
You are currently browsing the category archive for the ‘254A – random matrices’ category.
I’ve just finished writing the first draft of my second book coming out of the 2010 blog posts, namely “Topics in random matrix theory“, which was based primarily on my graduate course in the topic, though it also contains material from some additional posts related to random matrices on the blog. It is available online here. As usual, comments and corrections are welcome. There is also a stub page for the book, which at present does not contain much more than the above link.
In this final set of lecture notes for this course, we leave the realm of self-adjoint matrix ensembles, such as Wigner random matrices, and consider instead the simplest examples of non-self-adjoint ensembles, namely the iid matrix ensembles. (I had also hoped to discuss recent progress in eigenvalue spacing distributions of Wigner matrices, but have run out of time. For readers interested in this topic, I can recommend the recent Bourbaki exposé of Alice Guionnet.)
The basic result in this area is
Theorem 1 (Circular law) Let
be an
iid matrix, whose entries
,
are iid with a fixed (complex) distribution
of mean zero and variance one. Then the spectral measure
converges both in probability and almost surely to the circular law
, where
are the real and imaginary coordinates of the complex plane.
This theorem has a long history; it is analogous to the semi-circular law, but the non-Hermitian nature of the matrices makes the spectrum so unstable that key techniques that are used in the semi-circular case, such as truncation and the moment method, no longer work; significant new ideas are required. In the case of random gaussian matrices, this result was established by Mehta (in the complex case) and by Edelman (in the real case), as was sketched out in Notes. In 1984, Girko laid out a general strategy for establishing the result for non-gaussian matrices, which formed the base of all future work on the subject; however, a key ingredient in the argument, namely a bound on the least singular value of shifts 
At present, the known methods used to establish the circular law for general ensembles rely very heavily on the joint independence of all the entries. It is a key challenge to see how to weaken this joint independence assumption.
Read the rest of this entry »
Now we turn attention to another important spectral statistic, the least singular value 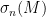


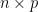
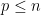
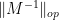
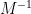

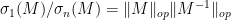
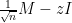

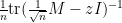
The least singular value

which sits at the “hard edge” of the spectrum, bears a superficial similarity to the operator norm

at the “soft edge” of the spectrum, that was discussed back in Notes 3, so one may at first think that the methods that were effective in controlling the latter, namely the epsilon-net argument and the moment method, would also work to control the former. The epsilon-net method does indeed have some effectiveness when dealing with rectangular matrices (in which the spectrum stays well away from zero), but the situation becomes more delicate for square matrices; it can control some “low entropy” portions of the infimum that arise from “structured” or “compressible” choices of 
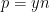
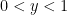
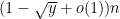


So one needs to supplement these existing methods with additional tools. It turns out that the key issue is to understand the distance between one of the 
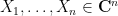

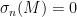
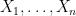

