tonelli theorem) Let
where
is the (almost surely defined) random variable that equals
whenever
whenever
is a non-negative (resp. bounded) measurable function. (One can essentially take (42), together with the fact that

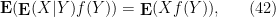
A typical use of conditioning is to deduce a probabilistic statement from a deterministic one. For instance, suppose one has a random variable 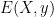
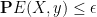
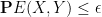
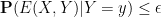
The act of conditioning a random variable to be fixed is occasionally also called freezing.
— 5. Convergence —
In a first course in undergraduate real analysis, we learn what it means for a sequence 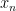
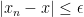
Now suppose that we have a sequence 

It turns out that there are several different notions of convergence which are of interest. For us, the four most important (in decreasing order of strength) will be almost sure convergence, convergence in probability, convergence in distribution, and tightness of distribution.
Definition 10 (Modes of convergence) Let
be a
converges to
for every
or equivalently if
holds asymptotically almost surely for every
, one has
of
for all sufficiently large
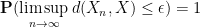
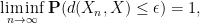
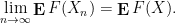
Remark 9 One can relax the requirement that
Exercise 23 (Implications and equivalences) Let
be random variables taking values in a
- (i) Show that if
- (ii) Show that if
- (iii) Show that if
- (iv) Show that
converges to
for all continuous functions
- (v) Conversely, if
- (vi) If
- (vii) If
- (viii) If
- (ix)
for every open subset
of
for every closed subset
Remark 10 The relationship between almost sure convergence and convergence in probability may be clarified by the following observation. If
is a sequence of events, then the indicators
converge in probability to zero iff
as
as
.
Example 9 Let
, let
lies in
. (Let us ignore the annoying
ambiguity in the decimal expansion here, as it will almost surely not be an issue.) Then the indicators
If
is the
digit of
, but do not converge in probability or almost surely. Thus we see that the latter two notions are sensitive not only to the distribution of the random variables, but how they are positioned in the sample space.
The limit of a sequence converging almost surely or in probability is clearly unique up to almost sure equivalence, whereas the limit of a sequence converging in distribution is only unique up to equivalence in distribution. Indeed, convergence in distribution is really a statement about the distributions 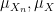
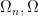
Exercise 24 (Borel-Cantelli lemma) Suppose that
for every
Exercise 25 (Convergence and moments) Let
.
- (i) If
, show that
- (ii) If
.
- (iii) If
and
.
- (iv) Give a counterexample to show that (iii) fails when
, even if we upgrade convergence in distribution to almost sure convergence.
- (v) If the
for every
, then
and analytic continuation.)
- (vi) If the
for every
, then
.
There are other interesting modes of convergence on random variables and on distributions, such as convergence in total variation norm, in the Lévy-Prokhorov metric, or in Wasserstein metric, but we will not need these concepts in this course.

134 comments
Comments feed for this article
11 April, 2012 at 7:01 pm
Rex
When defining real-valued random variables, does one typically equip the real line with the Borel measure, or its Lebesgue completion? Does this distinction matter much in practice?
For instance, does one have to do a significant amount of extra work to check that certain random variables are Lebesgue-measurable as opposed to merely Borel-measurable?
In the definition you refer only to the Borel measure, but later on you mention some issues about pullbacks of (Lebesgue) null sets when discussing absolute continuity of random variables.
11 April, 2012 at 8:28 pm
Terence Tao
In general, the Borel sigma algebra is slightly more convenient to use than the Lebesgue sigma algebra for the _range_ of a measurable function, but the Lebesgue can be more a convenient algebra to use for the _domain_ of a measurable function. But the main advantage of Lebesgue measure, namely completeness, is more useful in measure theory than in probability theory; for most probabilistic applications one does not actually need completeness.
p.s. I don’t know what issue about pullbacks of null sets you are referring to in your comment.
11 April, 2012 at 8:32 pm
Rex
I did not really mean to say there was any “issue”, but rather just that you switched from Borel measure to Lebesgue measure in the following passage:
“Now we turn to non-discrete random variables {X} taking values in some range {R}. We say that a random variable is continuous if {{\bf P}(X=x)=0} f
or all {x \in R} (here we assume that all points are measurable). If {R} is already equipped with some reference measure {dm} (e.g. Lebesgue measure in the case of scalar, vector, or matrix-valued random variables), we say that the random variable is absolutely continuous if {{\bf P}(X \in S)=0} for all null sets {S} in {R}. ”
and it was not clear to me whether there was any significance in this switch.