More generally, if the least singular value 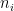
When working with random matrices with jointly independent coefficients, we have the crucial property that the unit normal 
These methods rely quite strongly on the joint independence on all the entries; it remains a challenge to extend them to more general settings. Even for Wigner matrices, the methods run into difficulty because of the non-independence of some of the entries (although it turns out one can understand the least singular value in such cases by rather different methods).
To simplify the exposition, we shall focus primarily on just one specific ensemble of random matrices, the Bernoulli ensemble 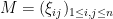
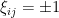
Our study of random matrices, to date, has focused on somewhat general ensembles, such as iid random matrices or Wigner random matrices, in which the distribution of the individual entries of the matrices was essentially arbitrary (as long as certain moments, such as the mean and variance, were normalised). In these notes, we now focus on two much more special, and much more symmetric, ensembles:
- The Gaussian Unitary Ensemble (GUE), which is an ensemble of random
, and the diagonal entries are iid with distribution
, and independent of the upper-triangular ones; and
- The Gaussian random matrix ensemble, which is an ensemble of random
The symmetric nature of these ensembles will allow us to compute the spectral distribution by exact algebraic means, revealing a surprising connection with orthogonal polynomials and with determinantal processes. This will, for instance, recover the semi-circular law for GUE, but will also reveal fine spacing information, such as the distribution of the gap between adjacent eigenvalues, which is largely out of reach of tools such as the Stieltjes transform method and the moment method (although the moment method, with some effort, is able to control the extreme edges of the spectrum).
Similarly, we will see for the first time the circular law for eigenvalues of non-Hermitian matrices.
There are a number of other highly symmetric ensembles which can also be treated by the same methods, most notably the Gaussian Orthogonal Ensemble (GOE) and the Gaussian Symplectic Ensemble (GSE). However, for simplicity we shall focus just on the above two ensembles. For a systematic treatment of these ensembles, see the text by Deift.
Read the rest of this entry »
In the foundations of modern probability, as laid out by Kolmogorov, the basic objects of study are constructed in the following order:
- Firstly, one selects a sample space
, whose elements
represent all the possible states that one’s stochastic system could be in.
- Then, one selects a
-algebra
of events
(modeled by subsets of
in a countably additive manner, so that the entire sample space has probability
.
- Finally, one builds (commutative) algebras of random variables
(such as complex-valued random variables, modeled by measurable functions from
), and (assuming suitable integrability or moment conditions) one can assign expectations
to each such random variable.
In measure theory, the underlying measure space
However, it is possible to take the abstraction process one step further, and view the algebra of random variables and their expectations as being the foundational concept, and ignoring both the presence of the original sample space, the algebra of events, or the probability measure.
There are two reasons for wanting to shed (or abstract away) these previously foundational structures. Firstly, it allows one to more easily take certain types of limits, such as the large 
Secondly, this abstract formalism allows one to generalise the classical, commutative theory of probability to the more general theory of non-commutative probability theory, which does not have a classical underlying sample space or event space, but is instead built upon a (possibly) non-commutative algebra of random variables (or “observables”) and their expectations (or “traces”). This more general formalism not only encompasses classical probability, but also spectral theory (with matrices or operators taking the role of random variables, and the trace taking the role of expectation), random matrix theory (which can be viewed as a natural blend of classical probability and spectral theory), and quantum mechanics (with physical observables taking the role of random variables, and their expected value on a given quantum state being the expectation). It is also part of a more general “non-commutative way of thinking” (of which non-commutative geometry is the most prominent example), in which a space is understood primarily in terms of the ring or algebra of functions (or function-like objects, such as sections of bundles) placed on top of that space, and then the space itself is largely abstracted away in order to allow the algebraic structures to become less commutative. In short, the idea is to make algebra the foundation of the theory, as opposed to other possible choices of foundations such as sets, measures, categories, etc..
[Note that this foundational preference is to some extent a metamathematical one rather than a mathematical one; in many cases it is possible to rewrite the theory in a mathematically equivalent form so that some other mathematical structure becomes designated as the foundational one, much as probability theory can be equivalently formulated as the measure theory of probability measures. However, this does not negate the fact that a different choice of foundations can lead to a different way of thinking about the subject, and thus to ask a different set of questions and to discover a different set of proofs and solutions. Thus it is often of value to understand multiple foundational perspectives at once, to get a truly stereoscopic view of the subject.]
It turns out that non-commutative probability can be modeled using operator algebras such as 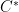
When one generalises the set of structures in one’s theory, for instance from the commutative setting to the non-commutative setting, the notion of what it means for a structure to be “universal”, “free”, or “independent” can change. The most familiar example of this comes from group theory. If one restricts attention to the category of abelian groups, then the “freest” object one can generate from two generators 
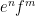
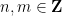
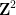
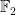
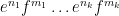

Similarly, when generalising classical probability theory to non-commutative probability theory, the notion of what it means for two or more random variables to be independent changes. In the classical (commutative) setting, two (bounded, real-valued) random variables 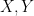
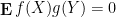
whenever 
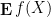
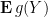
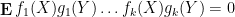
whenever 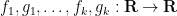
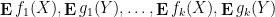
The concept of free independence was introduced by Voiculescu, and its study is now known as the subject of free probability. We will not attempt a systematic survey of this subject here; for this, we refer the reader to the surveys of Speicher and of Biane. Instead, we shall just discuss a small number of topics in this area to give the flavour of the subject only.
The significance of free probability to random matrix theory lies in the fundamental observation that random matrices which are independent in the classical sense, also tend to be independent in the free probability sense, in the large
Much as free groups are in some sense “maximally non-commutative”, freely independent random variables are about as far from being commuting as possible. For instance, if 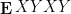
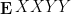