11 April, 2012 at 8:43 pm
Terence Tao
Ah. I tend to use Lebesgue measure to denote both the standard measure on the Lebesgue sigma algebra, as well as its restriction to the Borel sigma algebra (which is indeed the slightly more natural sigma algebra to use in this context). (The terminology “the Borel measure on ” to denote this restriction is also in use, but somewhat less common, perhaps because it can be confused with the more general concept of a Borel measure.)
” to denote this restriction is also in use, but somewhat less common, perhaps because it can be confused with the more general concept of a Borel measure.)
17 June, 2012 at 9:41 am
frankpmurphyh
Reblogged this on algebrafm.
5 September, 2012 at 6:12 pm
Gelasio Salazar
Dear Terry,
One question about the distinction between “with high probability” and
“asymptotically almost surely”. We just got a referee report in which they
ask us to change “w.h.p.” to “a.a.s.” — since in a particular lemma, all
we can prove is that a certain event holds with probability 1 -o(1). I
would have normally used w.h.p. and a.a.s. interchangeably, but after the
referee’s remark (s/he gave your Notes as reference) I realized we need to
be more careful. In the revised version we’ll use “a.a.s.”, and I was
wondering if you were aware of other sources in which this distinction
between “overwhelming probability”, “with high probability” and
“asymptotically almost surely” is used.
Last but not least, thanks for your comprehensive notes in Probability
Theory.
5 September, 2012 at 8:21 pm
Terence Tao
“asymptotically almost surely”, when it is used in literature, invariably means 1-o(1), but for “with high probability” there is less consensus; I have seen it used for both 1-o(1) and for 1-O(n^{-c}) (though not in the same paper, of course). But given that a.a.s. is a perfectly useful and accepted notation for 1-o(1), it seems logical to me to exclusively use w.h.p for 1-O(n^{-c}) instead.
19 September, 2012 at 10:59 am
Jack
Could you give an example of your saying that “If one was particularly well organised, one could in principle work out in advance all of the random variables one would ever want or need, and then specify the sample space accordingly, before doing any actual probability theory.”?
19 September, 2012 at 11:28 am
Jack
Can one say to some degree that a random variable on
on 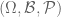 can be regarded as an extension
can be regarded as an extension 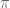 ?
?
27 September, 2012 at 5:24 pm
Jack
I’m confused about the concept “pushforward”. Let be a probability space and random variable
be a probability space and random variable  on this space with range
on this space with range 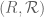 . Then
. Then 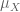 is a probability measure on
is a probability measure on 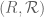 . However, according to your notes of 245A,
. However, according to your notes of 245A, 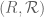 can be any measurable space, for example
can be any measurable space, for example  . But I also learned that one cannot sign a measure to
. But I also learned that one cannot sign a measure to  that render it a measure space. What do I do wrong here?
that render it a measure space. What do I do wrong here?
28 September, 2012 at 3:08 am
Terence Tao
One can place several measures on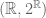 , e.g. a Dirac measure. (But one cannot have a non-trivial translation-invariant measure on this space, due to Banach-Tarski type paradoxes.)
, e.g. a Dirac measure. (But one cannot have a non-trivial translation-invariant measure on this space, due to Banach-Tarski type paradoxes.)
28 September, 2012 at 6:02 am
Jack
Ah, I see the point. As you said in this note, the underlying sample space of a random variable is often not specified. And the range of the random variable , according to Remark 2, can be somehow not mentioned either as I understand. I’m puzzled about this: to what extend should one specify a random variable? What’s left for a function when one does not specify its domain and range?
, according to Remark 2, can be somehow not mentioned either as I understand. I’m puzzled about this: to what extend should one specify a random variable? What’s left for a function when one does not specify its domain and range?
I saw lots of times when one says something like “consider a -value random variable”. They don’t even specify which
-value random variable”. They don’t even specify which  algebra is used for
algebra is used for  . What’s more, I’ve never read that one specify a measure for the range measurable space
. What’s more, I’ve never read that one specify a measure for the range measurable space  . Is it because we have an immediate one,
. Is it because we have an immediate one, 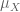 , or it doesn’t matter at all?
, or it doesn’t matter at all?