Another important (and closely related) analogy is that while the distribution of sums of independent commutative random variables can be quickly computed via the characteristic function (i.e. the Fourier transform of the distribution), the distribution of sums of freely independent non-commutative random variables can be quickly computed using the Stieltjes transform instead (or with closely related objects, such as the 
As mentioned earlier, free probability is an excellent tool for computing various expressions of interest in random matrix theory, such as asymptotic values of normalised moments in the large 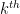


We can now turn attention to one of the centerpiece universality results in random matrix theory, namely the Wigner semi-circle law for Wigner matrices. Recall from previous notes that a Wigner Hermitian matrix ensemble is a random matrix ensemble 
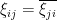
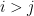
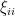
In previous notes we saw that the operator norm of 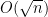
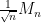

of 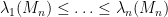
When 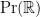
Now we consider the behaviour of the ESD of a sequence of Hermitian matrix ensembles 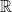
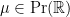

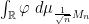
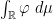
Remark 1 As usual, convergence almost surely implies convergence in probability, but not vice versa. In the special case of random probability measures, there is an even weaker notion of convergence, namely convergence in expectation, defined as follows. Given a random ESD
, defined via duality (the Riesz representation theorem) as
this probability measure can be viewed as the law of a random eigenvalue
drawn from a random matrix
converges the vague topology to
, thus
for all
.
In general, these notions of convergence are distinct from each other; but in practice, one often finds in random matrix theory that these notions are effectively equivalent to each other, thanks to the concentration of measure phenomenon.
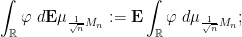

Exercise 1 Let
- Show that
converges almost surely to
for all
.
- Show that
- Show that
converges to
We can now state the Wigner semi-circular law.
Theorem 1 (Semicircular law) Let
. Then the ESDs

A numerical example of this theorem in action can be seen at the MathWorld entry for this law.
The semi-circular law nicely complements the upper Bai-Yin theorem from Notes 3, which asserts that (in the case when the entries have finite fourth moment, at least), the matrices 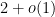
![{[-2,2]}](https://s0.wp.com/latex.php?latex=%7B%5B-2%2C2%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

As will hopefully become clearer in the next set of notes, the semi-circular law is the noncommutative (or free probability) analogue of the central limit theorem, with the semi-circular distribution (1) taking on the role of the normal distribution. Of course, there is a striking difference between the two distributions, in that the former is compactly supported while the latter is merely subgaussian. One reason for this is that the concentration of measure phenomenon is more powerful in the case of ESDs of Wigner matrices than it is for averages of iid variables; compare the concentration of measure results in Notes 3 with those in Notes 1.
There are several ways to prove (or at least to heuristically justify) the semi-circular law. In this set of notes we shall focus on the two most popular methods, the moment method and the Stieltjes transform method, together with a third (heuristic) method based on Dyson Brownian motion (Notes 3b). In the next set of notes we shall also study the free probability method, and in the set of notes after that we use the determinantal processes method (although this method is initially only restricted to highly symmetric ensembles, such as GUE).
One theme in this course will be the central nature played by the gaussian random variables 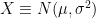
One way to exploit this algebraic structure is to continuously deform the variance 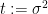

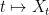
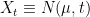


At present, we have not completely specified what 
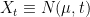
We will begin with one-dimensional Brownian motion, but it is a simple matter to extend the process to higher dimensions. In particular, we can define Brownian motion on vector spaces of matrices, such as the space of
Let 

of 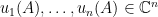
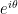
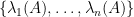
A basic question in linear algebra asks the extent to which the eigenvalues 
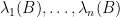

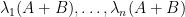

when expressed in terms of eigenvalues, gives the trace constraint


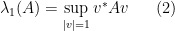
(together with the counterparts for 
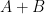

and so forth.
The complete answer to this problem is a fascinating one, requiring a strangely recursive description (once known as Horn’s conjecture, which is now solved), and connected to a large number of other fields of mathematics, such as geometric invariant theory, intersection theory, and the combinatorics of a certain gadget known as a “honeycomb”. See for instance my survey with Allen Knutson on this topic some years ago.
In typical applications to random matrices, one of the matrices (say, 

valid whenever 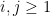
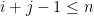