28 September, 2012 at 12:27 pm
Terence Tao
We usually don’t specify the sample space of a random variable for much the same reason we don’t specify which base (e.g. base 10, binary, etc.) we use to represent numbers, or which coordinate system we use to represent a manifold. We could specify these representations, if desired, but we wish to focus on those aspects of the mathematical objects being studied that are independent of the choice of representation, and so it is usually counterproductive to devote too much attention to these representations. (This is discussed near the beginning of this blog post.)
Also, one should make a distinction between a measurable space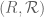 and a measure space
and a measure space 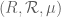 . A measurable space can be turned into a measure space by specifying a measure, but there are multiple measures one could use for this purpose, and in many cases it is better to not specify a measure at all.
. A measurable space can be turned into a measure space by specifying a measure, but there are multiple measures one could use for this purpose, and in many cases it is better to not specify a measure at all.
15 October, 2012 at 9:01 am
SAADA
Professeur Tao, auriez-vous une version française de cette note ?
Merci par avance.
15 October, 2012 at 10:08 am
Terence Tao
Non, mais outils de traduction automatique, tels que Google Translate, peuvent faire un travail raisonnable: http://translate.google.com/translate?sl=en&tl=fr&js=n&prev=_t&hl=en&ie=UTF-8&layout=2&eotf=1&u=http%3A%2F%2Fterrytao.wordpress.com%2F2010%2F01%2F01%2F254a-notes-0-a-review-of-probability-theory&act=url
15 October, 2012 at 10:35 am
Daniel
merci beaucoup professeur.
http://www.daniel-saada.eu
15 October, 2012 at 10:48 pm
Hoeffding bound | blayz
[…] first two sections of the book Topics in Random Matrix Theory by Terry Tao, with his draft and relevant notes available online, and the Hoeffding’s original paper along with the paper by […]
4 January, 2013 at 9:45 am
http terrytao wordpress com 2010 01 01 254a… « Kathys LinkBook
[…] https://terrytao.wordpress.com/2010/01/01/254a-notes-0-a-review-of-probability-theory/ […]
19 January, 2013 at 12:14 pm
tim
Hi Prof Tao,
Thanks for sharing your note!
I don’t quite understand why the extension is defined to be surjective in Tao’s blog. Is the concept “extension” trying to become morphisms in some category of probability spaces?
I found two links http://theoreticalatlas.wordpress.com/2010/11/11/categorifying-measure-theory/ and http://mathoverflow.net/questions/49426/is-there-a-category-structure-one-can-place-on-measure-spaces-so-that-category-th. Although I can only understand some small part of them, I hope they can be interesting to you!
Thanks!
23 March, 2013 at 5:05 am
Marek
Dear Prof. Tao,
Excellent post, thank you for sharing! I have a related question, and I would be very grateful if you or someone else could provide me an answer.
As is well-known, the total variation distance between (the laws of) two random variables X and Y defined on R is given by sup|E[g(X)]−E[g(Y)]|, where the supremum is taken over all g:R→[0,1] that are measurable. Here is my question: do we obtain the same definition if one considers the supremum over all g:R→[0,1] that are continuous? Or over all g:R→[0,1] that are differentiable?
Thanks a lot in advance!
23 March, 2013 at 7:11 am
Terence Tao
Yes, basically because test functions are dense in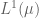 for any Borel probability measure on the real line (note that all Borel probability measures on R are Radon measures), thanks to basic tools such as the Stone-Weierstrass theorem, Lusin’s theorem, the Tietze extension theorem, and Urysohn’s lemma (as discussed in this previous blog post). Applying this general fact to
for any Borel probability measure on the real line (note that all Borel probability measures on R are Radon measures), thanks to basic tools such as the Stone-Weierstrass theorem, Lusin’s theorem, the Tietze extension theorem, and Urysohn’s lemma (as discussed in this previous blog post). Applying this general fact to  , the Borel probability measure formed by the average of the two laws, and using the Radon-Nikodym theorem to write
, the Borel probability measure formed by the average of the two laws, and using the Radon-Nikodym theorem to write 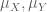 as bounded multiples of
as bounded multiples of  , we obtain the desired equivalence.
, we obtain the desired equivalence.