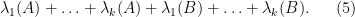
One consequence of these inequalities is that the spectrum of a Hermitian matrix is stable with respect to small perturbations.
We will also establish some closely related inequalities concerning the relationships between the eigenvalues of a matrix, and the eigenvalues of its minors.
Many of the inequalities here have analogues for the singular values of non-Hermitian matrices (which is consistent with the discussion near Exercise 16 of Notes 3). However, the situation is markedly different when dealing with eigenvalues of non-Hermitian matrices; here, the spectrum can be far more unstable, if pseudospectrum is present. Because of this, the theory of the eigenvalues of a random non-Hermitian matrix requires an additional ingredient, namely upper bounds on the prevalence of pseudospectrum, which after recentering the matrix is basically equivalent to establishing lower bounds on least singular values. We will discuss this point in more detail in later notes.
We will work primarily here with Hermitian matrices, which can be viewed as self-adjoint transformations on complex vector spaces such as 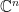

Now that we have developed the basic probabilistic tools that we will need, we now turn to the main subject of this course, namely the study of random matrices. There are many random matrix models (aka matrix ensembles) of interest – far too many to all be discussed in a single course. We will thus focus on just a few simple models. First of all, we shall restrict attention to square matrices
- Iid matrix ensembles, in which the coefficients
to have mean zero and unit variance. Examples of iid models include the Bernouli ensemble (aka random sign matrices) in which the
, and the complex gaussian matrix ensemble in which
.
- Symmetric Wigner matrix ensembles, in which the upper triangular coefficients
are jointly independent and real, but the lower triangular coefficients
are constrained to equal their transposes:
. Thus
. (We will explain the reason for this discrepancy later.)
- Hermitian Wigner matrix ensembles, in which the upper triangular coefficients are jointly independent, with the diagonal entries being real and the strictly upper triangular entries complex, and the lower triangular coefficients
Given a matrix ensemble
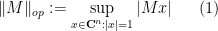
of the matrix 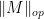
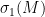
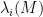

on this quantity, for various thresholds 
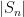
An 


As mentioned before, there is an analogy here with the concentration of measure phenomenon, and many of the tools used in the latter (e.g. the moment method) will also appear here. (Indeed, we will be able to use some of the concentration inequalities from Notes 1 directly to help control
The most advanced knowledge we have on the operator norm is given by the Tracy-Widom law, which not only tells us where the operator norm is concentrated in (it turns out, for instance, that for a Wigner matrix (with some additional technical assumptions), it is concentrated in the range ![{[2\sqrt{n} - O(n^{-1/6}), 2\sqrt{n} + O(n^{-1/6})]}](https://s0.wp.com/latex.php?latex=%7B%5B2%5Csqrt%7Bn%7D+-+O%28n%5E%7B-1%2F6%7D%29%2C+2%5Csqrt%7Bn%7D+%2B+O%28n%5E%7B-1%2F6%7D%29%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Read the rest of this entry »
Consider the sum 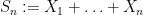


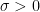
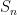
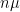

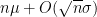
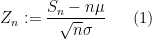
then 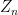
In the previous set of notes, we were able to establish various tail bounds on

and if the original distribution
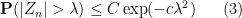
for some absolute constants 
Now we look at the distribution of
Theorem 1 (Central limit theorem) Let
Exercise 2 Show that
of
and
are almost independent of each other, since the bulk of the sum
is determined by those
with
. Now make this intuition precise.)
Exercise 3 Use Stirling’s formula from Notes 0a to verify the central limit theorem in the case when
Exercise 4 Use Exercise 9 from Notes 1 to verify the central limit theorem in the case when
Note we are only discussing the case of real iid random variables. The case of complex random variables (or more generally, vector-valued random variables) is a little bit more complicated, and will be discussed later in this post.
The central limit theorem (and its variants, which we discuss below) are extremely useful tools in random matrix theory, in particular through the control they give on random walks (which arise naturally from linear functionals of random matrices). But the central limit theorem can also be viewed as a “commutative” analogue of various spectral results in random matrix theory (in particular, we shall see in later lectures that the Wigner semicircle law can be viewed in some sense as a “noncommutative” or “free” version of the central limit theorem). Because of this, the techniques used to prove the central limit theorem can often be adapted to be useful in random matrix theory. Because of this, we shall use these notes to dwell on several different proofs of the central limit theorem, as this provides a convenient way to showcase some of the basic methods that we will encounter again (in a more sophisticated form) when dealing with random matrices.

Recent Comments