23 March, 2013 at 7:56 am
Marek
Thank you very much for the prompt reply! It is very clear in my mind now. Best, Marek
11 July, 2013 at 11:53 am
Probability and Statistics Books Online | Download free ebook
[…] A review of probability theory by Terence Tao, 2010 […]
16 September, 2013 at 7:12 am
Free Mathematics eBooks Online : Probability and Statistics | Top Free Books
[…] A review of probability theory by Terence Tao, 2010 […]
16 November, 2013 at 10:12 pm
Qualitative probability theory, types, and the group chunk and group configuration theorems | What's new
[…] classical foundations of probability theory (discussed for instance in this previous blog post) is founded on the notion of a probability space – a space (the sample space) equipped with […]
16 November, 2013 at 10:12 pm
Qualitative probability theory, types, and the group chunk and group configuration theorems | What's new
[…] classical foundations of probability theory (discussed for instance in this previous blog post) is founded on the notion of a probability space – a space (the sample space) equipped with […]
10 June, 2014 at 6:23 pm
Ehsan
Dear Prof. Tao,
Thank you for sharing your notes!
My question is about the probabilistic way of thinking. I understand that the cardinality of an event is not probabilistic notion because it is not preserved under the extension of the probability space.
Can rank and eigenvalues be probabilistic notions? If we consider the space of n-by-n matrices and extend it to the space of n+1-by-n+1 matrices, the the rank and eigenvalues may change as well.
I think I am missing something here.
Thanks!
10 June, 2014 at 9:13 pm
Terence Tao
The space of n by n matrices is not a probability space (and conversely, most probability spaces are not spaces of matrices), so I don’t see how your scenario would connect with probability theory.
Of course, if one had a matrix-valued random variable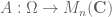 (i.e. a random matrix), one could compute its rank and eigenvalues, giving a random natural number and a random (multi-)set of points (i.e. a point process) respectively. These would all be probabilistic notions, but in all cases one would be extending the probabilistic domain
(i.e. a random matrix), one could compute its rank and eigenvalues, giving a random natural number and a random (multi-)set of points (i.e. a point process) respectively. These would all be probabilistic notions, but in all cases one would be extending the probabilistic domain  rather than the matrix space
rather than the matrix space 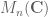 when performing probabilistic extensions.
when performing probabilistic extensions.
11 June, 2014 at 3:05 pm
Ehsan
Dear Prof. Tao,
Thank you for the answer. As you mentioned, I missed the fact that the probabilistic domain $\Omega$ is extended rather than the space of matrices.
16 June, 2014 at 7:47 pm
CRQ
Dear Prof Tao,
quick notation question: in definition 1, you say ”for some independent of
independent of  and all
and all 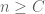 ”. Do you mean instead that there exists
”. Do you mean instead that there exists 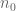 such that this holds ”for some
such that this holds ”for some  independent of
independent of  and all
and all 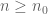 ? Thank you!
? Thank you!
17 June, 2014 at 6:26 am
Terence Tao
As long as there are no parameters in play besides , this is equivalent to the definition presented, since one could always raise either
, this is equivalent to the definition presented, since one could always raise either  or
or 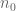 to be equal to each other. Once there are parameters, though, one has to be more careful. For instance if there are two parameters
to be equal to each other. Once there are parameters, though, one has to be more careful. For instance if there are two parameters 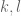 and one is asserting that
and one is asserting that 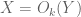 , then the conventions I use are that this means that
, then the conventions I use are that this means that  for all
for all 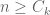 , where
, where 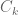 depends only on
depends only on  but not on
but not on 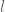 or
or  . With the definition involving
. With the definition involving 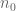 , it can be ambiguous as to whether
, it can be ambiguous as to whether 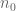 is allowed to depend on
is allowed to depend on 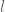 or not.
or not.
17 June, 2014 at 10:03 pm
nomen
I have been trying to define/explore “conditional random variables” for a while. In particular, I find that “sampling notation”, and what appears to be an adjunction in the algebra of random variables, makes them very natural. For example, consider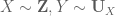 . It is very natural to treat
. It is very natural to treat  as being conditional on
as being conditional on  , since
, since  is uniformly distributed on
is uniformly distributed on 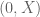 .
.
However, when I have tried to find out about this idea (mostly on math.stackexchange.com and mathoverflow.net), people have been dismissive. Actually, somebody on mathoverflow.net was supportive and suggested that I look into disintegrations.
Can you comment on the feasibility of defining such objects? Are they compatible with distintegrations, as you have used them?
17 June, 2014 at 10:09 pm
nomen
Sorry for the self-reply. I just wanted to clarify my motivation.
I often see that used as shorthand for
used as shorthand for
This “sample and bind” shorthand seems completely straight-forward to me, since we can “always” recover the distribution of Y from the joint distribution of (X,Y) by marginalizing X out. Are marginalizing and conditioning adjoints? It seems that the notation witnesses triple-ability, if they are adjoint at all.
This is effectively what I asked on mathoverflow.
22 June, 2014 at 11:15 am
Felix V.
Dear Prof. Tao,
thank you very much for this nice post and your book on Random Matrices.
as I noted in this (http://math.stackexchange.com/questions/842989/the-completeness-assumption-in-prokhorovs-theorem/843397#843397) stackexchange post, Exercise 23 seems to have mild problems.
You only assume that is
is  -compact, not necessarily complete.
-compact, not necessarily complete.
In that case, part (iv) of that exercise fails. Take e.g. . Then there are no nontrivial continuous functions with compact support, so that one of the conditions is vacuous.
. Then there are no nontrivial continuous functions with compact support, so that one of the conditions is vacuous.
I am also not sure that part (i) is really true in that setting. The proofs that I found all use the completeness of to show that certain sets (namely of the form
to show that certain sets (namely of the form 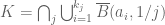 are compact, as they are closed and totally bounded).
are compact, as they are closed and totally bounded).
Sadly, I did not manage to produce a counterexample up to now.
Best regards,
Felix V.
22 June, 2014 at 1:11 pm
Terence Tao
Oops, you’re right; I had intended to assume that the metric space is both sigma compact and locally compact, but I think I thought that the latter hypotheses was implied by the former one for metric spaces, but as you point out, the example of the rationals shows that this is not the case. I’ve modified the text accordingly.
24 June, 2014 at 5:14 am
Felix V.
Thanks for the answer.
In my post above I was actually referring to part (ii) of the exercise, not part (i), sorry about that.
Do you know if this part (ii) is correct without the completeness assumption? Wikipedia (http://en.wikipedia.org/wiki/Prokhorov%27s_theorem , part 1 of “Statement of the theorem”) also only assumes that the metric space is separable, but they give neither a proof, nor a source.
24 June, 2014 at 7:42 am
Xiteng Liu
Congratulations Terry for The Breakthrough Award! You deserve it for your endeavor and enthusiasm in math.
27 June, 2014 at 3:00 am
Alon Gonen
Dear professor Terrence Tao,
How do you derive equation 1.24 using dominated converge?
Thanks
27 June, 2014 at 12:29 pm
Terence Tao
15 July, 2014 at 4:22 am
Real analysis relative to a finite measure space | What's new
[…] 1 In my previous post on the foundations of probability theory, I emphasised the freedom to extend the sample space to a larger sample space whenever one wished […]
11 August, 2014 at 7:40 am
254A, Notes 0: A review of probability theory | Mathemania
[…] 254A, Notes 0: A review of probability theory. […]
4 March, 2015 at 12:57 pm
Aryeh
Dear Prof. Tao, I don’t see how Poisson variables are subgaussian. In particular, the Laplace transform of the Poisson distribution is not upper-bounded by $e^{c t^2}$. Best, -Aryeh
[Oops, you’re right – corrected, thanks -T.]
29 September, 2015 at 9:54 pm
275A, Notes 0: Foundations of probability theory | What's new
[…] the classical measure-theoretic foundations of probability. (I wrote on these foundations also in this previous blog post, but in that post I already assumed that the reader was familiar with measure theory and basic […]
3 October, 2015 at 2:58 pm
275A, Notes 1: Integration and expectation | What's new
[…] Remark 2 There is one minor exception to this general rule if we do not impose the additional requirement that the factor map is surjective. Namely, for non-surjective , it can become possible that two events are unequal in the original sample space model, but become equal in the extension (and similarly for random variables), although the converse never happens (events that are equal in the original sample space always remain equal in the extension). For instance, let be the discrete probability space with and , and let be the discrete probability space with , and non-surjective factor map defined by . Then the event modeled by in is distinct from the empty event when viewed in , but becomes equal to that event when viewed in . Thus we see that extending the sample space by a non-surjective factor map can identify previously distinct events together (though of course, being probability preserving, this can only happen if those two events were already almost surely equal anyway). This turns out to be fairly harmless though; while it is nice to know if two given events are equal, or if they differ by a non-null event, it is almost never useful to know that two events are unequal if they are already almost surely equal. Alternatively, one can add the additional requirement of surjectivity in the definition of an extension, which is also a fairly harmless constraint to impose (this is what I chose to do in this previous set of notes). […]
6 October, 2015 at 9:40 am
Ben Golub
As a complement to Durrett’s book, I always found Amir Dembo’s notes on probability to be useful for a course of this type… their main virtue is that they are very systematic and (perhaps obsessively!) organized. http://statweb.stanford.edu/~adembo/stat-310a/lnotes.pdf
24 May, 2016 at 7:40 am
Robert
Thanks for the post. In relating to Terry’s definition of random matrices, does anybody know what is the best way to define a random matrix when its shape is also random variable? For instance, if A is random matrix such that A: Omega -> {space of matrices with m rows}. Thus A maps to the space of matrices with m rows, but the number of columns is itself a random variable. Is there a common way to construct of such a random matrix?
13 July, 2017 at 4:39 pm
Making Probability Mathematical | Infinite Series
[…] 254A, Notes 0: A review of probability theory Kolmogorov – Foundations of the Theory of Probability Ian Hacking – The Emergence of Probability […]
22 November, 2017 at 8:04 am
Mateo Wirth
I am having trouble with the definition of a disintegration given above. In particular, without the condition that for any measurable subset S of R, letting E be the event that Y is in S, we have
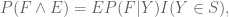
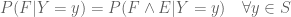 .
.
I can’t seem to conclude that
22 November, 2017 at 8:13 am
Mateo Wirth
Nevermind I see how it works now. Sorry!
12 February, 2019 at 6:33 am
The probability space as a fiction | Hydrobates
[…] search starting from this suspicion let me to an enlightening blog post of Terry Tao called ‘Notes 0: A review of probability theory‘. There he reviews ‘foundational aspects of probability theory’. Fairly early in […]
23 February, 2019 at 1:12 pm
What's the meaning of "random" in Mathematics? | Page 2 | Physics Forums
[…] measure space; we will return to this point when we discuss free probability later in this course. https://terrytao.wordpress.com/2010/01/01/254a-notes-0-a-review-of-probability-theory/ so for starting out: why not focus on probabilistic concepts as opposed to representation in […]
7 August, 2019 at 8:33 am
Making Probability Mathematical | Infinite Series - دکتر تیز
[…] 254A, Notes 0: A review of probability theory Kolmogorov – Foundations of the Theory of Probability Ian Hacking – The Emergence of Probability […]
12 November, 2019 at 6:47 pm
254A, Notes 9 – second moment and entropy methods | What's new
[…] In these notes we presume familiarity with the basic concepts of probability theory, such as random variables (which could take values in the reals, vectors, or other measurable spaces), probability, and expectation. Much of this theory is in turn based on measure theory, which we will also presume familiarity with. See for instance this previous set of lecture notes for a brief review. […]
14 December, 2019 at 12:58 pm
Is there a category consisting of probability spaces as objects and measurable functions as morphisms? – Lofgren's financial decisions
[…] this post, Terance Tao writes ”probability theory is only ‘allowed’ to study concepts and […]
7 July, 2020 at 7:05 pm
Server Bug Fix: Categorification of probability theory: what does a “probability sheaf” tell us (if anything) about probability theory? - TECHPRPR
[…] If you’re interested in this field, I think you will want to read these references (plus the blog post by Tao that Simpson cites), and you may need to give it time before super compelling applications […]
12 January, 2021 at 2:44 am
Anonymous
Dear Prof. Tao,
I am an undergraduate student majoring in mathematics, and I really enjoyed the way you explained the “probabilistic way of thinking” and ideas of conditioning on events or extending the sample space in a way far better than most introductory texts that I’ve read. (Although most of this article went over my head). I would be really grateful if you could suggest some references/ lecture notes written in a similar style, which are more suited to an undergraduate looking to learn probability theory.
Thank you.
11 October, 2021 at 9:19 am
254A, Supplement 4: Probabilistic models and heuristics for the primes (optional) | What's new
[…] material in this set of notes presumes some prior exposure to probability theory. See for instance this previous post for a quick review of the relevant […]